现在的PC、手机客户端等终端设备大量使用了网页前后端技术,另外主流的网站也会经常会更新,导致以前一个月更新一次爬虫代码,变成了天天需要更新代码,所以自动化爬虫技术在当前就显得特别重要,最近我也是在多次更新某个爬虫后,突然有了这样的需求,尝试搜索了下相关信息,发现是有人弄过这东西,我想哪些大厂肯定也有爬虫工程师开发过这东西,但是都没有开源,找不到啥资料,所以我想写一篇这方面的东西,感兴趣的朋友可以看下去。
首先,我们先确定下基本思路,我经常使用Requests+BeautifulSoup写爬虫,所以基本代码的模板很好写,如下:
code_template = """
import requests
from bs4 import BeautifulSoupdef crawl(url):response = requests.get(url)response.raise_for_status()soup = BeautifulSoup(response.text, 'html.parser')results = []SELECTORS_PLACEHOLDERreturn resultsif __name__ == "__main__":url = "URL_PLACEHOLDER"results = crawl(url)for result in results:print(result)"""其中SELECTORS_PLACEHOLDER就是我们需要用程序动态填写的内容,这是根据爬虫自我填写的代码,输入的代码如下所示: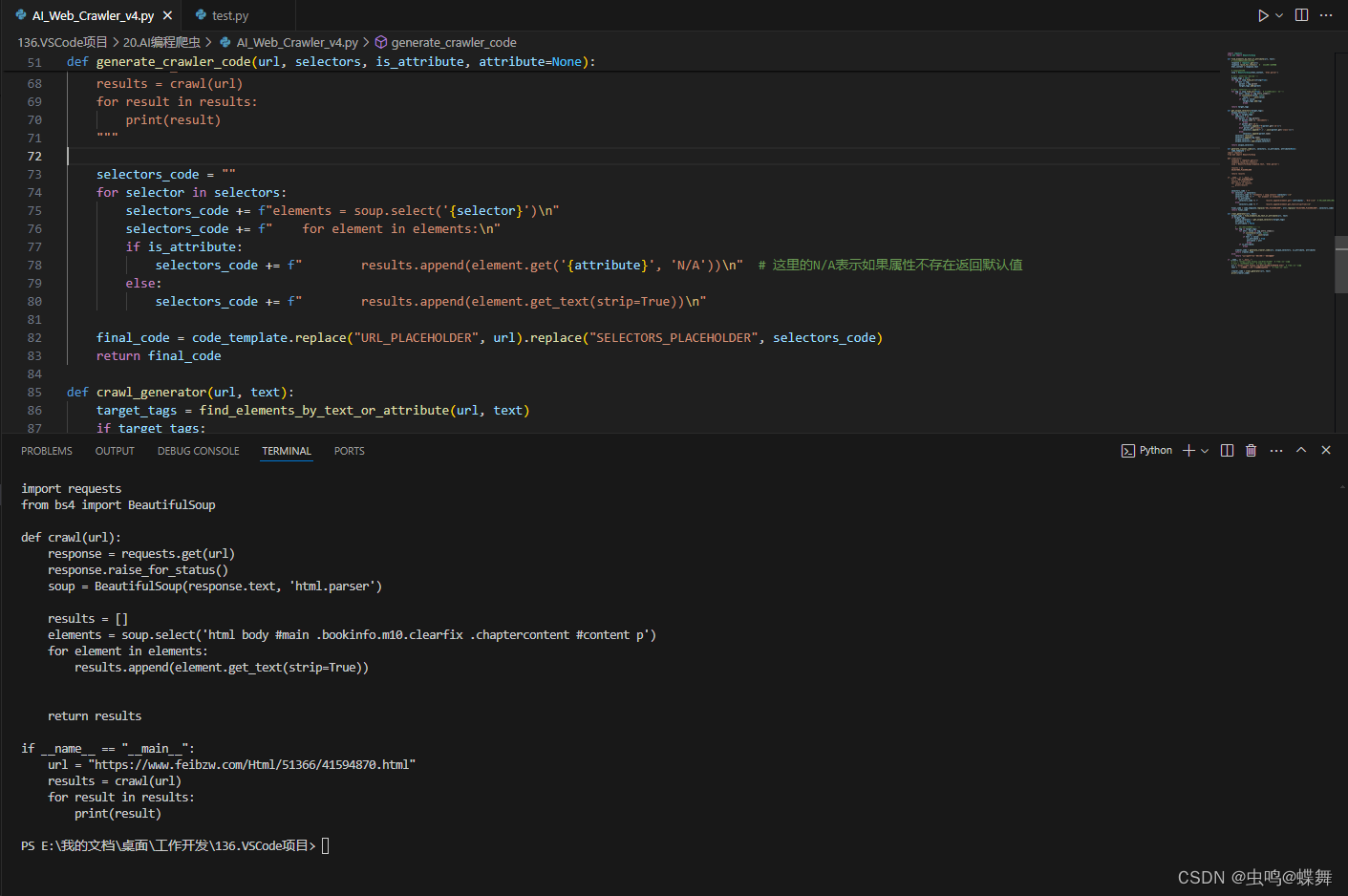 那么我们跟这个程序根据什么爬虫那,其实也很简单,我们使用上一篇文章的例子,链接如下为:
那么我们跟这个程序根据什么爬虫那,其实也很简单,我们使用上一篇文章的例子,链接如下为:
Python爬虫系列-爬取小说20240703更新(Request方法)![]() https://blog.csdn.net/donglxd/article/details/140145498
https://blog.csdn.net/donglxd/article/details/140145498
我们先试试爬取某个章节部分,随便打开一篇文章,如下图: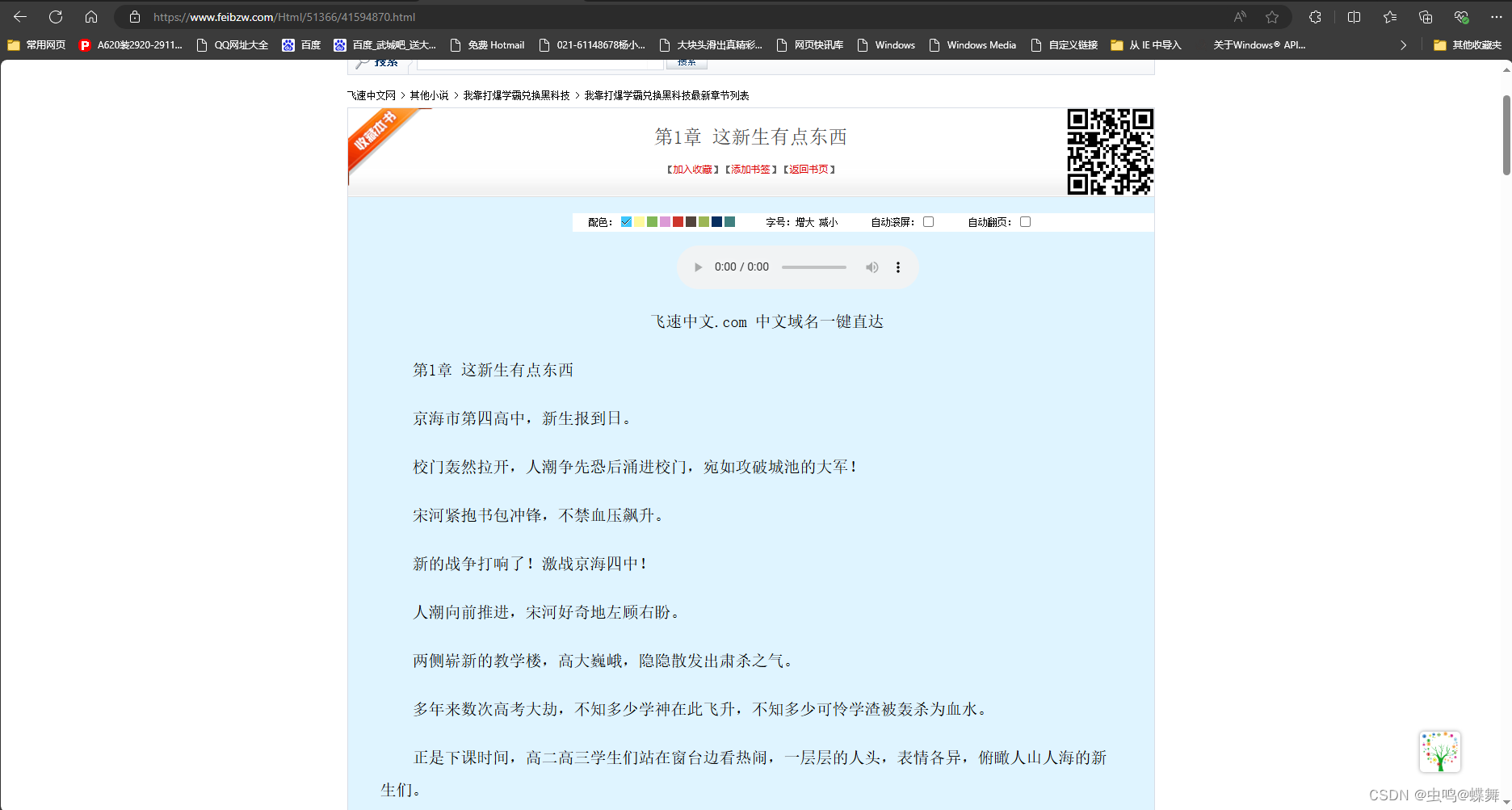
选取一行字,比如正文的第一句:"京海市第四高中,新生报到日。" 把这句作为一个参数代入到我的程序中,同时把这篇文章的网址也代入到我的程序中如下:
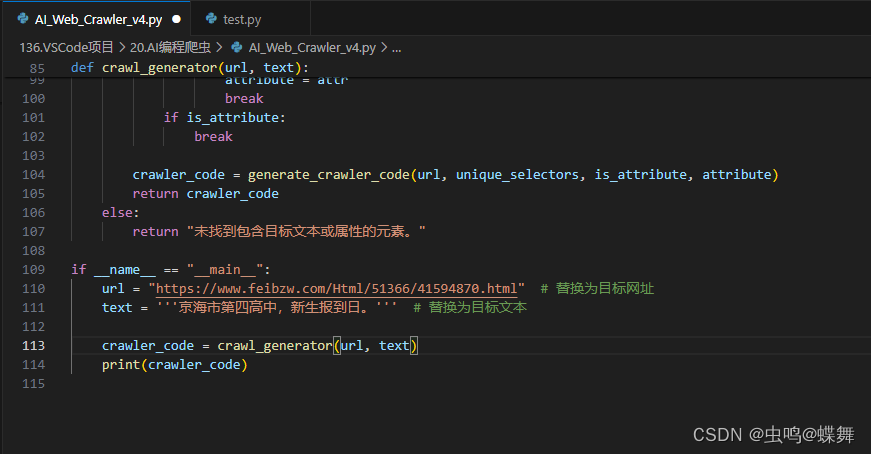
把运行后的自动写的代码如下:
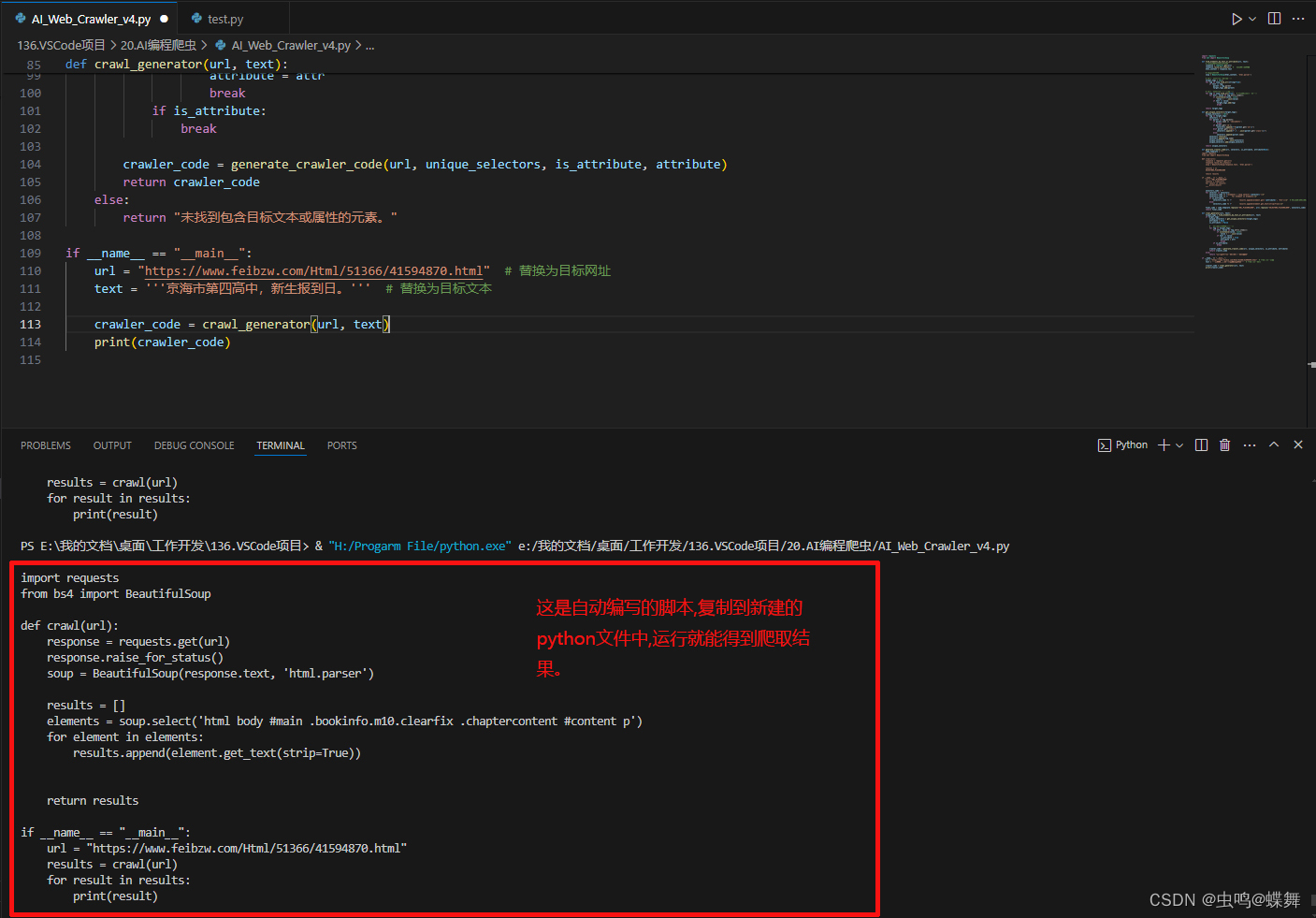
复制后新建一个python文件,粘贴进去,保存并运行,就会得到如下结果:
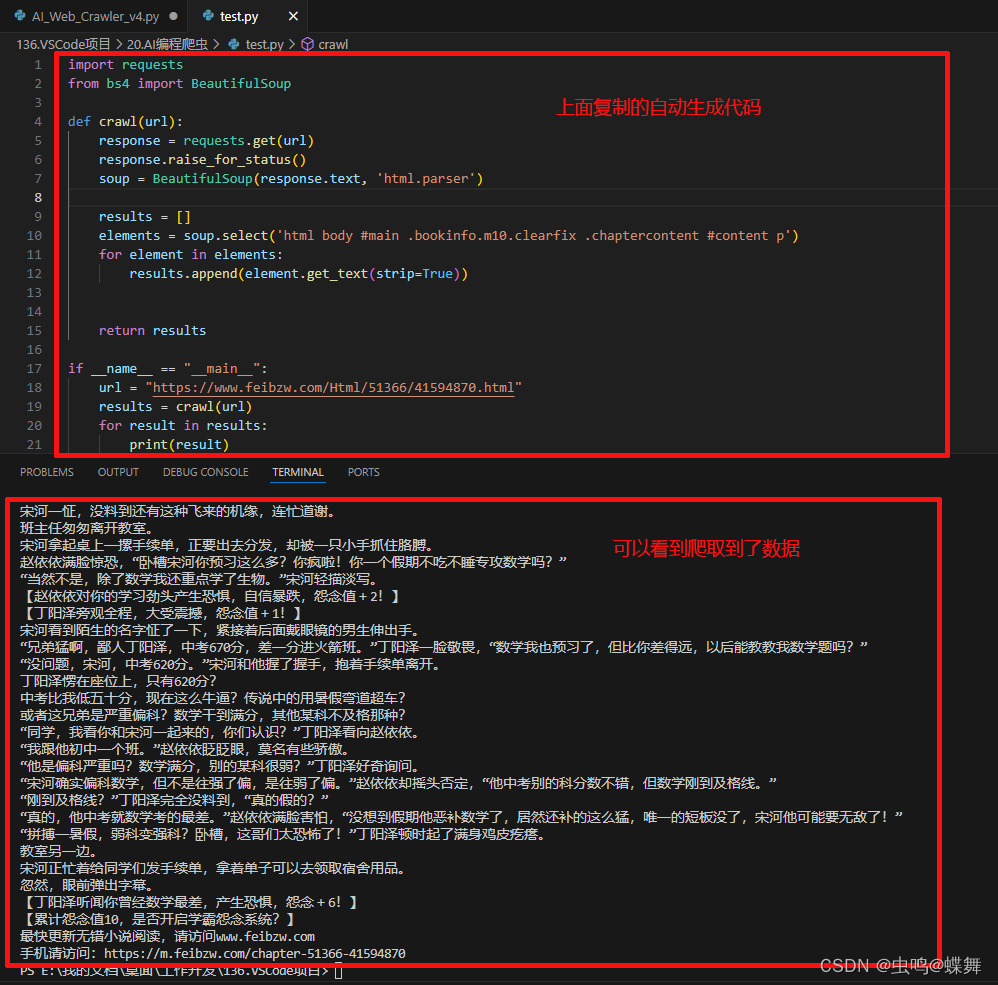
有人要问了,我的自动生成爬虫,只能爬取文本吗?不能爬取属性值吗?比如属性里的链接?当然可以,请看下图:
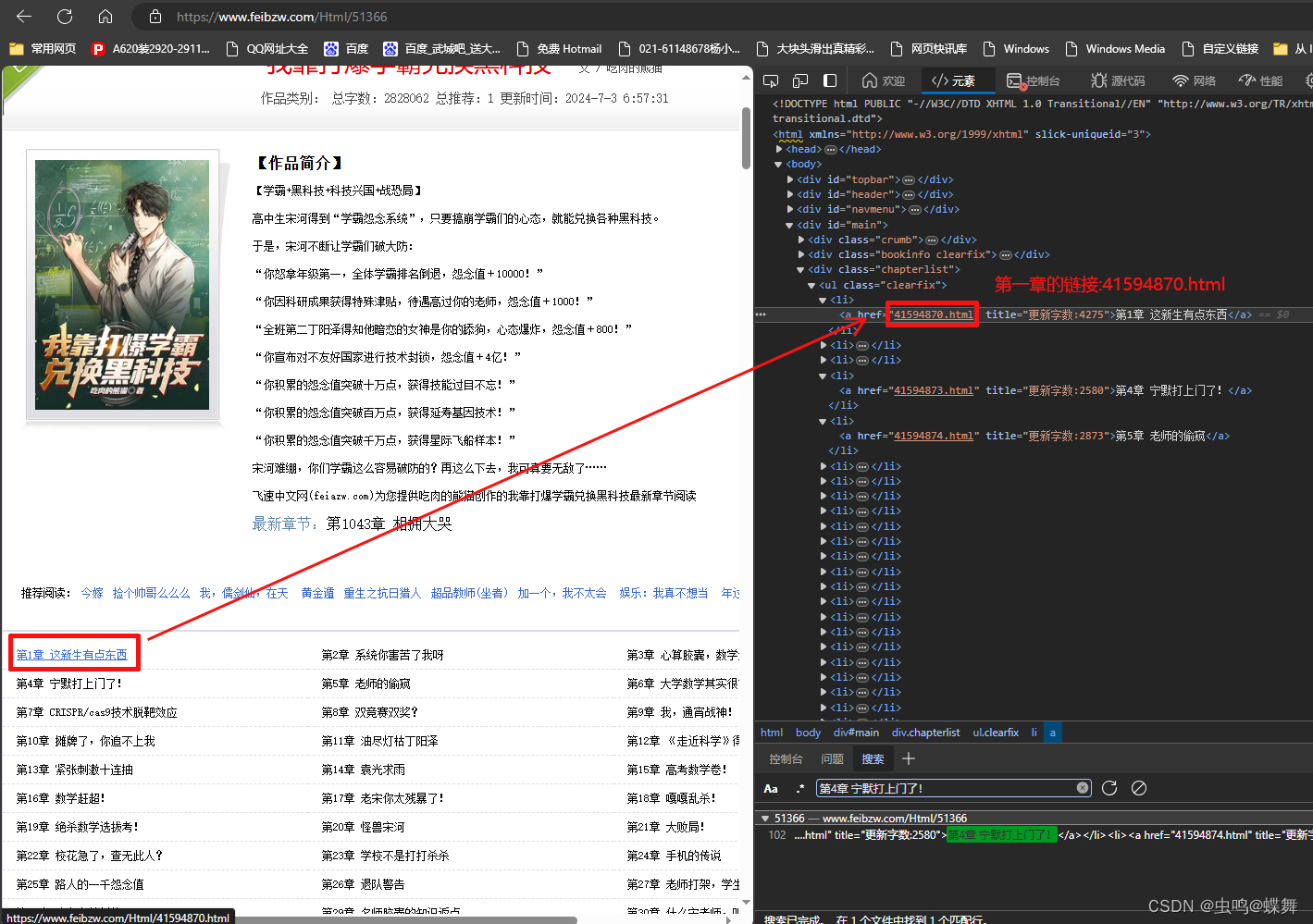 可以看到第一章的链接是"41594870.html",这个不是绝对链接,而是相对链接,需要拼接处理,这个很简单,我想稍微学过5分钟python字符串语法的都会。我们把这个"41594870.html"属性代入我的程序读取看看,参数设置如下:
可以看到第一章的链接是"41594870.html",这个不是绝对链接,而是相对链接,需要拼接处理,这个很简单,我想稍微学过5分钟python字符串语法的都会。我们把这个"41594870.html"属性代入我的程序读取看看,参数设置如下:
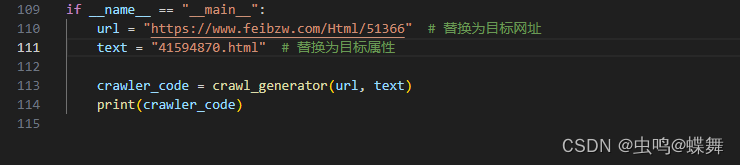
生成的爬虫如下: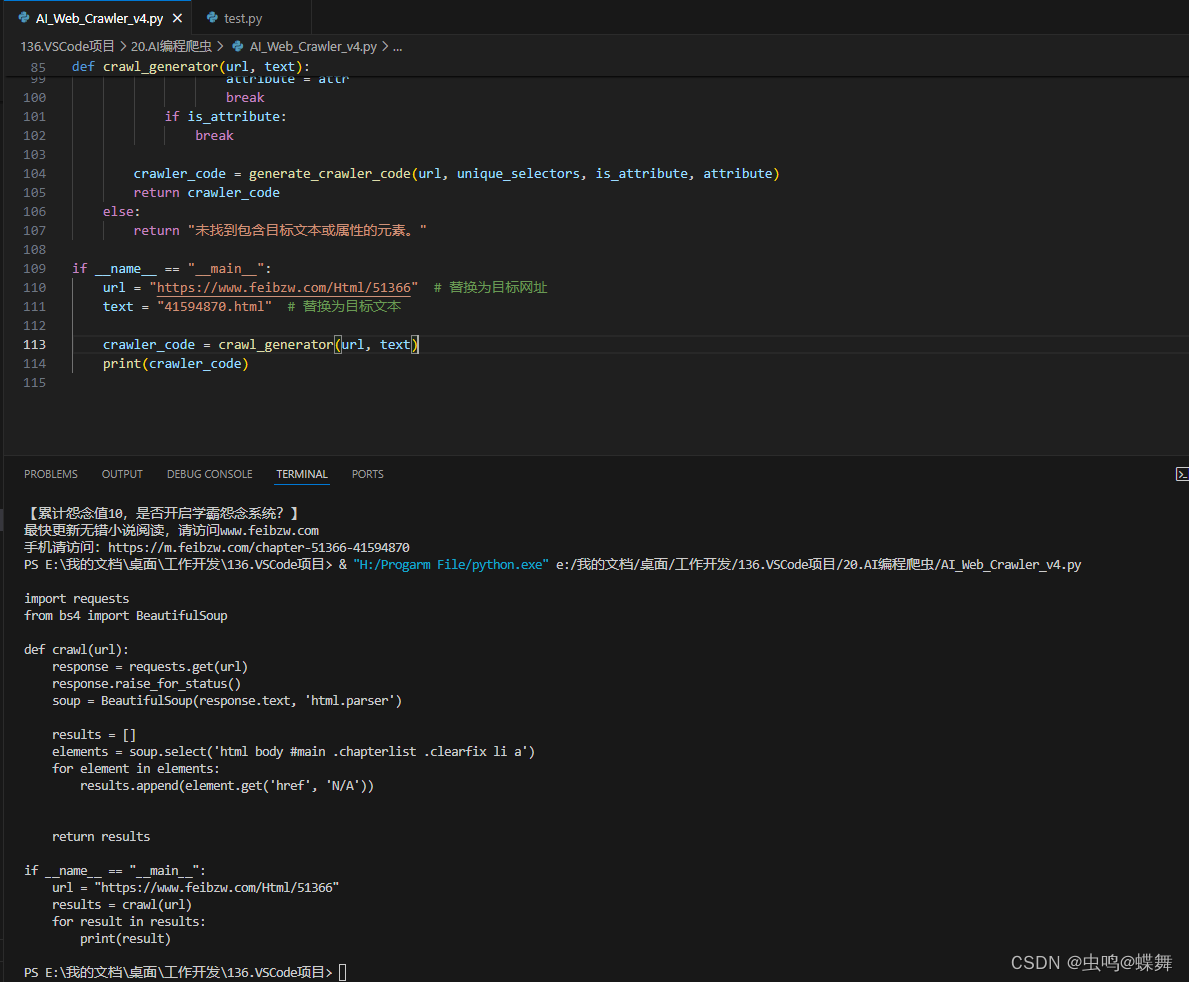 新建一个python文档运行看看:
新建一个python文档运行看看:
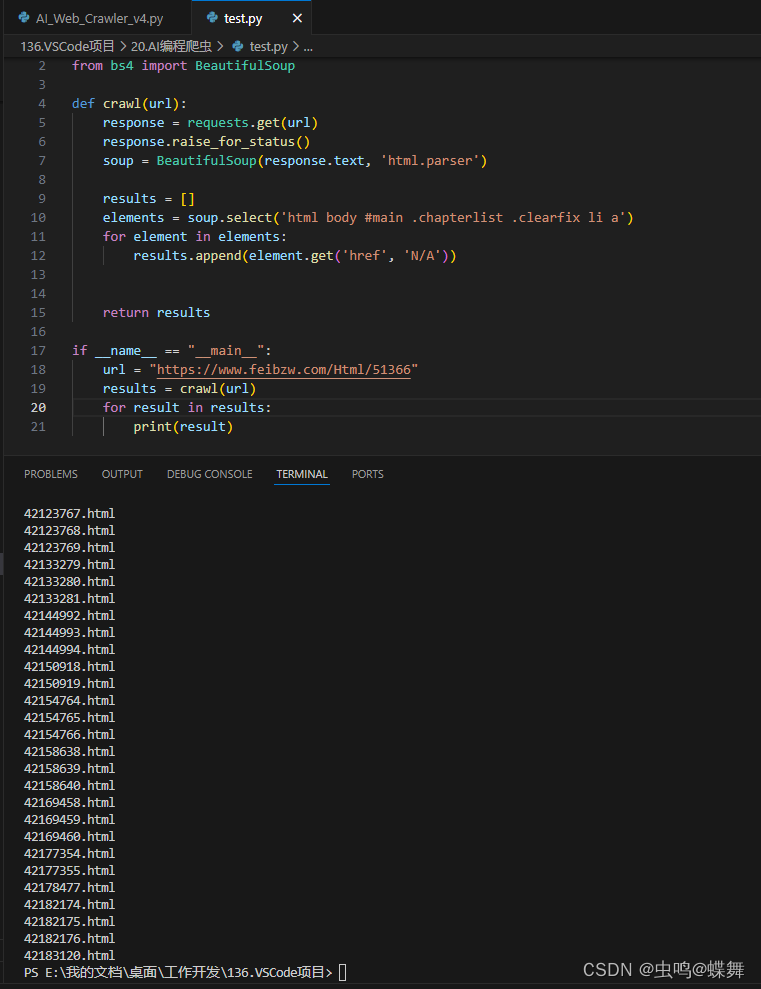
可以看到爬取成功了,我们可以尝试把两者结合起来,写一个手动爬虫,如下:
import requests
from bs4 import BeautifulSoup
import time# 导入time库加延迟用# def crawl(url):
def getText(url):#把crawl函数建立一个新名称,方便调用,这个函数和下面的函数名不同,已区分开功能(读取每章内容)response = requests.get(url)response.raise_for_status()soup = BeautifulSoup(response.text, 'html.parser')# results = []results = ""#把数组改成字符串拼接用elements = soup.select('html body #main .bookinfo.m10.clearfix .chaptercontent #content p')for element in elements:# results.append(element.get_text(strip=True))results = results + element.get_text(strip=True) + "\n"results = results + "\n"#每章之间空一行return results# def crawl(url):
