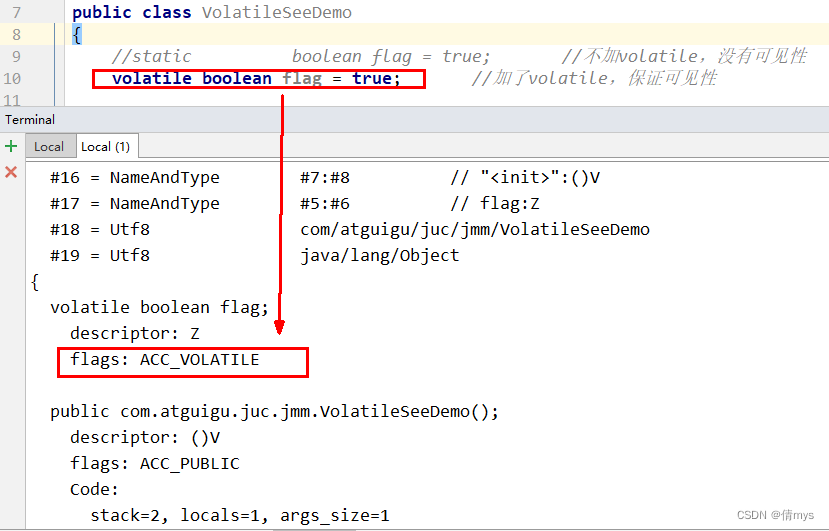
文章目录
- 一、书籍推荐
- 二、完整代码
- 三、效果
一、书籍推荐
推荐本人书籍《Python网络爬虫入门到实战》 ,详细介绍见👉: 《Python网络爬虫入门到实战》 书籍介绍
二、完整代码
import os
import requests
from bs4 import BeautifulSoup# 定义保存图片的文件夹
SAVE_PATH = 'photo'# 确保保存图片的文件夹存在
if not os.path.exists(SAVE_PATH):os.makedirs(SAVE_PATH)def get_html(url):"""发送网络请求,获取网页内容"""try:response = requests.get(url)response.raise_for_status()return response.textexcept requests.RequestException as e:print(f"请求网页失败:{e}")return Nonedef download_image(image_url, image_name):"""下载并保存图片"""try: