参考:
1、官方教程:https://docs.ultralytics.com/zh/tasks/segment/
2、YOLOv8制作自己的实例分割数据集保姆级教程(包含json转txt)
下载最新yolov8代码
git clone https://github.com/ultralytics/ultralytics.git
一、制作自己的数据集
省略
二、分离img和json 以及json转yolo格式
2.1 分离images和json文件
使用labelme标注完成后的结果是在一个文件夹中。
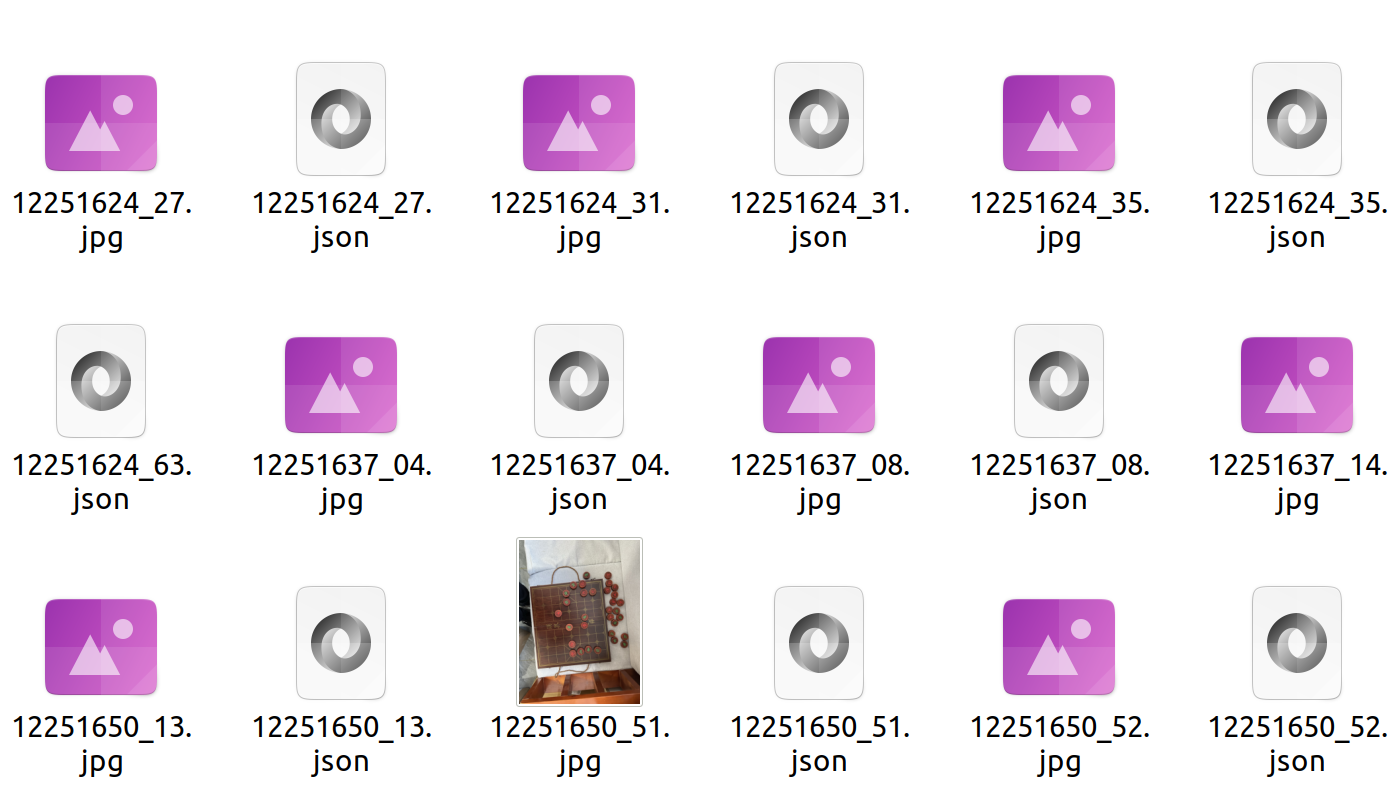
分离开来
fenli_image_and_label.py
# 分离jpg txt和json文件import os.path
import xml.etree.ElementTree as ET
from xml.dom.minidom import Document
import os
import os.path
from PIL import Imageimport os
import shutilclass_name = './class.txt'class_new_name = './class_new.txt'
Class_Name = []
Class_new_Name = []
# img_path = r'/media/huifeimao/2/diyun/11_h264_data/苏州申通5/images/' #图片文件夹
# xml_path = r'/media/huifeimao/2/diyun/11_h264_data/苏州申通5/xml/' #xml文件存放地址
# ann_path = r'/media/huifeimao/2/diyun/11_h264_data/苏州申通5/0/'# yolov3标注.txt文件夹source_folder="/media/diyun/T9/diyun/10_train_data/9_Chinese_chess/key_point/24_0125_train_183/images_src/"dst_folder="/media/diyun/T9/diyun/10_train_data/9_Chinese_chess/key_point/24_0125_train_183"jpg_destination_folder=dst_folder + "/images" # 源文件夹路径
txt_destination_folder = dst_folder + "/labels" # 目标文件夹路径
json_destination_folder= dst_folder + "/json" # 目标文件夹路径is_delete_src=0def copy_txt_files(source_folder, destination_folder,is_delete_src):# 遍历源文件夹中的所有文件和目录for root, dirs, files in os.walk(source_folder):for file in files:# 检查文件扩展名是否为 .txtif file.endswith(".txt"):# 构建源文件的完整路径source_path = os.path.join(root, file)# 构建目标文件的完整路径destination_path = os.path.join(destination_folder, file)# 复制文件到目标文件夹shutil.copy(source_path, destination_path)if is_delete_src:os.remove(source_path)def copy_json_files(source_folder, destination_folder,is_delete_src):# 遍历源文件夹中的所有文件和目录for root, dirs, files in os.walk(source_folder):for file in files:# 检查文件扩展名是否为 .txtif file.endswith(".json"):# 构建源文件的完整路径source_path = os.path.join(root, file)# 构建目标文件的完整路径destination_path = os.path.join(destination_folder, file)# 复制文件到目标文件夹shutil.copy(source_path, destination_path)if is_delete_src:os.remove(source_path)def copy_jpg_files(source_folder, destination_folder):# 遍历源文件夹中的所有文件和目录for root, dirs, files in os.walk(source_folder):for file in files:# 检查文件扩展名是否为 .txtif file.endswith(".jpg"):# 构建源文件的完整路径source_path = os.path.join(root, file)# 构建目标文件的完整路径destination_path = os.path.join(destination_folder, file)# 复制文件到目标文件夹shutil.copy(source_path, destination_path)if not os.path.exists(txt_destination_folder):os.mkdir(txt_destination_folder)
