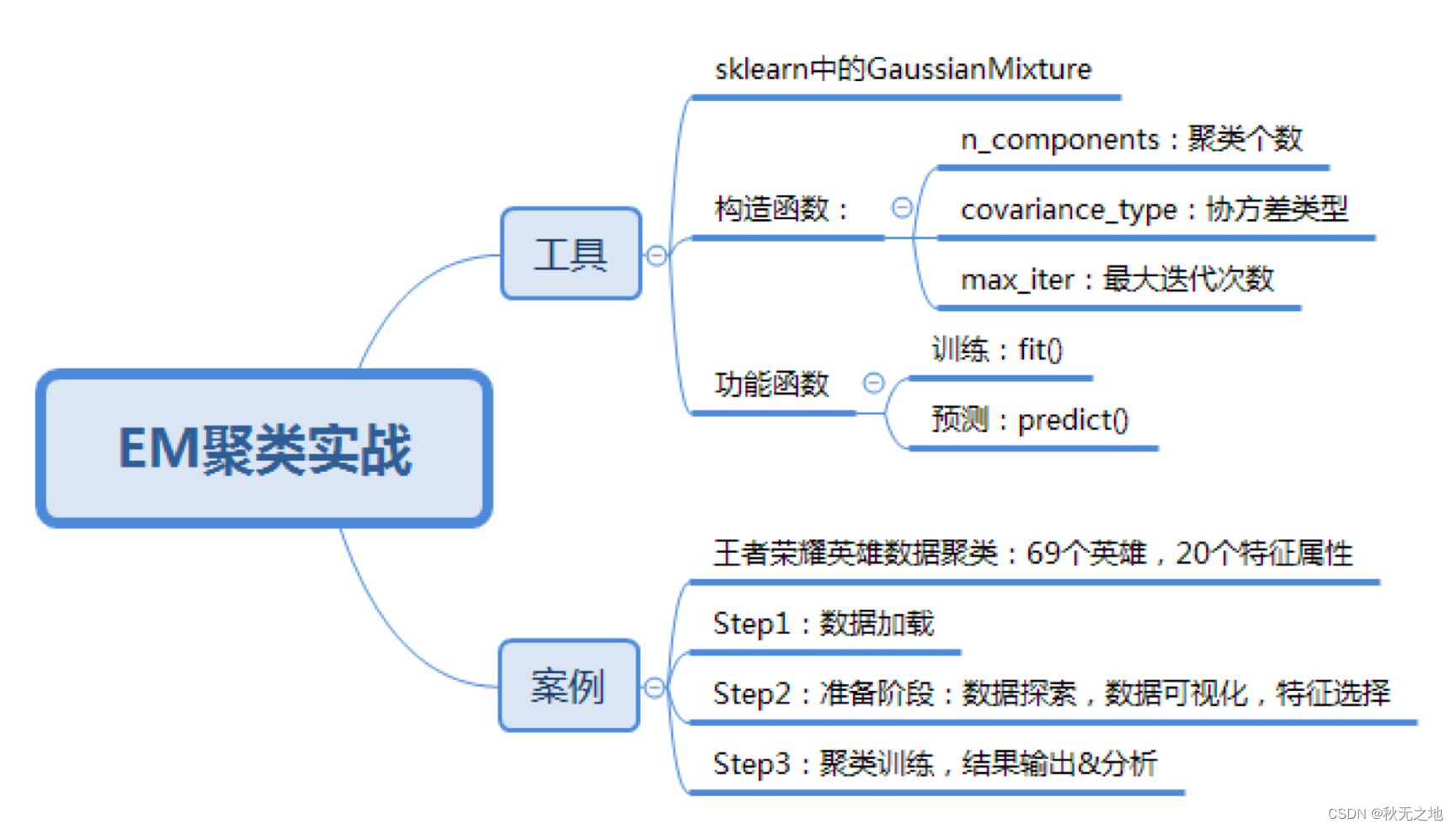
在我们的日常开发中,经常会使用到批量insert/update的语句来实现相关的业务功能。而如果数据量比较大的话,会导致sql语句更新失败、抛出异常的情况出现。这个时候我们可以批量执行sql语句,一批一批的执行。
比如说现在有一个需要批量修改商品的方法,我们可以这么改造:
public void batchUpdateById(List<Product> productList) {if (CollectionUtils.isEmpty(productList)) {return;}if (productList.size() > CommonUtils.BATCH_NUMBER) {int sizeNum = productList.size();int startNum = 0;int endNum = CommonUtils.BATCH_NUMBER - 1;while (startNum < endNum) {productMapper.batchUpdateById(productList.subList(startNum, endNum));startNum += CommonUtils.BATCH_NUMBER - 1;endNum += CommonUtils.BATCH_NUMBER - 1;if (endNum > sizeNum - 1) {endNum = sizeNum;}}} else {productMapper.batchUpdateById(productList);}
}上面BATCH_NUMBER的值是50,意味着当修改商品的数量大于50的时候,会以50个数据为一批,分批的执行;而如果修改商品的数量不大于50的时候,就直接一次执行就够了。
上面是我们自己手写的分批代码,而如果每个方法都这么写,也未免太过于繁琐了。这个时候我们就可以使用guava库中关于集合的partition分组方法来进行简化:
@Override
public void batchUpdateById(List<GoodsSkuBO> list) {if (CollectionUtils.isEmpty(list)) {return;}List<MerchantGoodsSkuDO> merchantGoodsSkuDOS = GoodsAnotherSkuConvertor.INSTANCE.goodsSkuBO2MerchantDOList(list);List<List<MerchantGoodsSkuDO>> groupMerchantGoodsSkuDOS = Lists.partition(merchantGoodsSkuDOS, CommonUtils.BATCH_NUMBER);groupMerchantGoodsSkuDOS.forEach(goodsSkuMasterMapper::batchUpdateById);
}由上可以看到,代码简化了很多(上面的goodsSkuBO2MerchantDOList方法只是将BO转成DO,和分组逻辑没有关系)。而对于批量查询的方法,我们也可以使用partition方法进行分组查询,防止in条件拼接太多的数据导致sql报错的情况出现:
@Override
public List<GoodsSkuBO> listBySpuIdsSimple(List<Long> spuIds) {if (CollectionUtils.isEmpty(spuIds)) {return Collections.emptyList();}//去重spuIds = spuIds.stream().distinct().collect(Collectors.toList());List<List<Long>> groupSpuIds = Lists.partition(spuIds, CommonUtils.BATCH_NUMBER);List<MerchantGoodsSkuDO> spuIdList = groupSpuIds.stream().map(goodsSkuMasterMapper::listBySpuIds).flatMap(Collection::stream).collect(Collectors.toList());return GoodsAnotherSkuConvertor.INSTANCE.merchantGoodsSkuDO2GoodsSkuBOList(spuIdList);
}
![[ruby on rails] postgres sql explain 优化](https://img-blog.csdnimg.cn/2277e669369c453f8ec8d2aef2d51b13.png)