文章目录
- 1、Kafka的Log日志梳理
- 1.1、Topic下的消息是如何存储的?
- 1.1.1、 log文件追加记录所有消息
- 1.1.2、 index和timeindex加速读取log消息日志。
- 1.2、文件清理机制
- 1.2.1、如何判断哪些日志文件过期了
- 1.2.2、过期的日志文件如何处理
- 1.3、Kafka的文件高效读写机制
- 1.3.1、Kafka的文件结构
- 1.3.2、顺序写磁盘
- 1.3.3、零拷贝
1、Kafka的Log日志梳理
这一部分数据主要包含当前Broker节点的消息数据(在Kafka中称为Log日志)。这是一部分无状态的数据,也就是说每个Kafka的Broker节点都是以相同的逻辑运行。这种无状态的服务设计让Kafka集群能够比较容易的进行水平扩展。比如你需要用一个新的Broker服务来替换集群中一个旧的Broker服务,那么只需要将这部分无状态的数据从旧的Broker上转移到新的Broker上就可以了。
1.1、Topic下的消息是如何存储的?
在搭建Kafka服务时,我们在server.properties配置文件中通过log.dir属性指定了Kafka的日志存储目录。实际上,Kafka的所有消息就全都存储在这个目录下。
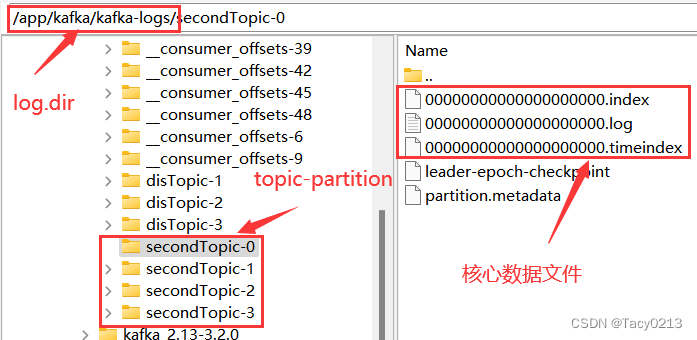
这些核心数据文件中,.log结尾的就是实际存储消息的日志文件。他的大小固定为1G(由参数log.segment.bytes参数指定),写满后就会新增一个新的文件。一个文件也成为一个segment文件名表示当前日志文件记录的第一条消息的偏移量。
.index和.timeindex是日志文件对应的索引文件。不过.index是以偏移量为索引来记录对应的.log日志文件中的消息偏移量。而.timeindex则是以时间戳为索引。
另外的两个文件,partition.metadata简单记录当前Partition所属的cluster和Topic。leader-epoch-checkpoint文件参见上面的epoch机制。
这些文件都是二进制的文件,无法使用文本工具直接查看。但是,Kafka提供了工具可以用来查看这些日志文件的内容。
#1、查看timeIndex文件
[oper@worker1 bin]$ ./kafka-dump-log.sh --files /app/kafka/kafka-logs/secondTopic-0/00000000000000000000.timeindex
Dumping /app/kafka/kafka-logs/secondTopic-0/00000000000000000000.timeindex
timestamp: 1661753911323 offset: 61
timestamp: 1661753976084 offset: 119
timestamp: 1661753977822 offset: 175
#2、查看index文件
[oper@worker1 bin]$ ./kafka-dump-log.sh --files /app/kafka/kafka-logs/secondTopic-0/00000000000000000000.index
Dumping /app/kafka/kafka-logs/secondTopic-0/00000000000000000000.index
offset: 61 position: 4216
offset: 119 position: 8331
offset: 175 position: 12496
#3、查看log文件
[oper@worker1 bin]$ ./kafka-dump-log.sh --files /app/kafka/kafka-logs/secondTopic-0/00000000000000000000.log
Dumping /app/kafka/kafka-logs/secondTopic-0/00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 1 count: 2 baseSequence: 0 lastSequence: 1 producerId: 7000 producerEpoch: 0 partitionLeaderEpoch: 11 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 0 CreateTime: 1661753909195 size: 99 magic: 2 compresscodec: none crc: 342616415 isvalid: true
baseOffset: 2 lastOffset: 2 count: 1 baseSequence: 2 lastSequence: 2 producerId: 7000 producerEpoch: 0 partitionLeaderEpoch: 11 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 99 CreateTime: 1661753909429 size: 80 magic: 2 compresscodec: none crc: 3141223692 isvalid: true
baseOffset: 3 lastOffset: 3 count: 1 baseSequence: 3 lastSequence: 3 producerId: 7000 producerEpoch: 0 partitionLeaderEpoch: 11 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 179 CreateTime: 1661753909524 size: 80 magic: 2 compresscodec: none crc: 1537372733 isvalid: true
.......
