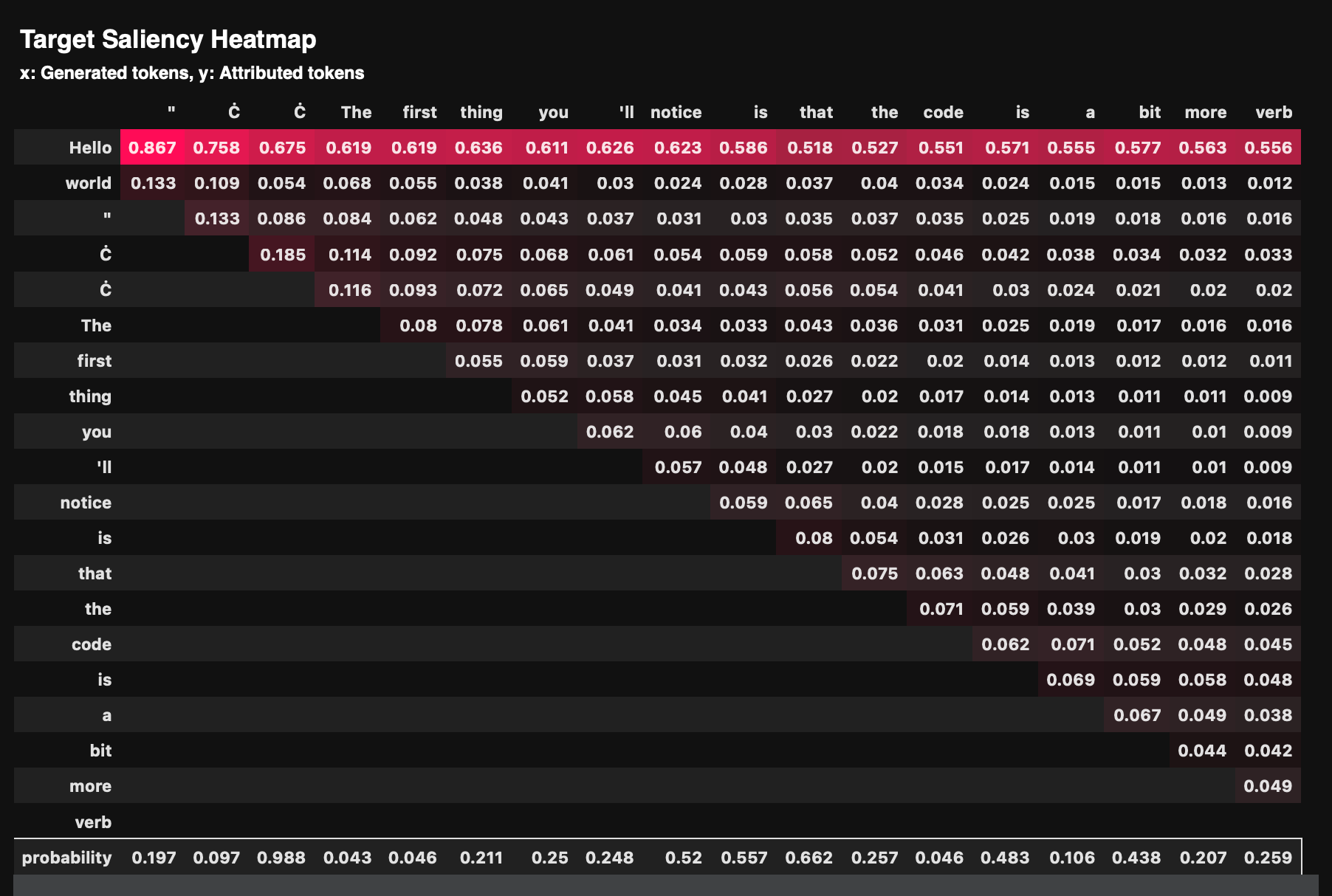
在深度学习中,概率论和数理统计是理解许多算法背后的理论基础。这些知识在处理不确定性、估计模型参数、理解数据分布等方面非常关键
1、概率
一种用来描述随机事件发生的可能性的数字度量,表示某一事件发生的可能性。
概率并不客观存在,是一种不确定性的度量。它的范围在【0,1】之间,0表示不可能发生,1表示必然发生。
概率公式:P(A) = 事件A发生的次数/总事件数
在深度学习中,概率用于表示模型预测某一结果的可能性。例如,分类问题中,输出为某一类别的概率。
2、概率和深度学习
概率论在深度学习中的应用广泛,它帮助我们理解模型的不确定性、推理和决策过程。
概率可以用来表示模型的准确率。概率可以用来描述模型的不确定性。概率可以作为模型损失的度量。
概率在深度学习中的作用包括:
- 模型的不确定性:如在贝叶斯神经网络中,权重是随机变量,通过概率表示模型的不确定性。
- 损失函数的定义:如交叉熵损失函数,是基于概率的度量。
- 生成模型:如变分自编码器(VAE)和生成对抗网络(GANs)都基于概率理论来生成新数据。
3、概率的研究
3.1 频率学派(Frequentist Probability)
频率学派定义概率为长期重复试验中事件发生的相对频率,即在无限次试验中,某事件发生的频率会趋近于某个稳定值。因此概率计算公式
,即
注:n是实验的总次数
3.1.1 典型应用:
- 大规模的实验数据,如质量控制中的产品抽样检验、医学研究中的临床试验等。
3.1.2 不足之处:
- 依赖大量实验:频率学派的定义依赖于无限次的重复实验。实际中,我们往往只能进行有限次实验,尤其在某些领域(如医学、天文),难以进行大量实验,这使得频率定义的概率无法准确反映现实情况。
- 不能处理单次事件:频率学派无法为一次性事件(如某个人是否会罹患某种疾病)提供合理的概率估计。这种情况使得频率学派在许多实际场景中无法给出明确答案。
- 不能处理主观信念:频率学派仅依赖于观察数据,无法量化基于个人信念或历史经验的主观判断。这在某些领域(如预测未来事件)表现出局限性。
3.2 古典学派(Classical Probability)-- 平均主义的倡导者
无法掌握先验知识的情况下,未知事件发生的概率都是相等的。
古典学派的概率理论起源于17世纪,基于对称性和等可能性概念进行推导。它的基本思想是:如果一个实验的所有可能结果数量有限,并且这些结果的发生机会是均等的,那么事件A的概率可以定义为
3.2.1 典型应用:
- 抛硬币、掷骰子等简单实验,其中所有结果都是等可能的。
3.2.2 不足之处:
- 依赖于等可能性假设:古典学派要求所有结果的发生是等可能的,但在实际问题中,等可能性常常难以实现。例如,无法保证现实生活中的每个事件都是等概率的。
- 不适合复杂问题:对于较为复杂的现象(如金融市场或生物实验),结果往往不具有对称性和等可能性,古典学派的适用性有限。
- 主观性限制:古典学派的概率值只能用于那些有明确对称结构的情况,缺乏普遍性。
3.3 贝叶斯派(Bayesian Probability) -- 探索未知世界的观察者
频率学派认为概率是随机性,贝叶斯派认为概率是不确定性的 。
贝叶斯学派将概率视为一种对不确定事件的主观信念或程度的度量,概率可以根据新的证据进行更新。贝叶斯定理是贝叶斯学派的核心,表示为:
- P(A∣B) 是在B发生的情况下A发生的概率,称为A的后验概率。
- P(B∣A) 是在A发生的情况下B发生的概率。
- P(A) 是A的先验概率,即不考虑B的情况下A发生的概率。
- P(B) 是B的先验概率,即不考虑A的情况下B发生的概率。
贝叶斯学派允许通过新的证据不断更新概率,这使得它在处理动态和不确定性方面表现优异。
3.3.1 典型应用:
- 贝叶斯分类器:如朴素贝叶斯分类器,用于文本分类、垃圾邮件过滤等。
- 贝叶斯神经网络:在深度学习中用于建模参数的不确定性。
- 推理与决策:贝叶斯方法广泛应用于医疗诊断、金融预测和科学推理。
3.3.2 不足之处:
- 先验分布的主观性:贝叶斯学派需要假设一个先验概率,这通常基于经验或主观判断,因此在某些情况下可能存在人为偏差。如果先验信息不准确,后验结果可能会有偏差。
- 计算复杂性:贝叶斯方法在处理复杂模型时计算量很大,尤其是当需要通过积分计算后验概率时,通常需要使用近似方法(如蒙特卡洛模拟),增加了计算难度。
- 数据依赖性:贝叶斯方法在小样本条件下可能效果不佳,因为当数据不足时,后验概率过于依赖主观先验,导致推断不准确。
3.4 各学派的优缺点对比
| 学派 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 古典学派 | 简单易懂,适用于对称性强、结果均等可能的情况 | 仅适用于等可能事件,无法处理复杂问题或主观概率 | 适合简单且对称的实验, 但在复杂问题中力不从心 |
| 频率学派 | 基于实验数据,提供长期稳定的概率估计 | 无法处理一次性事件,依赖大量实验,不能处理主观信念 | 适用于大规模实验数据, 但在处理小样本或一次性事件时效果不佳 |
| 贝叶斯学派 | 允许通过新证据更新概率,能够处理主观信念和先验知识,灵活性强 | 先验分布的选择带有主观性,复杂模型计算复杂度高,可能对小样本数据过于依赖 | 以其灵活性和动态更新能力,成为不确定性推断中的强大工具, 但也因其依赖先验分布和计算复杂性而具有一定挑战性 |
4、概率论和数理统计
4.1 区别和联系
- 概率论研究的是一次事件的结果,即随机事件的发生规律
- 数理统计研究的是总体数据的情况,即如何通过观察数据对随机现象进行推断。
- 概率论是数理统计的基础(概率论中的知识,如分布、联合概率等,是数理统计中推导和估计的基础),数理统计则是根据观测的数据反向思考数据生成的过程
| 方面 | 概率论 | 数理统计 |
| 研究对象 | 随机现象及其规律 | 从数据中推断未知参数或现象 |
| 核心问题 | 计算事件发生的概率 | 从样本数据推断总体特征,估计参数 |
| 工具 | 随机变量、概率分布、联合概率、条件概率等 | 假设检验、点估计、区间估计、回归分析等 |
| 应用领域 | 主要用于理论分析 | 主要用于实际数据分析,尤其是在实验设计和数据分析中 |
| 关联 | 概率论为数理统计提供理论基础 | 数理统计基于概率论进行推断 |
5、事件(Event)
- 事件:指随机试验结果的一个集合, 例如,在掷一枚骰子的试验中,“出现偶数”就是一个事件,它包含了{2, 4, 6}这三个可能的结果。
- 随机事件(Random Event):指一次或多次随机实验的结果,即在一次实验中可能发生也可能不发生的事件。比如抛硬币,出现正面是随机事件。
- 依赖事件(Dependent Events):指的是事件的发生受其他事件的影响,。例如,从不放回抽卡中,抽到一张特定卡的概率会随着已抽卡变化。用条件概率表示同时发生的概率:
表示在事件A已经发生的条件下,事件B发生的概率
- 独立事件(Independent Events):指的是事件的发生与其他事件无关,例如,抛两次硬币,第一次结果不影响第二次。
6、随机变量
随机变量是定义在样本空间上的函数,用来表示每个实验结果的数值。分为离散型和连续型。
7、概率分布
概率分布用来描述随机变量的分布情况。
在离散型分布中,通过概率质量函数(PMF)描述每个值的概率;
在连续型分布中,我们通过概率密度函数(PDF)描述概率的密度。
- 离散型分布:
定义:随机变量只能取有限个或可数个值,其概率通过概率质量函数(PMF)来表示。
常见的离散型分布:
- 二项分布:描述了n次独立的伯努利试验中成功的次数。
- 泊松分布:用于描述在单位时间内某个事件发生的次数。
- 连续型分布:
定义:随机变量可以取无限个值,其概率通过概率密度函数(PDF)来表示。
常见的连续型分布:
- 均匀分布:所有值的概率密度相同。
- 正态分布:又称为高斯分布,描述自然界中广泛存在的随机现象。
正态分布的概率密度函数为:
( 其中,μ是均值,σ^2是方差)
8、概率密度(Probability density)
一种描述概率分布的函数,表示在某一区间内取一个特定值的概率
概率=概率密度曲线下的面积
9、正态分布(Normal Distribution)
也称为高斯分布(Gaussian Distribution)。
正态分布由两个参数完全描述:均值(mean)𝜇 和方差(variance)𝜎^2。均值决定了分布的中心位置,而方差则决定了分布的宽度。正态分布概率密度函数:
,其中 𝑒e 是自然对数的底数,大约等于 2.71828
正态分布的性质
- 对称性:正态分布是以均值为中心的对称分布。
- 峰度:标准正态分布(均值为 0,方差为 1)具有最高的峰度(kurtosis),其峰度值为 3。
- 尾部:正态分布有轻尾特性,即极端值出现的概率相对较小。
- 68-95-99.7规则(经验法则):对于任何均值和方差的正态分布,大约 68% 的值落在均值的一个标准差内,大约 95% 的值落在均值的两个标准差内,大约 99.7% 的值落在均值的三个标准差内。
10、联合概率和条件概率
- 联合概率:多个事件同时发生的概率,对于两个事件A和B,联合概率记为
- 条件概率:在某个条件下发生某个事件的概率,记为
条件概率在深度学习中的应用包括朴素贝叶斯分类器,它假设每个特征是条件独立的。
联合概率和条件概率的转化:
即
11、贝叶斯定理
表明在已知条件概率的情况下,可以推导出联合概率。常用于,根据已知信息预测未知信息的场景
贝叶斯定理在深度学习中的应用之一是贝叶斯神经网络。
12、先验(Prior) 后验(Posterior)
- 先验概率:在观测到数据之前,对参数的初始信念。
反映了我们对模型参数或隐变量在看到数据之前的信念。它是我们基于已有知识对参数 𝜃θ 的初始估计。在数学上,可以表示为 𝑃(𝜃)。
- 后验概率:根据观测数据,利用贝叶斯定理更新后的概率分布。
13、极大似然估计(Maximum Likelihood Estimation MLE)
利用已知的样本结果,反推最有可能导致这样结果的参数值,即找到参数的最大概率取值
定义:假设我们有一组观测数据 ,并且假设数据是由某个参数化的概率分布
生成的,这里的 θ 表示未知的参数向量。
我们的目标是找到 θ 的最优估计值 ,使得观测数据 D 在该参数下的概率最大。
为了实现这个目标,我们可以定义似然函数 𝐿(𝜃∣𝐷) 为给定参数 θ 下数据 D 的联合概率:
这里假设每个观测 是独立同分布(i.i.d.)的。由于直接计算联合概率可能不方便,通常会取对数来简化乘积运算,并且对数函数是单调递增的,因此极大化似然等价于极大化对数似然:
然后,我们寻找参数 θ 的值,以最大化上述对数似然函数。即求解:
在深度学习中的应用
在深度学习中,模型通常是一个复杂的神经网络,其中参数 𝜃θ 包括权重和偏置项。训练一个神经网络的目标就是调整这些参数,以便正确地映射输入数据到输出数据。使用 MLE 作为训练目标意味着我们希望找到一组参数,使得网络对于训练集上的所有样本都能产生正确的预测概率分布。
例如,在分类任务中,我们可能会使用softmax层来将模型的输出转换为类别概率分布。在这种情况下,我们通常使用交叉熵损失(cross-entropy loss),它是对数似然的一种形式,来度量模型的预测与实际标签之间的差异,并通过最小化这个损失来训练模型。
总之,极大似然估计是一种强大的工具,可以帮助我们在机器学习和深度学习中找到合适的模型参数。