- 论文:https://arxiv.org/pdf/2402.03216
- 代码:GitHub - FlagOpen/FlagEmbedding: Retrieval and Retrieval-augmented LLMs
- 机构:BAAI
- 领域:embedding model
- 发表:

研究背景
- 研究问题:这篇文章要解决的问题是如何设计一种多语言、多功能、多粒度的文本嵌入模型,以支持超过100种工作语言的语义检索,并能同时完成密集检索、多向量检索和稀疏检索等多种检索功能。
- 研究难点:该问题的研究难点包括:现有方法在多语言支持、多功能集成和长文档处理方面的局限性;如何在训练过程中有效地整合不同检索功能的相关性分数;如何优化批处理策略以提高嵌入的判别力。
- 相关工作:该问题的研究相关工作包括预训练语言模型的发展、对比学习的进步以及多功能嵌入模型的探索,如Contriever、LLM-Embedder、E5、BGE、SGPT和Open Text Embedding等。
研究方法
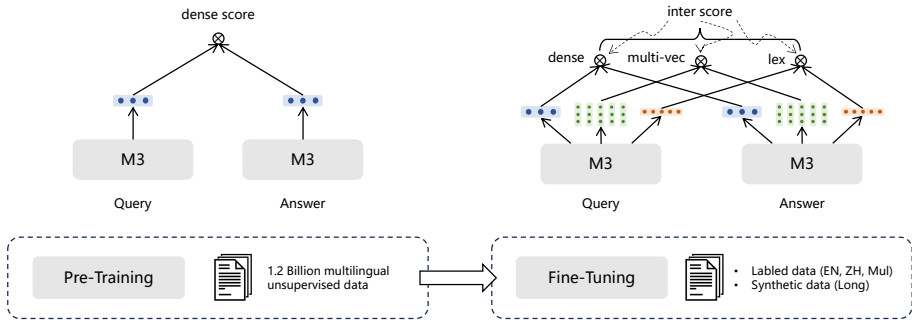
这篇论文提出了M3-Embedding模型,用于解决多语言、多功能、多粒度文本嵌入的问题。具体来说,
- 数据收集与预处理:首先,从大规模的多语言语料库中提取无监督数据,并从标注语料库中收集相对较小但多样且高质量的微调数据。此外,通过合成稀缺的长文档检索任务数据来补充数据集。
- 混合检索:M3-Embedding统一了文本嵌入模型的常见检索功能,包括密集检索、词汇(稀疏)检索和多向量检索。其公式如下:
- 密集检索:使用特殊标记"[CLS]"的隐藏状态表示查询,计算查询和段落嵌入的内积。
- 词汇检索:计算查询中每个词的重要性权重,基于共现词的重要性计算查询和段落的相关性分数。
- 多向量检索:利用整个输出嵌入表示查询和段落,使用晚期交互计算细粒度的相关性分数。
- 最终的综合相关性分数:

w1,w2,w3 的值取决于下游场景。
- 自知识蒸馏:提出了一种新的自知识蒸馏框架,将不同检索功能的相关性分数作为教师信号,增强学习过程。具体公式如下:
- 原始损失函数:

- 综合损失函数:

- 最终的自知识蒸馏损失函数:

- 原始损失函数:
- 高效批处理:通过优化批处理策略,实现大批量和高效训练。具体方法包括按序列长度分组数据、使用梯度检查点技术以及跨GPU广播。
实验设计
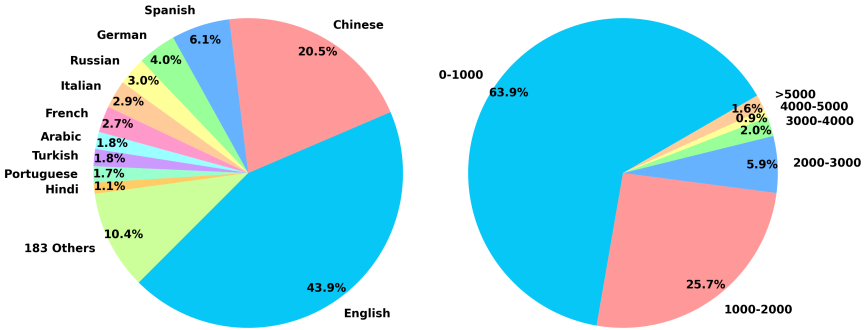
- 数据收集:从多个来源收集大规模的多语言数据,包括无监督数据、标注数据和合成数据。无监督数据来自维基百科、S2ORC、xP3、mC4和CC-News等语料库;标注数据来自HotpotQA、TriviaQA、NQ、MS MARCO、COL-IEE、PubMedQA、SQuAD和SimCSE等数据集;合成数据通过采样维基百科、Wudao和mC4中的长篇文章并生成问题。
- 实验设置:采用XLM-RoBERTa作为基础模型,扩展最大位置到8192,并通过RetroMAE方法进行预训练。预训练数据包括Pile、Wudao和mC4数据集,共覆盖105种语言。微调阶段使用7个负样本进行训练,初始阶段进行约6000步的预热训练,随后进行统一的自知识蒸馏训练。
结果与分析
-
多语言检索:在MIRACL数据集上的实验结果表明,M3-Embedding在仅使用密集检索功能时,已经优于其他基线方法。稀疏检索和多向量检索进一步提升了性能,最终的综合检索方法(All)表现最佳。
-
跨语言检索:在Mrowka数据集上的实验结果显示,M3-Embedding在仅使用密集检索功能时,也显著优于其他基线方法。不同检索方法的结合进一步提升了跨语言检索的性能。
-
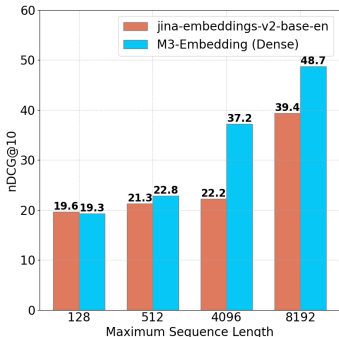
多语言长文档检索:在MLDR和NarrativeQA数据集上的实验结果表明,M3-Embedding在长文档检索任务中表现出色,尤其是稀疏检索方法(Sparse)和多向量检索方法(Multi-vec)。
-
消融研究:自知识蒸馏和多阶段训练的消融实验表明,自知识蒸馏显著提高了稀疏检索的性能,多阶段训练则进一步提升了整体检索质量。
总体结论
这篇论文提出的M3-Embedding模型在多语言检索、跨语言检索和多语言长文档检索任务中表现出色,展现了前所未有的多功能性和高效性。通过自知识蒸馏、高效批处理和高质数据预处理,M3-Embedding实现了优越的检索性能,并为未来的文本嵌入研究和应用提供了重要的资源。
论文评价
优点与创新
- 多语言支持:M3-Embedding能够支持超过100种工作语言,实现了跨语言的多语言检索和跨语言的检索。
- 多功能性:该模型不仅支持密集检索,还能进行稀疏检索和多向量检索,满足了不同的检索需求。
- 多粒度处理:M3-Embedding能够处理从短句子到长达8192个词的文档,适应了不同长度的输入数据。
- 自知识蒸馏:提出了一种新的自知识蒸馏方法,通过将不同检索功能的相关性分数作为教师信号来增强训练质量。
- 高效的批处理策略:优化了批处理策略,实现了大批次和高吞吐量训练,提高了嵌入的判别力。
- 高质量的数据集:进行了广泛且高质量的数据收集和整理,包括无监督数据、标注数据的微调和合成数据的生成。
- 实验验证:在多个多语言、跨语言和长文档检索基准上取得了最新的实验结果。
不足与反思
- 泛化能力:尽管在MIRACL和 MKVQA等流行的多语言和跨语言基准上取得了最新的实验结果,但该方法在不同数据集和实际场景中的泛化能力需要进一步研究。
- 长文档处理:虽然M3-Embedding能够处理长达8192个词的文档,但在处理极长文档时可能会面临计算资源和模型效率的挑战。对于超过指定标记限制的长文档或文档的性能需要进一步研究。
- 语言性能差异:虽然M3-Embedding声称支持超过100种工作语言,但对不同语言性能的潜在变化没有进行深入的讨论。需要在更广泛的范围内对更多语言进行分析和评估,以理解模型在不同语言家族和语言特征下的鲁棒性和有效性。
关键问题及回答
问题1:M3-Embedding模型在数据收集与预处理方面有哪些具体的策略?
- 无监督数据:从大规模的多语言语料库中提取无监督数据,包括维基百科、S2ORC、xP3、mC4和CC-News等语料库。这些数据被用来提取丰富的语义结构,如标题-正文、标题-摘要、指令-输出等。
- 标注数据:从多个标注数据集中收集相对较小但多样且高质量的微调数据。对于英语,使用了HotpotQA、TriviaQA、NQ、MS MARCO、COL-IEE、PubMedQA、SQuAD和SimCSE等数据集;对于中文,使用了DuReader、mMARCO-ZH、T2-Ranking、LawGPT、CMedQAv2、NLI-zh2和LeCaRDv2等数据集;对于其他语言,使用了Mr.TyDi和MIRACL等数据集。
- 合成数据:通过采样维基百科、Wudao和mC4中的长篇文章并生成问题,以补充长文档检索任务的稀缺数据。具体方法是随机选择段落并使用GPT-3.5生成问题,生成的问题和采样的文章构成新的文本对用于微调数据。
问题2:M3-Embedding模型如何实现混合检索功能,并且如何计算最终的综合相关性分数?
M3-Embedding模型实现了三种常见的检索功能:密集检索、词汇(稀疏)检索和多向量检索。具体实现方式如下:
- 密集检索:使用特殊标记"[CLS]"的隐藏状态表示查询,计算查询和段落嵌入的内积。公式如下:
- 词汇检索:计算查询中每个词的重要性权重,基于共现词的重要性计算查询和段落的相关性分数。公式如下:
- 多向量检索:利用整个输出嵌入表示查询和段落,使用晚期交互计算细粒度的相关性分数。公式如下:
问题3:M3-Embedding模型在自知识蒸馏方面有哪些创新,这些创新如何提高模型的性能?

这些创新使得不同检索功能的相关性分数可以相互补充,增强了模型的泛化能力和学习效果,特别是在稀疏检索方面表现尤为显著。















![byte[]/InputStream/MultipartFile之间进行转换](https://i-blog.csdnimg.cn/direct/d99b163a318b4c61b949d8f2452ca65d.png)



