作者:胡赟豪
本文约2800字,建议阅读5分钟
本文介绍了构建评分卡模型。一、背景
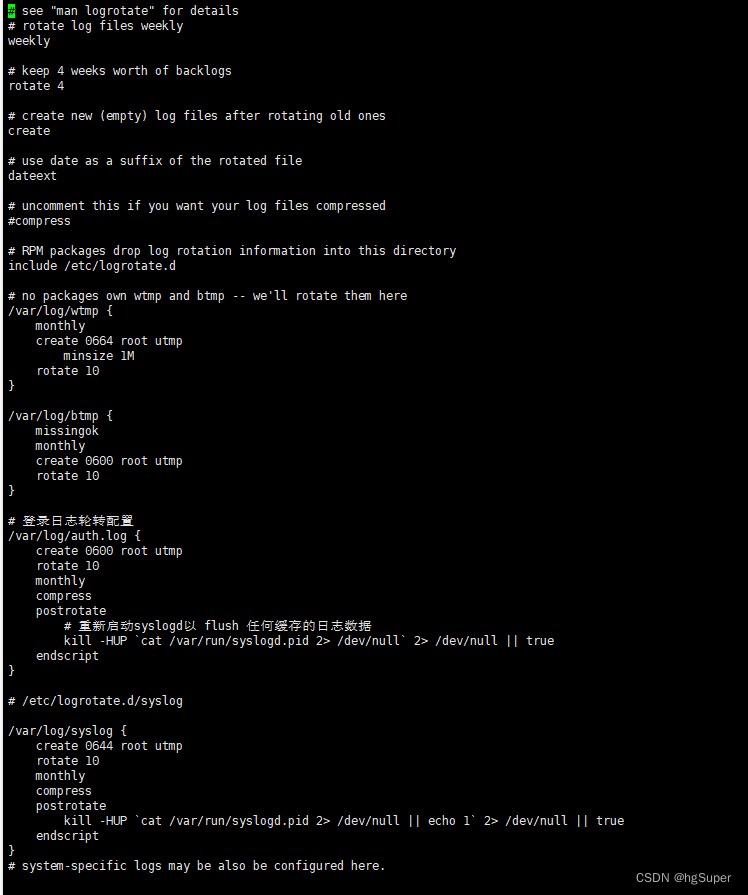
在各种机器学习、深度学习模型快速发展的当下,评分卡模型作为一种可解释机器学习模型,仍然在金融、营销等领域被广泛使用。这一模型通过构建一组基于输入变量的评分规则,能够直观地对样本进行评分,非常易于理解和操作。举一个金融信用风险评分卡的例子,要判断一笔贷款能够被按时偿还的风险大小,可以设置这样一个评分卡:
是否有车 | 否 | 0 |
是 | 10 | |
是否有房 | 否 | 0 |
是 | 30 | |
是否已婚 | 否 | 0 |
是 | 10 | |
年龄 | [0,25) | 0 |
[25,40) | 5 | |
[40~55) | 10 | |
[55,+∞) | 5 | |
学历 | 初中及以下 | 0 |
高中 | 5 | |
本科 | 10 | |
硕士及以上 | 20 | |
月均收入 | 0~3000 | 0 |
3000~6000 | 5 | |
6000~10000 | 10 | |
10000~20000 | 15 | |
20000+ | 20 |
这个评分卡的得分范围是[0,100],分数越高,违约的风险就越小。对于一个有房有车,有着本科学历和15000元月收入的30岁已婚申请者,按照评分卡可以计算其得分:10+30+10+5+10+15=80分,据此风险评估人员可以快速地判断出该申请者的信用风险较小。
评分卡的强可解释性一方面使其能够快速给出结论,另一方面也能给出原因。通过查看每个评分项的得分,我们也可以清楚看到申请者在哪些项目扣了多少分。在一些其他场景下我们如果要给予被评分人建议,也可以清楚地看到哪一项提升到什么程度,对应能够增加多少得分。
那么评分卡为什么最后是选用这些变量?这些分数又是怎么计算出来的呢?接下来我们一起看看评分卡的构建过程。
二、数据清洗
在上面的例子中,模型的目标是申请者是否会按时偿还,特征则是每个申请者的个人信息。在收集好样本数据之后,首先需要对数据进行清洗,包括异常值、缺失值处理等。
异常值可以基于规则或者离群值检测来发现,例如发现年龄为负数、收入高于平均值的X%(X可以自行调整)等情况的样本,可以予以剔除,避免干扰后续的模型构建。
缺失值则可以用平均数、相似样本填充等方法进行填补,也可以直接保留缺失状态,在后续的建模中作为单独的一个分箱。
三、分箱
评分卡模型的一大特点是对每个输入变量的不同分箱分别进行打分。例如在上面例子中,我们注意到每个输入变量都是离散的。即使是像收入、年龄这样的连续型变量,也是先进行分箱(分成不同的取值区间)后再进行打分,因此模型最后的得分也是离散的。
分箱的常见方法包括:
(1)等距分箱
将变量可能取值的区间分为k个相同大小的小区间,例如连续区间[0,3]拆分为[0,1)和[1,2)、[2,3]三个分箱。
(2)等频分箱
将变量可能取值的区间分为k个区间(可以不同大小),每个区间内的样本频率相同,例如[0,3]拆分为[0,1)和[1,3]两个区间,但样本中在两个区间内的取值频率相同。
(3)最优分箱
最优分箱方法是有监督的,需要样本的标签信息,使用类似于决策树的方法,通过计算信息熵增益等指标来决定拆分点。
四、WOE编码
分箱之后输入变量变成一系列取值为0或1的变量分箱,接下来我们需要对它们进行有监督的WOE(证据权重,weight of evidence)编码,将“1”转换成其他更加有预测能力的数字。
假设样本标签中违约为1,按时偿还为0,则对于变量分箱i,定义以下变量:
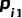 为分箱i中违约客户占所有样本中违约客户的比例
为分箱i中违约客户占所有样本中违约客户的比例
 为分箱i中按时偿还客户占所有样本中违约客户的比例
为分箱i中按时偿还客户占所有样本中违约客户的比例
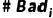 为分箱i中违约客户人数
为分箱i中违约客户人数
 为分箱i中按时偿还的客户人数
为分箱i中按时偿还的客户人数
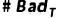 为所有样本中违约客户人数
为所有样本中违约客户人数
 为所有样本中按时偿还的客户人数
为所有样本中按时偿还的客户人数
则分箱i的WOE取值为
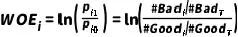
通过公式可以看出,分箱中违约客户比例越高,WOE值越大,理论上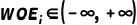 。当分箱i中违约客户占比高于总体时WOE>0,小于总体时WOE<0;违约客户的占比和总体一致时,WOE值为0,分箱没有预测能力
。当分箱i中违约客户占比高于总体时WOE>0,小于总体时WOE<0;违约客户的占比和总体一致时,WOE值为0,分箱没有预测能力
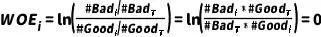
从上面的式子可以看出,WOE值能够反映分箱对目标预测的贡献情况,在分箱的分类信息“1”的基础上增加该分箱的权重信息,因此WOE被称为“证据权重”。注意在计算时,即使是缺失值组成的分箱也可以算出一个WOE分数。
但是WOE的计算为什么是这个形式?一种解释是为了更加适配后续的logistic建模,从以下推导中可以看出,WOE分数和预测目标的对数几率的变化近似线性相关。
Logistic模型公式: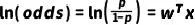 ,其中p为客户违约概率,
,其中p为客户违约概率,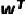 为模型的参数向量
为模型的参数向量
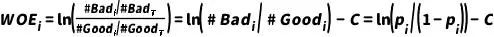 ,其中
,其中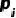 为分箱i中客户违约概率,
为分箱i中客户违约概率, 为总体的违约对数几率。
为总体的违约对数几率。
五、变量选择
变量选择的目标主要有两个,一个是筛选出预测能力强的变量,另一个是处理多重共线性问题。
评分卡模型中常用IV值(信息价值,information value)来表示变量的预测能力,变量的IV值是其所有分箱的IV值之和:
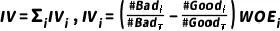
由于公式中的两个项同向,故IV≥0,IV值越大,变量对目标的预测能力越强。
多重共线性则可以结合变量间相关系数、VIF值等进行判断,在多个共线性较高的变量中,可以优先保留预测能力较高的变量。
六、模型训练与评估
训练前首先对样本进行样本集和测试集的拆分。评分卡模型本质上是一个二分类预测模型,使用logistic模型来估计参数,接下来只需要将筛选后的变量的分箱WOE值输入到模型中,完成模型的训练即可。在测试集上可以计算模型的AUC、KS等指标,来评估模型效果。
七、评分卡转换
至此还剩下最后一个问题:怎样将模型的结果转化为文章开头那样的评分卡里的分数?
例子中评分卡的分数实际上表达的是违约的对数几率大小(因为希望分数大小和违约几率负相关所以加入负号):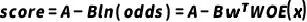
假设向量x取某个值时,违约几率为odds0,则此时得分为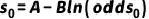 ;再假设几率翻倍时,有
;再假设几率翻倍时,有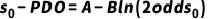 ,其中PDO表示违约几率翻倍时分数的变动幅度。可以将以上两个式子联成一个方程组,在人工设定基础分数s0、基础几率odds0和PDO的基础上即可解出A、B大小。
,其中PDO表示违约几率翻倍时分数的变动幅度。可以将以上两个式子联成一个方程组,在人工设定基础分数s0、基础几率odds0和PDO的基础上即可解出A、B大小。
在式子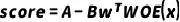 中代入A、B后,就可以将各个变量的分箱得分计算出来,生成评分卡了。注意此时评分卡得分的阈值范围很可能并不是0~100这样比较规整的区间,但可以通过分数的映射再进行一些调整得到。
中代入A、B后,就可以将各个变量的分箱得分计算出来,生成评分卡了。注意此时评分卡得分的阈值范围很可能并不是0~100这样比较规整的区间,但可以通过分数的映射再进行一些调整得到。
编辑:王菁
作者简介
胡赟豪,硕士毕业于清华大学经济管理学院,现从事于互联网数据科学相关工作,主要技术探索方向为机器学习及其在商业中的应用。
数据派研究部介绍
数据派研究部成立于2017年初,以兴趣为核心划分多个组别,各组既遵循研究部整体的知识分享和实践项目规划,又各具特色:
算法模型组:积极组队参加kaggle等比赛,原创手把手教系列文章;
调研分析组:通过专访等方式调研大数据的应用,探索数据产品之美;
系统平台组:追踪大数据&人工智能系统平台技术前沿,对话专家;
自然语言处理组:重于实践,积极参加比赛及策划各类文本分析项目;
制造业大数据组:秉工业强国之梦,产学研政结合,挖掘数据价值;
数据可视化组:将信息与艺术融合,探索数据之美,学用可视化讲故事;
网络爬虫组:爬取网络信息,配合其他各组开发创意项目。
点击文末“阅读原文”,报名数据派研究部志愿者,总有一组适合你~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THUID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
未经许可的转载以及改编者,我们将依法追究其法律责任。
 点击“阅读原文”加入组织~
点击“阅读原文”加入组织~