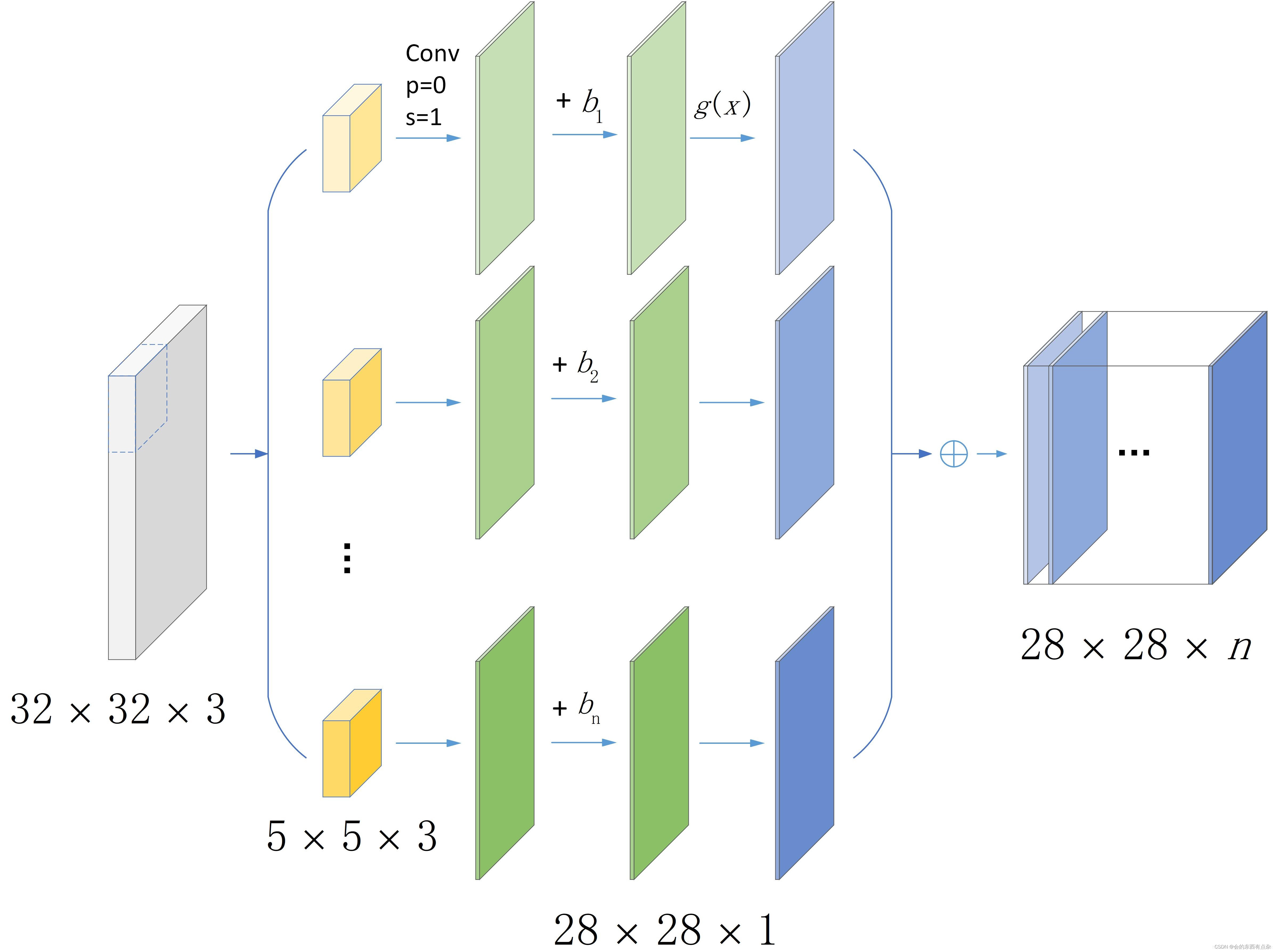
nodeSelector 提供了一个非常简单的方式,将 Pod 限定到包含特定标签的节点上。亲和性与反亲和性(affinity / anti-affinity)特性则极大地扩展了限定的表达方式。主要的增强点在于:
- 表达方式更加有效(不仅仅是多个精确匹配表达式的“和”关系)
- 可以标识该规则为“soft” / “preference” (软性的、偏好的)而不是 hard requirement(必须的),此时,如果调度器发现该规则不能被满足,Pod 仍然可以被调度
- 可以对比节点上(或其他拓扑域 topological domain)已运行的其他 Pod 的标签,而不仅仅是节点自己的标签,此时,可以定义类似这样的规则:某两类 Pod 不能在同一个节点(或拓扑域)上共存
节点亲和性
节点亲和性(node affinity)的概念与 nodeSelector 相似,可以基于节点的标签来限定 Pod 可以被调度到哪些节点上。
当前支持两种类型的节点亲和性, requiredDuringSchedulingIgnoredDuringExecution (hard,目标节点必须满足此条件) 以及 preferredDuringSchedulingIgnoredDuringExecution (soft,目标节点最好能满足此条件)。名字中 IgnoredDuringExecution 意味着:如果 Pod 已经调度到节点上以后,节点的标签发生改变,使得节点已经不再匹配该亲和性规则了,Pod 仍将继续在节点上执行(这一点与 nodeSelector 相似)。将来,Kubernetes 将会提供 requiredDuringSchedulingRequiredDuringExecution 这个选项,该选项与 requiredDuringSchedulingIgnoredDuringExecution 相似,不同的是,当节点的标签不在匹配亲和性规则之后,Pod 将被从节点上驱逐。
requiredDuringSchedulingIgnoredDuringExecution 的一个例子是,只在 Intel CPU 上运行该 Pod,preferredDuringSchedulingIgnoredDuringExecution 的一个例子是,尽量在高可用区 XYZ 中运行这个 Pod,但是如果做不到,也可以在其他地方运行该 Pod。
PodSpec 中通过 affinity.nodeAffinity 字段来定义节点亲和性
apiVersion: v1
kind: Pod
metadata:name: with-node-affinity
spec:affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/e2e-az-nameoperator: Invalues:- e2e-az1- e2e-az2preferredDuringSchedulingIgnoredDuringExecution:- weight: 1preference:matchExpressions:- key: another-node-label-keyoperator: Invalues:- another-node-label-valuecontainers:- name: with-node-affinityimage: k8s.gcr.io/pause:2.0此处的亲和性规则表明,该 Pod 只能被调度到包含 key 为 kubernetes.io/e2e-az-name 且 value 为 e2e-az1 或 e2e-az2 的标签的节点上。此外,如果节点已经满足了前述条件,将优先选择包含 key 为 another-node-label-key 且 value 为 another-node-label-value 的标签的节点。
例子中使用了操作符 In。节点亲和性支持如下操作符:In、NotIn、Exists、DoesNotExist、Gt、Lt。使用 NotIn 和 DoesNotExist 可以实现节点反亲和性(node anti-affinity)的效果,或者也可以使用 [污点 为节点排斥某类 Pod。
如果某个 Pod 同时指定了 nodeSelector 和 nodeAffinity,则目标节点必须同时满足两个条件,才能将 Pod 调度到该节点上。
如果为 nodeAffinity 指定多个 nodeSelectorTerms,则目标节点只需要满足任意一个 nodeSelectorTerms 的要求,就可以将 Pod 调度到该节点上。
如果为 nodeSelectorTerms 指定多个 matchExpressions,则目标节点必须满足所有的 matchExpressions 的要求,才能将 Pod 调度到该节点上。
当 Pod 被调度到某节点上之后,如果移除或者修改节点的标签,Pod 将仍然继续在节点上运行。换句话说,节点亲和性规则只在调度该 Pod 时发生作用。
preferredDuringSchedulingIgnoredDuringExecution 中的 weight 字段取值范围为 1-100。对于每一个满足调度要求的节点(资源请求、亲和性/反亲和性规则,等),调度器将遍历该节点匹配的 preferredDuringSchedulingIgnoredDuringExecution 中所有的weight 并求和。此求和结果将与节点的其他优先级计算的得分合并。得分最高的节点被优先选择。
Pod亲和性与反亲和性
Pod之间的亲和性与反亲和性(inter-pod affinity and anti-affinity)可以基于已经运行在节点上的 Pod 的标签(而不是节点的标签)来限定 Pod 可以被调度到哪个节点上。此类规则的表现形式是:
-
当 X 已经运行了一个或者多个满足规则 Y 的 Pod 时,待调度的 Pod 应该(或者不应该 - 反亲和性)在 X 上运行
-
规则 Y 以 LabelSelector 的形式表述,附带一个可选的名称空间列表
与节点不一样,Pod 是在名称空间中的(因此,Pod的标签是在名称空间中的),针对 Pod 的 LabelSelector 必须同时指定对应的名称空间
-
X 是一个拓扑域的概念,例如节点、机柜、云供应商可用区、云供应商地域,等。X 以
topologyKey的形式表达,该 Key代表了节点上代表拓扑域(topology domain)的一个标签。
-
pod affinity 的一个例子
apiVersion: v1
kind: Pod
metadata:name: with-pod-affinity
spec:affinity:podAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: securityoperator: Invalues:- S1topologyKey: failure-domain.beta.kubernetes.io/zonepodAntiAffinity:preferredDuringSchedulingIgnoredDuringExecution:- weight: 100podAffinityTerm:labelSelector:matchExpressions:- key: securityoperator: Invalues:- S2topologyKey: failure-domain.beta.kubernetes.io/zonecontainers:- name: with-pod-affinityimage: k8s.gcr.io/pause:2.0该 Pod 的 affinity 定义了一个 Pod 亲和性规则和一个 Pod 反亲和性规则,例子中, podAffinity 是 requiredDuringSchedulingIgnoredDuringExecution,而 podAntiAffinity 则是 preferredDuringSchedulingIgnoredDuringExecution。
-
Pod 亲和性规则要求,该 Pod 可以被调度到的节点所在的可用区
zone必须已经有一个已经运行的 Pod 包含标签 key=security,value=S1,或者更准确地说,节点必须满足如下条件:- 节点包含 key 为
failure-domain.beta.kubernetes.io/zone的标签,假设该标签的值为V - 至少有一个包含 key 为
failure-domain.beta.kubernetes.io/zone且 value 为V的标签的节点已经运行了一个包含标签 key 为security且 value 为S1的 Pod
- 节点包含 key 为
-
Pod 反亲和性规则要求,该 Pod 最好不要被调度到已经运行了包含 key 为
security且 value 为S2的标签的 Pod 的节点上,或者更准确地说,必须满足如下条件:- 如果
topologyKey是failure-domain.beta.kubernetes.io/zone,则,Pod不能被调度到同一个 zone 中的已经运行了包含标签security: S2的节点上
- 如果
原则上, topologyKey 可以是任何合法的标签 key。然而,处于性能和安全的考虑,仍然对 topologyKey 有如下限制:
- 对亲和性以及
requiredDuringSchedulingIgnoredDuringExecutionPod 反亲和性,topologyKey不能为空 - 对
requiredDuringSchedulingIgnoredDuringExecutionPod 反亲和性,管理控制器LimitPodHardAntiAffinityTopology被用来限制topologyKey必须为kubernetes.io/hostname。如果想要使用其他的自定义 topology,必须修改该管理控制器,或者将其禁用 - 对
preferredDuringSchedulingIgnoredDuringExecutionPod 反亲和性,如果topologyKey为空,则代表所有的 topology (此时,不局限于kubernetes.io/hostname、failure-domain.beta.kubernetes.io/zone和failure-domain.beta.kubernetes.io/region的组合) - 除了上述的情形以外,
topologyKey可以是任何合法的标签 Key
除了 labelSelector 和 topologyKey 以外,还可以指定一个 namespaces 的列表,用作 labelSelector 的作用范围(与 labelSelector 和 topologyKey 的定义为同一个级别)。如果不定义或者该字段为空,默认为 Pod 所在的名称空间。
所有与 requiredDuringSchedulingIgnoredDuringExecution 亲和性和反亲和性关联的 matchExpressions 必须被满足,Pod 才能被调度到目标节点。
更多实用的例子
Pod 亲和性与反亲和性结合高级别控制器(例如 ReplicaSet、StatefulSet、Deployment 等)一起使用时,可以非常实用。此时可以很容易的将一组工作复杂调度到同一个 topology,例如,同一个节点。
始终在同一个节点
在一个三节点的集群中,部署一个使用 redis 的 web 应用程序,并期望 web-server 尽可能与 redis 在同一个节点上。
下面是 redis deployment 的 yaml 片段,包含三个副本以及 app=store 标签选择器。Deployment 中配置了 PodAntiAffinity,确保调度器不会将三个副本调度到一个节点上:
apiVersion: apps/v1
kind: Deployment
metadata:name: redis-cache
spec:selector:matchLabels:app: storereplicas: 3template:metadata:labels:app: storespec:affinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- storetopologyKey: "kubernetes.io/hostname"containers:- name: redis-serverimage: redis:3.2-alpine配置详解:
这个YAML文件描述了一个Kubernetes的Deployment对象,用于部署一个名为 “redis-cache” 的应用程序。以下是文件的详细解读:
apiVersion: apps/v1: 这个字段指定了使用的Kubernetes API版本,这里是apps/v1,表示我们正在定义一个Deployment对象。kind: Deployment: 这个字段指定了我们要创建的Kubernetes资源的类型,这是一个Deployment资源,用于部署和管理应用程序的副本。metadata: 这个字段包含有关Deployment对象的元数据信息,例如名称和标签。name: redis-cache: 这个字段指定了Deployment对象的名称,它将被用来标识和引用这个Deployment。
spec: 这个字段包含了Deployment的规范,定义了如何创建和运行Pod的规则。selector: 这 个部分定义了哪些Pod将被包括在Deployment中。matchLabels: 这里指定了一个标签选择器,要求匹配具有 “app: store” 标签的Pod将包括在Deployment中。
replicas: 3: 这个字段指定了要创建的Pod副本数量,这里是3个。template: 这个部分定义了要创建的Pod的模板。metadata: 这里指定了Pod模板的标签,这些标签与Deployment的标签选择器匹配。labels: 这里定义了一个标签 “app: store”。
