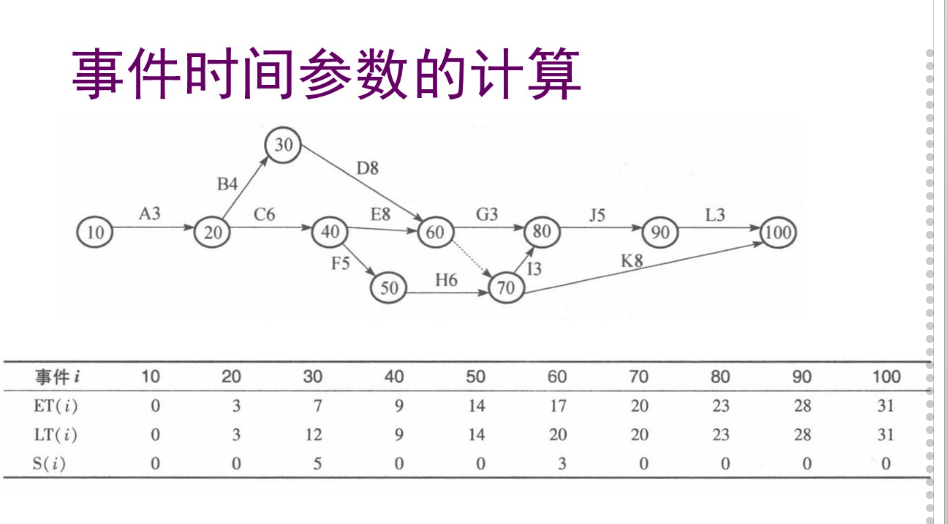
在当今数据驱动的决策过程中,因果推断和增益模型扮演了至关重要的角色。因果推断帮助我们理解不同变量间的因果关系,而增益模型则专注于评估干预措施对个体的影响,从而优化策略和行动。然而,要提高这些模型的精确度和适应性,引入元学习器成为了一个创新的解决方案。元学习器通过将估计任务分解并应用不同的机器学习技术,能够有效增强模型的表现。接下来,我们将详细探讨如何利用元学习优化增益模型的性能,特别是通过S-Learner、T-Learner和X-Learner这几种估计器。

因果推断
因果推断是理解干预、处理与其结果之间的因果关系的基本概念。它在统计学、流行病学、经济学等领域中有所应用。
HTE(异质性处理效应)模型是一种强大的工具,可用于理解实验干预对不同人群的不同影响。它通过人群定向提供了一种个性化的干预方式,最大程度地提高了实验的影响力。超越了传统的因果推断方法,后者通常估计整个人群的平均处理效应(ATE)。而HTE关注干预或处理如何影响特定个体或人群段,承认他们的独特特性。
增益模型
增益模型(uplift model):估算干预增量(uplift),即**干预动作(treatment)对用户响应行为(outcome)**产生的效果。
这是一个因果推断(Causal Inference) 课题下估算ITE(Individual Treatment Effect)的问题——估算同一个体在干预与不干预(互斥情况下)不同outcome的差异。为了克服这一反事实的现状,增益模型强依赖于随机实验(将用户随机分配到实验组&对照组)的结果数据。
可以说增益模型位于因果推断和机器学习的交叉点,为理解个体对干预的响应提供了强大的方法。
因果推断与增益模型的关系
虽然这两种方法的应用场景和目标有所不同,但它们都寻求评估某种干预的效果。因果推断提供了一种框架和方法来理解和估计一个变量对另一个变量的影响,而增益模型则是这一框架下的一个应用,专注于个体层面的干预效果。增益模型在设计时会使用因果推断的方法来确保其预测的准确性和可靠性,尤其是在处理非实验数据时处理潜在的偏见。
因果推断提供了理解和证明因果关系的方法,而增益模型则利用这些方法来优化决策和策略,尤其是在面对大规模客户群体时。
Meta-learner
Meta-learner(元学习器)通过减少数据需求和增强适应性来改善提升模型,是一种模型不可知的算法,用于使用任何机器学习方法估计平均处理效应 (CATE) 。
元学习器将估计 CATE 的任务分解成可以使用任何回归或监督机器学习算法解决的较小的预测任务,这些算法称为基础学习器。
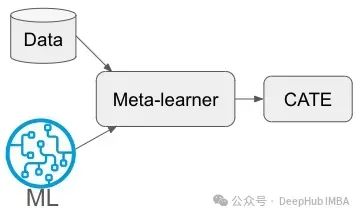
这些基础学习器可以是机器学习的任何算法,如XGBoost、回归、决策树或神经网络。
S-Learner(单一估计器)
S-Learner使用单一监督学习算法,例如回归树、随机森林或 XGBoost,来估计提升建模的 CATE 的单一估计器。
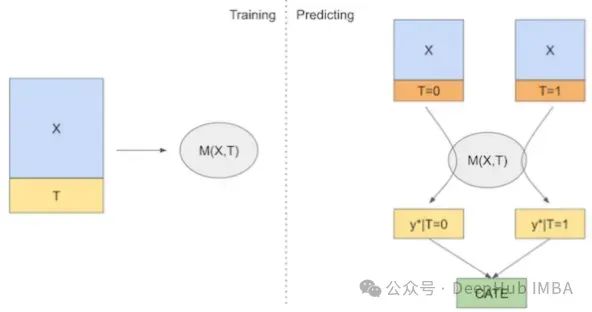
S-Learner将干预变量(T)与其他特征(X)结合在一起,训练单个机器学习模型(M)。该模型预测不同干预方案(控制T=0,干预T=1)下的结果(Y)。估计CATE然后被计算为干预方案和控制方案预测之间的差异。
S-Learner使用单一机器学习模型,易于理解和实施,可以处理连续和离散的干预变量 S-学习者不给变量分配任何特殊角色,将其视为任何其他特征。如果干预变量不是结果的强预测因子,那么S-Learner将倾向于估计零干预效应,低估干预的真实影响。
使用Causalml实现S-Learner
下面的代码片段使用S-Learner实现提升建模。它将基础学习器XGBRegressor封装为单个机器学习算法。
#control_name=0 specifies the control group in the treatment variables_learner = BaseSRegressor(XGBRegressor(), control_name=0)# Split the data into training and test setsX_train, X_test, y_train, y_test, treatment_train, treatment_test = train_test_split(df[x_names], df['converted'], df['em1'], test_size=0.2, random_state=42)# Train the models_learner.fit(X=X_train, treatment=treatment_train, y=y_train)# Predict the treatment effect on the test datas_cate_estimates = s_learner.predict(X=X_test)# Create a DataFrame for easier manipulationpred_data = pd.DataFrame({'outcome': np.ravel(y_test),'treatment': np.ravel(treatment_test),'predicted_effect': np.ravel(s_cate_estimates)})plot_gain(pred_data, outcome_col="outcome", treatment_col="treatment")plt.show()
T-Learner(两个估计器)
T-Learner是一种提升建模技术,将干预组和对照组视为单独的实验。它训练两个分开的模型——一个用于干预组,另一个用于对照组——使其能够捕捉干预如何不同地影响每个组。
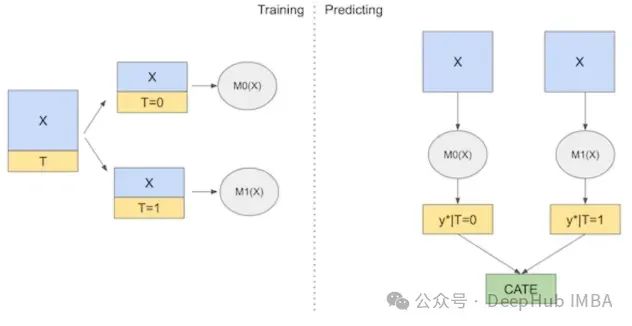
在预测时,T-Learner对不同的干预指标应用适当模型进行结果预测——对于对照组使用对照模型(T=0),对于干预组使用干预模型(T=1)。然后CATE计算为这两个模型的平均预测差值。
使用Causalml实现T-Learner
下面的代码实现了T-Learner模型
learner_t = BaseTRegressor(XGBRegressor(), control_name=0)# Train the modellearner_t.fit(X=X_train, treatment=treatment_train, y=y_train)# Predict the treatment effect on the test datat_cate_estimates = learner_t.predict(X=X_test)# Create a DataFrame for easier manipulationt_pred_data = pd.DataFrame({'outcome': np.ravel(y_test),'treatment': np.ravel(treatment_test),'T_Learner_Predicted_Effect': np.ravel(t_cate_estimates)})plot_gain(t_pred_data, outcome_col="outcome", treatment_col='treatment')plt.show()
T-Learner需要大量的对照组和干预组数据来防止过拟合。适用于干预和结果之间关系复杂的情况,以及干预可能对个体产生不同影响的情况
X-Learner
X-Learner的思路是基于T-Learner的,在T-Learner基础上,分为了两个阶段,并生成了一个倾向性模型。
第一阶段:与 T-Learner相同,独立分析每个组并为干预组和对照组分别建立模型。
第二阶段:X-Learner首先承认两组之间可能存在的信息差距,然后通过利用每组的数据估计干预对另一组的缺失效果。然后使用这些估计来预测结果。
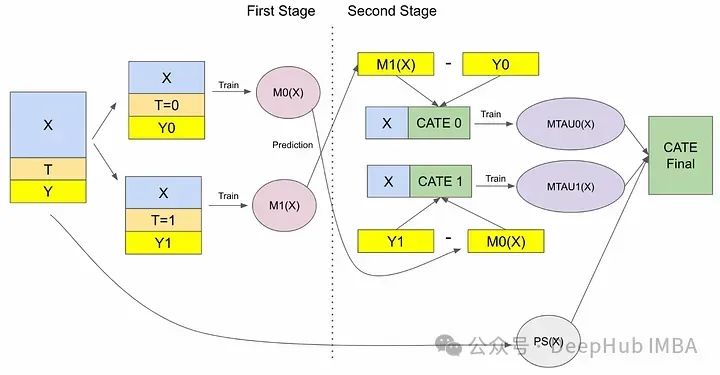
X-Learner使用倾向性得分,这是衡量每个个体接受干预的可能性,连同第二阶段的结果,估计CATE。
因为它像 X 一样在干预组和对照组之间交叉信息,所以才被称为X-Learner。与 T-Learner不同,当其中一个干预组比另一个组大得多或不平衡或者当 CATE 函数较简单时,X-Learner表现非常好。
使用Causalml实现T-Learner
下面的代码使用XGBoost作为基础学习器来预测结果,并使用单独的线性回归模型来估计干预效果。
learner_x = BaseXRegressor(learner=XGBRegressor(), treatment_effect_learner=LinearRegression())cate_x = learner_x.fit_predict(X=X_train, treatment=treatment_train, y=y_train)# Predict the treatment effect on the test datax_cate_estimates = learner_x.predict(X=X_test)# Create a DataFrame for easier manipulationx_pred_data = pd.DataFrame({'outcome': np.ravel(y_test),'treatment': np.ravel(treatment_test),'X_Learner_Predicted_Effect': np.ravel(x_cate_estimates),'T_Learner_Predicted_Effect':np.ravel(t_cate_estimates),'S_Learner_Predicted_Effect':np.ravel(s_cate_estimates),'Uplifting':y_pred['recommended_treatment']})plot_gain(x_pred_data, outcome_col="outcome", treatment_col="treatment")plt.show()
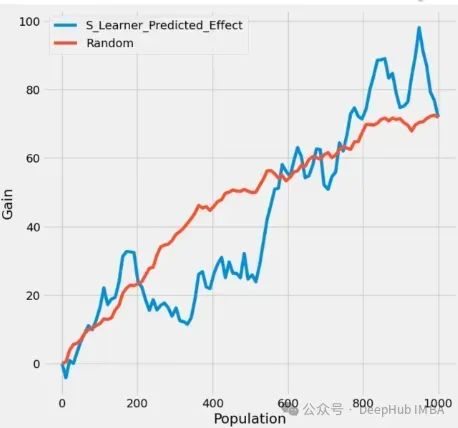
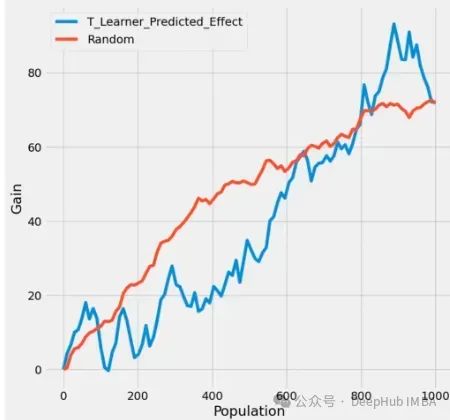
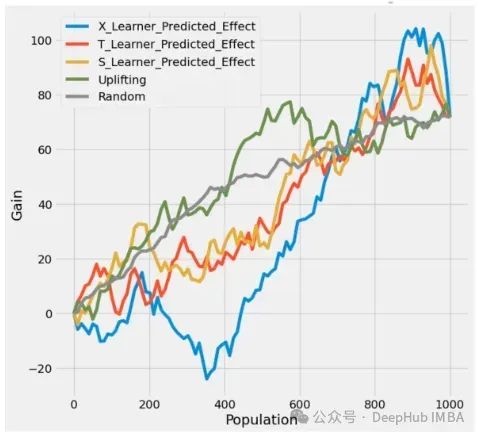
下图是模型的累积收益图,比较了不同类型的元学习器和目标干预策略。
总结
X-Learner和Uplifting方法在目标过程的后期似乎更有效,这表明随着更多的数据被考虑,这些方法在识别真正可处理的个例方面更好。
S-Learner的收益随着目标人群的增加而稳步增长。
T-Learner始终提供更好的结果。
X-Learner最初表现出较低的结果,但随着目标人群的增加而改善,这表明在早期阶段可能会更加谨慎或有选择性。
最后本文出现了一些专有名词,如果你对因果推断不理解,可以看看下面的简单解释:
ATE:Average Treatment Effect,平均处理效应。实验组的平均处理效应。比如实验组上线了新的推荐策略,实验组与对照组之间平均效果的差别就是ATE。
CATE:Conditional Average Treatment Effect,条件平均处理效应。实验组中某个细分群的平均处理效应。比如实验组的活跃用户与对照组活跃用户平均效果的差别就是CATE。
ITE:Individual Treatment Effect,个体处理效应。实验组中每个个体的处理效应差异。
ATT:Average Treatment Effects on Treated,受处理群体的平均处理效应。比如实验组受处理的这群人如果不受处理,会是怎样的(这群人受处理与不受处理之间效果的差异)。但是对照组中不存在与实验组中一模一样的人,一般通过PSM来找到实验组人群的替身。
https://avoid.overfit.cn/post/91a55677ab61439cb6db84a7a4249937
作者:Renu Khandelwal