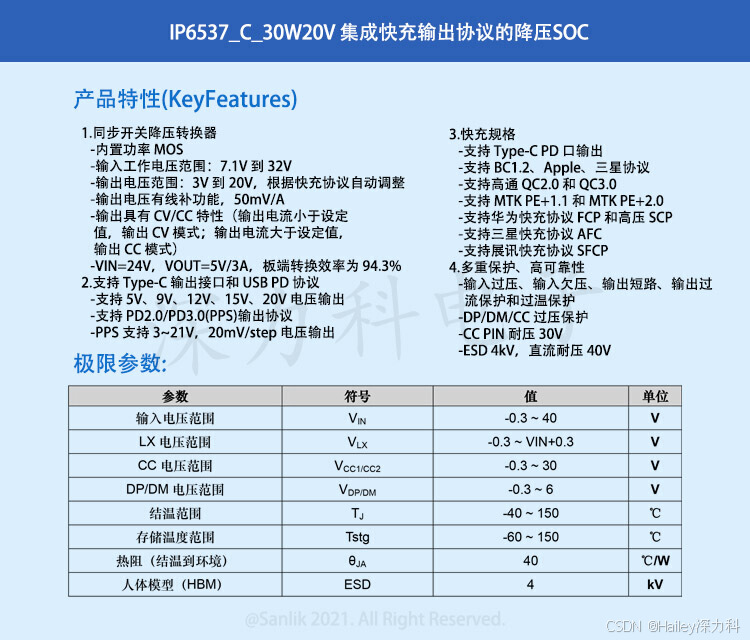
图神经网络实战——分层自注意力网络
- 0. 前言
- 1. 分层自注意力网络
- 1.1 模型架构
- 1.2 节点级注意力
- 1.3 语义级注意力
- 1.4 预测模块
- 2. 构建分层自注意力网络
- 相关链接
0. 前言
在异构图数据集上,异构图注意力网络的测试准确率为 78.39%,比之同构版本有了较大提高,但我们还能进一步提高准确率。在本节中,我们将学习一种专门用于处理异构图的图神经网络架构,分层自注意力网络 (hierarchical self-attention network, HAN)。我们将介绍其工作原理,以便更好地理解该架构与经典图注意力网络 (Graph Attention Networks,GAT) 之间的区别。最后,使用 PyTorch Geometric 实现此架构,并将结果与其它 GNN 模型进行比较。
1. 分层自注意力网络
1.1 模型架构
在本节中,我们将实现一个专为处理异构图而设计的图神经网络 (Graph Neural Networks, GNN) 模型——分层自注意力网络 (hierarchical self-attention network, HAN)。该架构由 Liu 等人于 2021 年提出。HAN 在两个不同层次上使用自注意力:
- 节点级注意力 (
Node-level attention):了解给定元路径中相邻节点的重要性 - 语义级注意力 (
Semantic-level attention):了解每个元路径的重要性。这是HAN的主要特点,它允许我们自动为给定任务选择最佳元路径。例如,在某些任务(如预测玩家人数)中,元路径game-user-game可能比game-dev-game更合适
接下来,我们将详细介绍 HAN 的三个主要组件——节点级注意力 (Node-level attention)、语义级注意力 (Semantic-level attention) 和预测模块 (prediction module),HAN 架构如下所示。
 )
)
1.2 节点级注意力
与图注意力网络 (Graph Attention Networks,GAT) 一样,第一步将节点投影到每个元路径的统一特征空间中。然后,用第二个权重矩阵计算同一元路径中的节点对(两个投影节点的连接)的权重,并对这一结果应用非线性函数,然后用 softmax 函数对其进行归一化处理。 j j j 节点对 i i i 节点的归一化注意力分数(重要性)计算如下:
α i j Φ = exp ( σ ( a Φ T [ W Φ h i ∣ ∣ W Φ h j ] ) ) ∑ k ∈ N i Φ exp ( σ ( a Φ T [ W Φ h i ∣ ∣ W Φ h k ] ) ) \alpha_{ij}^\Phi =\frac {\exp (\sigma(a_{\Phi}^T[W_{\Phi}h_i||W_{\Phi}h_j]))}{\sum _{k\in \mathcal N_i^{\Phi}}\exp(\sigma(a_{\Phi}^T[W_{\Phi}h_i||W_{\Phi}h_k]))} αijΦ=∑k∈NiΦexp(σ(aΦT[WΦhi∣∣WΦhk]))exp(σ(aΦT[WΦhi∣∣WΦhj]))
其中, h i h_i hi 表示 i i i 节点的特征, W Φ W_{\Phi} WΦ 是 Φ \Phi Φ 元路径的共享权重矩阵, a Φ a_{\Phi} aΦ 是 Φ \Phi Φ 元路径的注意力权重矩阵, σ σ σ 是非线性激活函数(如 LeakyReLU), N i Φ \mathcal N_i^{\Phi} NiΦ 是节点(包括其自身)在 Φ \Phi Φ 元路径中的邻居集。使用多头注意力获得最终的嵌入:
Z i = ∣ ∣ k = 1 K σ ( ∑ k ∈ N i α i j Φ ⋅ W Φ h j ) Z_i=||_{k=1}^K\sigma(\sum _{k\in \mathcal N_i}\alpha _{ij}^{\Phi}\cdot W_{\Phi}h_j) Zi=∣∣k=1Kσ(k∈Ni∑αijΦ⋅WΦhj)
1.3 语义级注意力
对于语义级注意力,我们对每个元路径的注意力得分(表示为 β Φ 1 , β Φ 2 , . . . , β Φ p β_{\Phi _1}, β_{\Phi _2}, ... , β_{\Phi _p} βΦ1,βΦ2,...,βΦp )重复类似的过程。对于给定元路径中的每个节点嵌入(表示为 Z Φ p Z_{\Phi _p} ZΦp),都将其馈送到一个多层感知机 (Multilayer Perceptron, MLP) 中,应用非线性变换。将这一结果与新的注意力向量 q q q 进行比较,作为相似性度量。我们将这一结果平均化,以计算给定元路径的重要性:
w Φ p = 1 ∣ V ∣ ∑ i ∈ V q T ⋅ tanh ( W ⋅ z i Φ p + b ) w_{\Phi_p}=\frac 1{|V|}\sum_{i\in V}q^T\cdot \tanh(W\cdot z_i^{\Phi_p}+b) wΦp=∣V∣1i∈V∑qT⋅tanh(W⋅ziΦp+b)
其中, W W W (MLP 的权重矩阵)、 b b b (MLP 的偏置)和 q q q (语义级注意力向量)在元路径中是共享的。
必须对这一结果进行归一化处理,以比较不同的语义级注意力得分。使用 softmax 函数来获得最终权重:
β Φ p = exp ( w Φ p ) ∑ k = 1 P exp ( w Φ k ) \beta _{\Phi_p}=\frac {\exp(w_{\Phi_p})}{\sum_{k=1}^P\exp(w_{\Phi_k})} βΦp=∑k=1Pexp(wΦk)exp(wΦp)
将节点级注意力和语义级注意力结合起来得到最终嵌入 Z Z Z:
Z = ∑ p = 1 P β Φ p ⋅ Z Φ p Z=\sum_{p=1}^P\beta_{\Phi_p}\cdot Z_{\Phi_p} Z=p=1∑PβΦp⋅ZΦp
1.4 预测模块
最后一层(如多层感知机 (Multilayer Perceptron, MLP) )用于针对特定的下游任务(如节点分类或链接预测)对模型进行微调。
2. 构建分层自注意力网络
接下来,使用 PyTorch Geometric 在 DBLP 数据集上实现分层自注意力网络 (hierarchical self-attention network, HAN) 架构。
(1) 首先,导入 HAN 层:
import torch
import torch.nn.functional as F
from torch import nnimport torch_geometric.transforms as T
from torch_geometric.datasets import DBLP
from torch_geometric.nn import HANConv, Linear
(2) 加载 DBLP 数据集,并为会议节点引入虚拟特征:
dataset = DBLP('.')
data = dataset[0]
print(data)data['conference'].x = torch.zeros(20, 1)

(3) 使用 HANConv 的 HAN 卷积层和用于最终分类的线性层创建 HAN 类:
class HAN(nn.Module):def __init__(self, dim_in, dim_out, dim_h=128, heads=8):super().__init__()self.han = HANConv(dim_in, dim_h, heads=heads, dropout=0.6, metadata=data.metadata())self.linear = nn.Linear(dim_h, dim_out)
(4) 在 forward() 方法中,我们必须指定需要关注作者:
def forward(self, x_dict, edge_index_dict):out = self.han(x_dict, edge_index_dict)out = self.linear(out['author'])return out
(5) 使用懒初始化 (dim_in=-1) 来初始化模型,因此 PyTorch Geometric 会自动计算每个节点类型的输入大小:
model = HAN(dim_in=-1, dim_out=4)
(6) 实例化 Adam 优化器,并尝试将数据和模型传输到 GPU:
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, weight_decay=0.001)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
data, model = data.to(device), model.to(device)
(7) 实现 test() 函数计算分类任务的准确率:
@torch.no_grad()
def test(mask):model.eval()pred = model(data.x_dict, data.edge_index_dict).argmax(dim=-1)acc = (pred[mask] == data['author'].y[mask]).sum() / mask.sum()return float(acc)
(8) 对模型进行 101 个 epoch 的训练,与同构图神经网络 (Graph Neural Networks, GNN) 的训练循环唯一不同的是,需要指定关注的作者节点类型:
for epoch in range(101):model.train()optimizer.zero_grad()out = model(data.x_dict, data.edge_index_dict)mask = data['author'].train_maskloss = F.cross_entropy(out[mask], data['author'].y[mask])loss.backward()optimizer.step()if epoch % 20 == 0:train_acc = test(data['author'].train_mask)val_acc = test(data['author'].val_mask)print(f'Epoch: {epoch:>3} | Train Loss: {loss:.4f} | Train Acc: {train_acc*100:.2f}% | Val Acc: {val_acc*100:.2f}%')
训练过程如下:

(9) 最后,在测试集上测试训练后的模型:
test_acc = test(data['author'].test_mask)
print(f'Test accuracy: {test_acc*100:.2f}%')# Test accuracy: 81.58%
HAN 的测试准确率为 81.58%,高于异构图注意力网络 (78.39%)和经典图注意力网络 (Graph Attention Networks,GAT) (73.29%)。这说明了构建良好的表示方法以聚合不同类型节点和关系的重要性。异构图的技术在很大程度上取决于具体应用,但尝试不同的模型对于构建高性能应能具有重要作用。
相关链接
图神经网络实战(1)——图神经网络(Graph Neural Networks, GNN)基础
图神经网络实战(6)——使用PyTorch构建图神经网络
图神经网络实战(7)——图卷积网络(Graph Convolutional Network, GCN)详解与实现
图神经网络实战(8)——图注意力网络(Graph Attention Networks, GAT)
图神经网络实战(12)——图同构网络(Graph Isomorphism Network, GIN)
图神经网络实战(18)——消息传播神经网络