目录
1. 二叉搜索树的概念及结构
1.1. 二叉搜索树的概念
1.2. 二叉搜索树的结构样例:
2. 二叉搜索树实现
2.1. insert的非递归实现
2.2. find的非递归实现
2.3. erase的非递归实现
2.3.1. 第一种情况:所删除的节点的左孩子为空
2.3.1.1. 错误的代码(第一种情况)
2.3.1.2. 正确的代码(第二种情况)
2.3.2. 第二种情况:所删除的节点的右孩子为空
2.3.2.1. 正确的代码(第二种情况)
2.3.3. 第三种情况:所删除的节点有两个非空节点
2.3.3.1. 有错误的代码(第三种情况)
2.3.3.2. 正确的代码(第三种情况):
2.3.4 erase的完整实现
2.4. find的递归实现
2.5. insert的递归实现
2.6. erase的递归实现
2.6.1. 第一种情况:被删除节点的右孩子为空
编辑
2.6.2. 第二种情况:被删除节点的左孩子为空
编辑
2.6.3. 第三种情况:被删除节点的左右孩子都不为空
2.7. 析构函数的实现
2.8. copy constructor的实现
2.9. 赋值运算符重载
3.二叉树搜索树应用分析
3.1. K模型 && KV模型
3.2. 二叉搜索树的性能分析
4. 二叉树进阶面试题
4.1. 根据一棵树的前序遍历与中序遍历构造二叉树
4.2. 根据一棵树的中序遍历与后序遍历构造二叉树
4.3. 二叉树的前序遍历 --- 非递归
4.4. 二叉树的中序遍历 --- 非递归
4.5. 二叉树的后序遍历 --- 非递归
4.6. 二叉树的层序遍历
4.7. 二叉树的层序遍历Ⅱ
4.8. 二叉树的最近公共祖先
4.8.1. 第二种思路实现
4.8.2. 第三种思路实现
4.9. 二叉搜素树和双向链表
4.10. 二叉树创建字符串
1. 二叉搜索树的概念及结构
学习二叉搜索树的一些原因:
1. map 和 set 特性需要 先铺垫二叉搜索树,而二叉搜索树也是一种树形结构2. 二叉搜索树的特性了解,有助于更好的理解 map 和 set 的特性
1.1. 二叉搜索树的概念
二叉搜索树(Binary Search Tree,简称BST)又名为二叉排序树或者是二叉查找树。它可能是一棵空树,或者是满足下面性质的二叉树:
- 如果它的左子树不为空,那么左子树上的所有节点的值都要小于根节点的值
- 如果它的右子树不为空,那么右子树上的所有节点的值都要大于根结点的值
- 它的左右子树也是一颗二叉搜索树
对于一颗二叉搜索树,它的中序遍历可以得到有序的数列。
需要注意的是,二叉搜索树要求每个节点的值都唯一,如果存在重复的值,可以在节点中添加计数器来解决。
1.2. 二叉搜索树的结构样例:
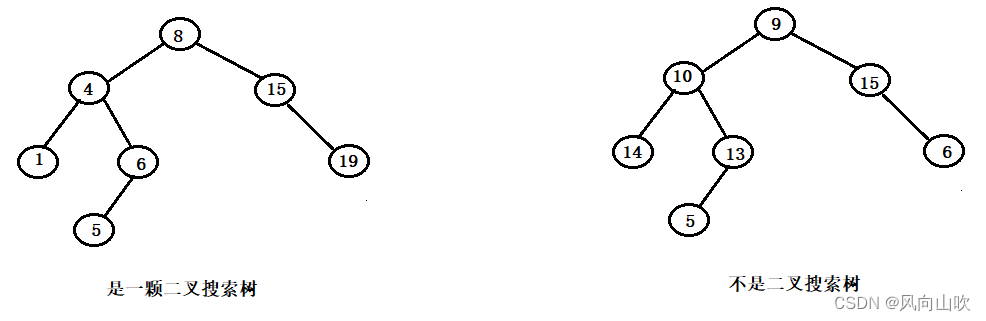
一棵树是否是一颗二叉搜索树,必须要符合二叉搜索树的性质。
2. 二叉搜索树实现
二叉搜索树的概念和结构比较简单,但为了我们能更好的理解二叉搜索树,对它的模拟实现是必不可少的。
2.1. insert的非递归实现
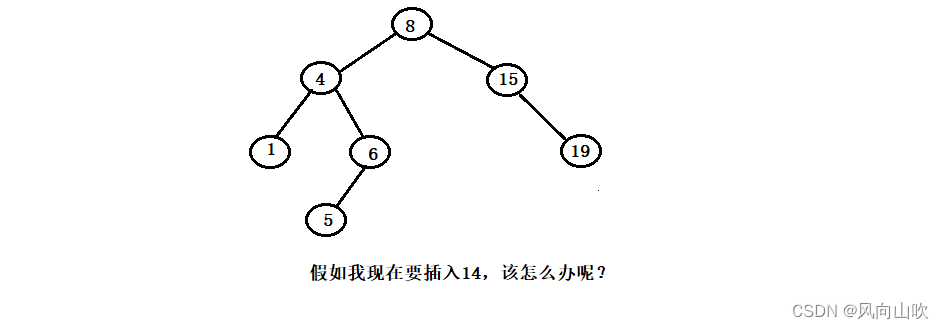
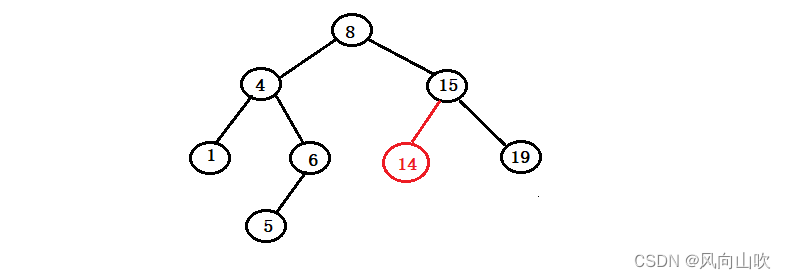
对于二叉搜索树的插入,我们需要满足插入后的二叉树仍旧是一颗二叉搜索树,也就是说,插入的元素必须要被插入到特定的位置,以维持二叉搜索树的结构。如上图所示,如果要插入14,那么它的位置是确定的,如下图所示:
因此insert的具体实现我们可以分解为两个过程:
第一步:找到要插入元素的位置。
第二步:插入元素,完成链接关系。
注意:在这里实现的二叉搜索树的每个值具有唯一性,相同值不插入
bool insert(const T& key){//1. 如果是空树,直接赋值即可,插入成功并返回trueif(_root == nullptr){node* newnode = new binary_search_tree_node<T>(key);_root = newnode;return true;}//2. 找到key的合适位置//为了更好的链接插入的节点,我们需要记录cur的父节点node* cur = _root;node* parent = nullptr;while(cur != nullptr){if(cur->_key > key){parent = cur;cur = cur->_left;}else if(cur->_key < key){parent = cur;cur = cur->_right;}else{//3. 走到这里说明,遇到了相同的key,那么不插入并返回falsereturn false;}}//4. 走到这里说明,找到了合适位置,需要插入,并完成链接关系,并返回truenode* newnode = new node(key);// 我们需要判断cur是parent的左节点还是右节点// 如果key小于parent的key,那么插入左节点if(key < parent->_key)parent->_left = newnode;// 反之链接到右节点elseparent->_right = newnode;return true;}2.2. find的非递归实现
find就很简单了,没什么要说的,根据传递的key进行判断,大于当前节点,那么当前节点向左走,反之向右走,如果相等,返回true,循环结束,则说明没有这个key
bool find(const T& key){//1. 从根节点开始node* cur = _root;while(cur != nullptr){//2. 如果当前关键字大于目标关键字,那么向左子树走if(cur->_key > key)cur = cur->_left;//3. 如果小于目标关键字,那么向右子树走else if(cur->_key < key)cur = cur->_right;//4. 相等,就返回trueelsereturn true;}//5. 循环结束,说明没找到return false;}
2.3. erase的非递归实现
对于搜索二叉树来说,真正有一些难度的是删除,对于删除我们可以分解为不同的情况,根据对应的情况,以特点方式解决。
在这里我们分为三种情况:
- 所删除的节点的左孩子为空:托孤法删除
- 所删除的节点的右孩子为空:托孤法删除
- 所删除的节点的有两个非空孩子:替代法删除
注意:对于叶子结点的处理可以归为第一类情况或者第二类情况。
为了可以更好的理解上面的三种情况,我们用图来说话:
2.3.1. 第一种情况:所删除的节点的左孩子为空
如图所示:假如现在我们要删除的节点是15节点,可以发现它的左孩子为空,那么如何删除呢?
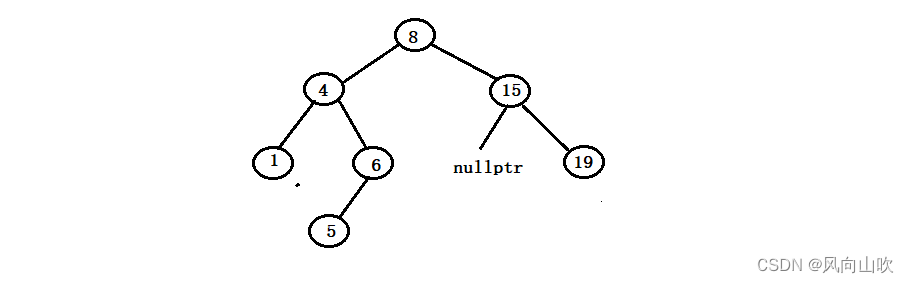
我们的方法是托孤法删除,什么叫托孤法删除呢?就是将15的非空孩子(在这里就是19)交给它的父亲节点(在这里就是8),如图所示:
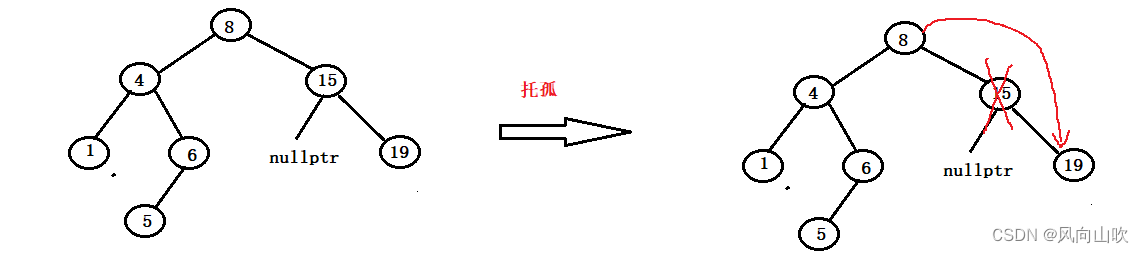
注意:在这里一定是父亲节点的右孩子指向被删除的节点的非空孩子吗?
答案是,不一定,我们需要根据被删除节点和父亲节点的关系判断:
如果被删除节点是父亲节点的右孩子,那么在这里就是父亲节点的右孩子指向被删除节点的非空节点;
如果被删除节点是父亲节点的左孩子,那么在这里就是父亲节点的左孩子指向被删除节点的非空节点
代码如下:
2.3.1.1. 错误的代码(第一种情况)
//第一种情况:所删除的节点的左孩子为空
if (del->_left == nullptr)
{if (del_parent->_left == del){del_parent->_left = del->_right;}else{del_parent->_right = del->_right;}delete del;
}可能我们认为这段代码没问题,但是如果是下面这种情况呢?
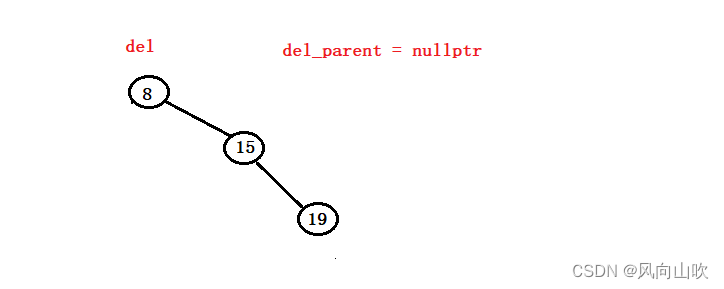
如果我此时要删除8,而8是这棵树的根节点,它是没有父节点的,那么此时上面的代码就会崩溃;为了解决这个隐患,我们的方案就是,如果被删除节点是根,且它的左子树为空树,那么我们更新根节点即可,在这里就是让15做根节点。
2.3.1.2. 正确的代码(第二种情况)
//第一种情况:所删除的节点的左孩子为空
if (del->_left == nullptr)
{// 如果被删除节点是根,那么更新根即可if (del == _root){node* newroot = del->_right;delete _root;_root = newroot;}// 被删除节点是非根节点else{if (del_parent->_left == del){del_parent->_left = del->_right;}else{del_parent->_right = del->_right;}delete del;}
}2.3.2. 第二种情况:所删除的节点的右孩子为空
如图所示:假如现在我们要删除的节点是6节点,可以发现它的右孩子为空,那么如何删除呢?
方案依旧是托孤法删除,在这里就是将6(被删除节点)的5(非空孩子节点)交给4(父亲节点)
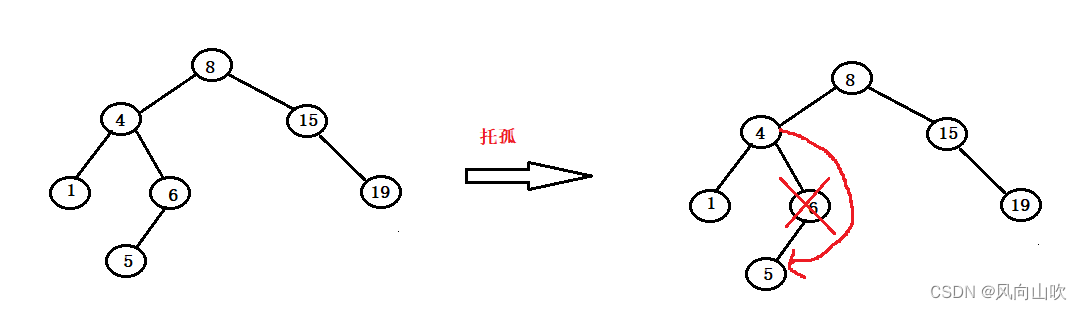
处理细节,和第一种情况大同小异。
需要注意的就是:最后父亲节点链接非空孩子节点的时候,要根据被删除节点是父亲节点的左孩子还是右孩子来判断。
第二种情况和第一种情况大同小异,也需要对根节点进行特殊处理:
代码如下:
2.3.2.1. 正确的代码(第二种情况)
//第二种情况:所删除的节点的右孩子为空
else if (del->_right == nullptr)
{// 当被删除节点为根节点if (del == _root){node* newroot = del->_left;delete del;_root = newroot;}//当被删除节点为非根节点else{if (del_parent->_left == del){del_parent->_left = del->_left;}else{del_parent->_right = del->_left;}delete del;}
}2.3.3. 第三种情况:所删除的节点有两个非空节点
较为复杂的就是第三种情况了,由于被删除的节点有两个孩子。因此无法托孤,因为父亲节点至多只能管理两个孩子,所以我们又提出了新的解决方案:替代法删除
如图所示:
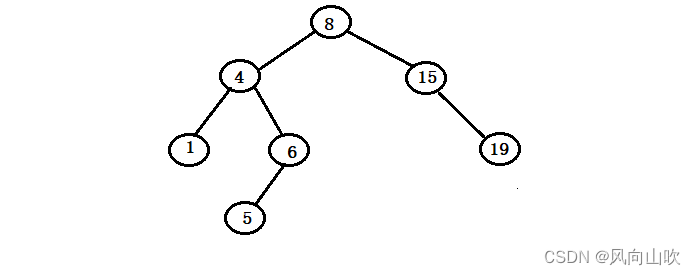
假如现在我们要删除4所在的节点,可以发现,4所在的节点有两个孩子,因此无法托孤。那么我们需要采用替代法删除,替代法删除就是在左子树或者右子树找一个"合适节点",将4所在的节点的key进行覆盖,将删除4所在的节点转化为删除我们找的这个"合适节点"。
而这个"合适节点"通常只有两个:
其一:左子树的最大节点,即左子树的最右节点。
其二:右子树的最小节点,即右子树的最左节点。
而我们在这里就找左子树的最大节点,在这里就是6
如果此时这个"合适节点"还有孩子(至多只会有一个孩子,而且在这里,只能是左孩子,因为这个"合适节点"就是左子树的最右节点),那么我们继续托孤法删除即可。
如图所示:
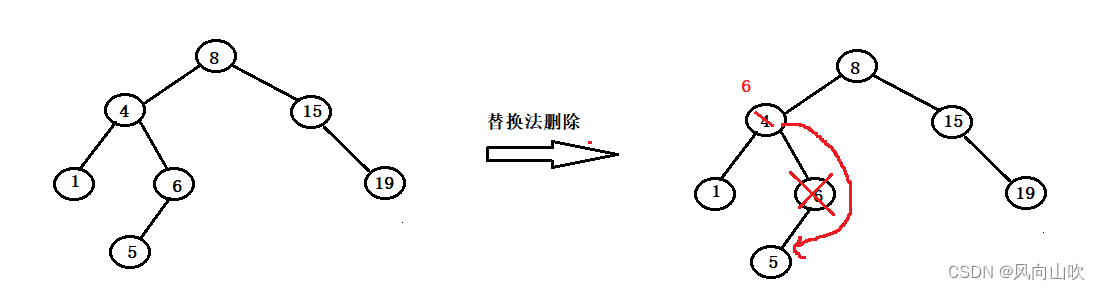
2.3.3.1. 有错误的代码(第三种情况)
// 第三种情况:所删除的节点有两个非空节点
else
{// 第一步:找左子树的最大节点or右子树的最小节点and它的父节点node* left_max = _root->_left;// 有可能这里我们会习惯的从nullptr开始,但是对于某些特殊情况会崩溃node* left_max_parent = nullptr;while (left_max->_right){left_max_parent = left_max;left_max = left_max->_right;}// 第二步: 覆盖被删除节点的keydel->_key = left_max->_key;// 第三步: 删除左子树的最大节点or右子树的最小节点if (left_max_parent->_left == left_max){left_max_parent->_left = left_max->_left;}else{left_max_parent->_right = left_max->_left;}delete left_max;left_max = nullptr;
}如果我们将"合适节点"的父节点初始值设为nullptr,那么在下面的场景会发生崩溃:

由于此时,这个"合适节点"正好是_root->_left,不会进入循环,那么left_max_parent就是空,那么后面的操作就会对空指针进行解引用,非法操作,进程崩溃。因此这里的left_max_parent的初始值必须要从根开始,不可以将初始值设为空。
同时,我们发现,最后执行托孤时,我们也进行了判断,这样的原因是因为这个"合适节点"既可能是父节点的左孩子,也可能是父节点的右孩子,因此必须判断。
2.3.3.2. 正确的代码(第三种情况):
// 第三种情况:所删除的节点有两个非空节点
else
{// 第一步:找左子树的最大节点or右子树的最小节点and它的父节点node* left_max = _root->_left;// 这里必须从根节点开始node* left_max_parent = _root;while (left_max->_right){left_max_parent = left_max;left_max = left_max->_right;}// 第二步: 覆盖被删除节点的keydel->_key = left_max->_key;// 第三步: 删除左子树的最大节点or右子树的最小节点if (left_max_parent->_left == left_max){left_max_parent->_left = left_max->_left;}else{left_max_parent->_right = left_max->_left;}delete left_max;left_max = nullptr;
}2.3.4 erase的完整实现
bool erase(const T& key)
{//1. 需要找到目标节点node* del = _root;node* del_parent = nullptr;while (del != nullptr){if (del->_key > key){del_parent = del;del = del->_left;}else if (del->_key < key){del_parent = del;del = del->_right;}else{//找到了被删除节点//第一种情况:所删除的节点的左孩子为空if (del->_left == nullptr){// 如果被删除节点是根,那么更新根即可if (del == _root){node* newroot = del->_right;delete _root;_root = newroot;}// 被删除节点是非根节点else{if (del_parent->_left == del){del_parent->_left = del->_right;}else{del_parent->_right = del->_right;}delete del;}}//第二种情况:所删除的节点的右孩子为空else if (del->_right == nullptr){// 如果被删除节点是根,那么更新根即可if (del == _root){node* newroot = del->_left;delete del;_root = newroot;}// 被删除节点是非根节点else{if (del_parent->_left == del){del_parent->_left = del->_left;}else{del_parent->_right = del->_left;}delete del;}}//第三种情况:所删除的节点有两个非空节点else{// 第一步:找左子树的最大节点or右子树的最小节点and它的父节点node* left_max = _root->_left;node* left_max_parent = _root;while (left_max->_right){left_max_parent = left_max;left_max = left_max->_right;}// 第二步: 覆盖被删除节点的keydel->_key = left_max->_key;// 第三步: 删除左子树的最大节点or右子树的最小节点if (left_max_parent->_left == left_max){left_max_parent->_left = left_max->_left;}else{left_max_parent->_right = left_max->_left;}delete left_max;left_max = nullptr;}return true;}}//没有该节点return false;
}2.4. find的递归实现
find的递归实现较为简单,思路是:根据传入的key与当前节点的key作比较,如果前者大于后者,那么当前节点往右子树走,如果前者小于后者,那么当前节点往左子树走,相等返回true,走到空,返回false。
代码实现:
bool _find_recursion(node* root, const T& key)
{// 走到空,代表没有这个keyif (root == nullptr)return false;else{if (root->_key > key){return _find_recursion(root->_left, key);}else if (root->_key < key){return _find_recursion(root->_right, key);}else{return true;}}
}2.5. insert的递归实现
insert分为两个过程
第一个过程:找到合适位置,类似于find()
第二个过程:插入数据,并完成链接关系
假如现在我们已经得到了合适的插入位置,那么如何链接呢?
例如,如下图所示:我们要插入13这个数据,现在的关键问题是,如何让15和13链接起来呢?
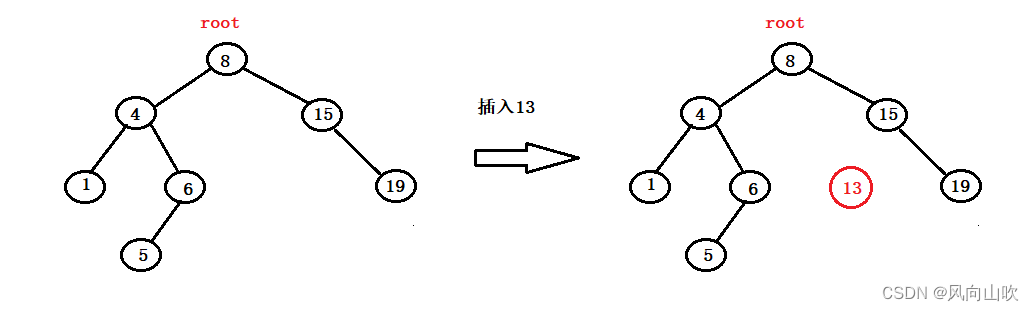
第一种方法:调用函数时,将父亲节点即这里的15也传进来。找到合适位置,创建节点并链接。
但是我们在这里提出一个较好玩的玩法,利用引用传参,如下所示:
bool _insert_recursion(node*& root, const T& key)
{if (root == nullptr){// 找到了目标位置,需要插入数据// 注意: 我们用上图解释,这里只是针对上面的图的特殊情况// 解释:root就是15这个结点的左孩子的引用,即root就是15的左孩子// 给root new了一个node(key),等价于插入了这个节点,并链接了起来.root = new node(key);return true;}else{if (root->_key > key){return _insert_recursion(root->_left, key);}else if (root->_key < key){return _insert_recursion(root->_right, key);}else{return false;}}
}2.6. erase的递归实现
对于erase的递归实现呢,其实也可以分为两个过程:
第一个过程:找到这个要删除的特殊节点
第二个过程:可以分为三种情况(左孩子为空、右孩子为空、左右孩子都不为空),根据不同情况进行删除。
假设我们现在已经得到了要删除节点的位置,该如何删除呢?
2.6.1. 第一种情况:被删除节点的右孩子为空
如图所示:我们要删除6号节点(其右孩子为空),该如何删除:
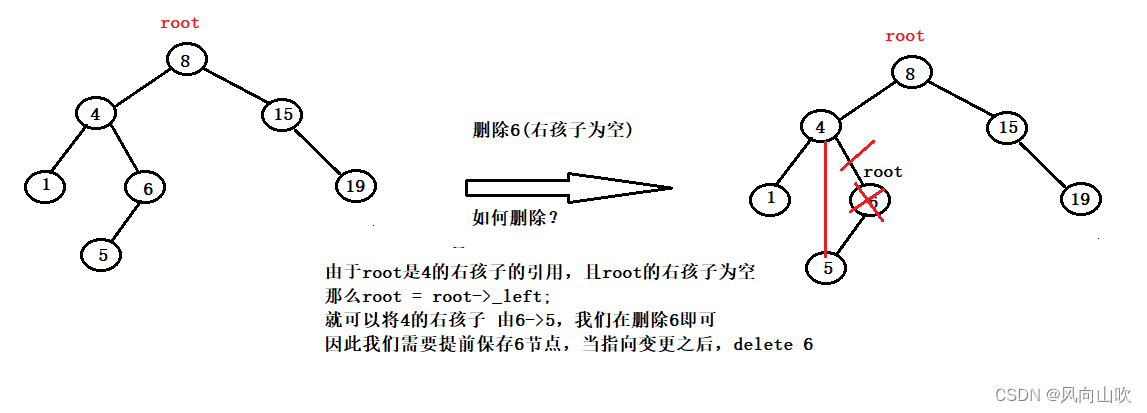
由于root是4的右孩子的引用,且root的右孩子为空
那么root = root->_left;
就可以将4的右孩子 由6->5,我们在删除6即可
因此我们需要提前保存6节点,当指向变更之后,delete 6
2.6.2. 第二种情况:被删除节点的左孩子为空
如图所示:我们要删除6号节点(其右孩子为空),该如何删除:
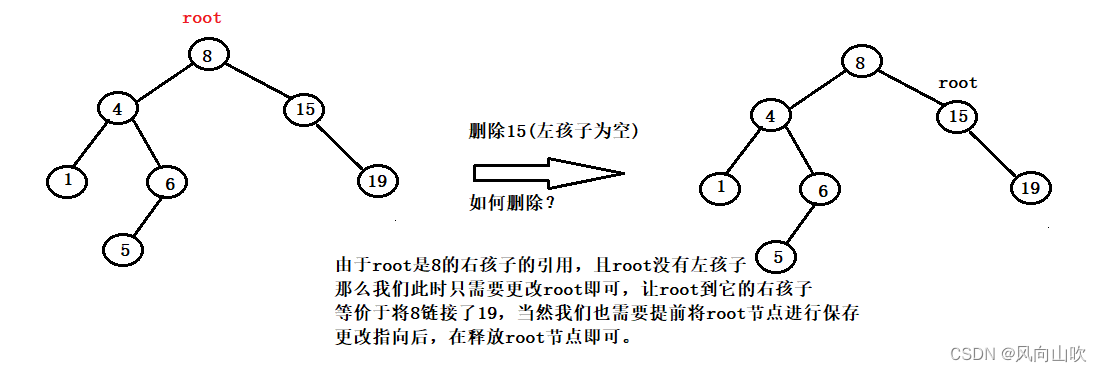
由于root是8的右孩子的引用,且root没有左孩子,那么我们此时只需要更改root即可,让root到它的右孩子,等价于将8链接了19,当然我们也需要提前将root节点进行保存,更改指向后,在释放root节点即可。
2.6.3. 第三种情况:被删除节点的左右孩子都不为空
较为复杂的就是第三种情况了,由于此时被删除节点有两个孩子。因此无法像上面两种情况进行处理。此时我们还是要利用循环实现的思路,(1):先找到左子树的最大节点or右子树的最小节点(我在这里称之为"合适节点")。然后我们可以(2):交换这个"合适结点"和被删除节点的key,(3):将删除原节点转化为删除我们后找的这个"合适节点"
在这里我们用实例说明,如下图所示:如果我要删除下图中的4,该如何删除?
我在这里实现的"合适节点"是: 左子树的最大节点
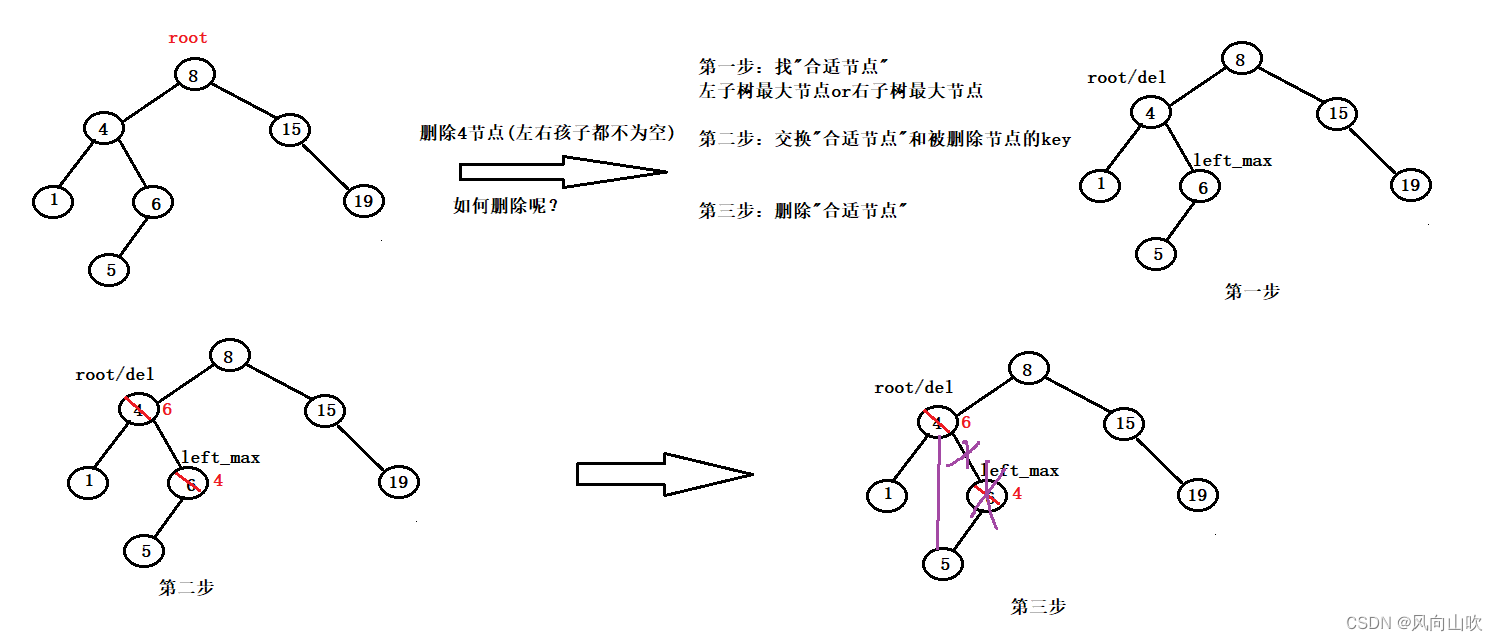
相信前两个过程是没有困难的,最后一步可能不好实现,但是当我们经过了前两个过程,我们发现被删除节点变成了我们找到的"合适节点",而且这个"合适节点"很有特征,如果它是左子树的最大值,那么它一定不会有右子树,反之,如果他是右子树的最小节点,那么它一定不会有左子树。因此我们可以在递归一次,如果"合适节点"是左子树的最大节点,那么我们递归树的左子树即可,反之如果是右子树的最小节点,那么我们递归树的右子树即可。
代码如下:
bool _erase_recursion(node*& root, const T& key)
{// 如果没有这个节点,返回false即可if (root == nullptr)return false;else{// 如果当前节点的key > 目标key,那么递归它的左子树即可if (root->_key > key){return _erase_recursion(root->_left, key);}// 如果当前节点的key < 目标key,那么递归它的右子树即可else if (root->_key < key){return _erase_recursion(root->_right, key);}// 如果找到了,进行删除else{// 提前保存被删除的节点,方便后面deletenode* del = root;//a. 右子树为空if (root->_right == nullptr){root = root->_left;}//b. 左子树为空else if (root->_left == nullptr){root = root->_right;}//c. 左右子树都不为空else{// 得到左子树的最大节点node* left_max = _root->_left;while (left_max->_right){left_max = left_max->_right;}// 交换"合适节点"和"被删除节点"的keystd::swap(left_max->_key, del->_key);// 在这里递归左子树即可return _erase_recursion(_root->_left, key);}delete del;del = nullptr;return true;}}
}2.7. 析构函数的实现
析构函数的实现我们依据的是后序的思想(LRN),先析构左子树、然后是右子树、最后才是根。这种实现的原因是是少了许多的记录信息,例如在这里我们就不用记录下一个节点。因为我们释放的就是当前的叶子节点。
具体实现如下:
~binary_search_tree()
{_bst_destroy(_root);
}
// 注意我们这里传递的是根的引用
void _bst_destroy(node*& root)
{if (root == nullptr)return;else{// 依据后序的思想_bst_destroy(root->_left);_bst_destroy(root->_right);delete root;root = nullptr;}
}2.8. copy constructor的实现
老生常谈的问题,如果我们没有显示实现拷贝构造函数,那么编译器默认生成的拷贝构造会对内置类型按照字节序的方式进行拷贝,对自定义类型成员属性会去调用它的拷贝构造函数。而字节序的方式进行拷贝会带来两个问题:
其一,其中一个对象的修改会影响另一个对象;
其二,同一空间会被析构两次,进程crash。
因此,我们在这里必须要实现深拷贝,那如何实现呢?我们可以借助前序的思想(NLR)。从根节点开始进行构造节点,然后递归构造它的左子树和右子树。注意构造的时候需要它们的链接关系。
代码如下:
binary_search_tree(const binary_search_tree<T>& copy)
{_root = _creat_new_root(copy._root);
}
node* _creat_new_root(node* root)
{// 如果遇到空了,就不用构造了if (root == nullptr)return nullptr;else{ // 根据前序的思想(NLR),依次构造它的根、左子树、右子树 // 同时将它们链接起来node* new_root = new node(root->_key);new_root->_left = _creat_new_root(root->_left);new_root->_right = _creat_new_root(root->_right);return new_root;}
}2.9. 赋值运算符重载
赋值运算符重载就比较简单了,因为我们已经实现了copy constructor,在这里利用传值传参会进行拷贝构造的特性实现我们的赋值
代码如下:
# 传值传参会进行拷贝构造
binary_search_tree<T>* operator=(binary_search_tree<T> copy)
{std::swap(_root, copy._root);return *this;
}2.10. 搜索二叉树的完整实现
#pragma once
#include <vector>
#include <iostream>
#include <queue>
#include <string>namespace Xq
{template<class T>struct binary_search_tree_node{binary_search_tree_node<T>* _left;binary_search_tree_node<T>* _right;T _key;binary_search_tree_node(const T& key):_left(nullptr), _right(nullptr), _key(key){}};template<typename T>class binary_search_tree{private:typedef binary_search_tree_node<T> node;public:binary_search_tree(node* root = nullptr):_root(root){}binary_search_tree(const binary_search_tree<T>& copy){_root = _creat_tree(copy._root);}binary_search_tree<T>& operator=(binary_search_tree<T> copy){std::swap(_root, copy._root);return *this;}// 由于类外不能访问_root,因此我们封装一层接口~binary_search_tree(){_destroy_tree(_root);}bool find(const T& key){//1. 从根节点开始node* cur = _root;while (cur != nullptr){//如果当前关键字大于目标关键字,那么向左子树走if (cur->_key > key)cur = cur->_left;// 如果小于目标关键字,那么向右子树走else if (cur->_key < key)cur = cur->_right;// 相等,就返回trueelsereturn true;}// 循环结束,说明没找到return false;}bool insert(const T& key){//1. 如果是空树,直接赋值即可,插入成功并返回trueif (_root == nullptr){_root = new node(key);return true;}//2. 