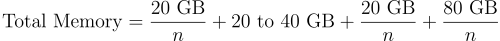🌎Linux线程同步与互斥
文章目录:
Linux线程同步与互斥
Linux线程互斥
线程锁
互斥量Mutex
初始化互斥量的两种方式
申请锁方式
解除与销毁锁
问题解决及线程饥饿
互斥锁的底层实现
线程同步
条件变量
条件变量函数
条件变量示例
🚀Linux线程互斥
- 临界资源:多线程执行流共享的资源就叫做临界资源
- 临界区:每个线程内部,访问临界资源的代码,就叫做临界区
- 互斥:任何时刻,互斥保证有且只有一个执行流进入临界区,访问临界资源,通常对临界资源起保护作用
- 原子性(后面讨论如何实现):不会被任何调度机制打断的操作,该操作只有两态,要么完成,要么未完成
如果不能保持互斥,那么会发生一些不合逻辑的事情,以下面这段多线程抢票代码为例:
#include <iostream>
#include <vector>
#include "thread.hpp" // 自己实现的线程封装using namespace ThreadModule;// 数据不一致
int g_tickets = 10000; // 共享资源,没有保护的, 多线程同时访问void route(int &tickets)
{while (true){if(tickets>0) // 票数小于0, 终止抢票{usleep(1000);printf("get tickets: %d\n", tickets);tickets--;}else{break;}}
}const int num = 4;
int main()
{// std::cout << "main: &tickets: " << &g_tickets << std::endl;std::vector<Thread<int>> threads;// 1. 创建一批线程for (int i = 0; i < num; i++){std::string name = "thread-" + std::to_string(i + 1);threads.emplace_back(route, g_tickets, name);}// 2. 启动 一批线程for (auto &thread : threads){thread.Start();}// 3. 等待一批线程for (auto &thread : threads){thread.Join();std::cout << "wait thread done, thread is: " << thread.name() << std::endl;}return 0;
}

这里线程对同一个共享资源进行操作,进行并发执行类似 “抢票” 的模式,但是最后得到的数据却发现,抢票居然还有负数?这种情况我们称为 数据不一致。
这个问题是怎么产生怎么导致的呢?首先我们先要了解一个概念:原子性,前面我们说,原子性只有两态,要么已完成,要么未完成。实际上,在编程的角度来说,原子性指的是汇编层面只有一条语句。比如对一个内置类型进行赋值操作,在汇编层面其实就是一条move指令。所以其是原子的。
了解了上述概念之后,我们再来看一看代码的逻辑结构,在route函数里,我们对tickets进行了判断,而判断是逻辑运算,需要在CPU内进行操作。

判断完成后,刚刚进入内部,执行usleep()函数,所以此时线程就被切换,进入到等待队列。假设此时是thread-1在跑,又因为tickets被保存到寄存器当中,而thread-1此时要进行线程切换则需要带走thread-1的数据,则此时thread-1把寄存器中的tickets带走了。(线程等待结束后才会继续执行后续代码)
随后thread-2也开始执行此函数,因为上一个thread-1线程遇到了usleep,所以后续的tickets- -,以及total- - 都是没有执行的。也就是说上一次对tickets操作后tickets值并没有变,所以此时thread-2同样将内存中的tickets加载到寄存器当中,同样,tickets此时的值还是1,同样thread-2遇到usleep,那么thread-2也要带着自己的数据到等待队列当中。

把全局变量加载到CPU不是本质,本质是 将共享的全局变量加载到寄存器使得当前线程私有化共享全局变量。而此时寄存器的值又没有被写回,所以此时thread-2也进入到等待队列。同理,周而复始,thread-3 4都是如此。
而当等待队列等待完成后,所有线程都开始执行后续的代码,之前阻塞到printf,这里printf不影响tickets所以忽略。后续代码执行到 tickets-- ⇒ tickets = tickets - 1; 此步操作不是原子的,因为它需要经历:1、从内存读取到CPU. 2、CPU内部进行- -操作. 3、写回到内存中, 那么此时问题就出来了。
当thread-1已经将tickets进行了–,并且将其写回到了内存。那么接下来thread-2等待完成又对tickets进行–,此时CPU中的tickets已经变为0了,所以–过后tickets变为了-1,再次将其写回到内存当中。周而复始,使得原本正常的抢票,最后却变为了负数。
也就是说,共享资源(tickets)被访问时没有被保护起来,并且本身操作不是原子的。
🚀线程锁
上面我们已经把问题给搞明白了,接下来我们需要解决问题,如何解决这种线程问题呢?通常的解决方案是对线程进行加锁。
✈️互斥量Mutex
大部分情况,线程使用的数据都是局部变量,变量的地址空间在线程栈空间内,这种情况,变量归属单个线程,其他线程无法获得这种变量。但有时候,很多变量都需要在线程间共享,这样的变量称为共享变量,可以通过数据的共享,完成线程之间的交互。多个线程并发的操作共享变量,会带来一些问题。为了解决上述问题:
- 代码必须要有互斥行为:当代码进入临界区执行时,不允许其他线程进入该临界区。
- 如果多个线程同时要求执行临界区的代码,并且临界区没有线程在执行,那么只能允许一个线程进入该临界区。
- 如果线程不在临界区中执行,那么该线程不能阻止其他线程进入临界区。
为此,Linux给我们提供了互斥锁,首先我们先来认识一下这些接口:

🚩初始化互斥量的两种方式
如果定义的锁是静态或者全局的:
使用 pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; 宏进行初始化互斥量,那么这把锁就可以直接使用了。
如果定义的是局部的锁(动态的,比如临时对象):
int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr);
函数参数:
- mutex:要初始化的互斥量
- attr:NULL
🚩申请锁方式
不论我们使用哪种方式定义上面的锁,我们都可以对这把锁进行上锁 pthread_lock():

申请锁接口:
int pthread_mutex_lock(pthread_mutex_t *mutex);
使用该接口只有三种结果:
- 申请成功,函数会返回,允许继续向后执行。
- 申请失败,函数会阻塞,不允许向后运行。
- 函数调用失败,出错返回。
尝试申请锁:
int pthread_mutex_trylock(pthread_mutex_t *mutex);
尝试申请锁,与pthread_mutex_lock()唯一不同的是,当申请锁失败之后,不会进行阻塞等待,而是直接出错返回,并设置错误码返回出错原因。
🚩解除与销毁锁
解除互斥锁:
int pthread_mutex_unlock(pthread_mutex_t *mutex);
有加锁必然有解锁,当线程在临界资源内执行完毕后,需要释放当前锁,让其他线程进入,所以需要释放锁。
销毁互斥锁:
int pthread_mutex_destroy(pthread_mutex_t *mutex);
- 使用 PTHREAD_ MUTEX_ INITIALIZER 初始化的互斥量不需要销毁
- 不要销毁一个已经加锁的互斥量
- 已经销毁的互斥量,要确保后面不会有线程再尝试加锁
✈️问题解决及线程饥饿
出现数据不一致问题的本质是,多个执行流并发访问全局数据的代码所导致的!访问公共资源的代码,我们称为临界区。
我们加锁的本质是把并行的执行流改变为串行的执行流,而对临街资源的保护实质上就是对临街区代码的加解锁。
#include <iostream>
#include <vector>
#include "thread.hpp"using namespace ThreadModule;// 数据不一致
int g_tickets = 10000; // 共享资源,没有保护的, 多线程同时访问class ThreadData
{
public:ThreadData(int tickets, const std::string &name):_tickets(tickets), _name(name), _total(0){}~ThreadData(){}
public:int &_tickets; // 所有的线程最后都会引用同一个全局的g_ticketsstd::string _name;int _total;
};pthread_mutex_t gmutex = PTHREAD_MUTEX_INITIALIZER;// 创建互斥量void route(ThreadData *td)
{while (true){// 加锁力度越细越好pthread_mutex_lock(&gmutex);// 上锁if(td->_tickets>0){usleep(1000);printf("%s running, get tickets: %d\n",td->_name.c_str(), td->_tickets);td->_tickets--;pthread_mutex_unlock(&gmutex);// 解锁td->_total++;// 将解锁放在此句后面也是可以的,只不过这里的total已经不属于临界区了,所以如果要严格按照规则加锁解锁,就在上一句进行解锁}else{break;}}
}const int num = 4;// 创建线程数
int main()
{// std::cout << "main: &tickets: " << &g_tickets << std::endl;std::vector<Thread<ThreadData*>> threads;std::vector<ThreadData*> datas;// 1. 创建一批线程for (int i = 0; i < num; i++){std::string name = "thread-" + std::to_string(i + 1);ThreadData* td = new ThreadData(g_tickets, name);threads.emplace_back(route, td, name);datas.emplace_back(td);}// 2. 启动 一批线程for (auto &thread : threads){thread.Start();}// 3. 等待一批线程for (auto &thread : threads){thread.Join();// std::cout << "wait thread done, thread is: " << thread.name() << std::endl;}// 4. 输出统计数据for(auto & data:datas){std::cout << data->_name << " : " << data->_total << std::endl;delete data;}return 0;
}

这样加锁了之后,就不会再出现之前的情形,数据也就正常了。但是如果你是CentOS的用户的话,是有一些bug的,因为CentOS环境中,某些线程的竞争能力太强了,以至于得到的结果往往只有一个线程有结果,其他线程为0,这是因为在CentOS中对线程调度的算法没有Unbuntu的新,也就是没有Ubuntu的算法好。
所以,又能得出另一个结论:多线程加锁,这些多线程对锁的竞争是自由的。如果竞争能力太强的线程,会导致其他线程抢不到锁,也就造成了线程饥饿问题!我所说的CentOS的这种行为就是竞争饥饿问题。
✈️互斥锁的底层实现
- 经过上面的例子,大家已经意识到单纯的 i++ 或者 ++i 都不是原子的,有可能会有数据一致性问题
- 为了实现互斥锁操作,大多数体系结构都提供了swap或exchange指令,该指令的作用是把寄存器和内存单元的数据相交换,由于只有一条指令,保证了原子性,即使是多处理器平台,访问内存的 总线周期也有先后,一个处理器上的交换指令执行时另一个处理器的交换指令只能等待总线周期。现在我们把lock和unlock的伪代码改一下

swap或者exchange可以交换寄存器和内存单元中的值,第一句movb 0, al,把左值赋值给寄存器al,第二步xchgb把寄存器内的值和Mutex锁进行交换,随后判断 寄存器内的内容是否>0,如果是则返回0,表示加锁成功,否则就挂起等待, 表示当前锁被线程等待,等待完成继续执行锁。
解锁的过程,此时线程已经执行完毕,把寄存器中的值重新放进内存的mutex变量中,表示当前锁已经释放。下图或许能帮助你更好的理解这一过程:

