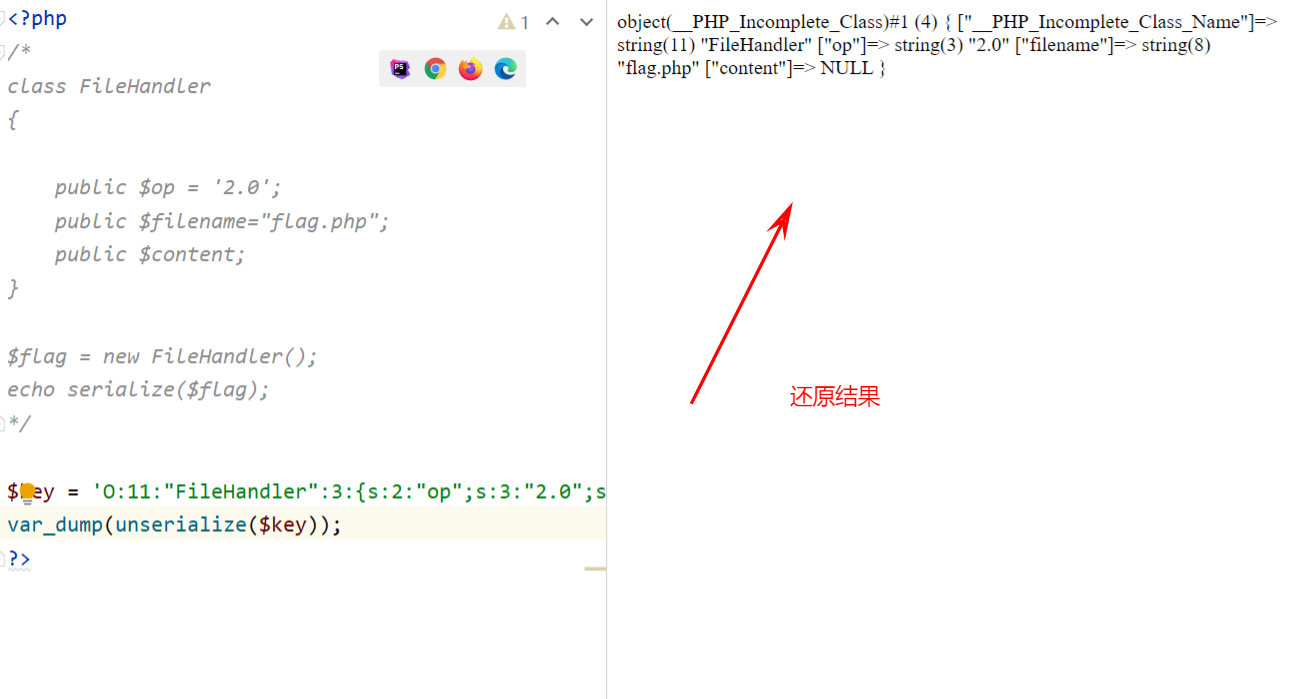
初识数据
from sklearn.datasets import load_irisif __name__ == '__main__':iris_dataset = load_iris()print("数据集的键为:\n{}".format(iris_dataset.keys()))# DESCR 数据集的简要说明print(iris_dataset['DESCR'][:193])# target_names 数组对应的是我们要预测的花的品种print("目标名字:{}".format(iris_dataset['target_names']))# feature_names 对每一个特征进行了说明print("特征的说明:{}".format(iris_dataset['feature_names']))# data中存放数据,对应feature_names里面的数据# sepal length (cm) 花萼长度# sepal width (cm) 花萼宽度# petal length (cm) 花瓣长度# petal width (cm) 花瓣宽度print("数据为:{}".format(iris_dataset['data']))print("数据为:{}".format(iris_dataset['data'].shape))# target表示品种,0代表setosa 1代表versicolor 2代表virginicaprint("品种为:{}".format(iris_dataset['target']))print("品种为:{}".format(iris_dataset['target'].shape))
训练数据与测试数据
train_test_split解释
from sklearn.model_selection import train_test_splitif __name__ == '__main__':# 参考上面# 得到训练数据和测试数据X_train,X_test,Y_train,Y_test = train_test_split(iris_dataset['data'],iris_dataset['target'],random_state=0)print("X训练数据:{}".format(X_train.shape))print("Y训练数据:{}".format(Y_train.shape))print("X测试数据:{}".format(X_test.shape))print("Y测试数据:{}".format(Y_test.shape))
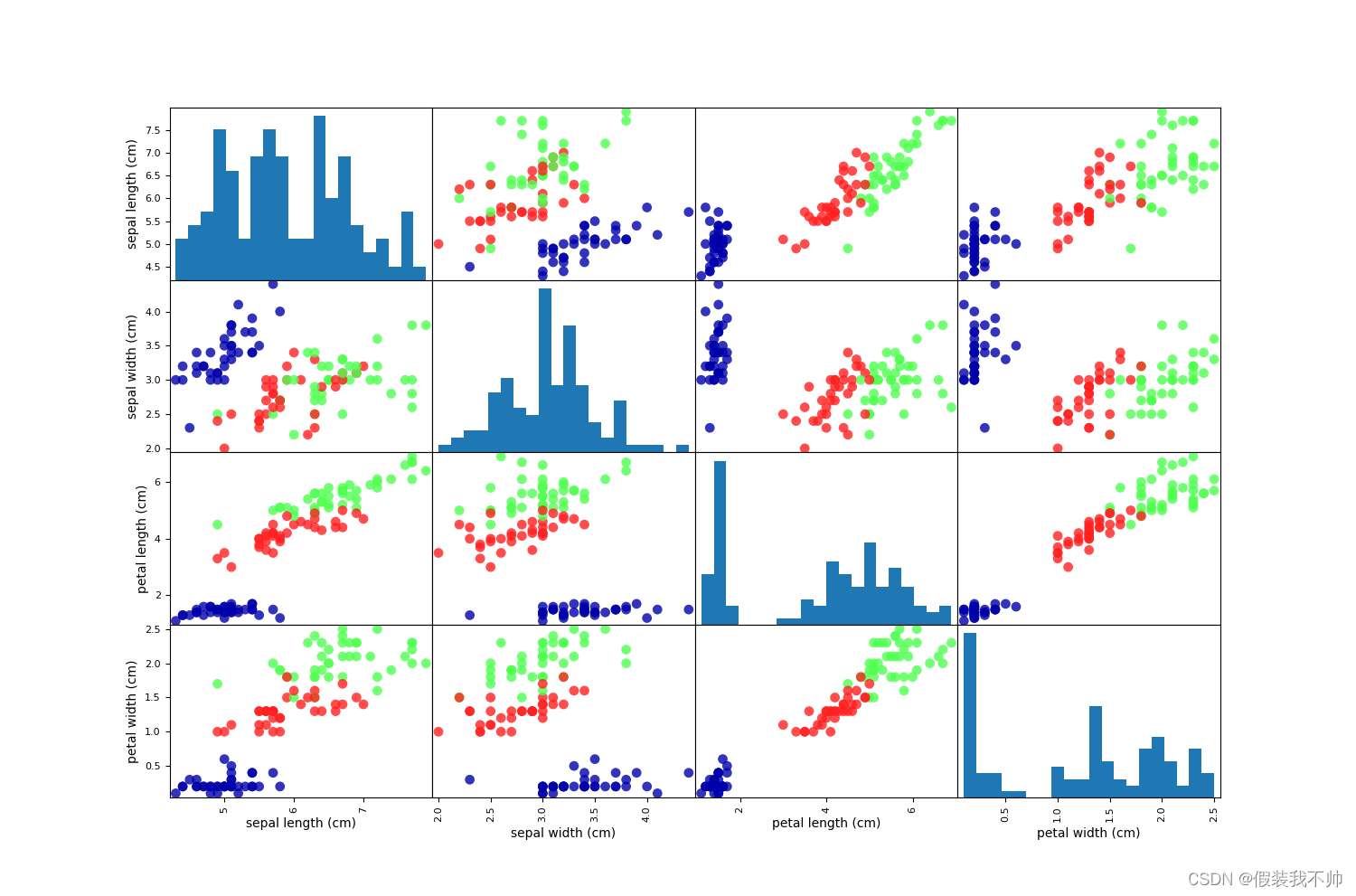
观察数据
import pandas as pd
from matplotlib.colors import ListedColormap
import matplotlib.pyplot as pltif __name__ == '__main__':# 参考上面# 利用x_train中的数据创建DataFrame# 利用iris_dataset.feature_names中的字符串对数据列进行标记iris_dataframe = pd.DataFrame(X_train,columns=iris_dataset.feature_names)# 利用DataFrame创建散点图矩阵按照y_train着色cm3 = ListedColormap(['#0000aa', '#ff2020', '#50ff50'])pd.plotting.scatter_matrix(iris_dataframe, c=Y_train, figsize=(15, 15),marker='o', hist_kwds={'bins': 20}, s=60,alpha=.8, cmap=cm3)plt.show()
k邻近算法
from sklearn.neighbors import KNeighborsClassifierif __name__ == '__main__':# 参考上面# k邻近算法,设置邻居的数目为1knn = KNeighborsClassifier(n_neighbors=1)knn.fit(X_train,Y_train)
预测数据
if __name__ == '__main__':# 参考上面# 预测数据# 新的鸢尾花,花萼长5cm,宽2.9cm,花瓣长1cm,宽0.2cmX_new = np.array([[5, 2.9, 1, 0.2]])prediction =knn.predict(X_new)print("预测结果为:{}".format(prediction))print("预测结果的种类为:{}".format(iris_dataset['target_names'][prediction]))
评估模型
if __name__ == '__main__':# 参考上面# 评估模型y_pred = knn.predict(X_test)print("预测结果:{}".format(y_pred))print("精度:{:.2f}".format(knn.score(X_test,Y_test)))