def getUrl(url):#把crawl函数建立一个新名称,方便调用,这个函数和下面的函数名不同,已区分开功能(读取每章网址)response = requests.get(url)response.raise_for_status()soup = BeautifulSoup(response.text, 'html.parser')# results = []elements = soup.select('html body #main .chapterlist .clearfix li a')with open("20.AI编程爬虫\\1.txt","a+",encoding="utf-8") as f:# 创建一个新的txt文档,记录小说内容。for element in elements:# results.append(element.get('href', 'N/A'))results = getText(url + "/" + element.get('href', 'N/A'))# 把主链接和href的相对链接拼合f.write(results)#写入每章内容到txt文档print("链接内容:" + url + "/" + element.get('href', 'N/A') + "写入成功!")#输出写入的链接time.sleep(3)#为了爬取稳定加点延迟# return resultsif __name__ == "__main__":url = "https://www.feibzw.com/Html/51366"# results = getUrl(url)getUrl(url)# for result in results:# print(result)可以看到上面的代码中,我注释的代码都是原来两个爬虫里的,新加的代码都有注释说明,一行行写下来不难,这部分其实也可以自动化,但是可能每个网站的链接地址都不同,拼接方法也不同,所以我写了这个模板给大家套用,按实际情况改就行了,这个模板可以应付大多数小说网站。我在这只是教大家方法,希望有抛砖引玉的作用,授人以渔。
最后放上我的自动生成程序,免费提供给大家:
import requests
from bs4 import BeautifulSoupdef find_elements_by_text_or_attribute(url, text):# 发送请求并获取网页内容response = requests.get(url)response.raise_for_status() # 检查请求是否成功html_content = response.text# 解析网页内容soup = BeautifulSoup(html_content, 'html.parser')# 查找所有包含目标文本的标签target_tags = set()for tag in soup.find_all(string=True):if text in tag:parent = tag.parenttarget_tags.add(parent)# 查找所有包含目标属性值的标签for tag in soup.find_all(True): # True表示查找所有标签for attr, value in tag.attrs.items():if isinstance(value, list):value = ' '.join(value)if text in value:target_tags.add(tag)breakreturn target_tagsdef get_unique_selectors(target_tags):unique_selectors = set()for tag in target_tags:selectors = []for parent in tag.parents:if parent.name == '[document]':breakif parent.get('id'):selectors.append(f"#{parent.get('id')}")elif parent.get('class'):selectors.append(f".{'.'.join(parent.get('class'))}")else:selectors.append(parent.name)selectors.reverse()selectors.append(tag.name)unique_selector = ' '.join(selectors)unique_selectors.add(unique_selector)return unique_selectorsdef generate_crawler_code(url, selectors, is_attribute, attribute=None):code_template = """
import requests
from bs4 import BeautifulSoupdef crawl(url):response = requests.get(url)response.raise_for_status()soup = BeautifulSoup(response.text, 'html.parser')results = []SELECTORS_PLACEHOLDERreturn resultsif __name__ == "__main__":url = "URL_PLACEHOLDER"results = crawl(url)for result in results:print(result)"""selectors_code = ""for selector in selectors:selectors_code += f"elements = soup.select('{selector}')\n"selectors_code += f" for element in elements:\n"if is_attribute:selectors_code += f" results.append(element.get('{attribute}', 'N/A'))\n" # 这里的N/A表示如果属性不存在返回默认值else:selectors_code += f" results.append(element.get_text(strip=True))\n"final_code = code_template.replace("URL_PLACEHOLDER", url).replace("SELECTORS_PLACEHOLDER", selectors_code)return final_codedef crawl_generator(url, text):target_tags = find_elements_by_text_or_attribute(url, text)if target_tags:unique_selectors = get_unique_selectors(target_tags)attribute = Noneis_attribute = False# 检查是文本内容还是属性值for tag in target_tags:for attr, value in tag.attrs.items():if isinstance(value, list):value = ' '.join(value)if text in value:is_attribute = Trueattribute = attrbreakif is_attribute:breakcrawler_code = generate_crawler_code(url, unique_selectors, is_attribute, attribute)return crawler_codeelse:return "未找到包含目标文本或属性的元素。"if __name__ == "__main__":url = "https://www.feibzw.com/Html/51366" # 替换为目标网址text = "41594870.html" # 替换为目标文本# url = "https://www.feibzw.com/Html/51366/41594870.html" # 替换为目标网址# text = '''京海市第四高中,新生报到日。''' # 替换为目标文本crawler_code = crawl_generator(url, text)print(crawler_code)
谢谢大家观看,再见!






)](https://i-blog.csdnimg.cn/direct/704e03d5212a475d97da16b27a150ad9.png)