知乎:难赋
链接:https://zhuanlan.zhihu.com/p/721054525
简述
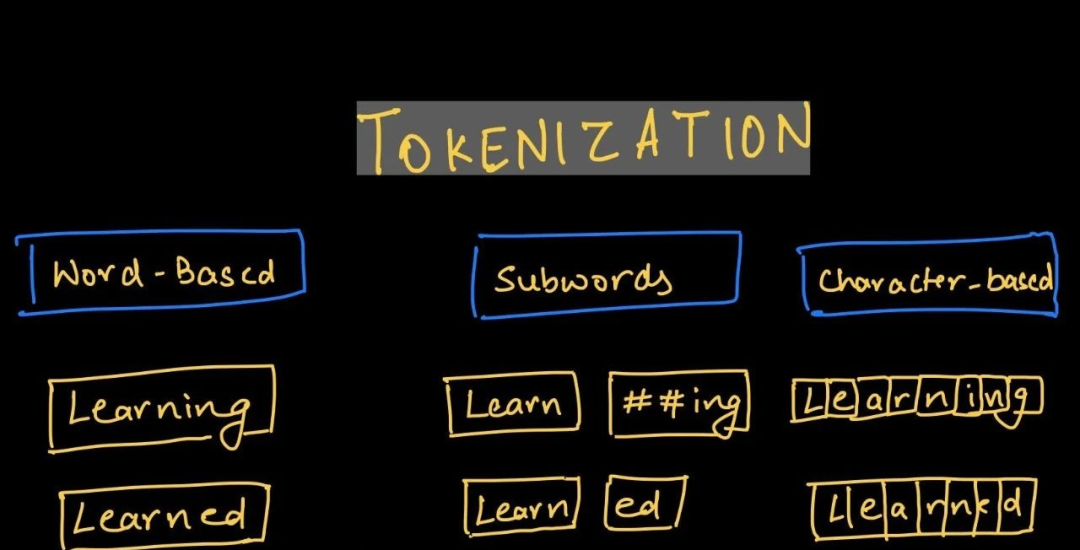
为了方便计算机处理文本,我们常把文本转化为数值的形式。具体操作是把文本分割成有意义的片段,再把这些片段映射为数组,就能够利用各种深度学习的技术来处理文本了。把文本分割成有意义的片段这一过程称为tokenize,片段称为token。我们可以发现,token是计算机处理文本的基本单位。
tokenize是一个复杂的问题,针对不同的情况出现了很多的算法。人力资源是非常昂贵的,程序员是一群喜欢自动化的人。因此我们在处理这个问题时首先回答了一个这样的问题:能否采用某种无监督的方式,通过某种算法将连续的文本自动地转化为token?
回答完这个问题后,人们把tokenize的过程分为以下几个步骤:
把训练文本中的所有字符作为初始token
根据某种规则把联系紧密的token对合并为更高阶的token,这一步我们有时称之为训练
重复第2步,直到满足某种限制条件(如词汇表达到限额)
之后我们可以利用最终的词汇表进行tokenize和detokenize。
接下来,我们根据huggingface的开源库来介绍常用的tokenize方法。
huggingface
huggingface关于tokenize有两个主要的文件:tokenizers库和transformers里的基类。
tokenizers库提供了tokenizer的定义、训练、使用等代码。
transformers提供了预训练模型中使用的tokenizer的实现以及包含共有方法的基类。
这两处的代码比较独立。
tokenizer
这部分我们会介绍tokenizers库的使用和自定义。
我们可以通过传入vocab.txt文件来初始化tokenizer或者采用from_pretrained方法加载云端的预训练tokenizer。
from tokenizers import Tokenizertokenizer = Tokenizer.from_pretrained("bert-base-uncased")或者
from tokenizers import BertWordPieceTokenizertokenizer = BertWordPieceTokenizer("bert-base-uncased-vocab.txt", lowercase=True)这个库把tokenize的过程分为四个步骤:
Normalization
让字符串变得不那么杂乱,使其规范化。主要处理编码层面的一些事情,如 https://unicode.org/reports/tr15 是最常实现的一个normalization。
Pre-tokenization
把字符串分割为word,也即保证token的范围为:
char ≤ token ≤ word,防止出现token大于word的情况(否则I'm可能分不开)。Model
用于实现
str->token的学习过程。常用的有:详见模型小节。
models.BPEmodels.Unigrammodels.WordLevelmodels.WordPiece
1.Post-processing
用于添加特殊的token等,如[UNK]、[PAD]。
这里给出一份tokenizer的训练代码:
from tokenizers import Tokenizer
from tokenizers.models import WordPiecebert_tokenizer = Tokenizer(WordPiece(unk_token="[UNK]"))from tokenizers import normalizers
from tokenizers.normalizers import NFD, Lowercase, StripAccentsbert_tokenizer.normalizer = normalizers.Sequence([NFD(), Lowercase(), StripAccents()])from tokenizers.pre_tokenizers import Whitespacebert_tokenizer.pre_tokenizer = Whitespace()from tokenizers.processors import TemplateProcessingbert_tokenizer.post_processor = TemplateProcessing(single="[CLS] $A [SEP]",pair="[CLS] $A [SEP] $B:1 [SEP]:1",special_tokens=[("[CLS]", 1),("[SEP]", 2),],
)from tokenizers.trainers import WordPieceTrainertrainer = WordPieceTrainer(vocab_size=30522, special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"]
