前言: 在Spring Boot框架下,可以使用以下方法来去重40亿个QQ号.请注意:QQ号码的理论最大值为 2 32 − 1 2^{32} - 1 232−1,大概是43亿左右。
文章目录
- 提前总结(总分总~~~)
- 最粗鲁的方式
- 1. 使用HashSet去重:
- 2. 使用Java 8的Stream去重:
- 3. 使用数据库的去重功能:
- 限制1GB内存,文件的方式
- 4. 文件分片
- 5. 外部排序算法
- 使用中间件 redis
- 6. bitmap
- 7. 布隆过滤器
- 分析一下布隆过滤器以及bitmap存储40亿个QQ号需要的内存
- 布隆过滤器:
- 位图(Bitmap):
- 总结
- 1. 使用 HashSet 去重:
- 2. 使用 Java 8 的 Stream 去重:
- 3. 使用数据库的去重功能:
- 4. 文件分片:
- 5. 外部排序算法:
- 6. 位图(Bitmap):
- 7. 布隆过滤器:
提前总结(总分总~~~)
- 如果限制在1GB内存,并且不依赖外部存储或中间件,
HashSet、Java 8 Stream都无法满足要求。 - 文件分片和外部排序算法可以适应1GB内存限制,但涉及到额外的文件操作和排序步骤。
- 使用数据库的去重功能可能需要额外的存储开销。
- Redis作为中间件可以满足内存限制,但需要依赖Redis服务。
- 布隆过滤器是一种适用于大规模数据去重的高效数据结构,可以根据预期插入数量和误判率进行内存估算。
最粗鲁的方式
1. 使用HashSet去重:
Set<String> qqSet = new HashSet<>();
// 假设qqList是包含40亿个QQ号的列表
for (String qq : qqList) {qqSet.add(qq);
}
List<String> distinctQQList = new ArrayList<>(qqSet);
2. 使用Java 8的Stream去重:
List<String> distinctQQList = qqList.stream().distinct().collect(Collectors.toList());
3. 使用数据库的去重功能:
- 首先,创建一个数据库表来存储QQ号,可以使用MySQL或其他关系型数据库。
- 将40亿个QQ号逐个插入数据库表中,数据库会自动去重。
- 最后,从数据库中读取去重后的QQ号列表:
// 假设使用Spring Data JPA进行数据库操作
@Repository
public interface QQRepository extends JpaRepository<QQEntity, Long> {List<QQEntity> findAll();
}// 在业务逻辑中使用QQRepository获取去重后的QQ号列表
List<QQEntity> distinctQQList = qqRepository.findAll();限制1GB内存,文件的方式
4. 文件分片
- 将40亿个QQ号分成多个较小的分段,每个分段可以包含一定数量的QQ号。
- 针对每个分段,使用HashSet进行去重,但是只在内存中保留部分分段的去重结果,而不是全部。
- 将每个分段的去重结果写入磁盘文件,以释放内存空间。
- 对下一个分段进行去重操作,重复上述步骤,直到处理完所有分段。
- 最后,将所有磁盘文件中的去重结果合并成最终的去重结果。
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.*;public class QQDuplicateRemover {private static final int MAX_MEMORY_USAGE_MB = 1024; // 最大内存使用限制,单位:MBprivate static final int MAX_SEGMENT_SIZE = 1000000; // 每个分段的最大数量public static void main(String[] args) {// 假设qqList是包含40亿个QQ号的列表List<String> qqList = loadQQList();// 分段处理int segmentCount = (int) Math.ceil((double) qqList.size() / MAX_SEGMENT_SIZE);List<File> segmentFiles = new ArrayList<>();for (int i = 0; i < segmentCount; i++) {List<String> segment = qqList.subList(i * MAX_SEGMENT_SIZE, Math.min((i + 1) * MAX_SEGMENT_SIZE, qqList.size()));Set<String> segmentSet = new HashSet<>(segment);segment.clear(); // 释放内存File segmentFile = writeSegmentToFile(segmentSet);segmentFiles.add(segmentFile);segmentSet.clear();}// 合并去重结果List<String> distinctQQList = mergeSegments(segmentFiles);// 输出去重后的QQ号列表for (String qq : distinctQQList) {System.out.println(qq);}}// 加载40亿个QQ号列表的示例方法private static List<String> loadQQList() {// TODO: 实现加载40亿个QQ号列表的逻辑,返回List<String>return new ArrayList<>();}// 将分段的去重结果写入磁盘文件private static File writeSegmentToFile(Set<String> segmentSet) {File segmentFile;BufferedWriter writer = null;try {segmentFile = File.createTempFile("qq_segment_", ".txt");writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(segmentFile), StandardCharsets.UTF_8));for (String qq : segmentSet) {writer.write(qq);writer.newLine();}} catch (IOException e) {throw new RuntimeException("Failed to write segment to file.", e);} finally {if (writer != null) {try {writer.close();} catch (IOException e) {e.printStackTrace();}}}return segmentFile;}// 合并分段文件并去重private static List<String> mergeSegments(List<File> segmentFiles) {List<String> distinctQQList = new ArrayList<>();PriorityQueue<BufferedReader> fileReaders = new PriorityQueue<>(Comparator.comparing(QQDuplicateRemover::readNextLine));for (File segmentFile : segmentFiles) {try {BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(segmentFile), StandardCharsets.UTF_8));String line = reader.readLine();if (line != null) {fileReaders.offer(reader);}} catch (IOException e) {throw new RuntimeException("Failed to read segment file: " + segmentFile.getName(), e);}}String currentQQ = null;while (!fileReaders.isEmpty()) {BufferedReader reader = fileReaders.poll();String qq = readNextLine(reader);if (!qq.equals(currentQQ)) {distinctQQList.add(qq);currentQQ = qq;}String nextQQ = readNextLine(reader);if (nextQQ != null) {fileReaders.offer(reader);} else {try {reader.close();} catch (IOException e) {e.printStackTrace();}}}return distinctQQList;}// 读取下一行数据private static String readNextLine(BufferedReader reader) {try {return reader.readLine();} catch (IOException e) {throw new RuntimeException("Failed to read line from segment file.", e);}}
}
这个示例代码中,使用了分段处理的思路。首先,将40亿个QQ号划分为较小的分段,并使用HashSet进行去重。然后,将每个分段的去重结果写入临时文件,以释放内存。最后,合并所有分段文件并去重,得到最终的去重结果。
请注意,示例代码中的loadQQList()方法是一个占位方法,需要根据实际情况实现另外,这个示例代码中使用了临时文件来存储分段的去重结果。在实际应用中,你可能需要根据需求进行适当的修改,例如指定输出文件路径、处理异常情况等。此外,由于内存限制为1GB,你可能需要根据实际情况调整MAX_SEGMENT_SIZE的大小,以确保每个分段在内存中的大小不超过限制。
这只是一个基本的示例代码,供你参考和理解分段处理的思路。根据实际需求和具体情况,你可能需要进行更多的优化和改进。
5. 外部排序算法
- 将40亿个QQ号划分为多个小文件,每个文件包含一部分QQ号。
- 对每个小文件进行内部排序,可以使用归并排序等算法。
- 合并排序后的小文件,使用归并排序的思想,逐步合并文件,同时去除重复的QQ号。
- 最终得到去重后的结果。
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.*;public class QQDuplicateRemover {private static final int MAX_MEMORY_USAGE_MB = 1024; // 最大内存使用限制,单位:MBprivate static final int MAX_SEGMENT_SIZE = 1000000; // 每个分段的最大数量public static void main(String[] args) {// 假设qqList是包含40亿个QQ号的列表List<String> qqList = loadQQList();// 外部排序去重List<File> sortedSegmentFiles = externalSort(qqList);// 合并去重结果List<String> distinctQQList = mergeSortedSegments(sortedSegmentFiles);// 输出去重后的QQ号列表for (String qq : distinctQQList) {System.out.println(qq);}}// 加载40亿个QQ号列表的示例方法private static List<String> loadQQList() {// TODO: 实现加载40亿个QQ号列表的逻辑,返回List<String>return new ArrayList<>();}// 外部排序算法private static List<File> externalSort(List<String> qqList) {List<File> segmentFiles = new ArrayList<>();int segmentCount = (int) Math.ceil((double) qqList.size() / MAX_SEGMENT_SIZE);// 将数据分段并排序for (int i = 0; i < segmentCount; i++) {List<String> segment = qqList.subList(i * MAX_SEGMENT_SIZE, Math.min((i + 1) * MAX_SEGMENT_SIZE, qqList.size()));Collections.sort(segment);File segmentFile = writeSegmentToFile(segment);segmentFiles.add(segmentFile);}// 逐步合并排序后的分段文件while (segmentFiles.size() > 1) {List<File> mergedSegmentFiles = new ArrayList<>();for (int i = 0; i < segmentFiles.size(); i += 2) {File segmentFile1 = segmentFiles.get(i);File segmentFile2 = (i + 1 < segmentFiles.size()) ? segmentFiles.get(i + 1) : null;File mergedSegmentFile = mergeSegments(segmentFile1, segmentFile2);mergedSegmentFiles.add(mergedSegmentFile);}segmentFiles = mergedSegmentFiles;}return segmentFiles;}// 将分段数据写入临时文件private static File writeSegmentToFile(List<String> segment) {File segmentFile;BufferedWriter writer = null;try {segmentFile = File.createTempFile("qq_segment_", ".txt");writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(segmentFile), StandardCharsets.UTF_8));for (String qq : segment) {writer.write(qq);writer.newLine();}} catch (IOException e) {throw new RuntimeException("Failed to write segment to file.", e);} finally {if (writer != null) {try {writer.close();} catch (IOException e) {e.printStackTrace();}}}return segmentFile;}// 合并两个分段文件private static File mergeSegments(File segmentFile1, File segmentFile2) {BufferedReader reader1 = null;BufferedReader reader2 = null;BufferedWriter writer = null;File mergedSegmentFile;try {mergedSegmentFile = File.createTempFile("qq_segment_", ".txt");reader1 = new BufferedReader(new InputStreamReader(new FileInputStream(segmentFile1), StandardCharsets.UTF_8));reader2 = new BufferedReader(new InputStreamReader(new FileInputStream(segmentFile2), StandardCharsets.UTF_8));writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(mergedSegmentFile), StandardCharsets.UTF_8));String qq1 = reader1.readLine();String qq2 = reader2.readLine();while (qq1 != null && qq2 != null) {if (qq1.compareTo(qq2) < 0) {writer.write(qq1);writer.newLine();qq1 = reader1.readLine();} else if (qq1.compareTo(qq2) > 0) {writer.write(qq2);writer.newLine();qq2 = reader2.readLine();} else {writer.write(qq1);writer.newLine();qq1 = reader1.readLine();qq2 = reader2.readLine();}}// 处理文件剩余的数据while (qq1 != null) {writer.write(qq1);writer.newLine();qq1 = reader1.readLine();}while (qq2 != null) {writer.write(qq2);writer.newLine();qq2 = reader2.readLine();}} catch (IOException e) {throw new RuntimeException("Failed to merge segment files.", e);} finally {try {if (reader1 != null) {reader1.close();}if (reader2 != null) {reader2.close();}if (writer != null) {writer.close();}} catch (IOException e) {e.printStackTrace();}}return mergedSegmentFile;}// 合并排序后的分段文件并去重private static List<String> mergeSortedSegments(List<File> segmentFiles) {List<String> distinctQQList = new ArrayList<>();PriorityQueue<BufferedReader> fileReaders = new PriorityQueue<>(Comparator.comparing(QQDuplicateRemover::readNextLine));for (File segmentFile : segmentFiles) {try {BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(segmentFile), StandardCharsets.UTF_8));String line = reader.readLine();if (line != null) {fileReaders.offer(reader);}} catch (IOException e) {throw new RuntimeException("Failed to read segment file: " + segmentFile.getName(), e);}}String currentQQ = null;while (!fileReaders.isEmpty()) {BufferedReader reader = fileReaders.poll();String qq = readNextLine(reader);if (!qq.equals(currentQQ)) {distinctQQList.add(qq);currentQQ = qq;}String nextQQ = readNextLine(reader);if (nextQQ != null) {fileReaders.offer(reader);} else {try {reader.close();} catch (IOException e) {e.printStackTrace();}}}return distinctQQList;}// 读取下一行数据private static String readNextLine(BufferedReader reader) {try {return reader.readLine();} catch (IOException e) {throw new RuntimeException("Failed to read line from segment file.", e);}}
}这个示例代码中使用了外部排序算法来处理40亿个QQ号的去重问题。首先,将数据分段,并在内存中对每个分段进行排序。然后,逐步合并排序后的分段文件,直到只剩下一个文件为止。最后,对合并后的分段文件进行去重操作,得到最终的去重结果。
请注意,示例代码中的loadQQList()方法是一个占位方法,需要根据实际情况实现另外,这个示例代码中使用了临时文件来存储分段和合并后的结果。在实际应用中,你可能需要根据需求进行适当的修改,例如指定输出文件路径、处理异常情况等。此外,由于内存限制为1GB,你可能需要根据实际情况调整MAX_SEGMENT_SIZE的大小,以确保每个分段在内存中的大小不超过限制。
这只是一个基本的示例代码,供你参考和理解外部排序算法的实现。根据实际需求和具体情况,你可能需要进行更多的优化和改进。
使用中间件 redis
6. bitmap
Redis位图(Bitmap)是一种特殊的数据结构,用于处理位级别的操作。你可以借助Redis位图来解决去重问题,包括处理大规模数据的去重。
以下是使用Redis位图解决去重问题的一般步骤:
-
将需要去重的数据转换为唯一标识,例如将QQ号转换为对应的整数或字符串。
-
使用Redis的位图数据结构,创建一个位图键(Key)用于存储去重标记。你可以使用Redis的SETBIT命令将位图中的特定位设置为1,表示该标识已经存在。
-
遍历数据集,对于每个唯一标识,使用SETBIT命令设置位图中对应的位。如果该位已经被设置为1,表示标识已经存在,可以进行相应的处理(例如丢弃或记录重复数据)。
-
完成遍历后,可以使用位图的其他命令(如BITCOUNT)获取去重后的数量,或者使用GETBIT命令检查特定位是否被设置,以判断某个标识是否存在。
下面是一个使用Redis位图进行去重的示例代码(使用Java Redis客户端Jedis):
import redis.clients.jedis.Jedis;public class RedisBitmapDuplicateRemover {private static final String BITMAP_KEY = "duplicate_bitmap";public static void main(String[] args) {// 假设qqList是包含40亿个QQ号的列表List<String> qqList = loadQQList();// 初始化Redis连接Jedis jedis = new Jedis("localhost");// 去重计数器int duplicateCount = 0;// 遍历qqList进行去重for (String qq : qqList) {long bit = Long.parseLong(qq); // 假设QQ号被转换为长整型// 检查位图中的对应位是否已经被设置boolean isDuplicate = jedis.getbit(BITMAP_KEY, bit);if (isDuplicate) {// 处理重复数据duplicateCount++;} else {// 设置位图中的对应位为1,表示标识已经存在jedis.setbit(BITMAP_KEY, bit, true);// 处理非重复数据}}// 获取去重后的数量long distinctCount = jedis.bitcount(BITMAP_KEY);System.out.println("Duplicate count: " + duplicateCount);System.out.println("Distinct count: " + distinctCount);// 关闭Redis连接jedis.close();}// 加载40亿个QQ号列表的示例方法private static List<String> loadQQList() {// TODO: 实现加载40亿个QQ号列表的逻辑,返回List<String>return new ArrayList<>();}
}在这个示例中,我们首先将QQ号转换为长整型,并使用Redis位图存储去重标记。然后遍历QQ号列表,对于每个QQ号,我们使用GETBIT命令检查位图中对应的位是否已经被设置。如果已经被设置,表示该QQ号重复,我们可以进行相应的处理。如果位图中对应的位未被设置,表示该QQ号是首次出现,我们使用SETBIT命令将位图中对应的位设置为1,表示标识已经存在。
最后,我们使用BITCOUNT命令获取位图中被设置为1的位的数量,即去重后的数量。同时,我们还可以使用其他位图命令来进行更多的操作,例如使用GETBIT命令检查特定位是否被设置。
请注意,示例代码中的loadQQList()方法仍然是一个占位方法,需要根据实际情况实现。此外,你需要确保已经安装了Redis并正确配置了Redis连接。
总结而言,借助Redis位图,你可以高效地解决大规模数据的去重问题。
7. 布隆过滤器
使用布隆过滤器(Bloom Filter)可以高效地进行快速查找和去重操作,而无需存储实际的数据。以下是使用布隆过滤器实现去重的一般步骤:
初始化布隆过滤器:确定布隆过滤器的大小(比特位数)和哈希函数的数量。
将需要去重的数据转换为唯一标识,例如将QQ号转换为对应的整数或字符串。
对每个唯一标识,使用多个不同的哈希函数进行哈希计算,得到多个哈希值。
将得到的多个哈希值对应的位设置为1,表示该标识已经存在。
当需要判断某个标识是否存在时,对该标识使用相同的哈希函数进行哈希计算,并检查对应的位是否都为1。如果有任何一个位为0,则标识不存在;如果所有位都为1,则标识可能存在(存在一定的误判率)。
下面是一个使用布隆过滤器实现去重的示例代码(使用Java Bloom Filter库 Guava):
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;public class BloomFilterDuplicateRemover {private static final int EXPECTED_INSERTIONS = 1000000; // 预期插入数量private static final double FPP = 0.01; // 期望误判率public static void main(String[] args) {// 初始化布隆过滤器BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(), EXPECTED_INSERTIONS, FPP);// 假设qqList是包含大量QQ号的列表List<String> qqList = loadQQList();// 去重计数器int duplicateCount = 0;// 遍历qqList进行去重for (String qq : qqList) {if (bloomFilter.mightContain(qq)) {// 处理重复数据duplicateCount++;} else {bloomFilter.put(qq);// 处理非重复数据}}// 获取去重后的数量long distinctCount = qqList.size() - duplicateCount;System.out.println("Duplicate count: " + duplicateCount);System.out.println("Distinct count: " + distinctCount);}// 加载大量QQ号列表的示例方法private static List<String> loadQQList() {// TODO: 实现加载大量QQ号列表的逻辑,返回List<String>return new ArrayList<>();}
}
在这个示例中,我们使用Guava库中的Bloom Filter实现去重功能。首先,我们初始化布隆过滤器 bloomFilter,指定预期插入数量和期望误判率。然后,遍历QQ号列表 qqList,对于每个QQ号,我们首先使用 mightContain() 方法判断该QQ号是否可能已经存在于布隆过滤器中。如果返回 true,表示该QQ号可能已经存在,我们可以进行相应的处理。如果返回 false,表示该QQ号很可能不存在,我们使用 put() 方法将其插入布隆过滤器中,并进行相应的处理。
最后,我们可以通过计算重复数据的数量,以及使用列表总数量减去重复数量,得到去重后的数量。
请注意,示例代码中的 loadQQList() 方法仍然是一个占位方法,需要根据实际情况实现。此外,你需要确保已经引入了Guava库并正确配置了依赖项。
总结而言,布隆过滤器是一种高效的去重数据结构,适用于大规模数据的去重操作。然而,布隆过滤器存在一定的误判率,因此在需要高精确度的场景下,可能需要额外的校验手段来确认数据的存在与否。
分析一下布隆过滤器以及bitmap存储40亿个QQ号需要的内存
布隆过滤器和位图(Bitmap)都是常见的数据结构,用于高效地存储和查询大量数据。下面我会分析一下布隆过滤器和位图存储40亿个QQ号所需的内存。
布隆过滤器:
要估算布隆过滤器需要的具体内存量,需要考虑以下几个因素:
-
期望的插入数量(Expected Insertions):这是指预计会插入到布隆过滤器中的元素数量。
-
期望的误判率(False Positive Probability):这是指布隆过滤器允许的判断错误的概率,也就是将一个不存在的元素误判为存在的概率。
-
哈希函数的数量(Hash Functions Count):布隆过滤器使用多个哈希函数来将输入元素映射到位数组中的多个位置,这有助于减小误判率。
布隆过滤器的内存占用可以通过以下公式近似计算:
M = − ( N ∗ l n ( p ) ) / ( l n ( 2 ) 2 ) M = -(N * ln(p)) / (ln(2)^2) M=−(N∗ln(p))/(ln(2)2)
其中,M 是所需的比特位数(内存占用),N 是预期插入数量,p 是期望误判率。
请注意,该公式仅提供了一个近似值,并且假设哈希函数的输出是均匀分布的。实际上,布隆过滤器的性能和内存占用与哈希函数的选择、哈希函数之间的相互独立性等因素也有关系。
例如,假设我们希望将40亿个QQ号存储在布隆过滤器中,并且期望误判率为0.01%(0.0001),我们可以将这些值代入公式进行估算:
M = ( 40 亿 ∗ l n ( 0.0001 ) ) / ( l n ( 2 ) 2 ) M = (40亿 * ln(0.0001)) / (ln(2)^2) M=(40亿∗ln(0.0001))/(ln(2)2)
B y t e s = c e i l ( M / 8 ) Bytes = ceil(M / 8) Bytes=ceil(M/8)
根据计算结果,布隆过滤器大约需要占用约 596.05MB 的内存。
需要注意的是,这只是一个估算值,实际的内存占用可能会有所偏差。同时,为了避免误判率过高,可能需要使用更多的哈希函数,从而增加内存占用。
因此,具体的内存占用量还需根据实际需求和误判率要求进行调整和测试。
位图(Bitmap):
位图的内存分析源于腾讯三面:40 亿个 QQ 号码如何去重?
位图是一种使用比特位来表示数据存在与否的数据结构。对于40亿个QQ号,每个QQ号可以用一个唯一的整数或哈希值来表示。
如果我们使用32位整数来表示每个QQ号,那么每个整数需要占用32个比特位。因此,存储40亿个QQ号所需的内存为:
来看绝招!我们可以对hashmap进行优化,采用bitmap这种数据结构,可以顺利地同时解决时间问题和空间问题。
在很多实际项目中,bitmap经常用到。我看了不少组件的源码,发现很多地方都有bitmap实现,bitmap图解如下:
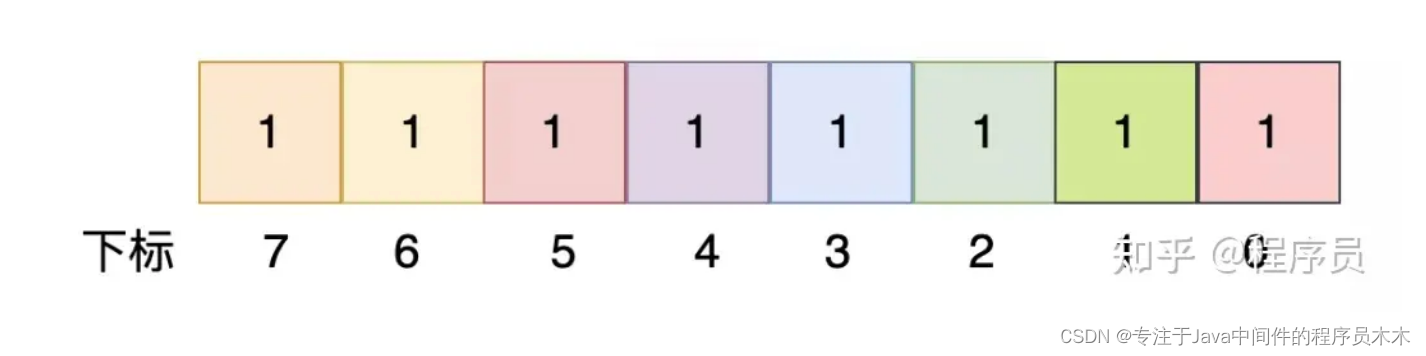
这是一个unsigned char类型,可以看到,共有8位,取值范围是[0, 255],如上这个unsigned char的值是255,它能标识0~7这些数字都存在。
同理,如下这个unsigned char类型的值是254,它对应的含义是:1~7这些数字存在,而数字0不存在:
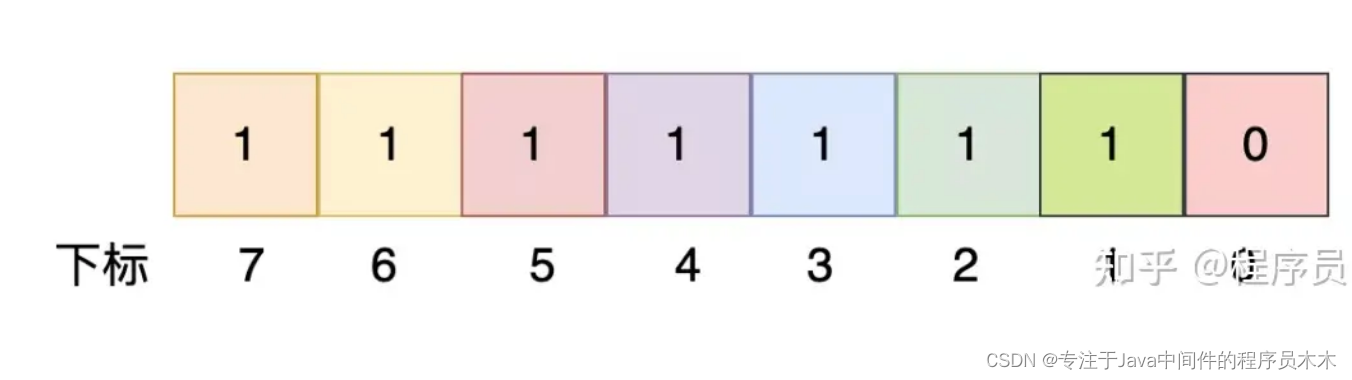
由此可见,一个unsigned char类型的数据,可以标识0~7这8个整数的存在与否。以此类推:
一个unsigned int类型数据可以标识0~31这32个整数的存在与否。
两个unsigned int类型数据可以标识0~63这64个整数的存在与否。
显然,可以推导出来:512MB大小足够标识所有QQ号码的存在与否,请注意:QQ号码的理论最大值为2^32 - 1,大概是43亿左右。
接下来的问题就很简单了:用512MB的unsigned int数组来记录文件中QQ号码的存在与否,形成一个bitmap,比如:
bitmapFlag[123] = 1
bitmapFlag[567] = 1
bitmapFlag[123] = 1
bitmapFlag[890] = 1
实际上就是:
bitmapFlag[123] = 1
bitmapFlag[567] = 1
bitmapFlag[890] = 1然后从小到大遍历所有正整数(4字节),当bitmapFlag值为1时,就表明该数是存在的。
总结
1. 使用 HashSet 去重:
这是一种简单粗暴的方法,使用内置的哈希集合数据结构。
需要将40亿个QQ号全部加载到内存中,因此可能会超出1GB的内存限制。
优点是实现简单,查询性能较好,但内存占用较高。
2. 使用 Java 8 的 Stream 去重:
利用 Java 8 的流操作特性,通过 distinct() 方法去重。
同样需要将40亿个QQ号全部加载到内存中,可能会超出1GB的内存限制。
优点是简单易用,但内存占用较高。
3. 使用数据库的去重功能:
利用数据库的去重功能,将QQ号作为唯一索引或使用 DISTINCT 关键字进行查询。
需要将数据存储在数据库中,可能需要额外的存储开销。
优点是适用于大规模数据,但需要依赖数据库系统。
4. 文件分片:
将数据进行分片存储,每个文件存储部分QQ号,然后逐个文件进行去重。
可以通过逐个读取文件并使用 HashSet 进行去重,最后合并结果。
可以适应1GB内存限制,但需要额外的文件操作和合并步骤。
5. 外部排序算法:
使用外部排序算法,将数据划分为多个部分,在排序过程中进行去重。
可以适应1GB内存限制,但需要额外的排序和合并步骤。
6. 位图(Bitmap):
使用位图存储40亿个QQ号,每个QQ号使用一个比特位表示存在与否。
需要大约512MB的内存来存储40亿个QQ号。
7. 布隆过滤器:
使用布隆过滤器存储40亿个QQ号,以较小的内存(596.05MB )占用来实现去重功能。
布隆过滤器的具体内存占用取决于预期插入数量和期望误判率,可以根据公式进行估算。