if not os.path.exists(json_destination_folder):os.mkdir(json_destination_folder)
if not os.path.exists(jpg_destination_folder):os.mkdir(jpg_destination_folder)copy_txt_files(source_folder, txt_destination_folder,is_delete_src)
copy_json_files(source_folder, json_destination_folder,is_delete_src)copy_jpg_files(source_folder, jpg_destination_folder)2.2、 json转yolo格式
新建segment_json_2_txt.py文件,将代码中的文件路径修改为自己的路径。
❗❗❗代码中第43行的classes中存放的是自己数据集的分类标签,记得修改成自己的。
'''
yolov8训练自己的实例分割数据集json转yolo格式
'''import json
import os
from tqdm import tqdmdef convert_label(json_dir, save_dir, classes):json_paths = os.listdir(json_dir)classes = classes.split(',')for json_path in tqdm(json_paths):path = os.path.join(json_dir, json_path)with open(path, 'r') as load_f:json_dict = json.load(load_f)h, w = json_dict['imageHeight'], json_dict['imageWidth']# save txt pathtxt_path = os.path.join(save_dir, json_path.replace('json', 'txt'))txt_file = open(txt_path, 'w')for shape_dict in json_dict['shapes']:label = shape_dict['label']label_index = classes.index(label)points = shape_dict['points']points_nor_list = []for point in points:points_nor_list.append(point[0] / w)points_nor_list.append(point[1] / h)points_nor_list = list(map(lambda x: str(x), points_nor_list))points_nor_str = ' '.join(points_nor_list)label_str = str(label_index) + ' ' + points_nor_str + '\n'txt_file.writelines(label_str)if __name__ == "__main__":json_dir = '/media/diyun/T9/diyun/10_train_data/9_Chinese_chess/segment/24_0302_train_333/json'save_dir = '/media/diyun/T9/diyun/10_train_data/9_Chinese_chess/segment/24_0302_train_333/labels'classes = 'checkerboard'convert_label(json_dir, save_dir, classes)

2.3、划分训练和验证集和测试集
将segment_make_train_val_test_txt.py代码中的文件路径修改为自己的路径。
'''
yolov8训练自己的实例分割数据集
yolov8训练,数据集的准备,从yolo的txt 文件,分为预测训练验证
'''import os
import randomtrain_percent = 0.9
trainval_percent = 0.1label_filepath = '/media/diyun/T9/diyun/10_train_data/9_Chinese_chess/segment/24_0302_train_333/labels' #xml文件存放地址