找到key的合适位置//为了更好的链接插入的节点,我们需要记录cur的父节点node* cur = _root;node* cur_parent = nullptr;while (cur != nullptr){if (cur->_key > key){cur_parent = cur;cur = cur->_left;}else if (cur->_key < key){cur_parent = cur;cur = cur->_right;}else{//3. 走到这里说明,遇到了相同的key,那么不插入并返回falsereturn false;}}//4. 走到这里说明,找到了合适位置,需要插入,并完成链接关系,并返回truenode* newnode = new node(key);// 我们需要判断cur是parent的左节点还是右节点// 如果key小于parent的key,那么插入左节点if (key > cur_parent->_key)cur_parent->_right = newnode;// 反之链接到右节点elsecur_parent->_left = newnode;}bool insert_recursion(const T& key){return _insert_recursion(_root, key);}void level_order(){_level_order(_root);}bool erase(const T& key){node* cur = _root;node* cur_parent = nullptr;while (cur != nullptr){if (cur->_key > key){cur_parent = cur;cur = cur->_left;}else if (cur->_key < key){cur_parent = cur;cur = cur->_right;}else{//进行删除if (cur->_left == nullptr){//找到了被删除节点//第一种情况:所删除的节点的左孩子为空if (cur == _root){// 如果被删除节点是根,那么更新根即可node* newroot = cur->_right;delete cur;_root = newroot;}//被删除节点是非根节点else{if (cur_parent->_left == cur){cur_parent->_left = cur->_right;}else{cur_parent->_right = cur->_right;}delete cur;}}//第二种情况:所删除的节点的右孩子为空else if (cur->_right == nullptr){if (cur == _root){node* newroot = cur->_left;delete _root;_root = newroot;}else{if (cur_parent->_left == cur){cur_parent->_left = cur->_left;}else{cur_parent->_right = cur->_left;}delete cur;}}//第三种情况:所删除的节点有两个非空节点else{// 第一步:找左子树的最大节点or右子树的最小节点and它的父节点node* left_max = _root->_left;node* left_max_parent = _root;while (left_max->_right){left_max_parent = left_max;left_max = left_max->_right;}// 第二步: 覆盖被删除节点的keycur->_key = left_max->_key;// 第三步: 删除左子树的最大节点or右子树的最小节点// 注意:此时我们也需要根据父子关系决定怎么链接 if (left_max_parent->_left == left_max){left_max_parent->_left = left_max->_left;}else{left_max_parent->_right = left_max->_left;}delete left_max;left_max = nullptr;}return true;}}return false;}bool erase_recursion(const T& key){return _erase_recursion(_root, key);}private:// 注意我们这里是引用bool _insert_recursion(node*& root, const T& key){if (root == nullptr){// 需要我们插入新节点,这里的root就是root = new node(key);return true;}else{if (root->_key < key){_insert_recursion(root->_right, key);}else if (root->_key > key){_insert_recursion(root->_left, key);}else{return false;}}}void _level_order(node* root){std::queue<node*> Qu;if (root)Qu.push(root);while (!Qu.empty()){node* front = Qu.front();Qu.pop();if (front){Qu.push(front->_left);Qu.push(front->_right);}if (!front)std::cout << "N ";elsestd::cout << front->_key << " ";}std::cout << std::endl;}bool _erase_recursion(node*& root, const T& key){if (root == nullptr)return false;else{if (root->_key > key)return _erase_recursion(root->_left, key);else if (root->_key < key)return _erase_recursion(root->_right, key);else{node* del = root;if (root->_left == nullptr){root = root->_right;delete del;del = nullptr;}else if (root->_right == nullptr){root = root->_left;delete del;del = nullptr;}else{node* right_min = _root->_right;while (right_min->_left){right_min = right_min->_left;}std::swap(del->_key, right_min->_key);_erase_recursion(_root->_right, key);}return true;}}}node* _creat_tree(node* copy_root){if (copy_root == nullptr)return nullptr;else{// 根据前序的思想(NLR),注意链接关系node* newroot = new node(copy_root->_key);newroot->_left = _creat_tree(copy_root->_left);newroot->_right = _creat_tree(copy_root->_right);return newroot;}}// 注意这里是引用void _destroy_tree(node*& root){if (root == nullptr)return;else{// 根据后序的思想_destroy_tree(root->_left);_destroy_tree(root->_right);delete root;root = nullptr;}}private:node* _root;};
}3.二叉树搜索树应用分析
3.1. K模型 && KV模型
二叉搜索树的应用:
1. K模型 --- 在不在的问题, K模型即只有key作为关键码,结构中只需要存储Key即可,关键码即为需要搜索到的值,解决的是在不在的问题
比如:给一个单词 word ,判断该单词是否拼写正确,具体方式如下:以词库中所有单词集合中的每个单词作为key,构建一棵二叉搜索树 ,在二叉搜索树中检索该单词是否存在,存在则拼写正确,不存在则拼写错误。还有我们日常生活中的门禁系统、车库系统等等。2:KV模型 --- 通过一个值查找另一个值,每一个关键码key,都有与之对应的值Value,即<Key, Value>的键值对。该种方式在现实生活中非常常见:
比如英汉词典就是英文与中文的对应关系,通过英文可以快速找到与其对应的中文,英文单词与其对应的中文<word, chinese>就构成一种键值对;再比如统计单词次数 ,统计成功后,给定单词就可快速找到其出现的次数,单词与其出现次数就是<word, count>就构成一种键值对
KV模型,假如我现在要实现简易版的英汉词典,通过英文单词,查询对应的中文,这时候我们的搜索二叉树的每个节点就是<key,value>的键值对,通过key查找我们的value:
namespace key_value
{template<class T, typename V>struct binary_search_tree_node{binary_search_tree_node<T, V>* _left;binary_search_tree_node<T, V>* _right;T _key;V _value;binary_search_tree_node(const T& key = T(), const V& value = V()):_left(nullptr), _right(nullptr), _key(key), _value(value){}};template<typename T, class V>class binary_search_tree{private:typedef binary_search_tree_node<T, V> node;public:binary_search_tree(node* root = nullptr):_root(root){}~binary_search_tree(){_destroy_tree(_root);}node* find(const T& key){node* cur = _root;while (cur){if (cur->_key < key)cur = cur->_right;else if (cur->_key > key)cur = cur->_left;elsereturn cur;}return nullptr;}bool insert(const T& key, const V& value){if (_root == nullptr){_root = new node(key, value);return true;}node* cur = _root;node* cur_parent = nullptr;while (cur != nullptr){if (cur->_key > key){cur_parent = cur;cur = cur->_left;}else if (cur->_key < key){cur_parent = cur;cur = cur->_right;}else{return false;}}node* newnode = new node(key, value);if (key > cur_parent->_key)cur_parent->_right = newnode;elsecur_parent->_left = newnode;}void level_order(){_level_order(_root);}bool erase(const T& key){node* cur = _root;node* cur_parent = nullptr;while (cur != nullptr){if (cur->_key > key){cur_parent = cur;cur = cur->_left;}else if (cur->_key < key){cur_parent = cur;cur = cur->_right;}else{//进行删除if (cur->_left == nullptr){if (cur == _root){node* newroot = cur->_right;delete cur;_root = newroot;}else{if (cur_parent->_left == cur){cur_parent->_left = cur->_right;}else{cur_parent->_right = cur->_right;}delete cur;}}else if (cur->_right == nullptr){if (cur == _root){node* newroot = cur->_left;delete _root;_root = newroot;}else{if (cur_parent->_left == cur){cur_parent->_left = cur->_left;}else{cur_parent->_right = cur->_left;}delete cur;}}else{node* left_max = _root->_left;node* left_max_parent = _root;while (left_max->_right){left_max_parent = left_max;left_max = left_max->_right;}cur->_key = left_max->_key;if (left_max_parent->_left == left_max){left_max_parent->_left = left_max->_left;}else{left_max_parent->_right = left_max->_left;}delete left_max;left_max = nullptr;}return true;}}return false;}void _level_order(node* root){std::queue<node*> Qu;if(root)Qu.push(root);while(!Qu.empty()){node* front = Qu.front();Qu.pop();if(front->_left)Qu.push(front->_left);if(front->_right)Qu.push(front->_right);if(!front)std::cout << "N ";elsestd::cout << front->_key << " " << front->_value << std::endl;}std::cout << std::endl;}void _destroy_tree(node*& root){if (root == nullptr)return;else{_destroy_tree(root->_left);_destroy_tree(root->_right);delete root;root = nullptr;}}private:node* _root;};
}void Test6(void)
{ // 这就是我们的KV模型,通过我们的单词可以查到对应的中文key_value::binary_search_tree<std::string, std::string> dict;dict.insert("left", "左边");dict.insert("right", "右边");dict.insert("superman", "超人");dict.insert("step", "步骤");std::string str;while (std::cin >> str){key_value::binary_search_tree_node<std::string, std::string>* ret = dict.find(str);if (ret == nullptr)std::cout << "没有此单词" << std::endl;elsestd::cout << ": " << ret->_value << std::endl;}} int main()
{Test1();return 0;
}假如我现在要实现统计动物园中不同动物的个数呢?
其实这也是一个KV模型,只不过这里的V是动物的个数,实现如下:
void Test7(void)
{key_value::binary_search_tree<std::string, size_t> animals_size;std::string str[6] = { "狮子", "老虎", "猴子", "猩猩", "大熊猫", "黑熊" };srand((size_t)time(nullptr));int count = 10;while (count--){std::string arr = str[rand() % 6];key_value::binary_search_tree_node<std::string, size_t>* ret = animals_size.find(arr);if (ret == nullptr){animals_size.insert(arr, 1);}else{++ret->_value;}}animals_size.level_order();
}
3.2. 二叉搜索树的性能分析
相信经过我们前面对于BST的模拟实现,我们对于增删查改有了一定的理解。我们可能会认为它们的时间复杂度就是O(logN),但是呢,这只是较好的情况或者称之为一般情况,
什么意思呢?就是当这棵二叉树是较为均衡的一棵二叉树,那么它的增删查改时间复杂度的确是O(logN),但是如果是下面这棵树呢?

