Generative Variational-Contrastive Learning for Self-Supervised Point Cloud Representation | IEEE Transactions on Pattern Analysis and Machine Intelligence (acm.org)
作者:Bohua Wang; Zhiqiang Tian; Aixue Ye; Feng Wen; Shaoyi Du; Yue Gao
摘要
三维点云的自监督表示学习受到了越来越多的关注。然而,现有的3D计算机视觉领域的方法通常使用固定的嵌入来表示潜在特征,并对嵌入施加硬约束,以使正样本的潜在特征值趋于一致,这限制了特征提取器在不同数据域上的泛化能力。为了解决这个问题,我们提出了一个生成变分对比学习(GVC)模型,其中使用高斯分布来构建潜在特征的连续、平滑表示。构建了分布约束和交叉监督,以提高特征提取器在合成和真实世界数据上的迁移能力。具体来说,我们设计了一个变分对比模块来约束特征分布,而不是潜在空间中每个样本对应的特征值。此外,引入了一个生成交叉监督模块,以保留不变特征并促进正样本间特征分布的一致性。实验结果表明,GVC在不同的下游任务上实现了最先进的性能。特别是,仅在合成数据集上预训练,GVC在转移到真实世界数据集时,在线性分类和少样本分类上分别取得了8.4%和14.2%的领先优势。
关键词
-
对比学习
-
生成学习
-
点云
-
自监督
-
变分推断
I. 引言
如今,3D视觉已广泛应用于自动驾驶汽车、机器人、增强现实等领域。作为一种常见的数据结构,点云为3D对象提供了简洁的表示,并促进了3D视觉的发展。通过雷达或深度相机可以轻松获取点云数据,点云数据处理已成为3D视觉研究的重要领域。近年来,深度学习已被引入到点云表示学习中,并在分类、分割、目标检测等任务中表现良好。然而,这些基于深度学习的方法高度依赖于大量标记数据,这需要大量的人力成本来标记每个样本。近年来,自监督学习在文本和图像处理领域取得了显著成果。相关工作将自监督学习引入到3D视觉中,它们使用生成、对比等预文本任务来预训练特征提取器。通过这些预文本任务,这些模型使得基于深度学习的特征提取器能够在没有手动标记的情况下提取点云的潜在特征。
然而,获取和构建真实世界的实例级点云数据集比捕获图像需要更多的人力和设备成本。像ImageNet一样构建一个包含数百万样本的点云数据集是困难的。相比之下,合成数据更容易获得。因此,现有的点云自监督模型通常在具有高数据量的合成数据集上进行预训练,然后将特征提取器迁移到真实世界数据集以执行下游任务。然而,数据域之间的差异导致先前自监督方法在合成数据和真实世界数据之间的性能差距很大(图1)。在少样本分类中,这种差距更为显著,其中特征提取器的泛化能力要求更高。因此,如何提高点云特征提取器在合成和真实世界数据域的自适应能力仍然是一个紧迫的问题。
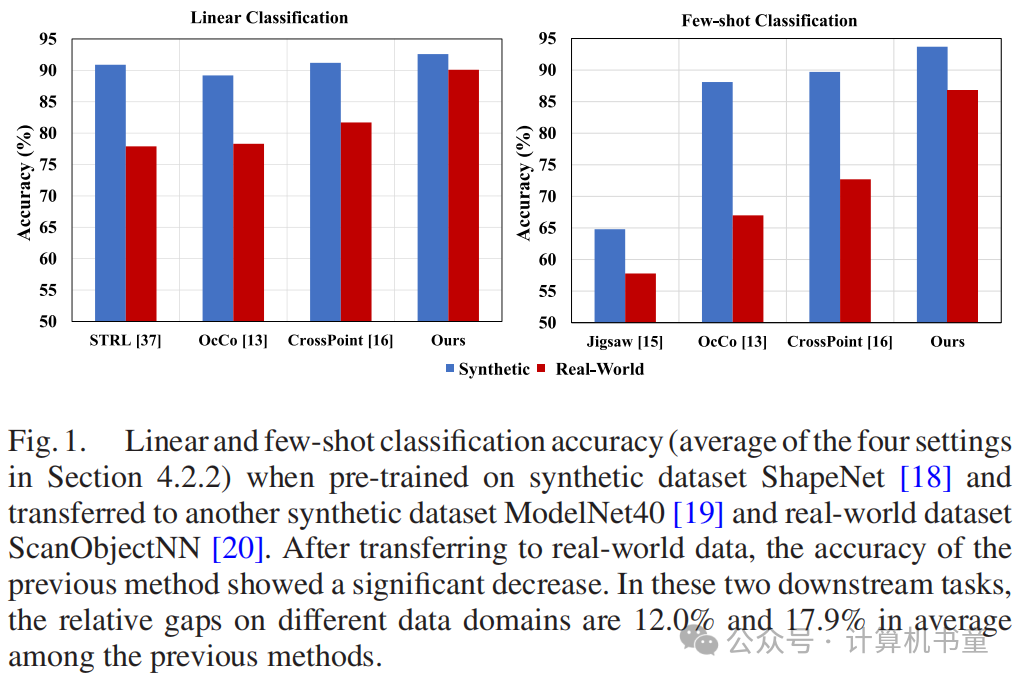
现有的点云自监督学习方法通常在合成数据集上进行预训练,因为这些数据集是通过CAD合成的,具有大量的数据、丰富的类型和低建设成本。然而,现有的点云3D对比学习方法主要遵循SimCLR或MoCo的框架,将样本投影到高维空间以获得固定潜在特征,并对其相似性施加硬约束。这些模型在相同的合成数据集上表现良好,但在转移到更具挑战性的真实世界数据集时性能显著下降。我们可以观察到,合成数据中的点是均匀分布的,没有局部信息缺失和噪声很少,而真实世界数据容易受到噪声和异常值的影响,不同区域的点不是均匀分布的(图2)。因此,在这种情况下,如何提高点云表示的泛化能力仍然是一个开放的问题。

为了解决这个问题,我们提出使用分布来构建潜在特征的连续和平滑表示。我们的模型不再约束潜在空间中每个样本对应的特征值,而是它们遵循的分布。与现有方法对潜在特征的硬约束相比,我们的方法可以避免在合成数据域上的过拟合,从而允许特征提取器具有更强的数据域迁移能力。具体来说,我们使用对比学习来约束潜在特征的分布,使得来自同一类别的样本的特征分布趋于相似,并区分不同类别的特征分布。此外,我们将对比学习与生成学习结合起来,提出了一个生成变分对比(GVC)模型,旨在整合生成学习与对比学习的优势,使我们的模型在保留不变特征的同时关注类别间的差异。而且,我们的生成交叉监督模块使用交叉监督而不是传统的自监督来促进正样本间特征分布的一致性。与应用于图像处理的对比学习模型不同,GVC不需要像SimCLR那样构建一个巨大的负样本库,这在训练中需要大量的内存,也不需要像MoCo那样以动量方式更新参数。据我们所知,我们的GVC是第一个在3D自监督学习领域使用对比学习来约束由高斯分布表示的潜在特征的模型。
我们的主要贡献如下:1)我们提出了一种变分对比学习用于自监督点云表示。变分对比学习约束特征分布而不是潜在空间中每个样本对应的特征值,旨在避免对潜在特征值的硬约束,并提高编码器的泛化能力。2)我们提出了一个生成交叉监督模块,并将其与我们的变分对比学习结合起来。它旨在使特征提取器在正样本间促进特征分布的一致性并保留不变点云特征。3)我们提出了一个分布对比损失(DCLoss)来约束潜在特征分布。DCLoss约束相同类别的特征分布趋于相似,并区分不同类别的特征分布。
本文的其余部分组织如下。首先,我们在第二节简要介绍3D领域自监督学习的相关工作。在第三节中,我们提出了我们提出的GVC模型的动机。第四节介绍了在一系列下游任务上的实验。最后,我们在第五节中得出结论。
III. 方法
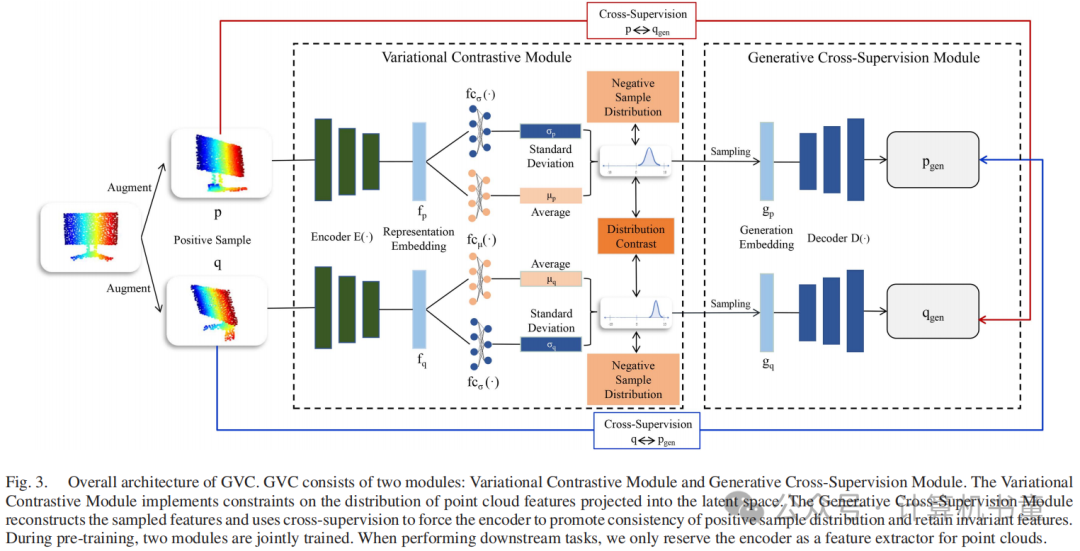
在本节中,我们介绍了用于自监督3D点云表示学习的框架GVC。图3展示了GVC的框架。如图3所示,我们的模型由变分对比模块和生成交叉监督模块组成。变分对比模块使用高斯分布来表示平滑的潜在特征,并将传统的潜在特征对比替换为特征分布对比。生成交叉监督模型从两个样本的特征分布中采样生成嵌入,采用共享权重解码器生成3D点云,然后通过交叉监督计算生成的点云和输入点云之间的重建损失。我们从三个方面介绍我们的模型。首先,我们陈述了GVC的动机。然后,我们展示了两个模块的详细实现。最后,我们推导出GVC的损失函数。
A. 动机
我们的自监督模型的目标是学习一个可扩展的编码器,该编码器可以有效地转移到在其他数据集上执行的下游任务。为了在没有标签的情况下实现这个目标,我们需要设计一个特定的预文本任务,以帮助点云编码器从数据中提取足够的信息,以提高其编码能力。对比学习是一种广泛使用的预文本任务。现有的基于对比的3D自监督学习方法[16]、[27]、[28]关注样本的潜在特征之间的一致性。它们直接对潜在特征施加硬约束,使正样本的潜在特征值趋于一致性。然而,在不同数据域下的实例对象存在很大差异,因此特征值也存在很大差异。由于训练数据有限,导致泛化能力有限以及领域迁移能力较弱。为了解决这个问题,我们提出了变分对比学习(VC)。VC约束特征分布而不是潜在空间中每个样本对应的特征值。VC的目标是使正样本特征的分布趋于相似,同时区分正样本和负样本之间的分布。目的是避免对潜在特征值的硬约束,提高编码器的泛化能力。
此外,对比学习会使模型倾向于关注样本的某些特定关键部分,这对模型的泛化能力也有负面影响。因此,我们的目的是引入生成性监督以保留不变特征。然而,传统的自重建方法会导致模型专注于全局坐标特征。专注于全局坐标特征对点云特征提取器的泛化能力有负面影响[4]。因此,我们提出了生成交叉监督,它使用两种不同数据增强得到的正样本相互监督,使模型保留更多的不变特征。此外,由于生成嵌入是通过从正样本的特征分布中采样获得的,交叉监督也有助于促进正样本分布的一致性,这也是变分对比学习优化目标的一部分。
B. 下游任务
在本节中,我们通过五个不同的下游任务来验证GVC的有效性和泛化性,包括对象分类、少样本学习、部分分割、语义分割和3D对象检测。
-
对象分类。数据集:在对象分类任务中,选择了3D合成数据集ModelNet40和真实世界数据集ScanObjectNN,这些数据集在之前的研究中被广泛使用。这两个数据集用于验证所提出的自监督模型的有效性和领域迁移能力。ModelNet40包含40个类别,12331个3D对象,9843个样本用于训练,2468个样本用于测试。与ShapeNet一样,3D对象由CAD合成。ScanObjectNN数据集包含15个类别,2890个真实世界3D样本,2309个样本用于训练,581个用于测试。在训练中,与其他自监督模型[16]、[17]一样,从每个3D模型中随机选择1024个点作为样本。
线性分类:线性分类是评估自监督模型迁移和泛化能力的常用方法。实验设置与其他自监督模型[13]、[16]、[23]一致。在分类数据集上,将预训练的编码器冻结,并编码训练集和测试集为特征嵌入和,然后在上训练线性SVM分类器,并在上进行测试。SVM的线性分类准确率反映了我们自监督模型的区别和泛化能力。在这样的实验设置下,编码器没有在标记数据上进行训练。因此,实验结果可以尽可能多地反映模型的泛化能力和领域迁移能力。在线性分类实验中,广泛使用的特征提取模型DGCNN被用作编码器。
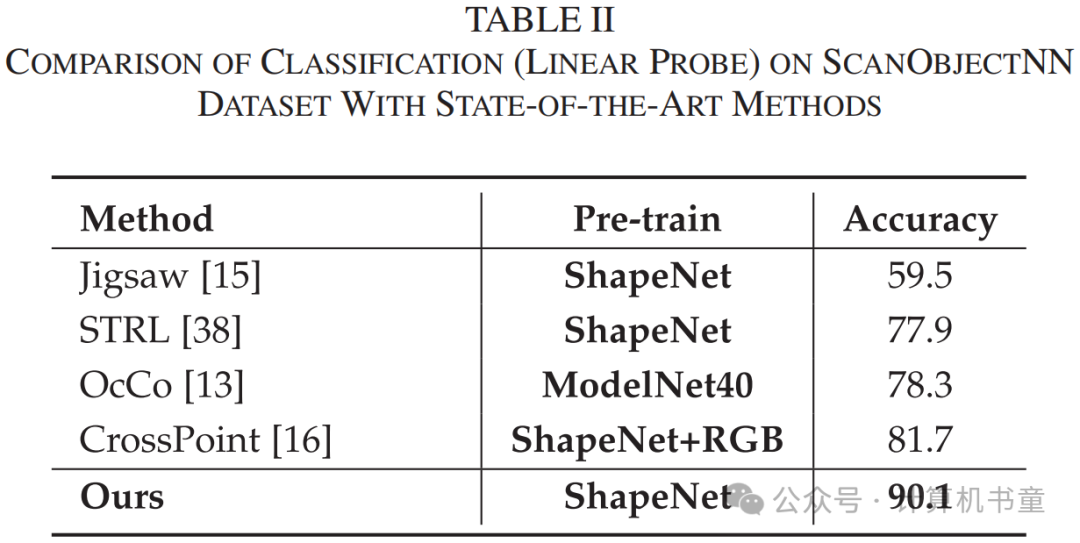
如表I所示,可以观察到我们的方法在ModelNet40数据集上的线性分类准确率超过了其他最新的自监督方法。我们的方法特别是在ScanObjectNN数据集上,与其他自监督模型相比,准确率有显著提高(8.4%)。比较表II和表IV,可以观察到在真实世界数据上,DGCNN的线性探针准确率接近微调准确率。值得注意的是,我们的模型仅在合成数据集上进行预训练,并直接使用预训练模型编码真实世界数据集,实验结果表明我们的模型有效提高了编码器在不同数据域之间的迁移能力,使编码器在真实世界数据集上保持良好效果。

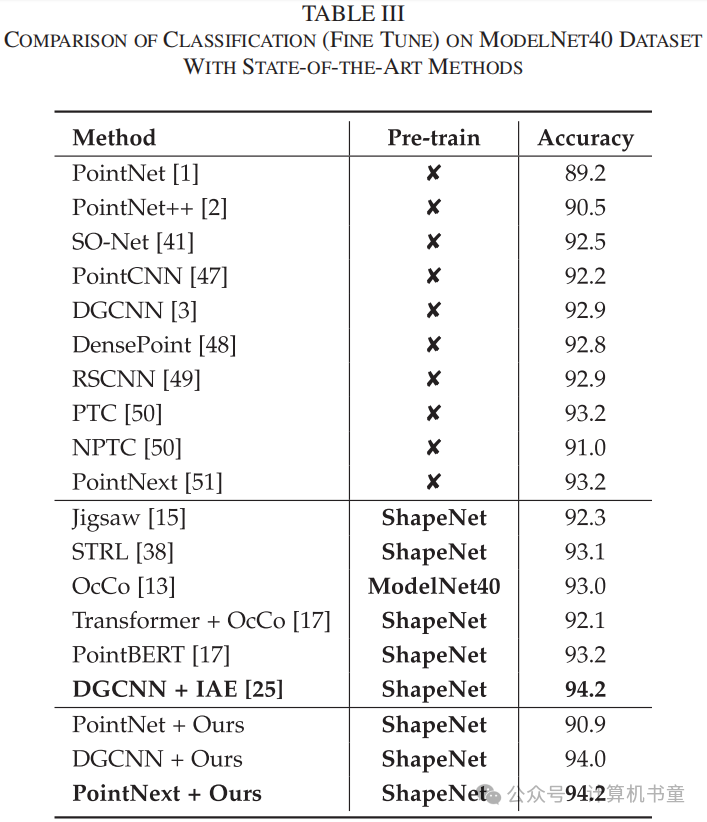
微调:与一些先前模型[13]、[17]一样,在编码器上添加一个MLP作为分类头,并在标记数据集上微调整个模型。在微调期间,批量大小设置为64,余弦退火用作学习率调度策略,权重衰减设置为。模型训练300个周期。在ModelNet40数据集上,使用SGD作为优化器,初始学习率设置为0.1,动量设置为0.9。在ScanObjectNN数据集上,使用AdamW作为优化器,初始学习率设置为0.001。表III和表IV报告了在ModelNet40和ScanObjectNN数据集上使用PointNet、DGCNN和最新点云特征提取器PointNext作为编码器时的微调准确率。我们的方法使所有编码器都比未经预训练的模型取得了更好的结果。在真实世界数据集(ScanObjectNN)上,我们的GVC展示了卓越的领域泛化能力,并实现了最高准确率。在合成数据集(ModelNet40)上,基于隐式自编码器的方法IAE[25]也展示了出色的性能。此外,作为一个通用的自监督模型,我们的方法在两个数据集上都超过了特别为变换器设计的PointBERT[17]。
