对于活跃的大型 Python 项目而言,维持架构的整洁性是一件颇具挑战的事情,这主要体现在包与包、模块与模块之间,难以保持简单而清晰的依赖关系。
一个大型项目,通常包含数以百记的子模块,各自实现特定的功能,互相依赖。如果在架构层面上缺少设计,开发实践上没有约束,这些模块间的依赖关系,常常会发展成为一个胡乱缠绕的线团,让人难以理清头绪。
这会带来以下问题:
•架构理解成本高:当新人加入项目时,会有许多关于架构的疑问,比方说:既然 common.validators 是一个低层的通用工具模块,为何要引用高层模块 workloads 中的 ConfigVar 模型?•影响开发效率:想要开发新功能时,开发者难以判断代码应放在哪个包的哪个模块中,而且不同的人可能会有不同的看法,很难达成共识•模块职责混乱:依赖关系很乱,基本等同于模块的职责也很乱,这意味着部分模块可能承担太多,关注了不应该关注的抽象
如果把依赖关系画成一张图,一个架构健康的项目的图,看上去应该层次分明,图中所有依赖都是单向流动,不存在环形依赖。健康的依赖关系,有助于各个模块达成“关注点分离”的状态,维持职责单一。
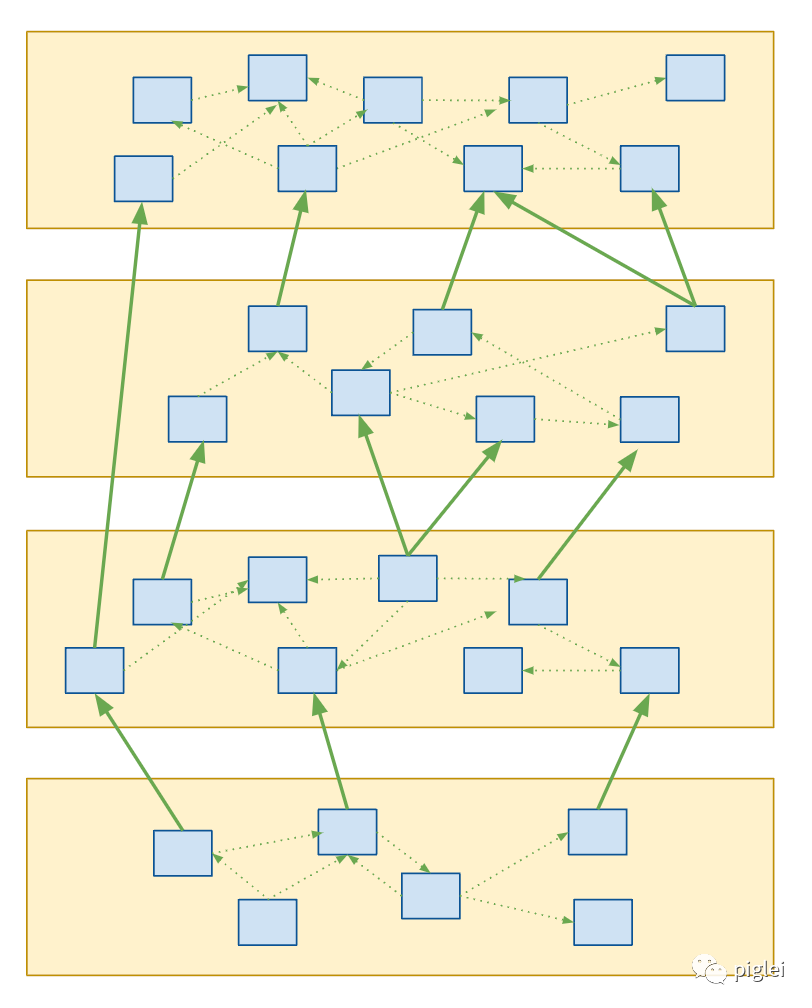
本文介绍一个治理模块间依赖关系的工具:import-linter[1] 。
import-linter 简介
import-linter[2] 是由 seddonym[3] 开发的一个开源代码 Linter 工具。
要使用 import-linter 检查依赖关系,首先需要在配置文件中定义一些“契约(contract)”。举个例子,下面是一份 import-linter 的配置文件:

其中的 [importlinter:contract:layers-main] 部分,定义了一个名为 the main layers 的“分层(layers)”类型的契约,分层契约意味着高层模块可以随意导入低层模块中的内容,反之就不行。
the main layers 设定了一个分层关系: foo_proj.client 模块属于高层,foo_proj.lib 属于低层。
运行命令 lint-imports,工具会扫描当前项目中的所有 import 语句,构建出模块依赖关系图,并判断依赖关系是否符合配置中的所有契约。
假如在项目中的 foo_proj/lib.py 文件里,存在以下内容:

则会导致 lint-imports 命令报错:

只有当我们删除这条 import 语句后,代码才能通过检查。
除了“分层”类型的契约以外,import-linter 还内置了两种契约:
•禁止(forbidden)[4]:禁止一些模块导入你所指定的其他模块•独立(independence)[5]:标记一个列表中的模块互相独立,不会导入其他模块中的任何内容
如果这些内置契约不能满足你的需求,你还可以编写自定义契约,详情可查阅 官方文档[6]。
在项目中引入 import-linter
要在项目中引入 import-linter 工具,首先需要编写好你所期望的所有契约。你可以试着从以下几个关键问题开始:
•从顶层观察项目,它由哪几个关键分层构成,之间的关系如何?许多项目中都存在类似 application -> services -> common -> utils 这种分层结构,将它们记录为对应契约•对于某些复杂的子模块,其内部是否存在清晰的分层?如果能找到 views -> models -> utils 这种分层,将其记录为对应契约•有哪些子模块满足“禁止(forbidden)”或“独立(independence)”契约?如果存在,将其记录下来
将这些契约写入到配置文件中以后,执行 lint-imports,你会看到海量的报错信息(如果没有任何报错,那么恭喜你,项目很整洁,关掉文章去干点其他事情吧!)。它们展示了哪些导入关系违反了你所配置的契约。
逐个分析这些报错信息,将其中不合理的导入关系添加到各契约的 ignore_imports 配置中:

处理完全部的报错信息以后,配置文件中的 ignore_imports 可能会包含上百条必须被忽略的导入信息,此时,再次执行 lint-imports 应该不再输出任何报错(一种虚假的整洁)。
接下来便是重头戏,我们需要真正修复这些导入关系。
饭要一口一口吃,修复依赖关系也需要一条一条来。首先,试着从 ignore_imports 中删除一条记录,然后执行 lint-imports,观察并分析该报错信息,尝试找到最合理的方式修复它。
不断重复这个过程,最后就能完成整个项目的依赖关系治理。
Tip:在删减
ignore_imports配置的过程中,你会发现有些导入关系会比其他的更难修复,这很正常。修复依赖关系常常是一个漫长的过程,需要整个团队的持续投入。
修复依赖关系的常见方式
下面介绍几种常见的修复依赖关系的方式。
为了方便描述,我们假设在以下所有场景中,项目定义了一个“分层”类型的契约,而低层模块违反契约,反过来依赖了高层模块。
1. 合并与拆分模块
调整依赖关系最直接的办法是合并模块。
假设有一个低层模块 clusters,违规导入了高层模块 resources 的子模块 cluster_utils 里的部分代码。考虑到这些代码本身就和 clusters 有一定关联性,因此,你其实可以把它们直接挪到 clusters.utils 子模块里,从而消除这个依赖关系。
如下所示:

如果被依赖的代码与所有模块间的关联都不太密切,你也可以选择将它拆分成一个新模块。
比方说,一个低层模块 users 依赖了高层模块 marketing 中发送短信相关的代码,违反了契约。你可以选择把代码从 marketing 中拆分出来,置入一个处于更低层级的新模块 utils.messaging 中。

这样做以后,不健康的依赖关系便能得到解决。
2. 依赖注入
依赖注入(Dependency injection)是一种常见的解耦依赖关系的技巧。
举个例子,项目中设置了一个分层契约:marketing -> users, 但 users 模块却直接导入了 marketing 模块中的短信发送器 SmsSender 类,违反了契约。

要通过“依赖注入”修复该问题,我们可以直接删除代码中对 SmsSender 的依赖,改为要求调用方必须在实例化 User 时,主动传入一个“代码通知器(sms_sender)”对象。

这样做以后,User 对“短信通知器”的依赖就变弱了,不再违反分层契约。
添加类型注解
但是,前面的依赖注入方案并不完美。当你想给 sms_sender 参数添加类型注解时,很快会发现自己开始重蹈覆辙:不能写 def __init__(self, sms_sender: SmsSender),那样得把删掉的 import 语句找回来。

即使像上面这样,把 import 语句放在 TYPE_CHECKING 分支中,import-linter 仍会将其当做普通导入对待(注:该行为可能会在未来发生改动,详见 Add support for detecting whether an import is only made during type checking · Issue #64[7]),将其视为对契约的一种违反。
为了让类型注解正常工作,我们需要在 users 模块中引入一个新的抽象:SmsSenderProtocol 协议(Protocol),替代实体 SmsSender 类型。

这样便解决了类型注解的问题。
Tip:通过引入 Protocol 来解耦依赖关系,其实上是对依赖倒置原则(Dependency Inversion Principle)的一种应用。依赖倒置原则认为:高层模块不应该依赖低层模块,二者都应该依赖抽象。
关于它的更多介绍,推荐阅读我的另一篇文章:《Python 工匠:写好面向对象代码的原则(下) 》[8]。
3. 简化依赖数据类型
在以下代码中,低层模块 monitoring 依赖了高层模块 processes 中的 ProcService 类型:

经过分析后,可以发现 build_monitor_config 函数实际上只使用了 service 对象的两个字段:host 和 port,不依赖它的任何其他属性和方法。所以,我们完全可以调整函数签名,将其改为仅接受两个必要的简单参数:

调用方的代码也需要进行相应修改:

通过简化函数所接收的参数类型,我们消除了模块间的不合理依赖。
4. 延迟提供函数实现
Python 是一门非常动态的编程语言,我们可以利用这种动态,延迟提供某些函数的具体实现,从而扭转模块间的依赖关系。
假设低层模块 users 目前违反了契约,直接依赖了高层模块 marketing 中的 send_sms 函数。要扭转该依赖关系,第一步是在低层模块 users 中定义一个用来保存函数的全局变量,并提供一个配置入口。
代码如下所示:

调用 send_sms 函数时,判断当前是否已提供具体实现:

完成以上修改后,users 不再需要从 marketing 中导入“短信发送器”的具体实现。而是可以由高层模块 marketing 来一波“反向操作”,主动调用 set_send_sms_func,将实现注入到低层模块 users 中:
这样便完成了依赖关系的扭转。
变种:简单的插件机制
除了用一个全局变量来保存函数的具体实现以外,你还可以将 API 设计得更复杂一些,实现一种类似于“插件”的注册与调用机制,满足更丰富的需求场景。
举个简单的例子,在低层模块中,实现“插件”的抽象定义以及用来保存具体插件的注册器:

在其他模块中,调用 SmsSenderPluginCenter.register 来注册具体的插件实现:

和使用全局变量一样,插件机制同样是对依赖倒置原则的一种具体应用。上面的代码仅包含最简单的原理示意,真实的代码实现会更复杂一些,不在此文中赘述。
5. 由配置文件驱动
假设低层模块 users 违规依赖了高层模块 marketing 中的一个工具函数 send_sms。除了使用上面介绍的方式以外,我们也可以选择将工具函数的导入路径定义成一个配置项,置入配置文件中。

在 users 模块中,不再直接引用 marketing 模块,而是通过动态导入配置中的工具函数的方式,来使用 send_sms 函数。

这样也可以完成依赖关系的解耦。
Tip:关于 import_string 函数的具体实现,可以参考 Django 框架[9]。
6. 用事件驱动代替函数调用
对于那些耦合关系本身较弱的模块,你也可以选择用事件驱动的方式来代替函数调用。
举个例子,低层模块 networking 每次变独立域名数据时,均需要调用高层模块 applications 中的 deploy_networking 函数,更新对应的资源,这违反了分层契约。

该问题很适合用事件驱动来解决(以下代码基于 Django 框架的信号机制[10] 编写)。
引入事件驱动的第一步是发送事件。我们需要修改 networking 模块,删除其中的函数调用代码,改为发送一个类型为 custom_domain_updated 的信号:

第二步,是在 applications 模块中新增事件监听代码,完成资源更新操作:

这样便完成了解耦工作。
总结
在依赖关系治理方面,import-linter[11] 是一个非常有用的工具。它通过提供各种类型的“契约”,让我们得以将项目内隐式的复杂依赖关系,通过配置文件显式的表达出来。再配合 CI 等工程实践,能有效地帮助我们维持项目架构的整洁。
如果你想在项目中引入 import-linter,最重要的工作是修复已有的不合理的依赖关系。常见的修复方式包括合并与拆分、依赖注入、事件驱动,等等。虽然手法多种多样,但最重要的事用一句话便可概括:把每行代码放在最恰当的模块中,必要时在当前模块引入新的抽象,借助它的力量来反转模块间的依赖关系。
愿你的项目架构永远保持整洁!
References
[1] import-linter: https://github.com/seddonym/import-linter[2] import-linter: https://github.com/seddonym/import-linter[3] seddonym: https://github.com/seddonym[4] 禁止(forbidden): https://import-linter.readthedocs.io/en/stable/contract_types.html#forbidden-modules[5] 独立(independence): https://import-linter.readthedocs.io/en/stable/contract_types.html#independence[6] 官方文档: https://import-linter.readthedocs.io/en/stable/custom_contract_types.html[7] Add support for detecting whether an import is only made during type checking · Issue #64: https://github.com/seddonym/grimp/issues/64[8] 《Python 工匠:写好面向对象代码的原则(下) 》: https://www.piglei.com/articles/write-solid-python-codes-part-3/[9] Django 框架: https://github.com/django/django/blob/main/django/utils/module_loading.py#L19[10] Django 框架的信号机制: https://docs.djangoproject.com/en/4.2/topics/signals/[11] import-linter: https://github.com/seddonym/import-linter















![机器学习之监督学习(一)线性回归、多项式回归、算法优化[巨详细笔记]](https://i-blog.csdnimg.cn/direct/9b1285613c3c4130a91c397eff02e61a.png#pic_center)