【Linux C/C++开发】使用hash算法进行性能优化
前言
C/C++项目可以直接接触到系统级接口,在出现性能问题(比如内存使用、CPU占用、读写IO、网络传输等)时,需要深入的进行解决,没有现成的框架可以直接套用,本篇主要介绍适合使用hash算法的场景。
hash特性
-
高效计算:通过位运算、模运算等高效数学操作将关键字映射到数组索引,实现散列表, O(1) 时间复杂度实现数据快速存取
-
固定长度输出:将任意长度的输入数据(如字符串、文件)映射为固定长度输出(哈希值)
-
唯一性:理想情况下,不同的输入应生成不同的哈希值
-
不可逆性:无法从哈希值反推出原始输入
-
确定性:相同的输入始终生成相同的哈希值
-
雪崩效应:当输入数据发生微小变化时,哈希值发生大幅度的变化
典型使用场景
- 完整性校验:网络通信时,对某些重要的数据进行hash计算,传递hash值给到对端,对端对接收的内容进行同样的hash计算,根据唯一性和雪崩效应特性,如果数据被篡改,生成的hash值必定与传输过来的hash值不一致,此时可对数据包进行丢弃及其他操作(预警日志);
- 加密:数据库中保存用户密码时,明文保存容易泄露,登录端和数据库中存储的密码使用同一种hash计算规则,对生成的值进行比较即可完整密码验证,即使hash值泄露,根据不可逆性特性,也无法获取到真实的密码;
- 快速检索:散列表特性,使得在单点查询的场景中,检索速度特别快。
C++的常见hash及场景应用
常见hash
1.C++标准库 哈希函数 std::hash
支持基本数据类型(如 int、float、std::string)和部分标准库类型(如指针、智能指针)的哈希计算,对自定义类型需手动特化 std::hash 模板或提供自定义哈希函数对象。
平均时间复杂度为 O(1),适合快速插入、删除和查找。
2.C++ STL容器 哈希表 std::unordered_map
它是一个无序容器,底层采用哈希桶(bucket)结构,通过哈希函数将键映射到特定桶中,桶内使用链表或其他结构处理冲突。
平均时间复杂度为 O(1),适合快速插入、删除和查找。
篇外介绍:std::map是基于红黑树(树结构)的有序容器,平均时间复杂度为O(log n)。
| STL容器 | 底层结构 | 时间复杂度 | 内存特点 | 场景 |
| map | 红黑树 (有序) | 平均 O(1) 最坏 O(n) | 每个节点需存储父/子指针, 结构紧凑但冗余,内存占用高 | 需要键有序或范围查询 内存敏感且数据量小 |
| unordered_map | 哈希表 (无序) | O(log n) | 预分配桶空间,内存碎片较高 相对树结构内存占用低 | 高频单点查询 数据量大但内存充足 |
3.第三方库--OpenSSL加密哈希
- MD5:输出128位哈希值;(不安全)
- SHA-1:输出160位哈希值;(不安全)
- SHA-2系列:SHA-224、SHA-256、SHA-384、SHA-512,输出长度分别为224/256/384/512位,安全性高。
安装了openssl之后,可以通过命令行进行加密:
字符串加密方式:echo "【待加密的字符串】" |openssl dgst -sha256
文件加密方式: openssl dgst -sha256 【文件路径】篇外:国密GMSSL是openssl的一个分支。
场景应用
1.标准库std::hash
我们有一堆需要归类管理(实体/虚拟)的“东西”,比如书籍、用户信息等。下面以书架管理系统为案例,设计一个性能高效解决方案。
需求场景
图书室有上万本书需要上架,划分为5个区域进行摆放。
设计思路
书籍的关键特征是书名(+作者)不同,需要把书名转换成编号,并对编号划分到5个区域中。书名<->编号,这是典型的k-v映射规则特性,把书名变成数字编号之后,即可通过运算规则划分为5个区域。
根据以上思路,选择std::hash进行实现的原因如下:
- std::hash支持对字符串(包括中文)输出固定长度的数值(64位系统输出的是8字节),用此数值进行%5计算即可分成5个区域
- std::hash是散列算法,“东西”越多,越是均匀分布(即5个区域内的“东西”数量趋向于总数/5)
代码实现
以下提供的功能为:
1、程序启动时,从存储文件中加载历史存储的数据;
2、程序以传参方式执行保存、查询的功能;
//stdhash.cpp
#include <iostream>
#include <fstream>
#include <vector>
#include <string>
#include <algorithm>
#include <functional> // std::hashclass BookshelfSystem {
public:struct Bookshelf {std::string shelf_id;std::string book_name;};BookshelfSystem() {if (loadData()) {std::cout << "系统初始化完成,已加载 " << m_shelves.size()<< " 条书籍记录" << std::endl;} else {std::cout << "未找到数据文件,已创建新存储" << std::endl;}}// 添加书籍(带重复检测和自动保存)void addBook(const std::string& book_name) {auto it = std::find_if(m_shelves.begin(), m_shelves.end(),[&book_name](const Bookshelf& entry) {return entry.book_name == book_name;});if (it != m_shelves.end()) {std::cout << "《" << book_name << "》已存在于书架: "<< it->shelf_id << std::endl;return;}Bookshelf