为什么线程能做这件事呢?我们之前说过,CPU寄存器内部的数据,保存了线程的硬件上下文,而数据在内存里,所有线程都能够访问,属于共享的,但是如果转移到CPU内部的寄存器中,就属于一个线程私有了。
上图中,线程1因为某些原因需要线程切换,进入等待队列。那么此时线程1需要把自己的上下文数据带走,其实就是把寄存器当中保存的值带走,并且没有对内存交换的0进行写回,也就是说此时内存中的mutex是0,那么线程2在交换mutex到寄存器当中,就会进行状态检测,此时检测到状态为0,说明当前已经有人占用锁了,则线程2进入到挂起状态,后来的线程依旧会如此,直到第一个线程执行完毕将锁释放。
所以上述所谓的交换就显得尤为重要,这里的交换指的不是单纯的拷贝,而是所有线程在争锁的时候只有一个值,而这个值往往就是那把锁。交换过程只有一条汇编语句,所以 交换过程是原子的,那么就能保证交换时不会发生线程切换这样的事情。
临界区内部正在访问临界区的线程,此时能否被调度切换呢?
一个线程在访问临界区时,对于其他线程来说,1、锁被释放。2、曾经没有申请到锁正在挂起状态。此时当前线程访问临街资源是加了锁的,对其他线程来说这一过程是原子的,所以说此时访问临界区资源是线程安全的。
🚀线程同步
主线开始前,我们先来听一个故事:
20年前,阿飞在xx大学上学,当时信号交通不便,他们学校西门只有一个电话庭,阿飞每次打电话都会去这个电话亭,一直让阿飞感到难受的是,电话庭太少了,人却太多了,每个人都想打电话。这一天阿飞早早的来到了电话庭,恰巧这时候没人,他是第一个,于是给异地的女朋友打了两个小时电话,这个时候阿飞看时间不早了,想要去吃中午饭,吃完饭继续再跟女朋友聊。
但是呢这个时候阿飞回头一看,阿飞刚出电话亭,就看到密密麻麻站满了人,“这吃完饭再来不得到猴年马月才能打上电话?” 于是阿飞咬咬牙,大不了中午不吃饭了,说完,因为他距离门最近,他又进去把门关了,又叙了两个小时。随后阿飞痛快的出门,可是刚出门就想起来自己没生活费了,然后又急忙转身进入电话亭把门关上,又给家里打了电话。这样来来回回好几次,一直占着电话亭。
此时电话亭外面的人不乐意了,“怎么还xx的不出来,再不出来劳资见你一次打你一次!”,阿飞眼看着局势不对,也不敢出电话亭,于是就拨通了警察局的电话,警察来了之后,了解了大致情况。于是在电话亭这里设立了警戒线,并且装上了高清摄像头,并规定:每个人来到这里以后必须要排队,并且打完电话的人不能再次直接进入,必须从队尾重新排队打电话。

其实上面这个故事就是今天的主线,线程同步,为什么这么说呢?我们把人比作线程,在警察来之前,线程一直在占用这个锁,导致其他线程没办法拿到锁,一直处于等待状态,就会产生线程饥饿问题。而第二种情况,每个线程在没拿到锁之前都需要排队等待,并且拿到锁的线程如果要二次进入则需要重新到队尾排队。
而上述的过程基本上做到了让不同线程在保证电话亭安全的前提下,让所有的线程访问临界资源具有了一定的顺序性。这个工作我们称为 线程同步。
- 同步:在保证 数据安全 的前提下,让线程能够按照某种特定的顺序访问 临界资源,从而有效避免 饥饿问题,叫做 同步。
✈️条件变量
实现线程同步,我们常用做法是使用条件变量。这里的条件变量可不是环境变量,那什么是条件变量呢?
- 当一个线程互斥地访问某个变量时,它可能发现在其它线程改变状态之前,它什么也做不了。
例如一个线程访问队列时,发现队列为空,它只能等待,只到其它线程将一个节点添加到队列中。这种情况就需要用到条件变量。
✈️条件变量函数
条件变量初始化(动态,局部条件变量):
int pthread_cond_init(pthread_cond_t *restrict cond,const pthread_condattr_t *restrict
attr);
函数参数:
- cond:要初始化的条件变量
- attr:NULL
静态,全局条件变量初始化:
pthread_cond_t cond cond = PTHREAD_COND_INTIALIZER;
这里与互斥锁规则相似,不再过多赘述。
销毁条件变量:
int pthread_cond_destroy(pthread_cond_t *cond)
等待条件满足:
int pthread_cond_wait(pthread_cond_t *restrict cond,pthread_mutex_t *restrict mutex);
函数参数:
- cond:要在这个条件变量上等待(队列内等待)
- mutex:互斥量
唤醒线程:
int pthread_cond_broadcast(pthread_cond_t *cond);// 唤醒所有在cond等待下的线程
int pthread_cond_signal(pthread_cond_t *cond);// 唤醒一个线程
以上接口的返回值,全部都是:返回0为成功,失败设置错误码。要学习条件变量实际上上面这些接口就足够了。
✈️条件变量示例
这里使用全局条件变量,全部使用接口调用的形式展示条件变量的作用: 创建一个主控线程,3个附属线程,对三个附属线程进行cond等待,通过主控线程唤醒这些线程(全部唤醒和单独唤醒)。
main函数内定义一个接收tid的数组,一函数调用的形式分别创建一个主控线程和多个附属线程:
int main()
{std::vector<pthread_t> tids;StartMaster(&tids);// 主控线程StartSlaver(&tids);// 其他线程WaitThread(tids);// 线程等待return 0;
}
添加需要的头文件,以及设置全局条件变量与全局互斥锁:
#include <iostream>
#include <string>
#include <vector>
#include <unistd.h>
#include <pthread.h>pthread_cond_t gcond = PTHREAD_COND_INITIALIZER;// 全局条件变量
pthread_mutex_t gmutex = PTHREAD_MUTEX_INITIALIZER;// 全局互斥量
创建附属线程,默认创建3个附属线程,所有附属线程执行同一回调SlaverCore,回调内将所有线程在临界区内加锁并等待,此时线程锁gmutex释放 线程进入cond等待队列,等待主控线程唤醒,下一个线程重复此步操作,直至所有现成进入到cond等待队列,等待主控唤醒:
void* SlaverCore(void* args)
{std::string name = static_cast<const char*>(args);while(true){// 1. 加锁pthread_mutex_lock(&gmutex);// 2. 一般条件变量是在加锁和解锁之间使用pthread_cond_wait(&gcond, &gmutex);// gmutex: 这个是用来释放的[前一半],进入等待队列,此时锁被释放std::cout << "当前被叫醒的线程是:" << name << std::endl;pthread_mutex_unlock(&gmutex);}return nullptr;
}void StartSlaver(std::vector<pthread_t> *tidsptr, int threadnum = 3)
{for(int i = 0; i < threadnum; ++i){char *name = new char[64];// 每一个线程都需要new 一个新名字,否则很可能会出现线程覆盖问题snprintf(name, 64, "slaver-%d", i + 1);pthread_t tid;int n = pthread_create(&tid, nullptr, SlaverCore, name);if(n == 0){std::cout << "create sucess: " << name << std::endl;tidsptr->emplace_back(tid);}}
}
主控线程,创建主控线程,执行主控回调,主控回调函数内,休眠三秒确保所有附属线程进入等待队列,在循环里可选择的将所有线程选择全部唤醒或者隔一秒唤醒一个线程:
void* MasterCore(void *args)// call back func
{sleep(3);std::cout << "master start work..." << std::endl;std::string name = static_cast<const char*>(args);while(true){// pthread_cond_signal(&gcond);// 一次唤醒1个线程pthread_cond_broadcast(&gcond);// 广播唤醒所有的线程std::cout << "master awake a thread..." << std::endl;sleep(1);}return nullptr;
}void StartMaster(std::vector<pthread_t> *tidsptr)// main contrl thread
{pthread_t tid;int n = pthread_create(&tid, nullptr, MasterCore, (void*)"Master Thread");if(n == 0){std::cout << "create master success" << std::endl;}tidsptr->emplace_back(tid);
}
main-thread阻塞等待回收所有线程:
void WaitThread(std::vector<pthread_t> &tids)
{for(auto & tid : tids){pthread_join(tid, nullptr);}
}
主控线程一次性全部唤醒等待队列的线程:

主控线程每隔一秒唤醒一个线程: