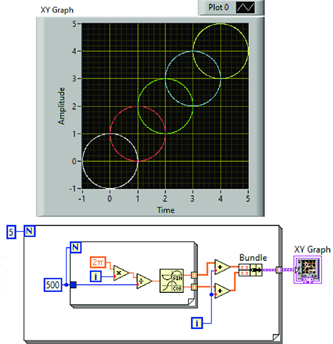
RNN
1. 概述
循环神经网络 (Recurrent Neural Network, RNN) 是一种专门用于处理序列数据的神经网络模型。与传统的前馈神经网络不同,RNN 具有循环结构,能够处理时间序列和其他顺序依赖的数据。其关键在于可以利用前一个时刻的信息,通过隐状态 (Hidden State) 在时间步长上进行传递,从而具有记忆性。
2. RNN 的基本结构
RNN的核心在于处理序列数据时,每个时间步 (time step) 的输入不仅会影响当前的输出,还会影响下一时间步的输入。其网络结构如下:
-
输入层 (Input Layer):序列数据中的每个元素会逐步输入神经网络,每个时间步对应一个输入。
-
隐藏层 (Hidden Layer):在每个时间步,隐藏层的输出不仅依赖当前的输入,还依赖前一时间步的隐藏层状态。隐藏状态通过时间步传播,从而使网络具备记忆力。
-
输出层 (Output Layer):每个时间步的输出可以是即时的(每个时间步输出),或者在最后的时间步产生整体输出。
3.相关代码实现
使用 PyTorch 来实现一个基本的 RNN 模型,并应用于文本分类任务(例如,情感分类)。代码包括数据预处理、模型构建、训练和分析。
1. 数据预处理
在文本处理中,我们通常需要将文本数据转换为数值形式,如单词的索引或词向量。为了简化,将使用 TorchText 来处理文本数据。
数据预处理示例代码:
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.legacy import data, datasets
# 设置随机种子以确保结果可重复
torch.manual_seed(1234)
# 定义字段,TEXT 用于存储文本数据,LABEL 用于存储标签
TEXT = data.Field(tokenize='spacy', tokenizer_language='en_core_web_sm', include_lengths=True)
LABEL = data.LabelField(dtype=torch.float)
# 加载IMDB数据集,数据集包含影评文本和情感标签
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
# 构建词汇表,使用预训练的词向量(GloVe)
TEXT.build_vocab(train_data, max_size=25000, vectors="glove.6B.100d", unk_init=torch.Tensor.normal_)
LABEL.build_vocab(train_data)
# 创建迭代器
BATCH_SIZE = 64
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator, test_iterator = data.BucketIterator.splits((train_data, test_data), batch_size=BATCH_SIZE, sort_within_batch=True,device=device)
2. RNN 模型定义
下面的代码定义了一个基本的 RNN 模型。使用一个嵌入层和一个简单的 RNN 层来对文本进行分类。输出的隐藏状态将传递到全连接层来预测情感标签。
模型定义代码:
class RNN(nn.Module):def __init__(self, input_dim, embedding_dim, hidden_dim, output_dim, n_layers, bidirectional, dropout):super().__init__()# 嵌入层self.embedding = nn.Embedding(input_dim, embedding_dim)# RNN层self.rnn = nn.RNN(embedding_dim, hidden_dim, num_layers=n_layers, bidirectional=bidirectional, dropout=dropout)# 全连接层self.fc = nn.Linear(hidden_dim * 2 if bidirectional else hidden_dim, output_dim)# Dropoutself.dropout = nn.Dropout(dropout)def forward(self, text, text_lengths):# text: [sent_len, batch_size]# 嵌入embedded = self.dropout(self.embedding(text))# 打包,RNN 可以处理不同长度的序列packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_lengths.to('cpu'))packed_output, hidden = self.rnn(packed_embedded)# 解包output, output_lengths = nn.utils.rnn.pad_packed_sequence(packed_output)# 只使用最后的隐藏状态hidden = self.dropout(hidden[-1,:,:])return self.fc(hidden)
# 初始化模型
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
HIDDEN_DIM = 256
OUTPUT_DIM = 1
N_LAYERS = 2
BIDIRECTIONAL = True
DROPOUT = 0.5
model = RNN(INPUT_DIM, EMBEDDING_DIM, HIDDEN_DIM, OUTPUT_DIM, N_LAYERS, BIDIRECTIONAL, DROPOUT)
3. 模型训练
接下来定义损失函数和优化器,并进行模型的训练。由于这是一个二分类问题,使用二元交叉熵损失函数。
训练代码:
# 使用预训练的词向量初始化嵌入层
pretrained_embeddings = TEXT.vocab.vectors
model.embedding.weight.data.copy_(pretrained_embeddings)
# 定义损失函数和优化器
optimizer = optim.Adam(model.parameters())
criterion = nn.BCEWithLogitsLoss()
model = model.to(device)
criterion = criterion.to(device)
# 计算准确率
def binary_accuracy(preds, y):rounded_preds = torch.round(torch.sigmoid(preds))correct = (rounded_preds == y).float()acc = correct.sum() / len(correct)return acc
# 训练函数
def train(model, iterator, optimizer, criterion):epoch_loss = 0epoch_acc = 0model.train()for batch in iterator:optimizer.zero_grad()text, text_lengths = batch.textpredictions = model(text, text_lengths).squeeze(1)loss = criterion(predictions, batch.label)acc = binary_accuracy(predictions, batch.label)loss.backward()optimizer.step()epoch_loss += loss.item()epoch_acc += acc.item()return epoch_loss / len(iterator), epoch_acc / len(iterator)
# 测试函数
def evaluate(model, iterator, criterion):epoch_loss = 0epoch_acc = 0model.eval()with torch.no_grad():for batch in iterator:text, text_lengths = batch.textpredictions = model(text, text_lengths).squeeze(1)loss = criterion(predictions, batch.label)acc = binary_accuracy(predictions, batch.label)epoch_loss += loss.item()epoch_acc += acc.item()return epoch_loss / len(iterator), epoch_acc / len(iterator)
# 开始训练
N_EPOCHS = 5
for epoch in range(N_EPOCHS):train_loss, train_acc = train(model, train_iterator, optimizer, criterion)test_loss, test_acc = evaluate(model, test_iterator, criterion)print(f'Epoch: {epoch+1}')print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')print(f'\tTest Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%')
4. 模型分析
通过训练和测试结果,可以观察模型在情感分类任务上的表现。进一步使用混淆矩阵、分类报告等工具来分析模型性能。
模型分析示例代码:
from sklearn.metrics import classification_report
# 预测函数
def predict_sentiment(model, sentence):model.eval()tokenized = [tok.text for tok in nlp.tokenizer(sentence)]indexed = [TEXT.vocab.stoi[t] for t in tokenized]length = [len(indexed)]tensor = torch.LongTensor(indexed).to(device)tensor = tensor.unsqueeze(1)length_tensor = torch.LongTensor(length)prediction = torch.sigmoid(model(tensor, length_tensor))return prediction.item()
# 示例测试
test_sentence = "This movie is absolutely wonderful!"
prediction = predict_sentiment(model, test_sentence)
print(f"Sentiment score: {prediction}")
5. 代码分析
-
数据预处理:使用
TorchText来加载数据,并将文本数据转换为索引。我们使用 GloVe 预训练词向量来初始化嵌入层。 -
RNN 模型:定义了一个带双向(Bidirectional)的 RNN 模型。该模型包含嵌入层、RNN 层和全连接层,用于情感分类任务。
-
模型训练:使用 Adam 优化器和二元交叉熵损失函数对模型进行训练,并通过准确率评估性能。
-
模型分析:可以通过预测情感分数来进一步分析模型的表现。
通过这些步骤,实现了一个完整的文本处理流水线,使用 RNN 对影评数据进行情感分类。