Hadoop高可用环境搭建
确定提前安装好了hadoop和zookeeper
1.删除原有数据文件
三台机器都要进行删除
可以使用CRT发送交互到所有会话
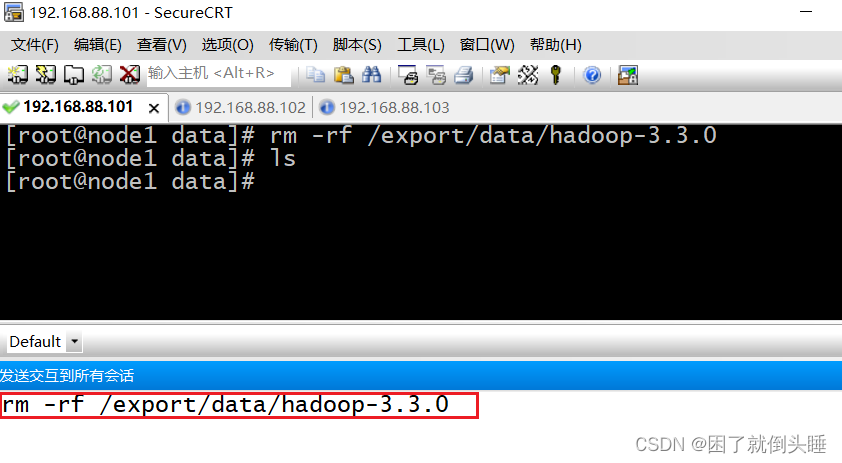
rm -rf /export/data/hadoop-3.3.0
2.安装软件
三台机器都要进行安装
注意: 如果网络较慢安装失败,那就重复安装即可
# 实现多个服务的通讯 yum install psmisc -y
3.修改配置文件
先只修改node1,最后拷贝给其他机器
进入hadoop目录
[root@node1 /]# cd /export/server/hadoop-3.3.0/etc/hadoop/ [root@node1 hadoop]# ls
修改hadoop-env.sh
在文件最后添加下面两行
export HDFS_JOURNALNODE_USER=root export HDFS_ZKFC_USER=root
修改core-site.xml
注意: 将之前 configuration 里面的内容全部替换掉
<configuration> <!-- HA集群名称,该值要和hdfs-site.xml中的配置保持一致 --> <property><name>fs.defaultFS</name><value>hdfs://cluster1</value> </property> <!-- hadoop本地磁盘存放数据的公共目录 --> <property><name>hadoop.tmp.dir</name><value>/export/data/ha-hadoop</value> </property> <!-- ZooKeeper集群的地址和端口--> <property><name>ha.zookeeper.quorum</name><value>node1:2181,node2:2181,node3:2181</value> </property> <!-- 整合hive 用户代理设置 --> <property><name>hadoop.proxyuser.root.hosts</name><value>*</value> </property> <property><name>hadoop.proxyuser.root.groups</name><value>*</value> </property> </configuration>
修改hdfs-site.xml
注意: 将之前 configuration 里面的内容全部替换掉
<configuration> <!--指定hdfs的nameservice为cluster1,需要和core-site.xml中的保持一致 --> <property><name>dfs.nameservices</name><value>cluster1</value> </property> <!-- cluster1下面有两个NameNode,分别是nn1,nn2 --> <property><name>dfs.ha.namenodes.cluster1</name><value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property><name>dfs.namenode.rpc-address.cluster1.nn1</name><value>node1:8020</value> </property> <!-- nn1的http通信地址 --> <property><name>dfs.namenode.http-address.cluster1.nn1</name><value>node1:50070</value> </property> <!-- nn2的RPC通信地址 --> <property><name>dfs.namenode.rpc-address.cluster1.nn2</name><value>node2:8020</value> </property> <!-- nn2的http通信地址 --> <property><name>dfs.namenode.http-address.cluster1.nn2</name><value>node2:50070</value> </property> <!-- 指定NameNode的edits元数据在JournalNode上的存放位置 --> <property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://node1:8485;node2:8485;node3:8485/cluster1</value> </property> <!-- 指定JournalNode在本地磁盘存放数据的位置 --> <property><name>dfs.journalnode.edits.dir</name><value>/export/data/journaldata</value> </property> <!-- 开启NameNode失败自动切换 --> <property><name>dfs.ha.automatic-failover.enabled</name><value>true</value> </property> <!-- 指定该集群出故障时,哪个实现类负责执行故障切换 --> <property><name>dfs.client.failover.proxy.provider.cluster1</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制方法--> <property><name>dfs.ha.fencing.methods</name><value>sshfence</value> </property> <!-- 使用sshfence隔离机制时需要ssh免登陆 --> <property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value> </property> <!-- 配置sshfence隔离机制超时时间 --> <property><name>dfs.ha.fencing.ssh.connect-timeout</name><value>30000</value> </property> </configuration>
修改yarn-site.xml
注意: 将之前 configuration 里面的内容全部替换掉
<configuration> <!-- 开启RM高可用 --> <property><name>yarn.resourcemanager.ha.enabled</name><value>true</value> </property> <!-- 指定RM的cluster id --> <property><name>yarn.resourcemanager.cluster-id</name><value>yrc</value> </property> <!-- 指定RM的名字 --> <property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value> </property> <!-- 分别指定RM的地址 --> <property><name>yarn.resourcemanager.hostname.rm1</name><value>node1</value> </property> <property><name>yarn.resourcemanager.hostname.rm2</name><value>node2</value> </property> <!-- 指定zk集群地址 --> <property><name>yarn.resourcemanager.zk-address</name><value>node1:2181,node2:2181,node3:2181</value> </property> <property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value> </property> </configuration>
补充:
rz -y:上传文件。-y,如果目的地中有相同名称的文件,那么会覆盖。否则不会做任何操作
拷贝给node2
[root@node1 ~]# scp -r /export/server/hadoop-3.3.0/ node2:/export/server/
拷贝给node3
[root@node1 ~]# scp -r /export/server/hadoop-3.3.0/ node3:/export/server/
4.启动高可用服务
注意:一定要按照以下的顺序进行启动
启动Zookeeper服务
三台机器都启动
zkServer.sh start
启动journalnode服务
三台机器都要启动
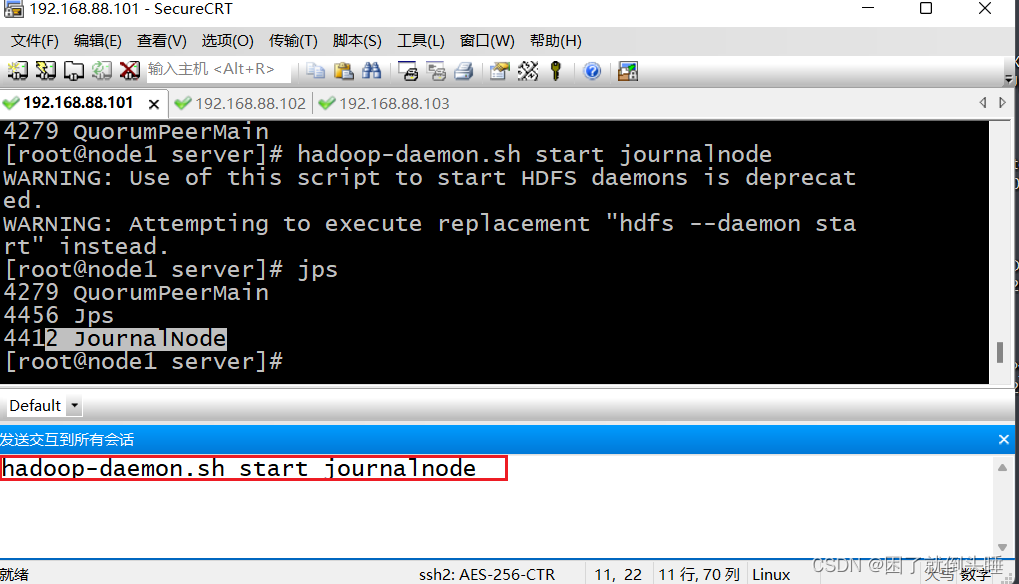
hadoop-daemon.sh start journalnode
cd /export/data : 进入目录查看journaldata目录是否生成
初始化 namenode
先在node1上执行初始化
[root@node1 data]# hdfs namenode -format # 查看ha-hadoop目录是否生成 [root@node1 data]# ll 总用量 0 drwxr-xr-x 3 root root 17 4月 29 16:11 ha-hadoop drwxr-xr-x 3 root root 22 4月 29 16:11 journaldata [root@node1 data]# pwd /export/data [root@node1 data]#
将初始化生成的目录,复制到 node2 下
[root@node1 data]# scp -r /export/data/ha-hadoop/ node2:/export/data/
格式化zkfc服务
注意: 要在 node1 上进行启动
[root@node1 data]# hdfs zkfc -formatZK
启动hadoop服务
注意: 要在node1 上进行启动
DFSZKFailoverController服务真正是hadoop启动起来的
[root@node1 data]# start-all.sh
查看所有服务
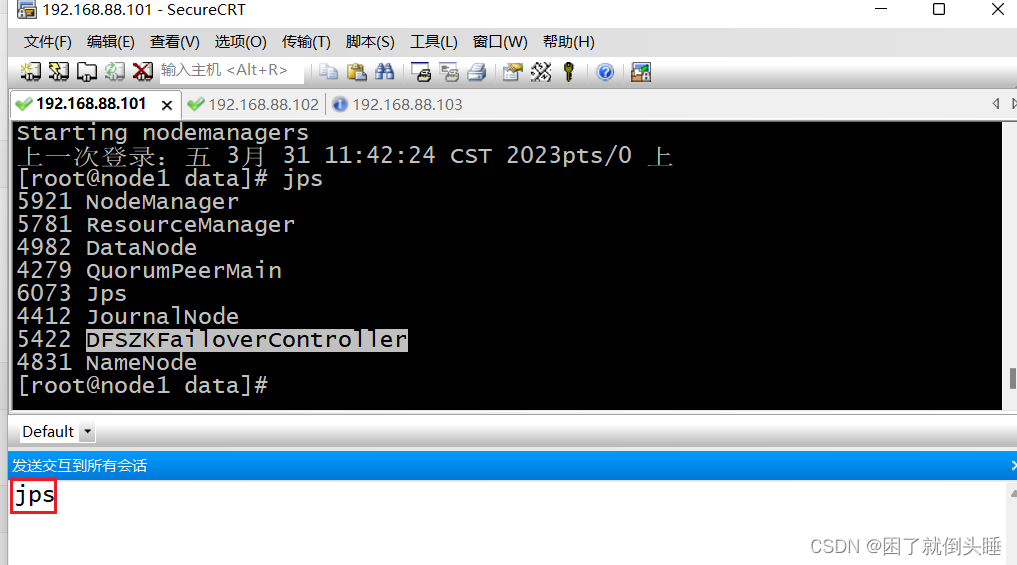
jps
5.web页面查看
hdfs服务: 192.168.88.101:50070 192.168.88.102:50070 yarn服务: 192.168.88.101:8088 192.168.88.102:8088