可以看到,这棵树是一棵"歪脖子树",它只有左子树,没有右子树,那么此时对于这棵树而言,他的增删查改就变成了O(N),也就是说,对于普通的搜索二叉树的增删查改的时间复杂度我们认为是O(N)(最坏情况)。
因此,为了避免这种最坏情况,我们需要调整搜索二叉树的结构,让它避免产生这种结构。
4. 二叉树进阶面试题
4.1. 根据一棵树的前序遍历与中序遍历构造二叉树
105. 从前序与中序遍历序列构造二叉树 - 力扣(LeetCode)
思路:前序NLR 中序 LNR,因此前序可以确立根,中序可以分割左右子区间。
Solution:
Step 1: 通过前序确定根
Step 2: 通过中序分割左右子区间:
由于前序确定的根,那么在中序中根左边的元素在左子树、在根右边的元素在右子树
Step 3: 递归子问题
通过递归左右子树,并通过返回值链接它们
class Solution {
public:TreeNode* _build_tree(std::vector<int>& pre_order,std::vector<int> in_order,int& pre_index, int in_begin,int in_end){// 注意,如果是非法区间,返回nullptr// 参数解释: pre_index是前序的下标,由于我们需要在每个子问题上都是同一个值,因此这里使用引用// in_begin 和 in_end 分别是中序区间的开始和结束if(in_begin > in_end)return nullptr;// 因为pre_order.length >= 1,因此没有空表,直接构造根节点,前序的第一个elements就是root//1. 前序确定根TreeNode* root = new TreeNode(pre_order[pre_index++]);//2. 中序分割左右子区间//a. 找根int in_index = in_begin;//b. 分割左右子区间// 区间被分为 [in_begin,in_index-1] in_index [in_index+1,in_end]while(in_order[in_index] != pre_order[pre_index-1])++in_index;//3. 递归子问题root->left = _build_tree(pre_order,in_order,pre_index,in_begin,in_index-1);root->right = _build_tree(pre_order,in_order,pre_index,in_index+1,in_end);//4. 返回根return root;}TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {int pre_index = 0;return _build_tree(preorder,inorder,pre_index,0,inorder.size()-1);}
};4.2. 根据一棵树的中序遍历与后序遍历构造二叉树
106. 从中序与后序遍历序列构造二叉树 - 力扣(LeetCode)
思路:后续确定根,中序分割左右子树
由于题目明确了没有重复元素。
Solution:
Step 1: 通过后续确定根
Step 2: 通过中序分割左右子树
Step 3: 递归子问题,并通过返回值链接它们
由于我们是后序(LRN)确立根,因此递归子问题时需要先递归右子树、在递归左子树
class Solution {
public:TreeNode* _build_tree(std::vector<int>& in_order,std::vector<int>& post_order,int& post_index,int in_begin, int in_end){// 注意: 对于非法的子区间,直接返回nullptrif(in_begin > in_end)return nullptr;//1. 后序确定根,题干明确了不可能为空表,因此直接构造根TreeNode* root = new TreeNode(post_order[post_index--]);//2. 根据根,分割中序的左右区间int in_index = in_begin;while(post_order[post_index+1] != in_order[in_index])++in_index;// 将左右子树分为 [in_begin,in_index-1] in_index [in_index+1,in_end]//3. 递归子问题//注意: 因为我们是后序确立根(LRN),因此需要先递归右子树、在递归左子树root->right = _build_tree(in_order,post_order,post_index,in_index+1,in_end);root->left = _build_tree(in_order,post_order,post_index,in_begin,in_index-1);//4. 返回根return root;}TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {int post_index = postorder.size() - 1;return _build_tree(inorder,postorder,post_index,0,inorder.size()-1);}
};4.3. 二叉树的前序遍历 --- 非递归
144. 二叉树的前序遍历 - 力扣(LeetCode)
思路:
前序的非递归解决方法是将一颗树分为:
左路节点
左路节点的右子树
step 1: 先将左路节点同时入栈和vector(目的是为了访问左路节点的右子树)
step 2: 取栈顶数据,出栈,访问右子树。继续重复step1的过程
注意:如果树不为空或者栈不为空就继续,树不为空说明树还有数据,栈不为空说明有可能还有右子树没有被访问
class Solution {
public:void _pre_order(TreeNode* root,std::vector<int>& v,std::stack<TreeNode*>& st){TreeNode* cur = root;// 树还有数据 或者 栈还有数据就继续while(cur || !st.empty()){// 将左路节点分别入栈、vector中,栈中数据的目的是为了获得我们的右子树while(cur){v.push_back(cur->val);st.push(cur);cur = cur->left;}// 去栈顶数据TreeNode* top = st.top();st.pop();// 遍历我们的右子树cur = top->right; }}vector<int> preorderTraversal(TreeNode* root) {std::vector<int> v;std::stack<TreeNode*> st;_pre_order(root,v,st);return v;}
};4.4. 二叉树的中序遍历 --- 非递归
思路:根据中序的思想(LNR),我们的迭代写法:
Step 1: 先向栈入左路节点
Step 2: 取栈顶数据入vector,pop栈顶数据,如果栈顶数据的右子树不为空,终止循环,向栈入右子树的左路节点(重复Step 1)
从栈里面取左路节点,意味着这个节点的左子树被访问完了,因此要访问右子树的左路节点。
class Solution {
public:vector<int> inorderTraversal(TreeNode* root) {std::vector<int> v;if(nullptr == root) return v;std::stack<TreeNode*> st;TreeNode* cur = root;// 树还有数据 || 栈不为空while(cur || !st.empty()){// 先向栈入左路节点while(cur){st.push(cur);cur = cur->left;}// 取栈顶数据,入vector,如果栈顶数据的右节点不为空,终止循环,继续向栈入右子树的左路节点//从栈里面取左路节点,意味着这个节点的左子树被访问完了,因此要访问右子树的左路节点。while(!st.empty()){TreeNode* top= st.top();st.pop();v.push_back(top->val);if(top->right){cur = top->right;break;}}}return v;}
};4.5. 二叉树的后序遍历 --- 非递归
思路:通过栈存储左路节点,用两个vector,第一个vector存储后序遍历的节点(为了判断某个节点的右子树是否被访问过),第二个vector存储后序遍历的节点的val(用于返回结果);
如何判断某个节点的右子树被访问过?
只要这个节点的右子树 == 存储后序遍历节点的vector的back(),那么就意味着这个节点的右子树已经被访问过了,此时只需要将这个节点分别push到两个vector中,并pop栈顶数据(就是这个节点),进入下一次循环即可
只要某个节点的右树为空树,那么就将这个结点分别push到两个vector中;否则,入右树的左路节点。
class Solution {
public:vector<int> postorderTraversal(TreeNode* root) {// 存储后序节点中的val的vectorstd::vector<int> v;if(nullptr == root) return v;// 存储左路节点的栈std::stack<TreeNode*> st;// 存储后序节点的vectorstd::vector<TreeNode*> v_node;TreeNode* cur = root;// 如果树还有数据 || 栈还有左路节点,那么就继续while(cur || !st.empty()){// 入左路节点while(cur){st.push(cur);cur = cur->left;}// 走到这里说明,左路节点走完了,需要走左路节点的右子树while(!st.empty()){// 取栈顶的数据TreeNode* top = st.top();// 如果栈顶数据的右子树已经被访问过了,那么此时直接将栈顶数据push到vector中,// 并把这个栈顶数据给pop掉,进行下一次循环// 我们在这里用了一个vector存储右子树的节点,只要这个vector的back()是栈顶数据的右子树// 那么就代表栈顶数据的右子树已经被访问过了if(!v_node.empty() && top->right == v_node.back()){v.push_back(top->val);v_node.push_back(top);st.pop();continue;}// 如果栈顶数据的右子树为空,那么就push到vector中if(!top->right){st.pop();v.push_back(top->val);v_node.push_back(top);}// 否则,就去入右子树的左路节点else{cur = top->right;break;}}}return v;}
};4.6. 二叉树的层序遍历
102. 二叉树的层序遍历 - 力扣(LeetCode)
思路:将每一层的数据都push进队列中,队列的大小就是当前层数的个数(因为当pop掉cur层的最后一个数据时,那么也意味着cur的下一层的数据都进入了队列中,此时队列的大小就是当前层数的元素个数 )。通过每一层的个数控制每一次的循环次数
class Solution {
public:vector<vector<int>> levelOrder(TreeNode* root) {std::vector<std::vector<int>> vv;if(root == nullptr) return vv;else{// 每层的元素个数int level_size = 0;std::queue<TreeNode*> qu;// 因为此时root != nullptr,因此直接push队列中qu.push(root);++level_size;// 只要队列还有数据,就继续while(!qu.empty()){std::vector<int> v;while(level_size--){TreeNode* front = qu.front();qu.pop();v.push_back(front->val);if(front->left)qu.push(front->left);if(front->right)qu.push(front->right);}// 当前层数的元素个数 = 队列的大小level_size = qu.size();vv.push_back(v);}}return vv;}
};4.7. 二叉树的层序遍历Ⅱ
107. 二叉树的层序遍历 II - 力扣(LeetCode)
思路:这是4.4.的变形题,但是如果我们解决了4.4,那么这里就很简单了,我们按照4.4.的思路得到结果,只需要逆置下该结果即可。
class Solution {
public:vector<vector<int>> levelOrderBottom(TreeNode* root) {std::vector<std::vector<int>> vv;if(root == nullptr) return vv;else{// 每层的元素个数int level_size = 0;std::queue<TreeNode*> qu;// 因为此时root != nullptr,因此直接push队列中qu.push(root);++level_size;// 只要队列还有数据,就继续while(!qu.empty()){std::vector<int> v;while(level_size--){TreeNode* front = qu.front();qu.pop();v.push_back(front->val);if(front->left)qu.push(front->left);if(front->right)qu.push(front->right);}// 当前层数的元素个数 = 队列的大小level_size = qu.size();vv.push_back(v);}}// 逆置结果即可std::reverse(vv.begin(),vv.end());return vv;}
};4.8. 二叉树的最近公共祖先
236. 二叉树的最近公共祖先 - 力扣(LeetCode)
思路一:如果这是一个三叉链(每个节点有parent),我们可以转化为链表相交问题。但是很抱歉,这里并不是三叉链,因此这种解决方案不可行。
思路二:通过两个目标节点的所在位置进行判断:
case 1: 只要一个节点是根,那么根就是公共祖先
case 2: 如果一个在我的左子树,一个在我的右子树,那么我就是公共祖先
case 3: 如果两个都在我的左树,递归子问题(递归左树)
case 4: 如果两个都在我的右树,递归子问题(递归右树)
时间复杂度为O(N^2)
只有满二叉树或者完全二叉树我们可以认为高度是logN,因为会有歪脖子树
优化思路:如果是搜索二叉树可以优化到O(N)
一个比根小,一个比根大,根就是最近公共祖先
思路三:用DFS(在这里我们用前序遍历)求出p和q的路径并分别将从根节点到目标节点的路径入栈,将该问题转化为链表相交问题
注意:入栈可以依据前序的思想,如果遇到了就return true即可,如果没有遇到,递归左子树和递归右子树,如果左子树、右子树都为空,那么返回false
时间复杂度是O(N)
4.8.1. 第二种思路实现
class Solution {
public:bool is_exist_node(TreeNode* root, TreeNode* obj){if(root == nullptr) return false;else{return root == obj|| is_exist_node(root->left,obj)|| is_exist_node(root->right,obj);}}TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {//只要一个节点是根,那么根就是最近公共祖先if(p == root || q == root) return root;// 因为p不是根,因此p要么在左树,要么在右树bool p_left = is_exist_node(root->left,p);bool p_right = !p_left;// 同理, q要么在左树,要么在右树bool q_right = is_exist_node(root->right,q);bool q_left = !q_right;// 如果p在左且q在右 或者 p在右且q在左,那么最近公共祖先是rootif((p_left && q_right) || (p_right && q_left))return root;// 如果p和q都在左树,那么递归左树if(p_left && q_left)return lowestCommonAncestor(root->left,p,q);// 如果p和q都在右树,那么递归右树else return lowestCommonAncestor(root->right,p,q);}
};4.8.2. 第三种思路实现
class Solution {
public:bool get_path(TreeNode* root, TreeNode* obj,std::stack<TreeNode*>& st){// 依据前序的思想if(root == nullptr)return false;else{// 无脑入根st.push(root);// 如果找到了,就返回trueif(root == obj)return true;bool ret = get_path(root->left,obj,st);// 如果没找到继续递归if(!ret)ret = get_path(root->right,obj,st);// 如果左右子树都找了且没找到,那么说明obj不在该路径,pop栈顶元素if(!ret)st.pop();return ret;}}TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {std::stack<TreeNode*> p_st;std::stack<TreeNode*> q_st;get_path(root,p,p_st);get_path(root,q,q_st);// 将求最近公共祖先的问题转化了"链表相交"问题// "链表相交"问题: 长的先走差距步,然后同时走,相等就是相交节点while(p_st.size() != q_st.size()){if(p_st.size() > q_st.size())p_st.pop();elseq_st.pop();}while(!p_st.empty() && !q_st.empty() && (p_st.top() != q_st.top())){p_st.pop();q_st.pop();}return p_st.top();}
};4.9. 二叉搜素树和双向链表
二叉搜索树与双向链表_牛客题霸_牛客网 (nowcoder.com)
思路:
利用中序的前驱节点和后继结点,
cur的前驱节点是prev,prev的后继节点是cur
即cur的left指向它的前驱节点;
如果前驱节点不为空,那么prev的后继节点指向cur
注意:cur需要保持唯一性(同一个prev),需要带引用。
例如:
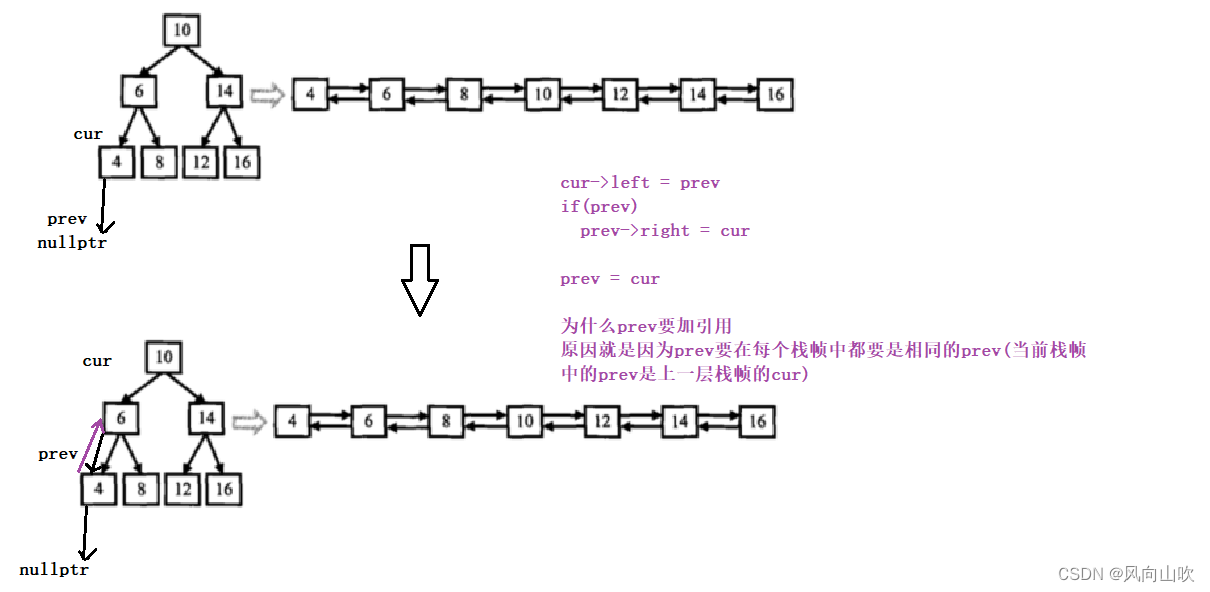
class Solution {
public:void _tree_to_become_list(TreeNode* cur,TreeNode*& prev){if(cur == nullptr)return ;else{// 依据中序的思想LNR_tree_to_become_list(cur->left, prev);// cur的left指向前驱节点prev,prev的right指向后继节点curcur->left = prev;if(prev)prev->right = cur;prev = cur;_tree_to_become_list(cur->right, prev);}}TreeNode* Convert(TreeNode* pRootOfTree) {// 如果是空树,直接返回nullptrif(pRootOfTree == nullptr)return nullptr;TreeNode* prev = nullptr;_tree_to_become_list(pRootOfTree, prev);TreeNode* head = pRootOfTree;// 找链表的头节点while(head->left)head = head->left;return head;}4.10. 二叉树创建字符串
题意:通过前序构造字符串。
注意,空节点要使用(),但是题干告诉我们有些括号会省略,但是如下情况不能省略:
case 1:如果左不为空,不能省略。
case 2:左树为空且右树不为空,括号不能省略。
case 3:右树不为空,括号不能省略
class Solution {
public:string tree2str(TreeNode* root) {if(root == nullptr)return "";else{std::string str = std::to_string(root->val);// if(root->left || root->right) if(root->left != nullptr || (root->left == nullptr && root->right != nullptr))// 左树不为空 或者 左树为空且右树不为空, 左树的括号不能省略{str += '(';str += tree2str(root->left);str += ')';}// 右树不为空,右树的括号不能省略if(root->right) {str += '(';str += tree2str(root->right);str += ')';}return str;}}
};