一文读懂:AI大模型!
引言
近年来,随着深度学习技术的迅猛发展,AI大模型已经成为人工智能领域的重要研究方向和热点话题。AI大模型,指的是拥有巨大参数规模和强大学习能力的神经网络模型,如BERT、GPT等,这些模型在自然语言处理、计算机视觉等领域取得了令人瞩目的成果。
AI大模型的意义不仅在于其巨大的参数规模和学习能力,更在于它们对于解决现实世界复杂问题的潜力。这些模型可以通过大规模数据的学习,自动发现数据之间的关联性和特征,从而实现对文本、图像等数据的高效处理和理解。
在自然语言处理领域,AI大模型已经在文本生成、语义理解等任务上取得了令人瞩目的成绩;在计算机视觉领域,它们也在图像分类、目标检测等任务上展现出了强大的能力。
科技腾飞,数据洪流,AI大模型正蓄势待发,引领创新浪潮。本文将深入剖析其发展历程、技术奥秘及应用展望,为您呈现一份详尽的参考指南,助您把握AI大模型带来的无限可能。
一、背景与相关工作AI大模型,以数十亿至数千亿参数构建,依托深度学习技术,凭借海量数据训练,展现出卓越性能,跨越多领域任务,引领智能技术新高度。
1、AI大模型的背景
AI大模型源于深度学习,该技术模拟人脑工作原理,构建多层神经网络以解析复杂数据。历经数十年发展,深度学习实现了多次飞跃,引领AI领域向前迈进。
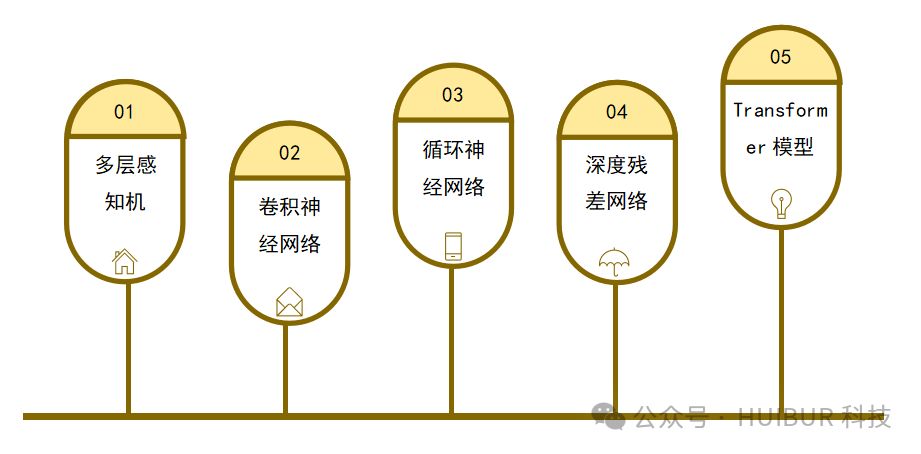
卷积神经网络(CNN)专为图像处理打造,利用卷积和池化层提取图像局部特征,高效实现图像分类、目标检测等,引领图像处理新潮流。
循环神经网络(RNN)是处理序列数据的强大工具,具备记忆能力,广泛应用于语言建模、机器翻译等前沿领域。
深度残差网络(ResNet)革新性地通过残差连接攻克了梯度消失与爆炸难题,极大推动了深层网络结构的训练与实现。
随着数据量和计算资源的激增,研究人员致力于构建超大规模神经网络,如BERT、GPT、T5等,参数规模高达数十亿至数千亿,以显著提升模型的表征和泛化能力,推动深度学习技术的前沿发展。
AI大模型的崛起,引领人工智能领域跨越式进步。在自然语言处理、计算机视觉、强化学习等领域屡获佳绩,赋能日常生活与工业生产。然而,高昂的训练成本、庞大的参数规模及有限的泛化能力,仍待科研力量深入探索与优化,推动AI技术迈向新高度。
2、AI大模型领域的研究成果和应用案例
AI大模型领域成果斐然,涵盖自然语言处理、计算机视觉、强化学习等,代表性研究成果及应用案例丰富,彰显其广泛影响力与实用价值。
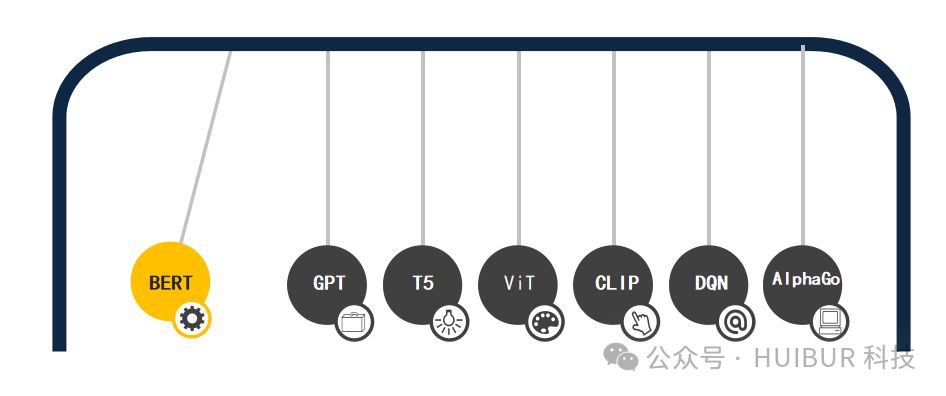
(1)自然语言处理(NLP):
BERT,基于Transformer架构的预训练语言模型,以其独特的双向编码器技术,精准捕获文本双向上下文信息。这一创新方法在多项NLP任务中均斩获顶尖表现,包括但不限于文本分类、命名实体识别及文本相似度计算,引领NLP领域迈向新高度。BERT,无疑是自然语言处理领域的杰出代表,展现了强大的模型实力和广泛的应用前景。
GPT系列模型,基于Transformer架构,卓越于生成连贯自然语言文本。在文本生成、对话生成等任务中,GPT展现出非凡实力,引领自然语言处理新潮流。
T5,一款领先的文本-文本转换模型,通过简化输入与输出形式,轻松驾驭翻译、摘要、问答等多样NLP任务,展现其卓越的通用性和高效性。
(2)计算机视觉:
ViT,即Vision Transformer,引领图像处理新纪元。通过将图像细分为图块,并历经线性与Transformer编码层深度处理,ViT在图像分类领域大放异彩,其卓越性能已超越传统CNN模型,为视觉识别领域带来革命性突破。
CLIP模型引领跨模态视觉理解新纪元,融合自然语言与图像表示,展现卓越零样本学习与多模态性能。无论是图像分类还是检索,CLIP均能以出色表现,开启视觉智能新时代。
(3)强化学习:
DQN,即深度Q网络,是强化学习领域的突破。它融合深度学习表征能力与强化学习决策智慧,成功应用于Atari游戏等复杂任务,实现了高效决策。DQN,让智能体在复杂环境中游刃有余,展现无限潜力。
AlphaGo,DeepMind的围棋AI杰作,凭强化学习与深度神经网络技术,勇破围棋界壁垒,力克顶尖棋手。其进化版AlphaZero,无需人类专家指导,仅凭自我对弈,便成就围棋、象棋、将棋三大棋类巅峰AI,彰显AI学习的无限可能。
AI大模型在各领域尽显卓越潜力,为智能系统提供坚实技术支撑。随着技术进步和应用场景拓展,AI大模型将日益发挥关键作用,引领人工智能迈向更高峰。
3、目前AI大模型面临的挑战和机遇
(1)挑战:
训练大型神经网络成本高昂,耗费大量计算资源和时间,成为研究机构及企业面临的挑战,亟待高效解决方案以降低成本。
模型参数规模激增,呈指数级增长,极大提升了存储与计算复杂度,显著增加了训练与推理的时间与资源投入,挑战重重。
AI大模型在大数据中表现卓越,但面对少样本、小样本时,其泛化能力尚需增强,这或将成为其在现实世界广泛应用的潜在瓶颈。
AI大模型结构复杂、参数繁多,难以揭示其内部工作机制,影响模型的可信度和解释性,成为技术发展的一大挑战。
数据隐私与安全性是大型模型训练的重大挑战。确保数据不泄露敏感信息至关重要,否则可能引发严重后果,必须严加防范。
(2)机遇:
数据激增与算力跃升,AI大模型性能有望在多元任务中显著增强。此外,新型软硬件技术的涌现,将大幅提升模型训练与推理效率,开启AI新纪元。
模型优化与压缩技术日新月异,有效应对AI大模型挑战,减轻存储与计算负担,降低训练成本,显著提升模型效率与性能。
AI大模型通过多模态数据(文本、图像、音频等)融合,为复杂任务提供创新解决方案,拓宽应用场景,显著提升模型智能水平。
AI大模型的发展倚赖跨学科合作与创新,各领域知识与技术的交融,将助推其迈向全新高度,实现更高层次的突破。
二、理论基础AI大模型研究中,理论基础至关重要。它指导模型构建与优化,并深刻影响模型性能与应用效果,是不可或缺的核心要素。
1、AI大模型的基本原理和核心技术
AI大模型的基本原理和核心技术主要包括以下几个方面:
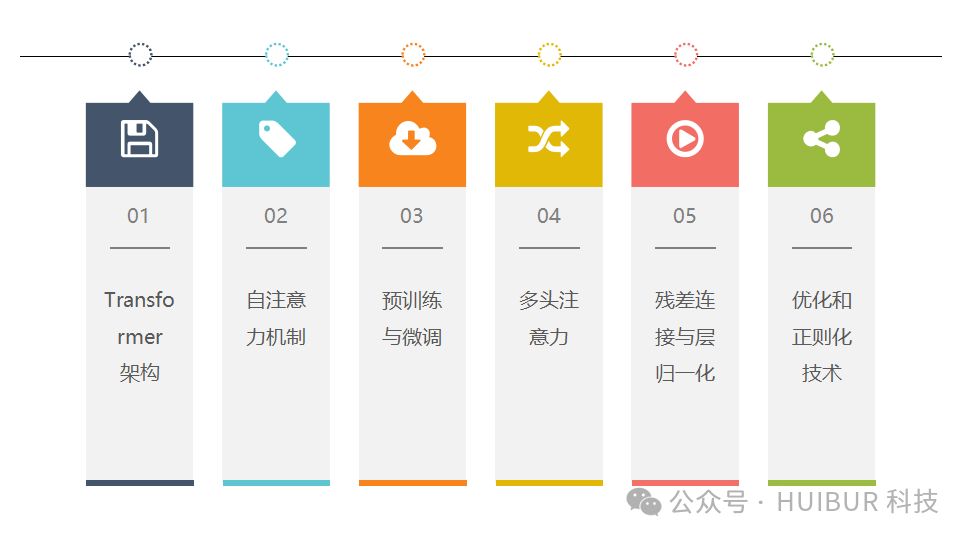
(1)Transformer 架构:
Transformer 是一种基于自注意力机制的神经网络架构,由 Vaswani 等人在论文《Attention Is All You Need》中提出。它摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),完全采用了自注意力机制来实现序列到序列的学习。Transformer 架构包括编码器和解码器,其中编码器用于将输入序列编码成抽象表示,解码器用于根据编码器输出和上下文信息生成目标序列。Transformer 架构的出现为AI大模型的发展奠定了基础。
(2)自注意力机制:
自注意力机制,Transformer架构之精髓,实现全局建模,让模型在输入序列的每个位置上都聚焦注意力。此机制不仅捕捉序列内部不同位置间的依赖关系,还能高效处理长距离依赖,为模型理解和处理复杂序列数据提供强大支持。
(3)预训练与微调:
AI大模型借助预训练和微调策略实现高效训练。预训练阶段,模型通过自监督或有监督学习,从海量无标注数据中提炼通用特征。随后,在微调阶段,模型针对特定任务的有标注数据进行调整,以满足特定需求。这一策略显著提升了模型的泛化性和适应性。
(4)多头注意力:
多头注意力机制,Transformer的卓越变体,实现多子空间特征学习。分头并行捕捉多语义层次信息,大幅提升模型表达能力与学习效率,实现更高效的特征融合与处理。
(5)残差连接与层归一化:
残差连接与层归一化是深度神经网络性能提升的关键。残差连接传递原始信息,缓解梯度问题;层归一化加速训练收敛,增强模型稳定性和泛化能力,共同助力深度学习模型的卓越表现。
(6)优化和正则化技术:
AI大模型训练运用先进优化算法与正则化技术,如随机梯度下降(SGD)、自适应学习率优化器(Adam)和动量法,以提升性能与泛化能力。同时,采用L1、L2正则化和Dropout等技术有效降低过拟合风险,确保模型高效稳定。
2、神经网络训练与优化的基本理论
神经网络训练与优化的基本理论涵盖了许多重要概念和技术,以下是其中的一些:
(1)损失函数(Loss Function):
损失函数是评估模型预测与实际标签差距的关键工具。在监督学习中,通过最小化损失函数,如均方误差(MSE)、交叉熵损失(Cross Entropy)和对数损失(Log Loss),优化模型参数,确保预测结果贴近真实标签。
(2)反向传播算法(Backpropagation):
反向传播算法,神经网络训练之关键,精准计算损失函数对模型参数的梯度。链式法则助力误差自输出层回溯至输入层,量化各参数对损失的影响,随后通过梯度下降优化,更新模型参数,提升网络性能。
(3)优化算法(Optimization Algorithms):
优化算法精准调整模型参数,最小化损失函数。主流算法如SGD、Momentum、AdaGrad、RMSProp、Adam等,均基于梯度下降优化,显著提升收敛速度、稳定性及泛化能力,为模型性能保驾护航。
(4)激活函数(Activation Functions):
激活函数是神经网络中的关键非线性变换,如Sigmoid、ReLU、Tanh等,它们增强模型表达能力。合理选择激活函数能显著提升模型拟合能力和训练效率,为神经网络带来更佳性能。
(5)权重初始化(Weight Initialization):
权重初始化关乎神经网络训练的稳定性和速度,其方法多样,包括随机、Xavier和He初始化等,对提升模型性能至关重要。
(6)批量归一化(Batch Normalization):
批量归一化技术,通过每批次数据的归一化处理,显著加速神经网络训练,增强模型稳定性,确保更快、更稳定的收敛效果。
过拟合即模型在训练集上性能优越,却难以泛化至测试集。为降低过拟合风险,建议运用正则化技术,如L1、L2正则化及Dropout,简化模型复杂度,强化泛化能力。
(8)学习率调度(Learning Rate Scheduling):
学习率调度,动态优化训练策略。根据模型性能自适应调整学习率,策略多样,如学习率衰减、余弦退火、指数衰减等,助力模型高效训练。
神经网络训练与优化的核心在于这些基本理论,其合理应用将显著提升模型性能与泛化能力,为深度学习应用奠定坚实基础。
3、与AI大模型相关的理论模型和概念
(1)深度学习(Deep Learning):
深度学习,模拟人脑多层神经网络,深度解析复杂数据。AI大模型基于深度学习,凭借海量数据训练,展现卓越表征与泛化能力,引领智能时代新潮流。
(2)神经网络(Neural Networks):
神经网络,深度学习之基石,由多层神经元构建,掌握数据特征,精确建模预测复杂任务。AI大模型更以其数十至数百层结构,展现强大能力。
(3)Transformer 架构:
Transformer,由Vaswani等人提出的自注意力机制神经网络架构,已成为自然语言处理领域的基石,为BERT、GPT、T5等AI大模型提供强大支撑,引领AI技术新潮流。
(4)自注意力机制(Self-Attention Mechanism):
自注意力机制,捕捉序列全局依赖的利器,它全面审视输入序列的每个位置,精准捕捉长距离依赖。作为Transformer架构的核心,自注意力机制引领了数据处理的革新潮流。
(5)预训练与微调(Pre-training and Fine-tuning):
AI大模型训练推崇预训练与微调策略。预训练时,模型在海量无标注数据上自监督或有监督学习,形成通用特征;微调阶段,则针对特定任务,在有标注数据上精细调整,以满足特定需求。此策略精准高效,是AI领域的翘楚之选。
(6)多模态学习(Multi-Modal Learning):
多模态学习融合文本、图像、音频等数据,实现联合建模。AI大模型精通多模态数据处理,卓越于图文生成、图像问答等任务,引领智能新纪元。
(7)元学习(Meta-Learning):
元学习赋能模型自主学习之道,通过掌握跨任务学习策略,迅速适应新任务,显著提升AI大模型在小样本场景下的泛化能力,引领智能未来。
三、技术方法AI大模型的研究与应用,技术方法的选择与运用至关重要。本节将深入剖析训练、优化与压缩AI大模型的前沿技术,涵盖分布式训练至模型压缩等全链条,轻松应对复杂模型挑战。
1、训练大型模型的技术方法
(1)分布式训练(Distributed Training):
分布式训练通过多节点并行处理,利用消息传递或参数服务器高效通信,显著加速训练,轻松应对大规模数据和复杂模型的计算与存储挑战,为深度学习带来质的飞跃。
(2)混合精度训练(Mixed Precision Training):
混合精度训练巧妙结合不同数值精度,对参数和梯度采用低精度(如半精度浮点数),而梯度更新则采用高精度(如单精度浮点数)。此法显著减少内存占用和计算量,大幅加速模型训练效率。
数据并行通过分割训练数据至多节点并行处理,确保各节点模型参数一致。模型并行则将模型分块至不同节点训练,各节点参数各异。二者可结合,高效应对大型模型与海量数据的训练挑战,显著提升训练效率。
(4)异步训练(Asynchronous Training):
异步训练,分布式训练中的高效策略,允许节点间异步更新参数,无需等待全部节点完成。虽提升训练效率,但需注意收敛速度与稳定性挑战,确保高效同时保障模型质量。
(5)模型蒸馏(Model Distillation):
模型蒸馏,高效训练新策略。它巧妙地将大型复杂模型知识精简至小型模型中,经训练后大幅减少存储和计算需求,是追求效率与性能并存的最佳选择。
(6)预训练与微调(Pre-training and Fine-tuning):
预训练,即在大规模无标注数据上通过自监督或有监督学习初始化模型;微调,即在特定任务的有标注数据上调整预训练模型,以满足特定需求。预训练与微调,为训练大型模型提供了高效策略。
动态学习率调整技术,如学习率衰减、余弦退火、指数衰减等,根据模型训练性能实时调整学习率,显著提升模型收敛速度和泛化能力。
这些技术方法和工程实践高效训练大型模型,显著增强性能与泛化能力,并加速收敛速度,助力在大规模数据和复杂任务中的卓越应用。
2、大型模型的优化和压缩技术
大型模型优化与压缩技术,有效提升模型效率,降低资源消耗,实现推理速度飞跃,为行业带来更高效、轻量级的解决方案。
(1)模型剪枝(Model Pruning):
模型剪枝通过精准剔除冗余参数与连接,有效缩减模型体积与计算负载。结构化、非结构化和稀疏化剪枝是常用手段,可大幅降低参数量,节省存储空间,并显著提升推理效率。
(2)量化(Quantization):
量化技术将模型参数与激活值由浮点数转为定点数或低位宽浮点数,常见方法涵盖定点、二值、三值量化等。此技术显著降低存储需求、计算复杂度,并提升模型在硬件上的执行效率。
(3)低秩近似(Low-Rank Approximation):
低秩近似,核心在于通过分解模型参数矩阵为低秩矩阵,大幅减少参数量与计算量。其中,奇异值分解(SVD)和张量分解等方法尤为常用,高效优化模型性能,实现高效计算与存储。
(4)知识蒸馏(Knowledge Distillation):
知识蒸馏,高效模型压缩技术,将大型模型智慧注入小型模型。通过以大型模型软标签为训练目标,结合温度参数优化概率分布,实现知识传承与压缩,精简模型结构,提升计算效率。
网络结构搜索,自动化探寻适配特定任务的神经网络架构。精准搜索与优化,打造轻量化、高效模型,轻松应对各种资源限制与性能挑战。
(6)动态模型调整(Dynamic Model Adaptation):
动态模型调整,精准响应环境与数据变化。它依据设备资源和实时数据特性,灵活调整模型结构与参数,实现高效计算与精准预测,确保模型性能与资源利用达到最佳平衡。
这些优化和压缩技术可大幅减少模型存储和计算开销,同时保持高性能与精度,实现资源受限环境下的高效部署与应用。
3、大型模型在特定任务上的调参策略和实验技巧
针对大型模型在特定任务上的调参策略和实验技巧
(1)选择适当的预训练模型:
启动任务前,精选预训练模型作为基石。评估模型时,考虑其领域性能、规模及训练数据集相似度,确保模型适配,助力高效推进。
(2)冻结部分层进行微调:
大型预训练模型可通过冻结底层或中间层参数,仅微调顶层或新层,以精简训练参数,加速训练过程,并有效减少过拟合风险,提升模型性能。
(3)选择合适的损失函数和评估指标:
精确匹配任务特性,选择合适的损失函数与评估指标至关重要。分类任务优选交叉熵损失,回归任务则选均方误差损失。评估指标涵盖准确率、精确度、召回率及F1分数,依据任务需求精准定制。
(4)采用学习率调度策略:
采用精准的学习率调度策略能显著提升模型收敛速度与性能。策略如学习率衰减、余弦退火、指数衰减等,经实验验证,动态调整学习率对模型优化更为有利。
(5)利用数据增强和正则化技术:
数据增强与正则化技术显著提升模型泛化及抗干扰能力。通过随机裁剪、旋转、翻转等数据增强方法扩充训练数据,结合Dropout、批量归一化等正则化技术,有效降低过拟合风险,提升模型性能。
(6)使用交叉验证:
交叉验证在模型调参中至关重要,它减少了对单一验证集的依赖,确保评估更精准、更稳定。此过程能精准确定最佳超参数设置,如学习率、批量大小和正则化参数,显著提升模型性能。
(7)持续监控和调整:
在模型训练中,我们实时跟踪性能与指标变化,精准调整超参数与训练策略。经多次迭代实验,模型性能得以显著提升。
四、应用场景AI大模型在实际应用中尽显威力,覆盖自然语言处理、计算机视觉、医疗健康等多元领域。深入了解其应用场景,有助于我们洞察其在解决现实挑战中的核心作用与深远意义。
1、AI大模型在不同领域的应用案例
AI大模型在不同领域的应用案例非常丰富,以下是一些典型的例子:
(1)自然语言处理(NLP):
AI大模型如BERT、GPT等卓越执行语言理解任务,涵盖情感分析、命名实体识别、文本分类等,功能强大且全面。
语言生成:利用AI大模型生成文本,如基于GPT的文章生成、对话系统等。
(2)计算机视觉(Computer Vision):
利用GAN与VAE等AI大模型,实现图像超分辨率、风格迁移等高效生成任务,创新技术驱动图像创作新纪元。
(3)自动驾驶与智能交通:
自动驾驶:AI大模型精准处理传感器数据,实现环境感知、路径规划、行为预测,深度学习赋能,引领自动驾驶新纪元。
智能交通管理凭借AI大模型精准分析交通数据,预测交通流,高效管理拥堵,特别运用RNN模型,实现精准交通流预测。
(4)医疗与生物信息学:
(5)金融与风控:
(6)教育与辅助学习:
智能辅导:利用AI大模型进行学习过程监控和辅导,如使用聊天机器人进行答疑解惑。
2、AI大模型在应用中的优势和局限性
AI大模型在应用中具有许多优势,同时也存在一些局限性。以下是它们的一些主要特点:
(1)优势:
强大的表征能力:
泛化能力强:
多模态融合:
自动化特征提取:
持续迭代和优化:
(2)局限性:
计算和存储资源需求大:
可解释性差:
数据隐私和安全风险:
过拟合和泛化能力不足:
AI大模型在小样本场景下易过拟合,泛化力受限。针对此问题,需进行精准调优与策略性改进,确保模型性能卓越。
环境依赖性:
AI大模型虽在各领域大放异彩,但实际应用仍需权衡其优势与局限,精准施策、持续优化,方能达到更佳效能与表现。
3、AI大模型在未来的发展趋势和可能的应用场景
未来AI大模型的发展趋势将会朝着以下几个方向发展:
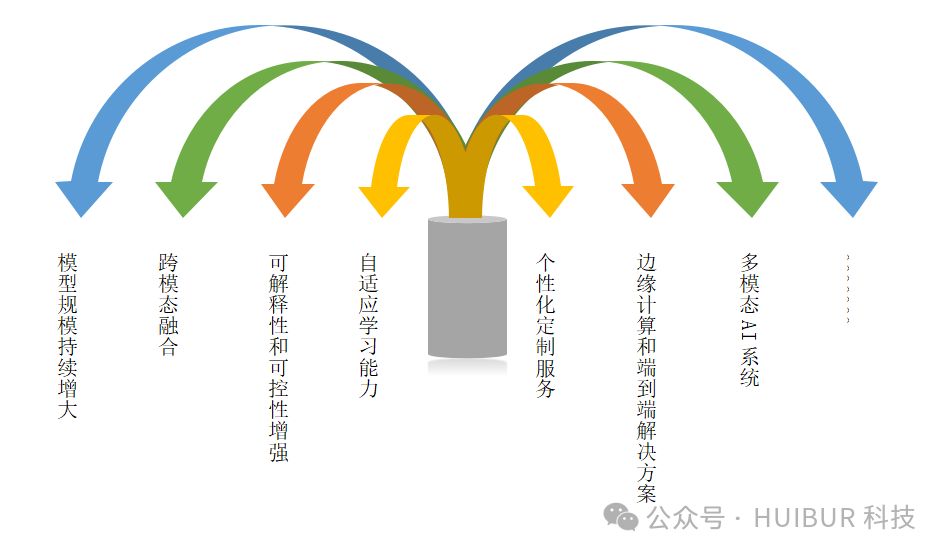
模型规模持续增大:
AI大模型规模将随硬件技术提升与数据量增长而持续扩大,预计将出现更大规模、参数更丰富的模型,以强化性能和泛化能力。
跨模态融合:
未来AI大模型将强化跨模态数据融合,整合文本、图像、语音等多元数据,构建更先进、应用更广泛的联合模型,解锁更多复杂场景下的智能应用。
可解释性和可控性增强:
针对AI大模型可解释性与可控性挑战,未来将强化模型内部结构与决策过程的解读,以增强其可解释性和可控性,满足高解释性需求的应用场景,实现模型透明化与精准控制。
自适应学习能力:
AI大模型未来将拥有卓越的自适应学习能力,自动调整结构和参数,实现环境和任务变化的精准应对,持续迭代优化。
个性化定制服务:
AI大模型将强化个性化定制,精准捕捉用户特征与偏好,提供定制化服务与精准建议,满足日益增长的个性化需求。
边缘计算和端到端解决方案:
AI大模型将借助边缘计算和物联网技术,实现边缘设备的高效部署与应用,打造全链条智能解决方案,引领未来智能新纪元。
多模态AI系统:
未来AI大模型将强化多模态数据处理,实现信息跨模态融合与互动,打造更丰富、更复杂的应用场景,引领智能化新潮流。
AI大模型未来将在医疗健康、智能交通、智能制造、教育、金融等领域大放异彩。然而,也需直面数据隐私保护、可解释性和普适性等挑战,持续探索创新,以确保技术的健康发展。
五、结论与展望本文探讨了AI大模型的理论、技术和应用,总结如下:
1、主要观点和结论:
在训练大型模型方面,分布式训练、混合精度训练、模型并行等技术方法可以提高效率。
2、未来研究和发展方向的建议:
3、对AI大模型技术的未来发展进行展望和预测:
AI大模型将更加注重在边缘计算和物联网领域的应用,实现智能物联网和智能边缘设备。
AI大模型,引领人工智能新纪元,理论基础深厚,技术方法先进,广泛应用于各领域。其潜力巨大,发展空间无限。然而,挑战与局限性并存,仍需我们不断探索与完善,以释放其更大价值。
在AI大模型的未来发展中,我们需深化理论研究,创新技术,提升模型性能与效率。同时,拓宽其应用场景,实现跨领域融合,推动人工智能技术的全面进步。需集合学术界、产业界与政府部门之力,共谋AI大模型技术的繁荣,为人类社会带来更大贡献,共同迈向更加智能的未来。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-