new_entry;new_entry.book_name = book_name;new_entry.shelf_id = getShelfId(book_name);m_shelves.push_back(new_entry);saveData();std::cout << "《" << book_name << "》已添加到书架: "<< new_entry.shelf_id << std::endl;}// 查询书籍位置或推荐书架void queryBook(const std::string& book_name) const {auto it = std::find_if(m_shelves.begin(), m_shelves.end(),[&book_name](const Bookshelf& entry) {return entry.book_name == book_name;});if (it != m_shelves.end()) {std::cout << "书籍《" << book_name << "》位于书架: "<< it->shelf_id << std::endl;} else {std::string shelf_id = getShelfId(book_name);std::cout << "书籍《" << book_name << "》可编入书架: "<< shelf_id << std::endl;}}private:std::vector<Bookshelf> m_shelves;static const std::vector<std::string> SHELF_IDS;static const std::string DATA_FILE;// 从二进制文件加载数据bool loadData() {std::ifstream file(DATA_FILE, std::ios::binary);if (!file) return false;m_shelves.clear();while (true) {Bookshelf entry;size_t id_size, name_size;// 读取书架编号file.read(reinterpret_cast<char*>(&id_size), sizeof(id_size));if (file.eof()) break;entry.shelf_id.resize(id_size);file.read(&entry.shelf_id[0], id_size);// 读取书籍名称file.read(reinterpret_cast<char*>(&name_size), sizeof(name_size));entry.book_name.resize(name_size);file.read(&entry.book_name[0], name_size);m_shelves.push_back(entry);}return true;}// 保存数据到二进制文件void saveData() const {std::ofstream file(DATA_FILE, std::ios::binary);for (const auto& entry : m_shelves) {// 写入书架编号size_t id_size = entry.shelf_id.size();file.write(reinterpret_cast<const char*>(&id_size), sizeof(id_size));file.write(entry.shelf_id.data(), id_size);// 写入书籍名称size_t name_size = entry.book_name.size();file.write(reinterpret_cast<const char*>(&name_size), sizeof(name_size));file.write(entry.book_name.data(), name_size);}}// 哈希计算书架编号std::string getShelfId(const std::string& book_name) const {std::hash<std::string> hasher;size_t hash_value = hasher(book_name);return SHELF_IDS[hash_value % SHELF_IDS.size()];}
};// 静态成员初始化
const std::vector<std::string> BookshelfSystem::SHELF_IDS ={"A1", "B2", "C3", "D4", "E5"};
const std::string BookshelfSystem::DATA_FILE = "bookshelf.bin";// 示例用法
int main(int argc, char* argv[]) {BookshelfSystem system;// 参数校验if (argc < 3) {std::cerr << "用法: \n"<< " 添加书籍: " << argv[0] << " save \"书名\"\n"<< " 查询书籍: " << argv[0] << " query \"书名\"\n";return 1;}const std::string command = argv[1];const std::string book_name = argv[2];// 命令路由if (command == "save") {system.addBook(book_name);} else if (command == "query") {system.queryBook(book_name);} else {std::cerr << "无效命令,支持命令: save, query\n";return 2;}return 0;
}
编译命令
g++ stdhash.cpp -ostdhash运行效果:
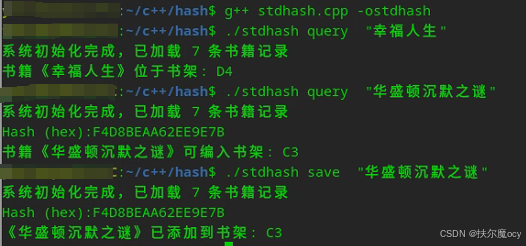
2.STL容器std::unordered_map
我们有一堆需要归类管理(实体/虚拟)的“东西”,比如书籍、用户信息等。下面以书架管理系统为例详细讲解。
需求场景
每天有过亿条用户行为数据(如购物流水、户外活动等),按用户进行去重,有上千万条用户数据,用户可查看最近一个月的历史行为数据。下面以历史查询系统为案例,设计一个性能高效解决方案。
设计思路
这是一个典型的数据量大,且高频单点查询的需求,使用快速检索引擎(比如elasticsearch)可以满足需求,但耗性能(内存和CPU),以下给出的是提供性能的思路:
- 上千万条数据加载到内存,至少占用700M以上的内存(一个月21G),如果能拆成10份,仅在查询时加载目标数据的那一份,则内存仅占用70M(一个月2G);
- 要满足微妙级的快速检索要求。
根据以上思路,选择std::unordered_map进行实现的原因如下:
- 平均时间复杂度为 O(1),能满足微妙级检索到数据的要求;
- 内存占用低,是无序哈希表,不需要维护(有序)树形结构的花销,性能高;
代码实现
以下实际功能的实现思路如下:
1、以结构体方式进行交互,内容包括:手机号(唯一值)、姓名、性别等;
2、生成100万条随机非连续手机号数据,并写入到二进制文件中保存;(二进制文件读写效率高)
3、以内存映射方式加载bin文件的数据到虚拟内存地址空间;(内存映射方式比IO操作高效)
4、构建index_map索引map,把哈希值<->用户数据,通过unordered_map加载到物理内存;
5、查询用户信息时,通过index_map索引map,获取到用户信息。
//hash_query.cpp
#include <iostream>
#include <fstream>
#include <string>
#include <chrono>
#include <sys/mman.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <unistd.h>
#include <cstring>#include <unordered_map>
#include <random>using namespace std;
using namespace chrono;//unordered_map 的底层采用哈希表结构,通过哈希函数将键(Key)映射到存储位置(无序),适合高频单点查询场景,平均常数时间复杂度O(1)
//std::map 的底层采用红黑树结构,适合需要键有序或范围查询场景,平均常数时间复杂度O(log n)#pragma pack(push, 1)
struct Record {long long phone; // 8字节char name[60]; // UTF-8姓名(30个汉字)char gender[4]; // 性别(1个汉字)
};
#pragma pack(pop)// 生成随机非连续手机号
long long generate_phone(mt19937_64& gen, unordered_map<long long, bool>& exists) {uniform_int_distribution<long long> dist(13300000000LL, 13399999999LL);while(true) {long long phone = dist(gen);if(!exists[phone]) {exists[phone] = true;return phone;}}
}// 生成二进制数据文件
void generate_data(const string& filename, int num) {ofstream file(filename, ios::binary | ios::trunc);unordered_map<long long, bool> exists;random_device rd;mt19937_64 gen(rd());for(int i=0; i<num; ++i) {Record record;record.phone = generate_phone(gen, exists);// 生成UTF-8中文数据//string name = "用户_" + to_string(i+1);string name = "用户_" + to_string(record.phone);strncpy(record.name, name.c_str(), sizeof(record.name)-1);record.name[sizeof(record.name)-1] = '\0';string gender = (i%2 ==0) ? "男" : "女";strncpy(record.gender, gender.c_str(), sizeof(record.gender)-1);record.gender[sizeof(record.gender)-1] = '\0';file.write(reinterpret_cast<char*>(&record), sizeof(Record));}cout << "生成数据完成,文件大小:"<< (num*sizeof(Record))/(1024.0*1024.0) << "MB" << endl;
}// 历史查询系统
class PhoneQuery {