这些数据文件的记录方式,就是我们去理解Kafka本地存储的主线。对这里面的各个属性理解得越详细,也就表示对Kafka的消息日志处理机制理解得越详细。
1.1.1、 log文件追加记录所有消息
首先:在每个文件内部,Kafka都会以追加的方式写入新的消息日志。position就是消息记录的起点,size就是消息序列化后的长度。Kafka中的消息日志,只允许追加,不支持删除和修改。所以,只有文件名最大的一个log文件是当前写入消息的日志文件,其他文件都是不可修改的历史日志。
然后:每个Log文件都保持固定的大小。如果当前文件记录不下了,就会重新创建一个log文件,并以这个log文件写入的第一条消息的偏移量命名。这种设计其实是为了更方便进行文件映射,加快读消息的效率。
1.1.2、 index和timeindex加速读取log消息日志。
详细看下这几个文件的内容,就可以总结出Kafka记录消息日志的整体方式:
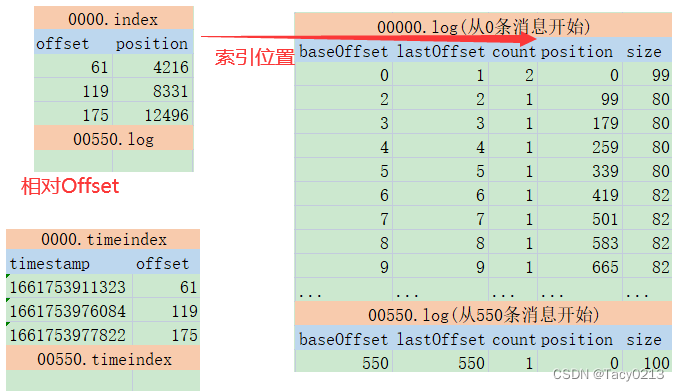
首先:index和timeindex都是以相对偏移量的方式建立log消息日志的数据索引。比如说 0000.index和0550.index中记录的索引数字,都是从0开始的。表示相对日志文件起点的消息偏移量。而绝对的消息偏移量可以通过日志文件名 + 相对偏移量得到。
然后:这两个索引并不是对每一条消息都建立索引。而是Broker每写入40KB的数据,就建立一条index索引。由参数log.index.interval.bytes定制。
log.index.interval.bytes
The interval with which we add an entry to the offset indexType: int
Default: 4096 (4 kibibytes)
Valid Values: [0,...]
Importance: medium
Update Mode: cluster-wide
index文件的作用类似于数据结构中的跳表,他的作用是用来加速查询log文件的效率。而timeindex文件的作用则是用来进行一些跟时间相关的消息处理。比如文件清理。
这两个索引文件也是Kafka的消费者能够指定从某一个offset或者某一个时间点读取消息的原因。
1.2、文件清理机制
Kafka为了防止过多的日志文件给服务器带来过大的压力,他会定期删除过期的log文件。Kafka的删除机制涉及到几组配置属性:
1.2.1、如何判断哪些日志文件过期了
log.retention.check.interval.ms:定时检测文件是否过期。默认是 300000毫秒,也就是五分钟。
log.retention.hours , log.retention.minutes, log.retention.ms 。 这一组参数表示文件保留多长时间。默认生效的是log.retention.hours,默认值是168小时,也就是7天。如果设置了更高的时间精度,以时间精度最高的配置为准。
在检查文件是否超时时,是以每个.timeindex中最大的那一条记录为准。
1.2.2、过期的日志文件如何处理
log.cleanup.policy:日志清理策略。有两个选项,delete表示删除日志文件。 compact表示压缩日志文件。
当log.cleanup.policy选择delete时,还有一个参数可以选择。log.retention.bytes:表示所有日志文件的大小。当总的日志文件大小超过这个阈值后,就会删除最早的日志文件。默认是-1,表示无限大。
压缩日志文件虽然不会直接删除日志文件,但是会造成消息丢失。压缩的过程中会将key相同的日志进行压缩,只保留最后一条。
1.3、Kafka的文件高效读写机制
这是Kafka非常重要的一个设计,同时也是面试频率超高的问题。可以分几个方向来理解。
1.3.1、Kafka的文件结构
Kafka的数据文件结构设计可以加速日志文件的读取。比如同一个Topic下的多个Partition单独记录日志文件,并行进行读取,这样可以加快Topic下的数据读取速度。然后index的稀疏索引结构,可以加快log日志检索的速度。
1.3.2、顺序写磁盘
这个跟操作系统有关,主要是硬盘结构。
对每个Log文件,Kafka会提前规划固定的大小,这样在申请文件时,可以提前占据一块连续的磁盘空间。然后,Kafka的log文件只能以追加的方式往文件的末端添加(这种写入方式称为顺序写),这样,新的数据写入时,就可以直接往直前申请的磁盘空间中写入,而不用再去磁盘其他地方寻找空闲的空间(普通的读写文件需要先寻找空闲的磁盘空间,再写入。这种写入方式称为随机写)。由于磁盘的空闲空间有可能并不是连续的,也就是说有很多文件碎片,所以磁盘写的效率会很低。
kafka的官网有测试数据,表明了同样的磁盘,顺序写速度能达到600M/s,基本与写内存的速度相当。而随机写的速度就只有100K/s,差距比加大。
1.3.3、零拷贝
零拷贝是Linux操作系统提供的一种IO优化机制,而Kafka大量的运用了零拷贝机制来加速文件读写。
传统的一次硬件IO是这样工作的。如下图所示: