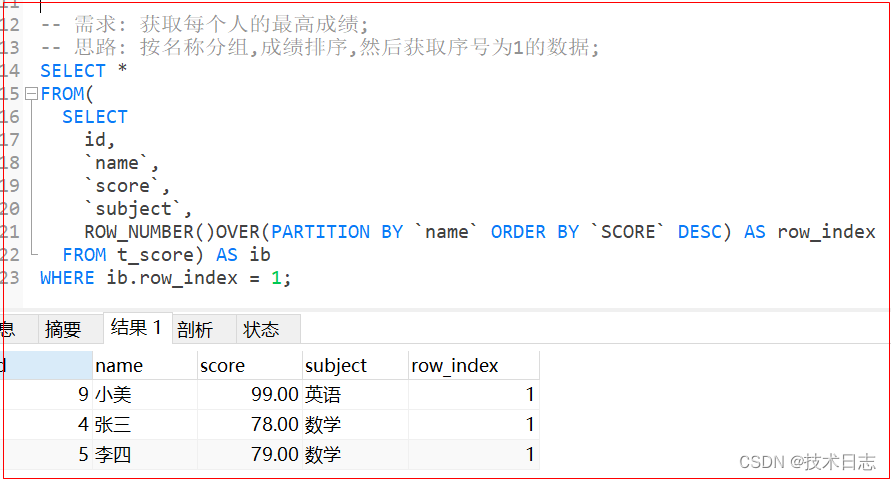
目录
内存分段
内存分页
内存分段
程序是由若干个逻辑分段组成的,如可由代码分段、数据分段、栈段、堆段组成。不同的段是有不同的属性的,所以就用分段的形式把这些段分离出来。
分段机制下,虚拟地址和物理地址是如何映射的?
分段机制下的虚拟地址由两部分组成,段选择因子和段内偏移量。
- 段选择子就保存在段寄存器里面。段选择子里面最重要的是段号,用作段表的索引。段表里面保存的是这个段的基地址、段的界限和特权等级等。
- 虚拟地址中的段内偏移量应该位于 0 和段界限之间,如果段内偏移量是合法的,就将段基地址加上段内偏移量得到物理内存地址。
在上面,知道了虚拟地址是通过段表与物理地址进行映射的,分段机制会把程序的虚拟地址分成 4 个段,每个段在段表中有一个项,在这一项找到段的基地址,再加上偏移量,于是就能找到物理内存中的地址,
分段的办法很好,解决了程序本身不需要关心具体的物理内存地址的问题,但它也有一些不足之处:
- 第一个就是内存碎片的问题。
- 第二个就是内存交换的效率低的问题。
接下来,说说为什么会有这两个问题。
我们先来看看,分段为什么会产生内存碎片的问题?
我们来看看这样一个例子。假设有 1G 的物理内存,用户执行了多个程序,其中:
- 游戏占用了 512MB 内存
- 浏览器占用了 128MB 内存
- 音乐占用了 256 MB 内存。
这个时候,如果我们关闭了浏览器,则空闲内存还有 1024 - 512 - 256 = 256MB。
如果这个 256MB 不是连续的,被分成了两段 128 MB 内存,这就会导致没有空间再打开一个 200MB 的程序。
内存分段会出现内存碎片吗?
内存碎片主要分为,内部内存碎片和外部内存碎片。
内存分段管理可以做到段根据实际需求分配内存,所以有多少需求就分配多大的段,所以不会出现内部内存碎片。
但是由于每个段的长度不固定,所以多个段未必能恰好使用所有的内存空间,会产生了多个不连续的小物理内存,导致新的程序无法被装载,所以会出现外部内存碎片的问题。
解决「外部内存碎片」的问题就是内存交换。
这个内存交换空间,在 Linux 系统里,也就是我们常看到的 Swap 空间,这块空间是从硬盘划分出来的,用于内存与硬盘的空间交换。
再来看看,分段为什么会导致内存交换效率低的问题?
对于多进程的系统来说,用分段的方式,外部内存碎片是很容易产生的,产生了外部内存碎片,那不得不重新 Swap 内存区域,这个过程会产生性能瓶颈。
因为硬盘的访问速度要比内存慢太多了,每一次内存交换,我们都需要把一大段连续的内存数据写到硬盘上。
所以,如果内存交换的时候,交换的是一个占内存空间很大的程序,这样整个机器都会显得卡顿。
为了解决内存分段的「外部内存碎片和内存交换效率低」的问题,就出现了内存分页。
内存分页
分段的好处就是能产生连续的内存空间,但是会出现「外部内存碎片和内存交换的空间太大」的问题。
分页是把整个虚拟和物理内存空间切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间,我们叫页。在 Linux 下,每一页的大小为 4KB。
虚拟地址与物理地址之间通过页表来映射
页表是存储在内存里的,内存管理单元 (MMU)就做将虚拟内存地址转换成物理地址的工作。
而当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入系统内核空间分配物理内存、更新进程页表,最后再返回用户空间,恢复进程的运行。
分页是怎么解决分段的「外部内存碎片和内存交换效率低」的问题?
内存分页由于内存空间都是预先划分好的,也就不会像内存分段一样,在段与段之间会产生间隙非常小的内存,这正是分段会产生外部内存碎片的原因。而采用了分页,页与页之间是紧密排列的,所以不会有外部碎片。
但是,因为内存分页机制分配内存的最小单位是一页,即使程序不足一页大小,我们最少只能分配一个页,所以页内会出现内存浪费,所以针对内存分页机制会有内部内存碎片的现象。
如果内存空间不够,操作系统会把其他正在运行的进程中的「最近没被使用」的内存页面给释放掉,也就是暂时写在硬盘上,称为换出。一旦需要的时候,再加载进来,称为换入。所以,一次性写入磁盘的也只有少数的一个页或者几个页,不会花太多时间,内存交换的效率就相对比较高。
更进一步地,分页的方式使得我们在加载程序的时候,不再需要一次性都把程序加载到物理内存中。我们完全可以在进行虚拟内存和物理内存的页之间的映射之后,并不真的把页加载到物理内存里,而是只有在程序运行中,需要用到对应虚拟内存页里面的指令和数据时,再加载到物理内存里面去。
分页机制下,虚拟地址和物理地址是如何映射的?
在分页机制下,虚拟地址分为两部分,页号和页内偏移。页号作为页表的索引,页表包含物理页每页所在物理内存的基地址,这个基地址与页内偏移的组合就形成了物理内存地址。
总结一下,对于一个内存地址转换,其实就是这样三个步骤:
- 把虚拟内存地址,切分成页号和偏移量;
- 根据页号,从页表里面,查询对应的物理页号;
- 直接拿物理页号,加上前面的偏移量,就得到了物理内存地址。
简单的分页有什么缺陷吗?
有空间上的缺陷。
因为操作系统是可以同时运行非常多的进程的,那就意味着页表会非常的庞大。
在 32 位的环境下,虚拟地址空间共有 4GB,假设一个页的大小是 4KB(2^12),那么就需要大约 100 万 (2^20) 个页,每个「页表项」需要 4 个字节大小来存储,那么整个 4GB 空间的映射就需要有 4MB 的内存来存储页表。
这 4MB 大小的页表,看起来也不是很大。但是要知道每个进程都是有自己的虚拟地址空间的,也就说都有自己的页表。
那么,100 个进程的话,就需要 400MB 的内存来存储页表,这是非常大的内存了,更别说 64 位的环境了。
多级页表
要解决上面的问题,就需要采用一种叫作多级页表的解决方案。
在前面我们知道了,对于单页表的实现方式,在 32 位和页大小 4KB 的环境下,一个进程的页表需要装下 100 多万个「页表项」,并且每个页表项是占用 4 字节大小的,于是相当于每个页表需占用 4MB 大小的空间。
我们把这个 100 多万个「页表项」的单级页表再分页,将页表(一级页表)分为 1024 个页表(二级页表),每个表(二级页表)中包含 1024 个「页表项」,形成二级分页。
你可能会问,分了二级表,映射 4GB 地址空间就需要 4KB(一级页表)+ 4MB(二级页表)的内存,这样占用空间不是更大了吗?
当然如果 4GB 的虚拟地址全部都映射到了物理内存上的话,二级分页占用空间确实是更大了,但是,我们往往不会为一个进程分配那么多内存。
其实我们应该换个角度来看问题,还记得计算机组成原理里面无处不在的局部性原理么?
每个进程都有 4GB 的虚拟地址空间,而显然对于大多数程序来说,其使用到的空间远未达到 4GB,因为会存在部分对应的页表项都是空的,根本没有分配,对于已分配的页表项,如果存在最近一定时间未访问的页表,在物理内存紧张的情况下,操作系统会将页面换出到硬盘,也就是说不会占用物理内存。
如果使用了二级分页,一级页表就可以覆盖整个 4GB 虚拟地址空间,但如果某个一级页表的页表项没有被用到,也就不需要创建这个页表项对应的二级页表了,即可以在需要时才创建二级页表。做个简单的计算,假设只有 20% 的一级页表项被用到了,那么页表占用的内存空间就只有 4KB(一级页表) + 20% * 4MB(二级页表)= 0.804MB,这对比单级页表的 4MB 是不是一个巨大的节约?
那么为什么不分级的页表就做不到这样节约内存呢?
我们从页表的性质来看,保存在内存中的页表承担的职责是将虚拟地址翻译成物理地址。假如虚拟地址在页表中找不到对应的页表项,计算机系统就不能工作了。所以页表一定要覆盖全部虚拟地址空间,不分级的页表就需要有 100 多万个页表项来映射,而二级分页则只需要 1024 个页表项(此时一级页表覆盖到了全部虚拟地址空间,二级页表在需要时创建)。
我们把二级分页再推广到多级页表,就会发现页表占用的内存空间更少了,这一切都要归功于对局部性原理的充分应用。
对于 64 位的系统,两级分页肯定不够了,就变成了四级目录
再来,为了解决简单分页产生的页表过大的问题,就有了多级页表,它解决了空间上的问题,但这就会导致 CPU 在寻址的过程中,需要有很多层表参与,加大了时间上的开销。于是根据程序的局部性原理,在 CPU 芯片中加入了 TLB,负责缓存最近常被访问的页表项,大大提高了地址的转换速度。









![linux使用操作[2]](https://img-blog.csdnimg.cn/e1babd9512df4c81be6d6f74796fb591.png)