)
files = [f"data/wikitext-103-raw/wiki.{split}.raw"for split in ["test", "train", "valid"]
]
bert_tokenizer.train(files, trainer)
bert_tokenizer.save("data/bert-wiki.json")模型
WordPiece(2016)
来自:Google's Neural Machine Translation System。BERT之后进入大众视野。未开源训练代码,开源分词代码。
准备模型的训练语料
确定「期望的词表大小」
将训练语料中的所有单词拆分为字符,这些字符作为初始的词表
统计训练语料中紧挨的token对的分数,选取最高的进行合并
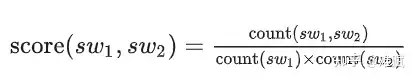
重复第4步,直到词表大小达到我们设定的期望或者剩下的字节对出现频率最高为1
编码方式采用字典树按最长优先进行匹配。
BPE(GPT2,2019)
准备模型的训练语料
确定「期望的词表大小」
将训练语料中的所有单词拆分为字符,这些字符作为初始的词表
统计训练语料中紧挨的token对出现的频率,「选择出现频率最高的token对合并成新的subword,并更新词表」,把被合并的token对加入合并规则表
重复第4步,直到词表大小达到我们设定的期望或者剩下的字节对出现频率最高为1
编码方式:
把字符串按字符拆分,按照合并规则表进行合并。
transformers
transformers库中关于分词由三个文件组成:tokenization_utils.py、tokenization_utils_base.py和tokenization_utils_fast.py。其中tokenization_utils_fast.py为Rust的快速实现版本,与tokenization_utils.py的接口几乎没区别。接下来我们梳理一下这几个文件。
tokenization_utils_base.py
这个文件主要实现 PreTrainedTokenizer 的基类。
class BatchEncoding(UserDict)PreTrainedTokenizerBase输出对象,tokenizer进行str->token处理时会以这个对象的形式返回结果。处理char、token、word和sentence的相互转化。>>> type(tokenizer(["1!"])) transformers.tokenization_utils_base.BatchEncodingclass SpecialTokensMixin以model独立的方式处理特殊token。
class PreTrainedTokenizerBase(SpecialTokensMixin, PushToHubMixin)PreTrainedTokenizer和PreTrainedTokenizerFast的公有方法。主要涉及:chat模板、预训练模型加载与保存、
tokenize(未实现,str->[id])、encode(str->[id])、__call__(tokenize和prepare方法)、padding、prepare_for_model(处理[id]以供model使用)、truncate_sequences、convert_tokens_to_string(未实现)、batch_decode、decode、get_special_tokens_mask、prepare_seq2seq_batch。
tokenization_utils.py
class Trie首先,文件实现了一个python版本的前缀树。
Trie(发音为 "try")是一种特殊的数据结构,也称为前缀树(Prefix Tree)或字典树(Digital Tree)。它是一种有序树,用于存储动态集合或关联数组,其中键通常是字符串。Trie 树的主要特点是它能够高效地进行字符串的插入、查找和前缀匹配操作。
Trie 树的主要特点:
支持以下方法:
add:向里面增加word。split:把句子分割为word列表。cut_text:内部方法,用于实际的分割操作。每个节点包含一个字符。
每个节点可以有多个子节点,每个子节点代表一个可能的字符。
根节点通常不包含字符,从根节点到某个节点的路径上的字符序列表示一个字符串。
class ExtensionsTrie(Trie)扩展以下方法:
extensions:获取指定前缀的所有单词。
PreTrainedTokenizer(PreTrainedTokenizerBase)
实现tokenizer的共有方法。
以下是 PreTrainedTokenizer 类的公共方法的表格,仅包含方法名和描述:
| 方法名(带*的表示需要实现) | 描述 |
|---|---|
is_fast | 返回一个布尔值,表示当前的 Tokenizer 是否是快速版本。 |
vocab_size* | 返回基础词汇表的大小(不包括添加的标记)。 |
added_tokens_encoder | 返回从字符串到索引的排序映射。 |
added_tokens_decoder | 返回添加的标记在词汇表中的字典,索引到 AddedToken。 |
get_added_vocab | 返回添加的标记在词汇表中的字典,标记到索引。 |
__len__ | 返回完整词汇表的大小(包括添加的标记)。 |
num_special_tokens_to_add | 返回在编码序列时添加的特殊标记的数量。 |
tokenize | 将字符串转换为标记序列,使用 Tokenizer。 |
_tokenize* | 将字符串转换为标记序列,使用 Tokenizer。不考虑添加的token。 |
convert_tokens_to_ids | 将标记字符串(或标记序列)转换为单个整数 ID(或 ID 序列),使用词汇表。 |
_convert_tokens_to_ids* | 将标记字符串(或标记序列)转换为单个整数 ID(或 ID 序列),使用词汇表。 |
_encode_plus | 对输入文本进行编码,并返回包含编码结果的字典。 |
_batch_encode_plus | 对一批输入文本进行编码,并返回包含编码结果的字典。 |
prepare_for_tokenization | 在 Tokenization 之前执行任何必要的转换。 |
get_special_tokens_mask | 从没有添加特殊标记的标记列表中检索序列 ID。 |
convert_ids_to_tokens | 使用词汇表和添加的标记将单个索引或索引序列转换为标记或标记序列。 |
_convert_id_to_token* | 将单个 ID 转换为对应的 token。 |
convert_tokens_to_string | 将标记列表转换为字符串。 |
_decode | 将标记 ID 列表解码为字符串。 |
我们实现自己的tokenizer需要实现的抽象方法:
PreTrainedTokenizer
vocab_size*_tokenize*_convert_tokens_to_ids*_convert_token_to_id*_convert_id_to_token*
PreTrainedTokenizerBase
get_vocab(返回词汇表作为token到索引的字典)。
最简实现
class miniTokenizer(PreTrainedTokenizer):def __init__(self,vocab_file,unk_token="[UNK]",sep_token="[SEP]",pad_token="[PAD]",cls_token="[CLS]",mask_token="[MASK]",):self.vocab_file = vocab_filewith open(vocab_file, "r", encoding="utf-8") as f:self.vocab = f.read().split("\n") # id2tokenself.vocab_size_ = len(self.vocab)self.token2id = {token: id_ for id_, token in enumerate(self.vocab)}super().__init__(unk_token=unk_token,sep_token=sep_token,pad_token=pad_token,cls_token=cls_token,mask_token=mask_token,)def vocab_size(self) -> int:return self.vocab_size_def _tokenize(self, text, **kwargs):return list(text)def _convert_tokens_to_ids(self, tokens):return [self.token2id.get(token, self.token2id[self.unk_token]) for token in tokens]def _convert_token_to_id(self, token):return self.token2id.get(token, self.token2id[self.unk_token])def _convert_id_to_token(self, id_):return self.vocab[id_]def get_vocab(self):return self.token2idtokenizer = miniTokenizer("vocab.txt")
tokenizer(["1!123"]) # {'input_ids': [[1, 6, 1, 2, 3]], 'token_type_ids': [[0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1]]}vocab.txt内容:
0
1
2
3
4
)
!
@
#
$
123备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦



















