无论你是从头开始训练 LLM、对其进行微调还是部署现有模型,选择合适的 GPU 对成本和效率都至关重要。在这篇博客中,我们将详细介绍使用单个和多个 GPU 以及不同的优化器和批处理大小进行 LLM 训练和推理时 GPU 要求的所有信息。
计算机处理器由多个决定性电路组成,每个电路都可以处于关闭或打开状态。就内存而言,这两种状态由 0 或 1 或位表示。一组八位称为一个字节。1 个字节可以表示零(00000000)和 255(11111111)之间的数字,或 28(等于 256 个不同位置)。通常,在 FP-32(包括符号、指数和尾数)数据类型上训练的神经网络最多占用 4 个字节的内存。
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
模型参数常用的数据类型如下:
- float(32 位浮点):每个参数 4 个字节
- half/BF16(16 位浮点):每个参数 2 个字节
- int8(8 位整数):每个参数 1 个字节
- int4(4 位整数):每个参数 0.5 个字节
1、什么会消耗 GPU 内存?
在模型训练期间,大部分内存被四个东西消耗
11 模型参数
模型参数是神经网络的可学习组件。它们定义网络的结构和行为,并在训练期间更新以最小化损失函数。通常,我们有权重和偏差参数。
正如我们已经知道的那样,存储一个数字需要 4 个字节。假设我们的模型中有 P 个参数。
- 参数内存(M)= 参数数量(P)x 精度大小(4 字节)
- M = Px4
- 16 位 M = P x 精度大小(2 字节)也类似
我们可以添加一个缩放因子并制定一个标准公式,如下所示:
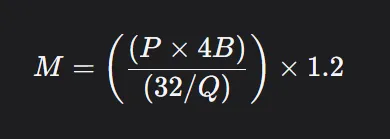
这里 1.2 表示在 GPU 内存中加载额外内容的 20% 开销,Q 是加载模型应使用的位数。即 16 位、8 位或 4 位。
16 位 Llama 70B 需要 GPU 内存:
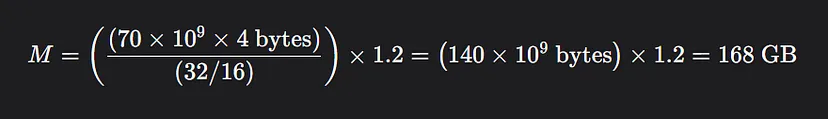
这是推理 Llama 70b 模型所需的总体最低 GPU。
1.2 激活
当输入数据通过网络时,激活是每层神经元的中间输出。在前向传递过程中,每层处理输入数据,应用权重、偏差和激活函数(如 ReLU、sigmoid 等)来产生激活。然后,这些激活将作为下一层输入。
需要存储每个层的激活,因为它们在反向传播期间用于计算梯度。
激活内存 = 激活数量 x 批次大小 x 精度大小
注意:“每个参数的激活”取决于模型架构、层数和序列长度。对于大型模型,激活通常需要与参数相当或超过参数的内存。将序列长度加倍也可能使激活内存加倍。
近似值:没有固定的公式来计算激活的 GPU 内存。对于较大的模型,激活所需的内存可能大致与参数的内存相似或略大。
1.3 梯度
梯度是损失函数关于模型参数的偏导数。它们表示应调整每个参数多少以最小化损失函数。
在反向传播期间,损失通过网络向后传播,并计算每个参数(权重和偏差)的梯度。优化器使用这些梯度来更新参数,从而减少整体损失。
存储梯度所需的内存等于参数本身所需的内存。由于每个参数都有相应的梯度,因此它们的内存要求相同。
梯度内存 = 参数内存
1.4 优化器状态
优化器状态是某些优化算法(如 Adam、RMSprop)维护的附加变量,用于提高训练效率。这些状态有助于根据过去的梯度更新模型参数。
不同的优化器维护不同类型的状态。例如:
- SGD(随机梯度下降):没有附加状态;仅使用梯度来更新参数。
- Adam:为每个参数维护两个状态:一阶矩(梯度平均值)和二阶矩(梯度平方平均值)。这有助于动态调整每个参数的学习率。对于具有 100 万个参数的模型,Adam 需要为每个参数维护 2 个附加值(一阶矩和二阶矩),从而产生 200 万个附加状态。
优化器状态的内存 = 参数数量 x 精度大小 x 优化器乘数
2、单GPU内存需求计算
我们举个例子
我们想在单个 GPU 上以混合精度(2 字节)训练 100 亿模型。
- 参数内存=参数数量 x 2 字节 (FP16)
- 参数内存=10B x 2 字节 = 20 GB
- 激活内存=每个参数的激活 x 批次大小 x 精度大小
我们可以计算每层激活内存,而不是计算激活的总内存,这是一种高效的方法,需要的内存更少,因为它可以在下一层使用。
- 每层神经元的近似数量 = sqrt(10B) ≈ 每层 100k 个神经元
- 一层的激活内存 ≈ 32 x 100k x 2 字节 ≈ 每层 6.4 MB
对于大型模型中的层(假设有数百层),激活内存最多可达数十 GB。
因此,正如我们之前讨论过的,对于 32 的批次大小,大约需要 20-40 GB 的内存。现在,如果我们将批次大小加倍,这个范围可以加倍。
- 梯度内存 = 参数内存
- 梯度内存 = 20 GB
- 优化器状态内存 = 参数数量 x 4 字节 (FP32) x 2 (用于 Adam)
- 优化器状态内存 = 10B x 4 字节 x 2 = 80 GB
总内存估计:
- 参数内存:20 GB
- 激活内存:≈20–40 GB(取决于批次大小)
- 梯度内存:20 GB
- 优化器状态内存:80 GB
- 总内存 = 20 + 20 到 40 + 20 + 80 = 140 到 160 GB
3、多个 GPU 的内存计算
要计算在 n 个 GPU 上训练时每个 GPU 的内存需求,我们需要考虑如何使用数据并行和模型并行等并行技术在 GPU 上分配内存。
关键假设:
- 模型并行:模型的参数在 GPU 之间分配,因此每个 GPU 仅存储总模型参数的一小部分。梯度和优化器状态也同样被划分。
- 数据并行:每个 GPU 都会获得整个模型参数的副本,但数据批次会在 GPU 之间分配。激活是针对每个 GPU 的小批次单独计算的。
如果我们使用模型并行性,那么所有模型参数、梯度和优化器统计数据都是分布式的。
但是,每个 GPU 仍然需要存储其批次部分的激活。激活的内存不会随着 GPU 数量的增加而减少,因为每个 GPU 都独立处理自己的数据。
因此,对于所有 GPU 来说,激活所需的内存仍然相同
![]()
因此,在 n 个 GPU 上以混合精度(2 字节)训练 100 亿模型所需的总内存为:
![]()
如果我们想使用 2 个 GPU 训练 LLM,我们需要大约 8o 到 100 GB 的内存。
原文链接:LLM显卡内存需求计算 - BimAnt