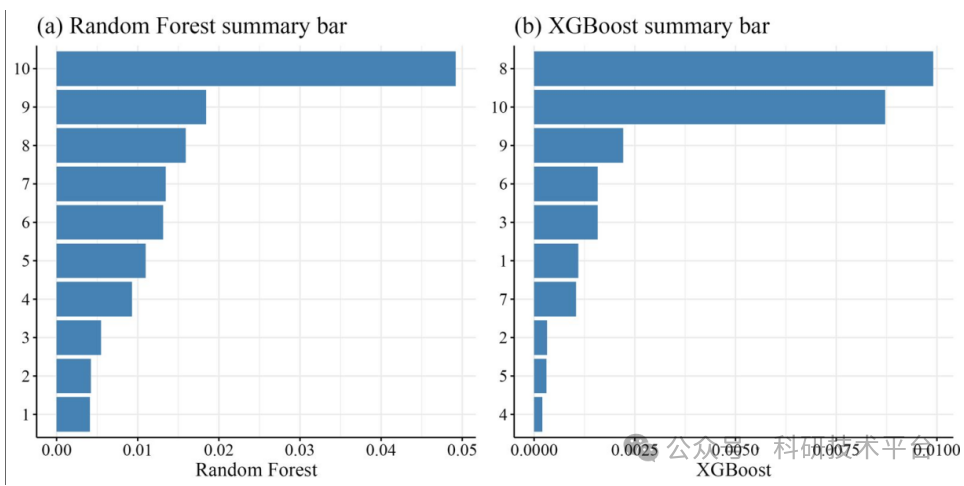
算法思想:
这个算法的目标是按照顺时针螺旋的顺序从矩阵中取出元素。为了做到这一点,整个思路可以分成几个关键步骤:
-
定义边界:首先需要定义四个边界变量:
left:当前左边界的索引。right:当前右边界的索引。top:当前上边界的索引。bottom:当前下边界的索引。
这些变量一开始会对应矩阵的外边界,然后我们会通过逐步缩小这些边界来遍历矩阵的每一层。
-
螺旋遍历:接下来我们会按照四个方向进行遍历:
- 从左到右:遍历上边界的所有元素,从左到右遍历,遍历结束后将上边界向下移动一行(
top++)。 - 从上到下:遍历右边界的所有元素,从上到下遍历,遍历结束后将右边界向左移动一列(
right--)。 - 从右到左:如果还有剩余行需要遍历(即
top <= bottom),遍历下边界的所有元素,从右到左遍历,遍历结束后将下边界向上移动一行(bottom--)。 - 从下到上:如果还有剩余列需要遍历(即
left <= right),遍历左边界的所有元素,从下到上遍历,遍历结束后将左边界向右移动一列(left++)。
- 从左到右:遍历上边界的所有元素,从左到右遍历,遍历结束后将上边界向下移动一行(
-
边界条件检查:在每次从右到左或从下到上遍历之前,需要检查是否仍然有需要遍历的行或列。这是因为在某些情况下,矩阵的某些边界可能已经被其他方向的遍历覆盖了。
-
终止条件:当
left > right或者top > bottom时,意味着已经没有元素可以遍历了,这时循环终止。
算法流程:
- 我们从矩阵的左上角开始,按照顺时针的顺序依次遍历。
- 每完成一圈的遍历,我们就收缩边界,继续处理内层的矩阵,直到所有元素都被处理为止。
时间复杂度分析:
- 每次遍历矩阵中的一圈元素,而每个元素最多被访问一次,因此时间复杂度是 O(m * n),其中
m是矩阵的行数,n是列数。
class Solution {public List<Integer> spiralOrder(int[][] matrix) {//首先创建一个存储结果的ArrayListList<Integer> result = new ArrayList <>();//获得矩阵的行和列int rows = matrix.length;int cols = matrix[0].length;//然后定义四周墙壁int left = 0;int right = cols - 1;int top = 0;int bottom = rows - 1;//开始遍历//最后一个元素是矩阵正中心时(left = result && top = bottom),所以循环终止条件是小于等于while(left <= right && top <= bottom) { //先从左往右遍历上方的每一行, i 从 left 开始遍历到 right, 而不是从 0 开始for(int i = left; i <= right; i++) {result.add(matrix[top][i]);}//每遍历完上方的一行,需要更新 toptop++;//然后从上往下遍历最右边一列for(int i = top; i <= bottom; i++) {result.add(matrix[i][right]);}//每次遍历完最右边列,需要更新rightright--;if (top <= bottom) {//检查是否还有需要遍历的行//然后从右往左遍历最下方的行for(int i = right; i >= left; i--) {result.add(matrix[bottom][i]);}//每次遍历完最下行,需要更新bottombottom--;}if (left <= right) {//检查是否还有需要遍历的列//然后下往上遍历最左方的列for(int i = bottom; i >= top; i--) {result.add(matrix[i][left]);}//每次遍历完最左方的列,需要更新leftleft++;}}return result;}
}
为什么这一部分代码片段,需要使用2个 if 进行判断?
if (top <= bottom) {// Traverse from right to leftfor (int i = right; i >= left; i--) {result.add(matrix[bottom][i]);}bottom--;}if (left <= right) {// Traverse from bottom to topfor (int i = bottom; i >= top; i--) {result.add(matrix[i][left]);}left++;}
在这段代码中,两个 if 判断是用来确保在进行从右到左、从下到上的遍历时,矩阵的边界没有发生交叉。如果不进行这些判断,可能会出现重复遍历或错误遍历的情况。
让我们具体分析这两个 if 判断的作用:
1. 第一个 if 判断 (if (top <= bottom))
if (top <= bottom) {// Traverse from right to leftfor (int i = right; i >= left; i--) {result.add(matrix[bottom][i]);}bottom--;
}
-
这个
if判断用于检查当前上边界top是否仍然小于等于下边界bottom,也就是说,检查是否还有需要遍历的行。如果top > bottom,说明矩阵的所有行已经遍历完了,再进行从右到左的操作将是没有意义的,甚至可能导致重复遍历或越界。 -
如果
top <= bottom,则表示当前还有未处理的行,于是可以安全地从右边界right开始向左遍历,并在遍历结束后将下边界bottom向上移动,减少一行。
2. 第二个 if 判断 (if (left <= right))
if (left <= right) {// Traverse from bottom to topfor (int i = bottom; i >= top; i--) {result.add(matrix[i][left]);}left++;
}
-
这个
if判断用于检查当前左边界left是否仍然小于等于右边界right,也就是说,检查是否还有需要遍历的列。如果left > right,说明矩阵的所有列已经遍历完了,再进行从下到上的操作将是没有必要的,可能导致重复操作或者越界。 -
如果
left <= right,则表示当前还有未处理的列,可以从下边界bottom向上遍历左边界的元素,并在遍历结束后将左边界left向右移动,减少一列。
为什么需要两个独立的 if 判断?
-
防止重复遍历:在螺旋遍历中,每次都会收缩边界(上、下、左、右)。当已经遍历完一层的矩阵后,边界会逐渐靠近矩阵的中心。如果没有这些
if判断,在某些情况下,比如在最后一层矩阵中,可能会导致重复遍历某些行或列。例如,如果你在遍历完右到左的行后,紧接着遍历从下到上的列,而此时没有检查边界是否已经重叠,可能会再次遍历已经处理过的行或列。 -
防止越界:螺旋遍历会不断缩小边界,如果不做这些检查,当边界重叠或交叉时,程序可能会试图访问无效的数组索引,导致数组越界异常。通过在每次遍历前检查边界的有效性,可以确保访问的数组索引始终在合法范围内。
举例:
假设你有一个 3x3 的矩阵:
1 2 3
4 5 6
7 8 9
按顺时针遍历的顺序是:
- 从左到右遍历第一行
[1, 2, 3] - 从上到下遍历第三列
[6, 9] - 从右到左遍历第三行
[8, 7] - 从下到上遍历第一列
[4] - 最后剩下中心元素
[5]
在这过程中,随着边界逐渐收缩,如果没有 if 判断,在遍历完成第三行时,可能会再次从右到左遍历已处理过的行,或者尝试遍历不存在的行。两个 if 判断就是为了避免这种情况发生。
总结:
if (top <= bottom)和if (left <= right)的作用是确保遍历时矩阵的边界没有交叉,从而避免重复访问或越界访问。- 它们是为了保证代码在任意大小和形状的矩阵上都能正确运行,特别是在螺旋遍历的过程中边界不断收缩的情况下。