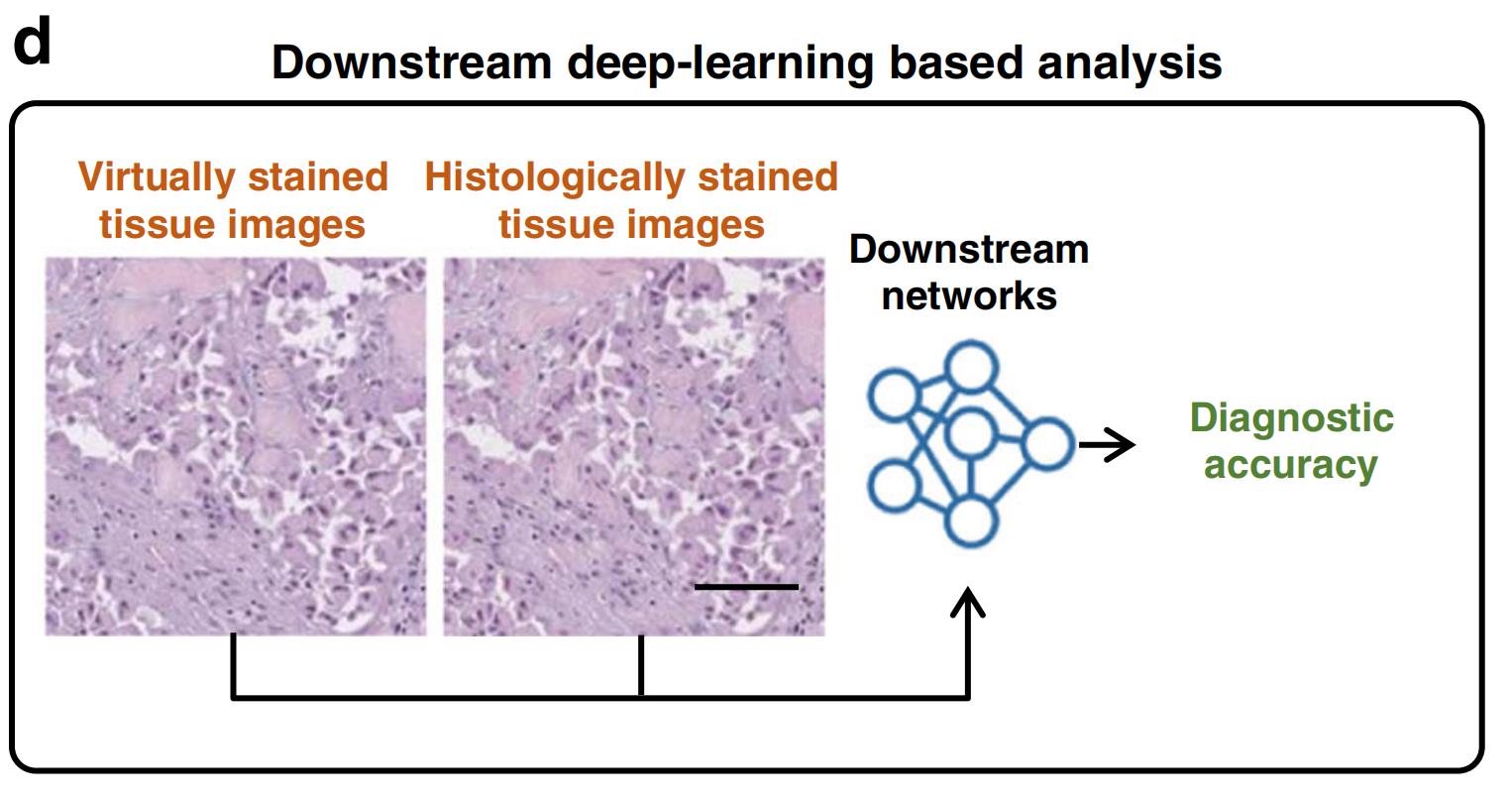
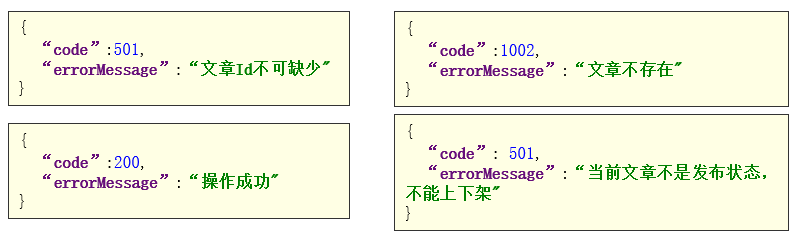
本文章想借着爬虫给大家介绍一下图片转pdf,有需要的友友们可以看看参考参考,有帮助到友友的可以收藏+关注。下面以爬取初中7年级数学上册为例给大家演示一下。网址是这个 https://mp.weixin.qq.com/s?__biz=MzAxOTE4NjI1Mw==&mid=2650214000&idx=6&sn=2e627183fc9376a2f09f29fb84d912b8&chksm=83c97952b4bef04499f9797b0b01daa54b46d00ef9958c1e521da0a29f41559c99aefe96f157&scene=27
1 导入包
import requests
from lxml import html,etree
from bs4 import BeautifulSoup
import re
import pandas as pd
from PIL import Image
from io import BytesIO
import os
from PyPDF2 import PdfFileMerger, PdfFileReader
import PyPDF2
2 爬取目标url获取有用照片url
### 1 解析网页获取可用数据
URL = 'https://mp.weixin.qq.com/s?__biz=MzAxOTE4NjI1Mw==&mid=2650214000&idx=6&sn=2e627183fc9376a2f09f29fb84d912b8&chksm=83c97952b4bef04499f9797b0b01daa54b46d00ef9958c1e521da0a29f41559c99aefe96f157&scene=27'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"}
respons = requests.get(url =URL,headers= headers)
respons.encoding='utf-8'
respons = respons.text
soup = BeautifulSoup(respons,'lxml')
# 使用正则表达式查找所有https开头的URL
urls = re.findall(r'https://\S+', str(soup))
book_url = []
# 打印找到的URL
for url in urls:if len(url)> 139:# print(url)book_url.append(url)else:None
3 爬取url对应的照片