private:// 添加哈希表配置参数static constexpr float LOAD_FACTOR = 0.75f; // 负载因子阈值,默认值是1.0 --减少哈希冲突static constexpr size_t BUCKET_MULTIPLIER = 2; // 桶数扩展倍数(经验值1.5-3倍)--预先分配足够的桶空间,避免插入时多次扩容:值越大,占用内存越多,查询速度越快Record* records = nullptr;void* mapped = MAP_FAILED;size_t file_size = 0;unordered_map<long long, size_t> index_map; // phone到索引的映射--哈希表public:explicit PhoneQuery(const string& filename) {auto start = high_resolution_clock::now();// 打开文件int fd = open(filename.c_str(), O_RDONLY);if(fd == -1) throw runtime_error("文件打开失败");// 获取文件大小struct stat sb;if(fstat(fd, &sb) == -1) throw runtime_error("获取文件大小失败");file_size = sb.st_size;// 内存映射--加载到虚拟内存地址空间mapped = mmap(nullptr, file_size, PROT_READ, MAP_SHARED, fd, 0);if(mapped == MAP_FAILED) throw runtime_error("内存映射失败");close(fd);// 构建索引--加载到物理内存records = static_cast<Record*>(mapped);const size_t num_records = file_size / sizeof(Record);// 计算初始桶容量(根据负载因子优化)size_t initial_buckets = num_records * BUCKET_MULTIPLIER;index_map.reserve(initial_buckets); // 预分配内存index_map.max_load_factor(LOAD_FACTOR); // 设置负载因子for(size_t i=0; i<num_records; ++i) {index_map[records[i].phone] = i;}std::cout << "加载数据数量:" << num_records << std::endl;auto duration = duration_cast<milliseconds>(high_resolution_clock::now() - start);cout << "加载耗时:" << duration.count() << "毫秒" << endl;}~PhoneQuery() {if(mapped != MAP_FAILED) {munmap(mapped, file_size);//释放虚拟内存地址空间和物理内存}}void query(long long phone) const {auto start = high_resolution_clock::now();if(auto it = index_map.find(phone); it != index_map.end()) {const Record& data = records[it->second];auto duration = duration_cast<microseconds>(high_resolution_clock::now() - start);cout << "手机号:" << data.phone << "\n"<< "姓名:" << data.name << "\n"<< "性别:" << data.gender << "\n"<< "查询耗时:" << duration.count() << "微秒" << endl;} else {auto duration = duration_cast<microseconds>(high_resolution_clock::now() - start);cout << "手机号不存在\n"<< "查询耗时:" << duration.count() << "微秒" << endl;}}
};int main() {const string filename = "phone_data.bin";// 检查文件是否存在if (access(filename.c_str(), F_OK) != 0) {cout << "生成测试数据文件:"<< filename << endl;// 生成测试数据(首次运行需要执行)const int DATA_SIZE = 1000000; // 百万数据generate_data(filename, DATA_SIZE);}try {PhoneQuery pro(filename);long long input;cout << "请输入查询手机号: ";cin >> input;pro.query(input);} catch(const exception& e) {cerr << "系统错误: " << e.what() << endl;return 1;}return 0;
}编译命令:
g++ -std=c++17 -O3 hash_query.cpp -o hash_query运行效果:
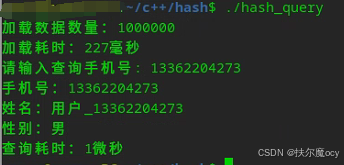
说明
百万级别的数据,map比unordered_map耗时多几十倍,都是微秒级,差别不是很大,如果分成了很多个这样的块,是可以进行优化的。
3.加密哈希
场景1是对书籍进行编码和上架,如果书籍是电子书籍,那么对文件内容进行编码,比对书籍名称进行编码更加能准确表达是否是同一本数。此时可以用openssl的md5算法批量求取hash值,生成到一个文本文件中。(虽然md5不安全,但当前的场景不涉及安全性)
openssl dgst -md5 filepath另外,以上的特性也可以用于对文件进行去重瘦身,以下提供一个开源的文件去重工具:
dedup_files
结尾
以上仅列举C++常用的函数、容器,主要是提供优化的思路,即使是相同的代码,数据量不同,反映出来的性能也不同,需要自己尝试及优化。