Imgpath = '/media/diyun/T9/diyun/10_train_data/9_Chinese_chess/segment/24_0302_train_333/images' #图片文件夹if not os.path.exists('ImageSets/'):os.makedirs('ImageSets/')total_xml = os.listdir(label_filepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
print("trainval_percent=",tv)
print("train_percent=",tr)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/trainval.txt', 'w')
ftest = open('ImageSets/test.txt', 'w')
ftrain = open('ImageSets/train.txt', 'w')
fval = open('ImageSets/val.txt', 'w')for i in list:name = total_xml[i][:-4] + '\n'if i in trainval:ftrainval.write(name)if i in train:ftest.write(name)else:fval.write(name)else:ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()sets = ['train', 'test','val']ImageSets_path='ImageSets/'print(Imgpath)
for image_set in sets:if not os.path.exists('labels/'):os.makedirs('labels/')image_ids = open(ImageSets_path+'%s.txt' % (image_set)).read().strip().split()list_file = open('%s.txt' % (image_set), 'w')for image_id in image_ids:list_file.write(Imgpath+'/%s.jpg\n' % (image_id))list_file.close()生成如下:


2.4、下载预训练模型
https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-seg.pt
https://github.com/ultralytics/assets/releases/download/v8.1.0/yolov8l-seg.pt
三、训练
训练配置文件
mytrain_segment_chess_board.yaml
train: /home/diyun/work/python_project/23_0130_xiangqi_yolov5/yolov8/datasets/train.txt # 生成的train.txt的路径
val: /home/diyun/work/python_project/23_0130_xiangqi_yolov5/yolov8/datasets/val.txt # 生成的val.txt的路径# Classes
names:0: chess_board训练代码
yolov8_segment_train.py
from ultralytics import YOLO# 加载模型
#model = YOLO('yolov8s-pose.yaml') # build a new model from YAML
model = YOLO('./weights/yolov8s-seg.pt') # load a pretrained model (recommended for training)
#model = YOLO('yolov8s-pose.yaml').load('yolov8s-pose.pt') # build from YAML and transfer weights# 训练
results = model.train(data='./datasets/mytrain_segment_chess_board.yaml', epochs=100, imgsz=640, workers=0, batch=8, project="Chinese_chess", name="segment")运行
python yolov8_segment_train.py
或者直接命令行
yolo pose train data=./datasets/mytrain_segment_chess_board.yaml model=yolov8s-seg.pt epochs=100 imgsz=640









![[用AI日进斗金系列]用码上飞在企微接单开发一个项目管理系统!](https://i-blog.csdnimg.cn/direct/664a7c11636445208d95fc0ae8b02689.png)