for index,url_ in enumerate(book_url):image_filename = r'E:/学习/7年级上册数学/{}.jpeg'.format(index)response = requests.get(url_)if response.status_code == 200:with open(image_filename, 'wb') as file:file.write(response.content)print(f'图片已保存到 {image_filename}')else:print(f'下载失败,状态码: {response.status_code}')
爬到照片:

4 图片转化为pdf并且合并
### 3将图片转化为pdf
folder_path = r'E:/学习/7年级上册数学'
# 创建一个列表来存储每张图片转换成的PDF文件的路径
pdf_files = []
# 遍历文件夹中的所有文件
for filename in os.listdir(folder_path):if filename.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.gif')):file_path = os.path.join(folder_path, filename)img = Image.open(file_path)# 转换图片为PDF文件,这里假设每张图片保存为一个单独的PDFpdf_file_path = f'{folder_path}/temp_{filename.rsplit(".", 1)[0]}.pdf'img.save(pdf_file_path, "PDF")pdf_files.append(pdf_file_path)
if pdf_files:merger = PyPDF2.PdfWriter()for pdf in pdf_files:merger.append(pdf)output_pdf_filename = os.path.join(folder_path, '7年级上册数学.pdf')with open(output_pdf_filename, 'wb') as fout:merger.write(fout)print(f"PDFs merged into {output_pdf_filename}")
else:print("No images were found in the specified folder.")
结果如下图:


![[数据集][目标检测]街头摊贩识别检测数据集VOC+YOLO格式758张1类别](https://i-blog.csdnimg.cn/direct/661724e63a6b435d8806320704b39ea8.png)