spec: 这个部分定义了Pod的规范。affinity: 这里定义了Pod的亲和性规则,以确保Pod在节点上的分布。podAntiAffinity: 这个字段定义了Pod的反亲和性规则,要求具有相同标签 “app: store” 的Pod不会被调度到相同的节点上。requiredDuringSchedulingIgnoredDuringExecution: 这个字段指定了在调度时必须满足的反亲和性规则。labelSelector: 这里定义了一个标签选择器,要求匹配具有 “app: store” 标签的Pod。topologyKey: "kubernetes.io/hostname": 这个字段指定了拓扑域的键,表示Pod的反亲和性规则将基于节点的主机名来执行。
containers: 这里定义了要在Pod中运行的容器列表。name: redis-server: 这个字段指定了容器的名称,这个容器运行一个名为 “redis-server” 的服务。image: redis:3.2-alpine: 这个字段指定了要使用的容器镜像,这里使用的是Redis 3.2版本的Alpine Linux基础镜像。
作用是创建一个名为 “redis-cache” 的Deployment,该Deployment包含3个副本,每个副本运行一个名为 “redis-server” 的Redis容器,并且确保这些Pod在不同的节点上运行,以提高可用性和容错性。这个Deployment使用标签选择器来选择要管理的Pod,并定义了Pod的亲和性规则以确保它们在节点上的分布。
下面是 webserver deployment 的 yaml 片段,配置了 podAntiAffinity 以及 podAffinity。要求将其副本与 包含 app=store 标签的 Pod 放在同一个节点上;同时也要求 web-server 的副本不被调度到同一个节点上。
apiVersion: apps/v1
kind: Deployment
metadata:name: web-server
spec:selector:matchLabels:app: web-storereplicas: 3template:metadata:labels:app: web-storespec:affinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- web-storetopologyKey: "kubernetes.io/hostname"podAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- storetopologyKey: "kubernetes.io/hostname"containers:- name: web-appimage: nginx:1.12-alpine如果创建上述两个 deployment,集群将如下所示:
| Node-1 | Node-2 | Node-3 |
|---|---|---|
| web-server-1 | webserver-2 | webserver-3 |
| cache-1 | cache-2 | cache-3 |
web-server 的三个副本都自动与 cach 的副本运行在相同的节点上。
kubectl get pods -o wide已复制到剪贴板!1
输出结果如下所示
NAME READY STATUS RESTARTS AGE IP NODE
redis-cache-1450370735-6dzlj 1/1 Running 0 8m 10.192.4.2 kube-node-3
redis-cache-1450370735-j2j96 1/1 Running 0 8m 10.192.2.2 kube-node-1
redis-cache-1450370735-z73mh 1/1 Running 0 8m 10.192.3.1 kube-node-2
web-server-1287567482-5d4dz 1/1 Running 0 7m 10.192.2.3 kube-node-1
web-server-1287567482-6f7v5 1/1 Running 0 7m 10.192.4.3 kube-node-3
web-server-1287567482-s330j 1/1 Running 0 7m 10.192.3.2 kube-node-2始终不在相同的节点上
上面的例子使用了 PodAntiAffinity 规则与 topologyKey: "kubernetes.io/hostname" 来部署 redis 集群,因此没有任何两个副本被调度到同一个节点上。参考 ZooKeeper tutorial 了解如何使用相同的方式为 StatefulSet 配置反亲和性以实现高可用。


![[NSSRound#1 Basic]sql_by_sql - 二次注入+布尔盲注||sqlmap](https://img-blog.csdnimg.cn/1a354c46fcba480b93818bcbebb011de.png)