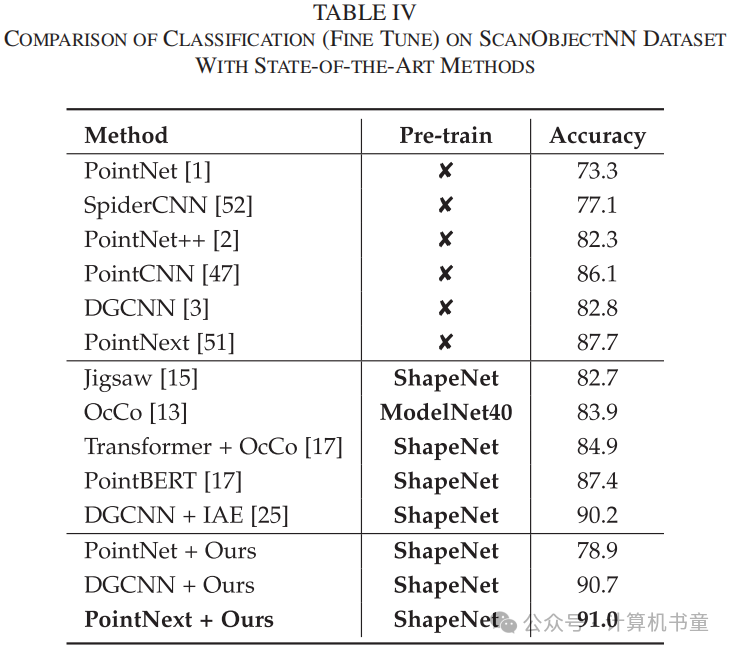
-
少样本学习:少样本学习也称为N-way K-shot学习,旨在使用少量样本进行训练,同时使模型能够识别新类别。在实验中,数据集被分为两部分,支持集和查询集。在支持集中,每个类别(N-way)随机选择N个类别和K个样本(K-shot)。像[16]一样,这些N×K个样本被预训练的编码器编码,并获得的N×K个特征嵌入作为训练集。对于每个类别,从查询集中随机提取20个样本。同样,这些样本被编码为20×K个特征嵌入作为测试集。在线性少样本学习中,使用线性SVM作为分类器在训练集上进行训练,并在测试集上进行测试。与比较方法一样,PointNet、DGCNN和PointNext作为编码器在ModelNet40和ScanObjectNN数据集上进行实验。每个设置下进行十次实验,报告平均性能和标准差。表V和表VI显示了在ModelNet40和ScanObjectNN数据集上进行线性少样本学习的准确率。两个表格表明,仅在ModelNet40上使用PointNet作为编码器的一个设置没有达到最先进水平。在所有其他实验设置中,我们的方法都取得了更高的准确率。比较表V和表VI,可以观察到以前的方法,如CrossPoint和OcCo,在合成数据集上可以获得良好的准确率。然而,当转移到真实世界数据集时,准确率显著下降。我们模型的准确率在真实世界数据集上显著提高。在ScanObjectNN数据集上,当使用DGCNN作为我们的编码器时,四个设置中的改进高达约14.2%,包括在“10-way 10-shot”设置中的改进高达16.9%。实验结果表明,与其它方法相比,我们的模型在领域迁移能力和泛化能力上有显著改进。
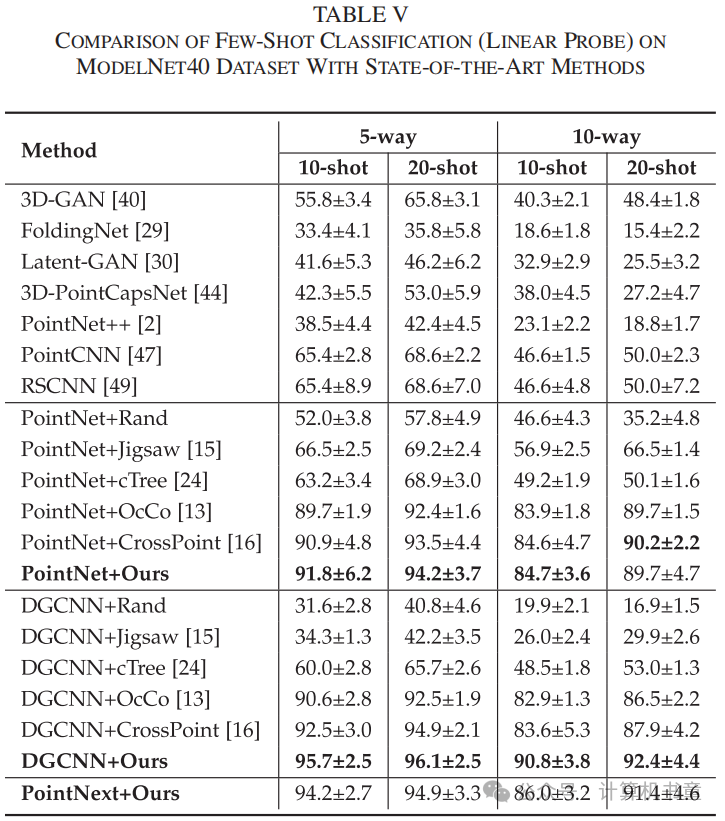
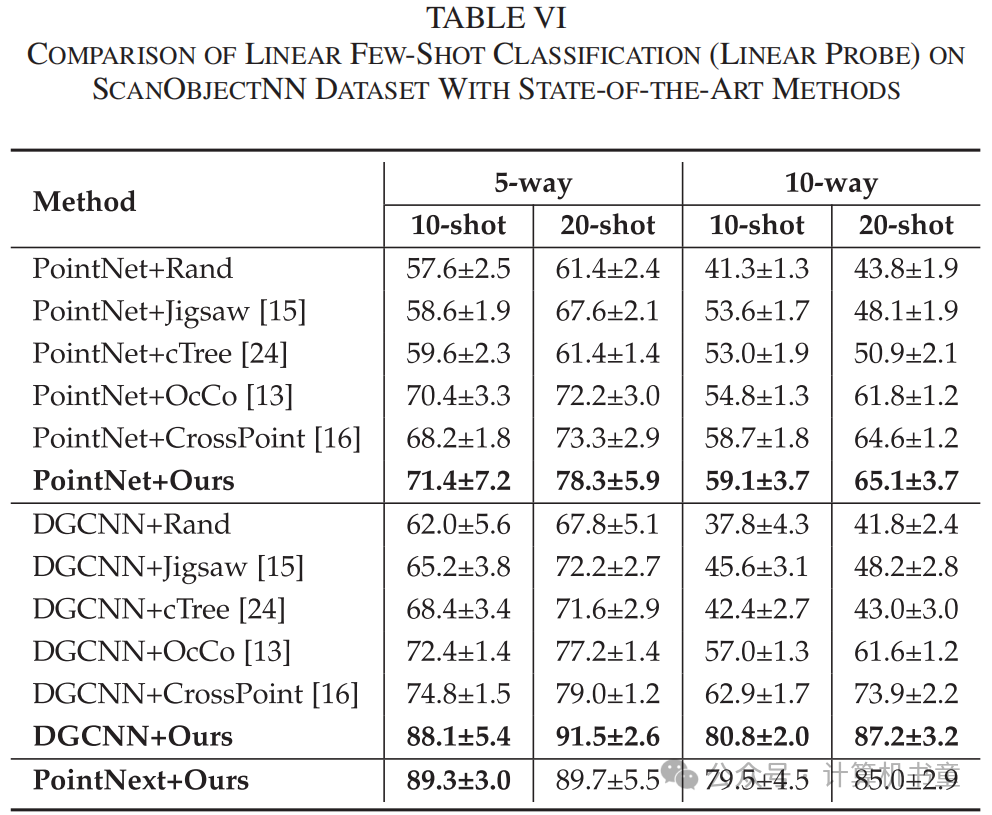
-
部分分割:与分类任务不同,部分分割是密集预测任务,更具挑战性。它要求神经网络预测点云中每个点的部分,这测试了对点云细粒度信息的编码能力。部分分割实验在ShapeNetPart上进行,包含16个类别,16881个3D模型,总共50个部分。首先,使用所提出的模型对DGCNN部分分割模型进行预训练,然后在ShapeNetPart数据集上进行微调。在实验中,使用SGD作为优化器,初始学习率设置为0.1,权重衰减为。默认动量为0.9,批量大小为16。模型训练400个周期。常用的分割评估指标IoU(交并比)用于衡量部分分割任务的性能。表IX报告说,我们的模型不仅比随机初始化参数的监督模型提高了0.6%,而且比其他自监督模型提高了0.2%。可视化结果如图4所示。从图4中可以观察到,我们模型的分割效果非常接近真实情况。实验结果表明,我们的模型在一定程度上保持了对点云细粒度信息的良好性能。

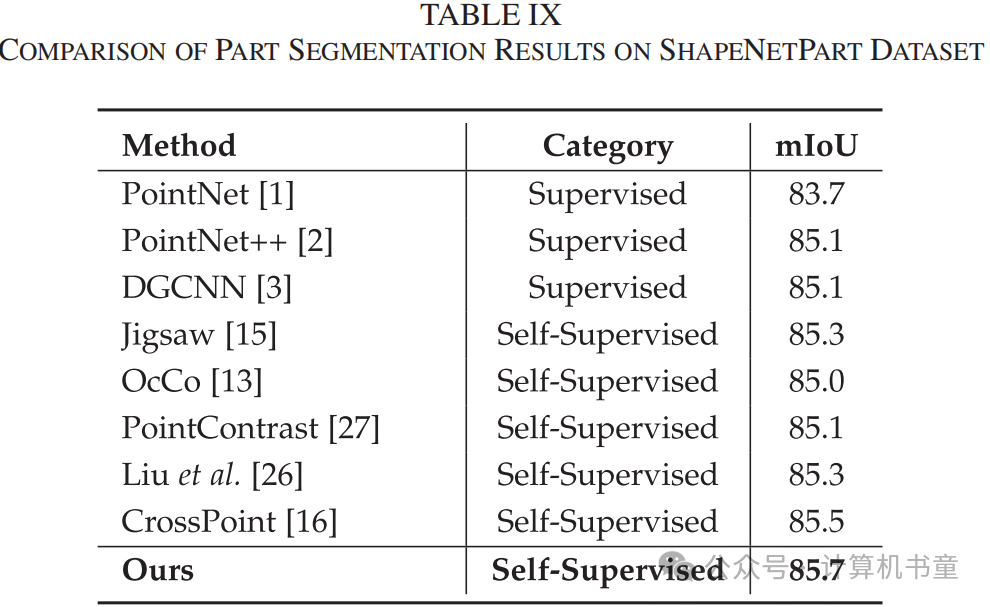
-
语义分割:与部分分割不同,语义分割任务需要对场景级点云进行密集预测,这进一步增加了实验的挑战性。实验在Stanford Large-Scale 3D Indoor Spaces (S3DIS)数据集[52]上进行,这是一个广泛使用的3D点云语义分割数据集。S3DIS包含6个大型室内区域,271个房间,每个点都标注有13个类别之一。按照Qi等人[1]的方法,将房间划分为1米×1米的块,每个块随机抽取4096个点。由于S3DIS数据集包含RGB特征,与其他任务不同,语义分割任务的编码器是在包含RGB特征的ShapeNet数据集上进行预训练的。在实验中,使用DGCNN和PointNext作为编码器。与其他方法一致,我们采用6折交叉验证来评估模型,6个实验结果的平均值作为最终结果。
如表VIII所示,与从头开始训练相比,GVC在DGCNN和PointNext上都取得了改进。与其他预训练方法相比,当使用DGCNN作为编码器时,GVC在总体准确率和mIoU上仍然分别提高了1.4%和1.2%。这表明GVC在点云的实例级别和场景级别之间仍然具有更好的泛化能力。

-
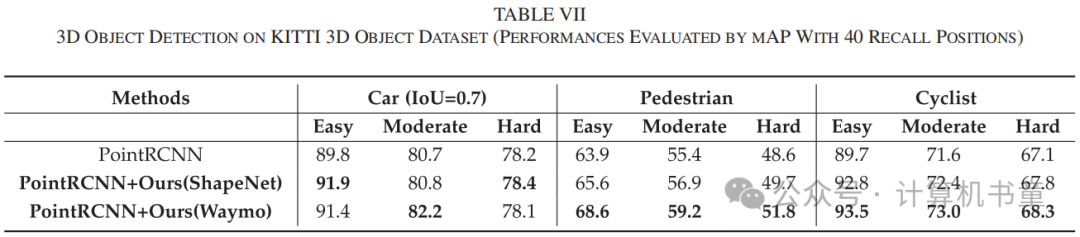
3D对象检测:3D对象检测要求检测模型预测对象的边界框位置和类别。它广泛应用于自动驾驶场景中。KITTI 3D Object[53],一个广泛使用的户外对象检测数据集被采用在我们的实验中。KITTI 3D由3712张训练图像、3769张验证图像和7518张测试图像组成,以及相应的点云(实验中仅使用点云)。与ScanObjectNN数据集不同,后者也是扫描真实世界场景的,KITTI数据集中的点云是使用激光雷达在户外收集的,更加稀疏、分布不均匀,因此更具挑战性。
在这项任务中,我们采用了两组实验设置。首先,我们在与KITTI数据集类似的Waymo Open数据集上进行预训练。此外,为了验证GVC的迁移能力,模型在ShapeNet数据集上进行预训练。在实验中,使用轻量级对象检测算法PointRCNN[54]作为基线。在实验中,移除了检测头,并对特征提取器进行了预训练。具体来说,在空间维度上的特征提取器的最后一层之后添加了一个最大池化层,以获得表示嵌入。
表VII表明,在GVC预训练后,三个不同类别的性能在不同难度级别(简单、中等和困难)上都有所提高。值得注意的是,GVC不仅在Waymo数据集上预训练时取得了显著结果,而且在与KITTI有显著领域差异的ShapeNet数据集上预训练时,也在一定程度上提高了对象检测能力。
C. 消融研究
在本节中,我们从三个方面进行消融研究:泛化性、架构和损失函数。为了更好地探索自监督模型的表达力和泛化能力,使用线性分类作为下游任务来衡量不同策略下实验效果的差异。在实验中,所有编码器都在ShapeNet上进行预训练,并转移到ScanObjectNN和ModelNet40数据集上进行下游任务。
-
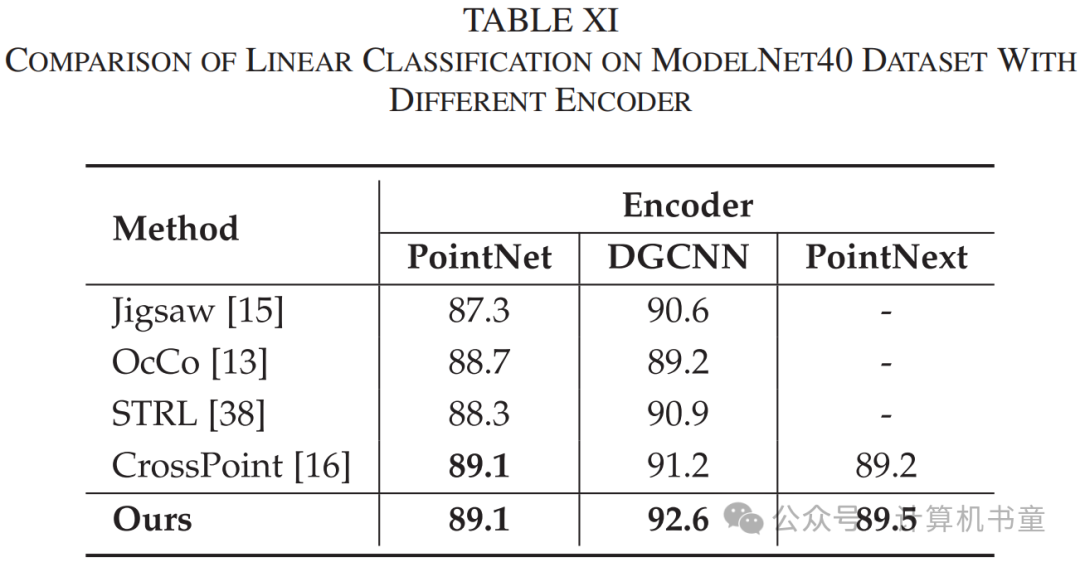
泛化性:为了验证GVC的泛化性,实验中使用了最广泛使用的PointNet、DGCNN和最新模型PointNext作为编码器。表X和表XI显示了在三种不同编码器下GVC的准确率,并与几种其他最近的自监督方法进行了比较。实验结果表明,使用PointNet、DGCNN和PointNext作为编码器时,GVC都取得了最佳结果。其中,使用DGCNN作为编码器的领先优势达到了8.4%。

-
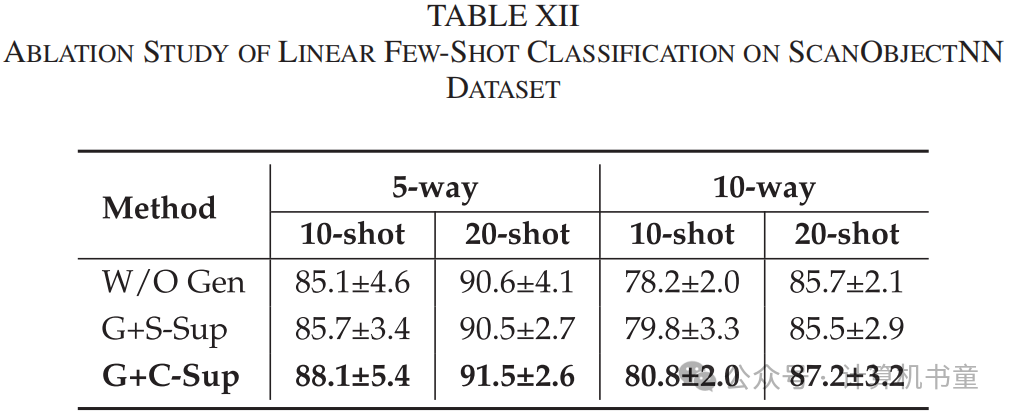
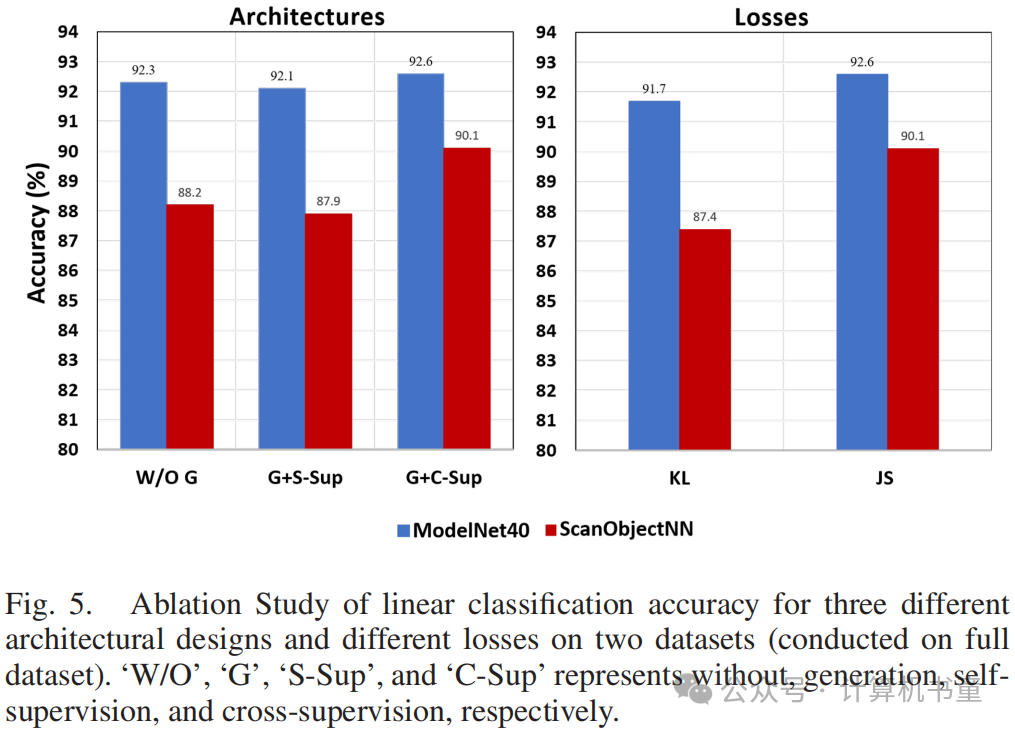
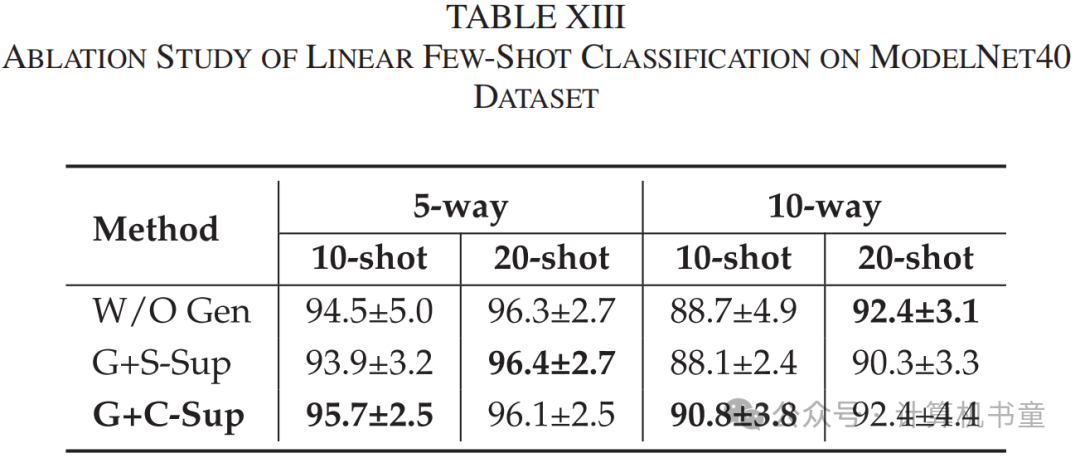
架构:在本节中,我们探索了三种不同的架构设计,包括仅变分对比模型、变分对比+自监督生成模型和变分对比+交叉监督生成模型。比较了在DGCNN作为编码器的情况下,这三种设计在线性(在完整数据集上进行)和少样本分类任务上的准确率。如图5(左图)、表XII所示,GVC架构在ScanObjectNN数据集上取得了最佳的线性和少样本分类结果,表明交叉监督模块可以提高编码器的泛化能力。然而,由于数据域相似(ShapeNet和ModelNet40都是合成数据),它在ModelNet40数据集上没有带来显著改进(见图5、表XIII)。此外,结果表明,当使用传统的自监督方法进行训练时,准确率会下降。因为自监督只关注每个点的位置重建。然而,专注于全局坐标特征对点云特征提取器的泛化能力有负面影响[4]。交叉监督方法使得重建点云的位置和真实情况不完全相同,这迫使编码器学习共同的不变特征,并促进两个正样本特征分布的一致性。
-
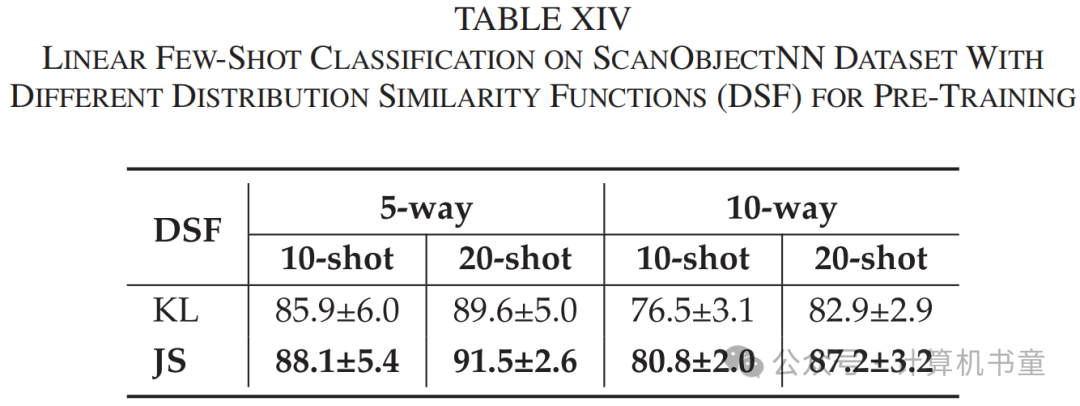
损失函数:在本节中,我们探索了损失函数中使用的两种不同的分布相似性函数,即非对称KL散度和对称JS散度。与IV-C2节中的实验设计相同,使用线性和少样本分类任务来验证对比学习中使用对称函数的重要性。在实验中,使用DGCNN作为编码器,我们将完整模型(Gen + CrossSupervision)设置为架构。图5还显示了当使用两种不同的散度计算分布相似性函数时的线性分类结果。实验结果表明,与KL散度相比,使用JS散度时准确率有所提高,无论是在ScanObjectNN还是ModelNet40数据集上。此外,表XIV和表XV表明,在选择JS散度进行少样本学习时,分类准确率显著提高。

D. 可视化
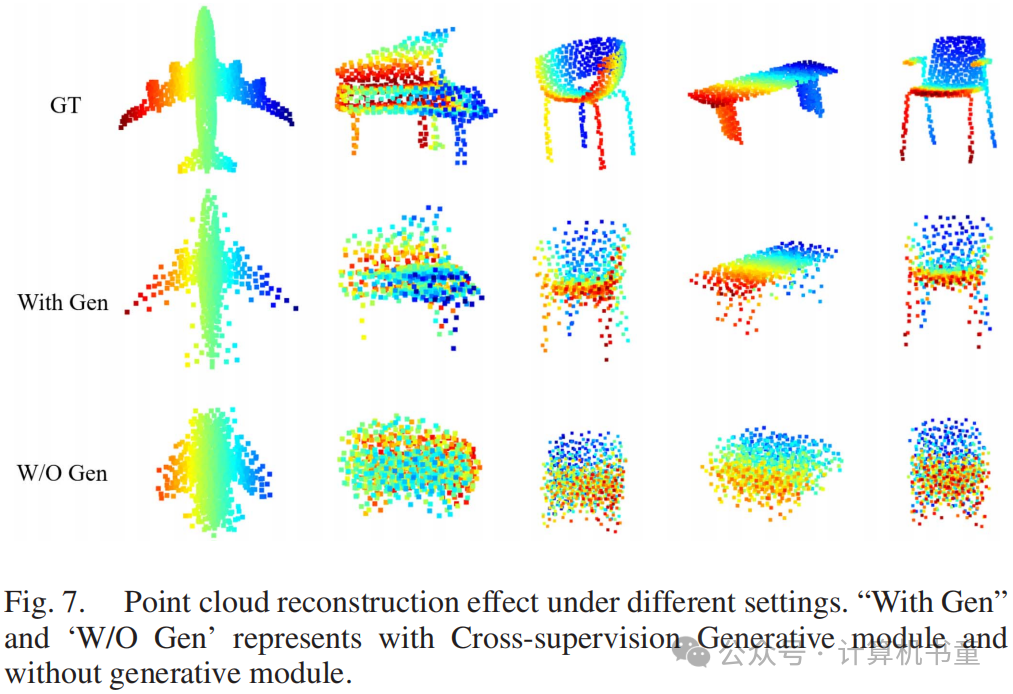
为了更直观地表示GVC自监督预训练的效果,使用t-SNE[55]对特征进行降维和可视化。图6显示了在ModelNet40和ScanObjectNN数据集上的结果。图(a)和(d)是通过在两个数据集上仅使用监督训练获得的。图(b)和(e)是通过在ShapeNet数据集上进行GVC预训练,然后直接转移到其他两个数据集上获得的。图(c)和(f)是在预训练+微调后获得的。比较这三组图,可以发现即使没有微调,通过GVC训练的编码器仍然具有良好的类别区分能力,并且比仅使用监督训练的模型更好。特别是在ScanObjectNN数据集上,仅在合成数据集上进行GVC自监督预训练的效果明显优于在ScanObjectNN上进行监督训练。实验结果表明,GVC具有很强的泛化能力,并且可以有效转移到不同类型的数据集上。图(c)和(f)表明,在微调后,编码器的类别区分能力得到了进一步增强。为了探索生成模块是否能够保留不变的几何特征,我们可视化了重建结果。由于通过'W/O Gen'设置训练的模型没有生成能力,我们使用'With Gen'预训练模型,冻结解码器,并仅使用变分对比模块对编码器进行微调。如图7所示,第2、3行显示'With Gen'设置取得了相对完整的重建结果,而没有生成模块时,重建质量显著下降。这表明生成模块能够在一定程度上保留被变分对比模块丢失的不变几何特征。

V. 结论
在本文中,我们提出了一个名为生成变分对比学习的3D自监督学习模型。GVC使用高斯分布来表示点云的潜在特征,并使用对比学习来约束特征分布。此外,生成交叉监督模块用于保留不变特征,并促进正样本分布的一致性。GVC显著提高了自监督学习的领域迁移能力,使其能够有效地在合成和真实世界的点云之间进行迁移。实验结果表明,GVC在对象分类(包括线性和微调)、少样本学习、部分分割和对象检测任务上表现良好。特别是在转移到真实世界数据的实验设置下,我们模型的准确率都取得了显著提高。GVC的思想可以进一步探索,应用于其他领域的自监督学习。







![[Simpfun游戏云1]搭建MC Java+基岩互通生存游戏服务器](https://i-blog.csdnimg.cn/direct/aabde7f742634a2db3d6695450a55f92.png)











