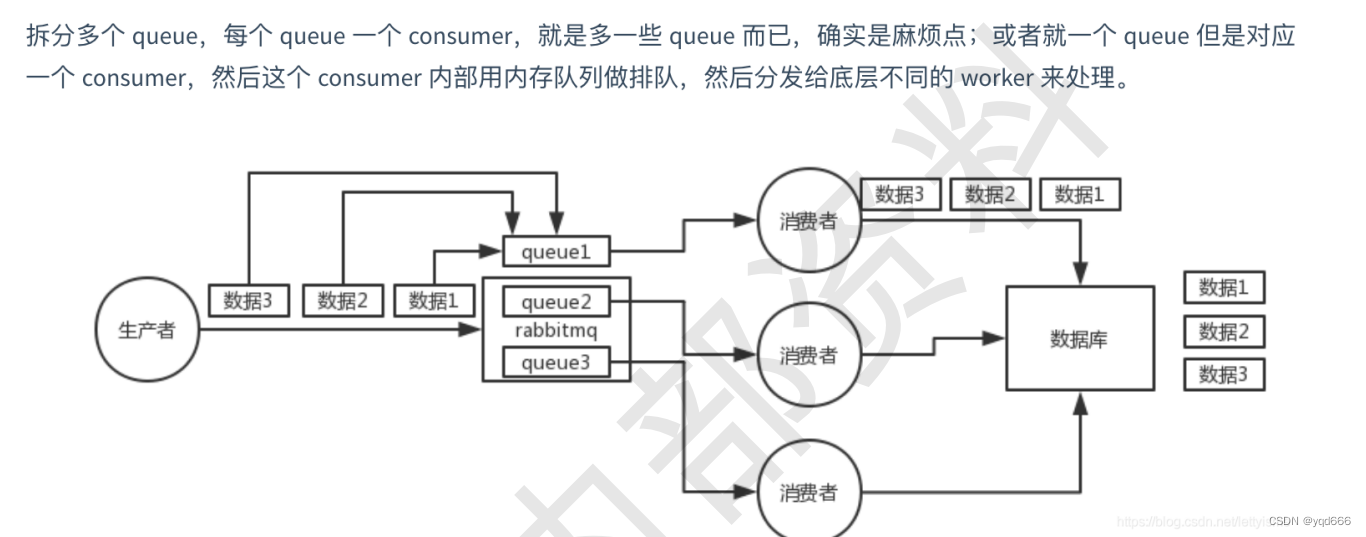
Python量化炒股的财务因子选股-财务因子选股
选股是股市投资的第一步,是最基础的一步,也是最重要的一步。
初识财务因子选股
量化选股是利用数量化的方法选择股票组合,期望该股票组合能够获得超越基准收益率的投资行为。总的来说,量化选股可分为两类,分别是基本面选股和技术面选股。
在实际股票投资中,往往利用基本面选出要操作的股票,放入自选股中,然后根据技术面来确定交易的时机,即根据技术判断来确定何时买入、何时加仓、何时减仓、何时全部卖出。
在基本面选股中,最常用的选股方法是财务因子选股。财务因子选股可以进一步分4类,分别是成长类因子选股、规模类因子选股、价值类因子选股和质量因子选股。
成长类因子选股
在Python财务因子量化选股中,成长类因为有6个,分别是营业收入同比增长率、营业收入环比增长率、净利润同比增长率、净利润环比增长率、营业利润率、销售净利率和销售毛利率。
需要注意的是,成长类因子都在财务指标数据表indicator中。
营业收入同比增长率(inc_revenue_year_on_year)选股
营业收入是指在一定时期内,企业销售商品或提供劳务所获得的货币收入,如商业企业的商品销售收入、生产加工企业的产品销售收入、饮食业的饮食品销售收入、服务业的服务收入、仓储企业的仓储收入、运输企业的运费收入、代办运输收入等。营业收入的计算公式如下:
营业收入 = 主营业务收入 + 其他业务收入
或营业收入 = 产品销售量(或服务量)x 产品单价(或服务单价)
主副产品(或不同等级产品)的销售收入应全部计入营业收入,所提供的不同类型服务收入也应计入营业收入。营业收入同比增长率是指企业在一定期间内取得营业收入与其上年同期营业收入的增长的百分比,以反映企业在此期间内营业收入的增长或下降等情况。营业收入同比增长率计算公诉如下:
营业收入同比增长率 = (当期营业收入 - 上期营业收入)➗ 上期营业收入 ✖️ 100%
当期营业收入按使用者的需要可以是月度、季度或年度,也可以是会计年度起始日至会计报表截止日,如2019年1月1日至2019年9月30日等。另外,也可以是分析者采用的年化数据,如2018年10月1日至2019年9月30日。
上期营业收入是指与当期营业收入相对应的上一个年度此期间的营业收入。营业收入同比增长率越大,说明企业当期获得的营业收入相对去年同期增长越大,对企业盈利有正面影响,而营业收入同比增长率为负时,则表明企业营业收入出现下降,应引起企业管理者或投资者的注意。
连续地观察营业收入同比增长率的历史趋势,可以反映出企业的营业收入在不同的会计期间其增长变化的情况,对后期的预测带来一定的帮助。
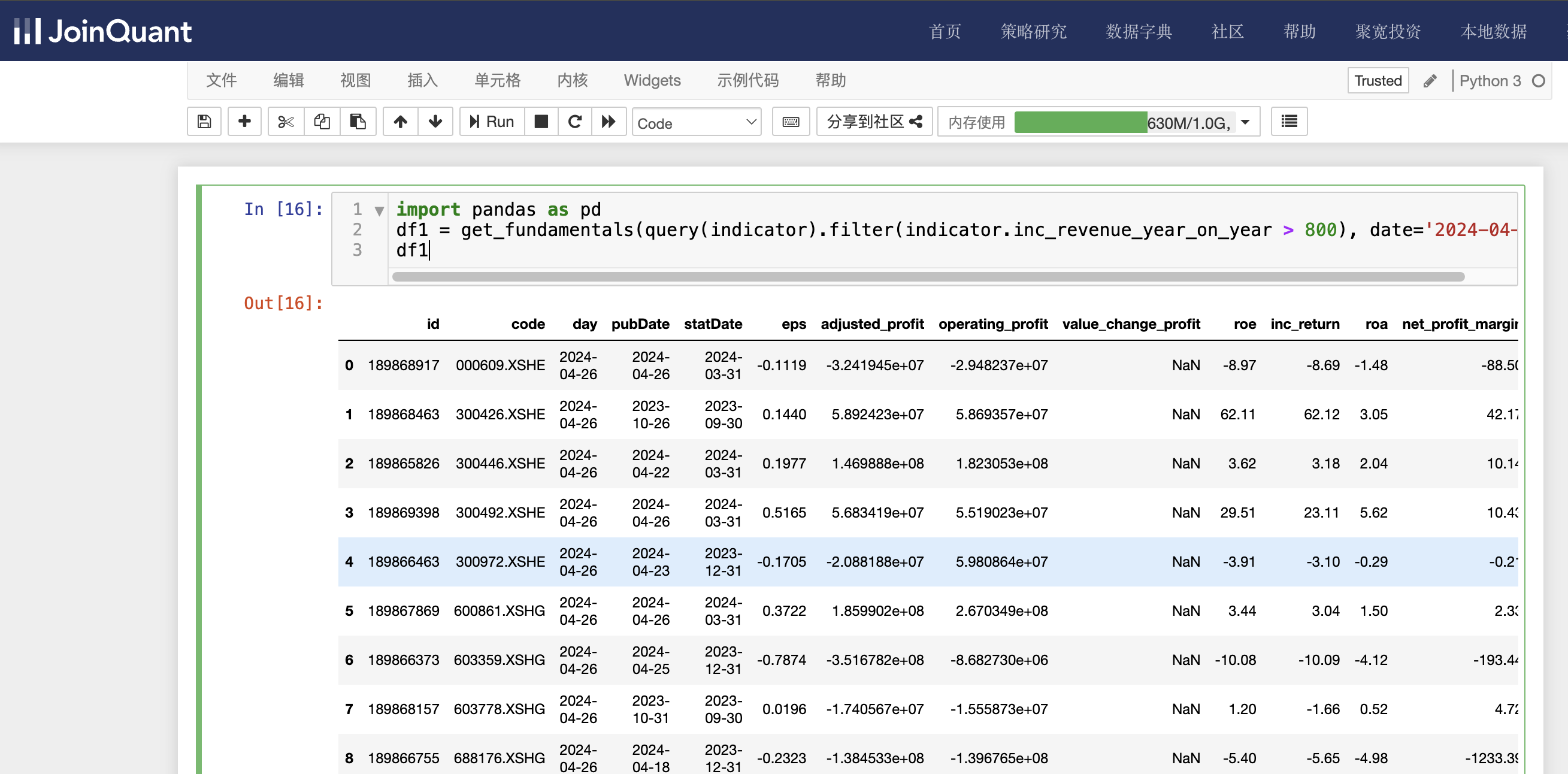
单击聚宽JoinQuant量化炒股平台中的“策略研究/研究环境”命令,进入Jupyter Notebook的研究平台。然后单击“新建”按钮,创建Python3文件,输入如下代码:
import pandas as pd
df1 = get_fundamentals(query(indicator).filter(indicator.inc_revenue_year_on_year > 800), date='2024-04-26')
df1
首先导入Pandas包,并设置名为pd,然后调用get_fundamentals()函数获取财务指标数据,返回值dataframe。indicator为财务指标数据表名,查询条件时营业收入同比增长率大于800,即indicator.inc_revenue_year_on_year > 800,时间为2024-04-26。
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
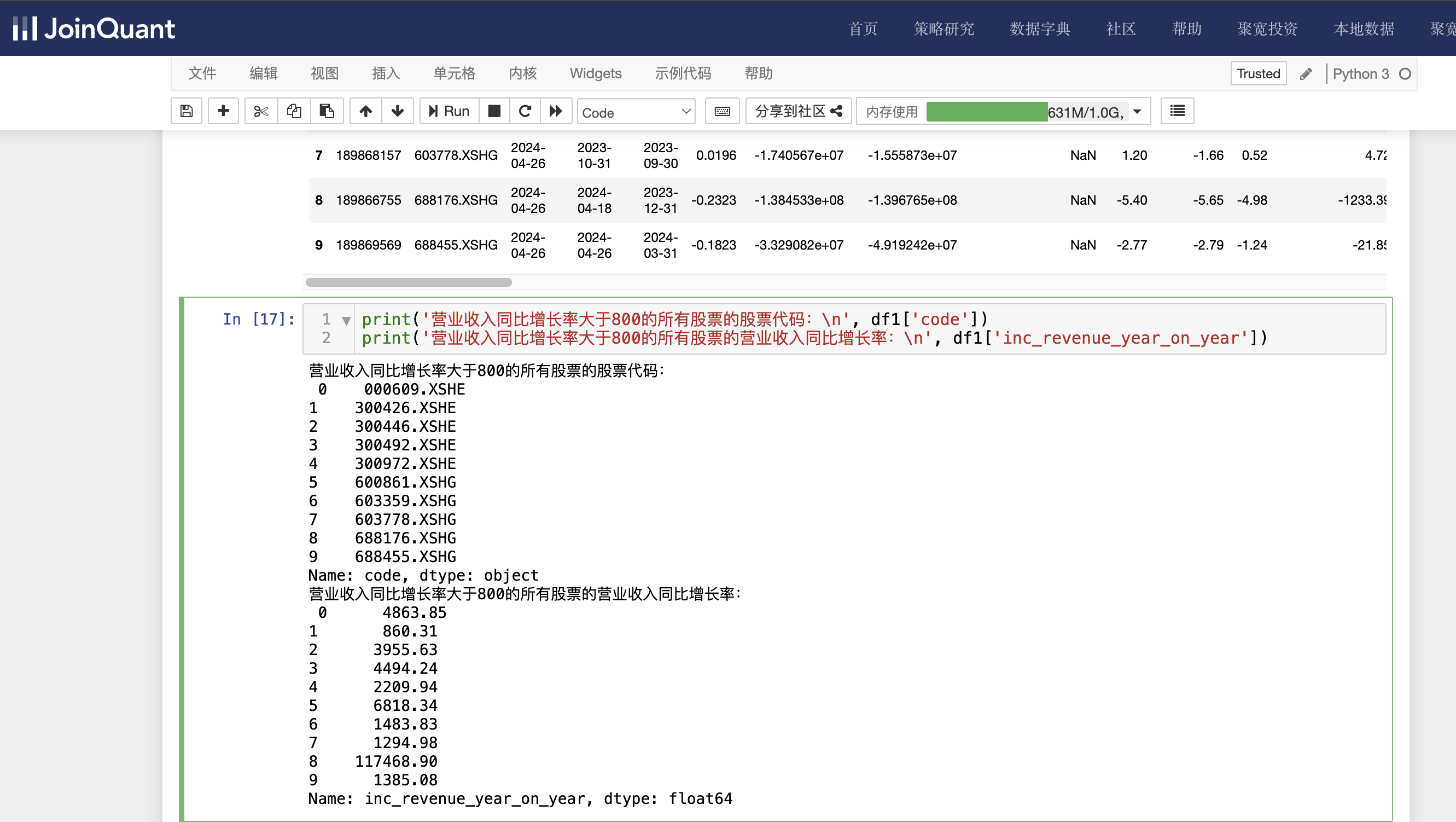
显示营业收入同比增长率大于800的所有股票的股票代码和营业收入同比增长率,具体代码如下:
print('营业收入同比增长率大于800的所有股票的股票代码:\n', df1['code'])
print('营业收入同比增长率大于800的所有股票的营业收入同比增长率:\n', df1['inc_revenue_year_on_year'])
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
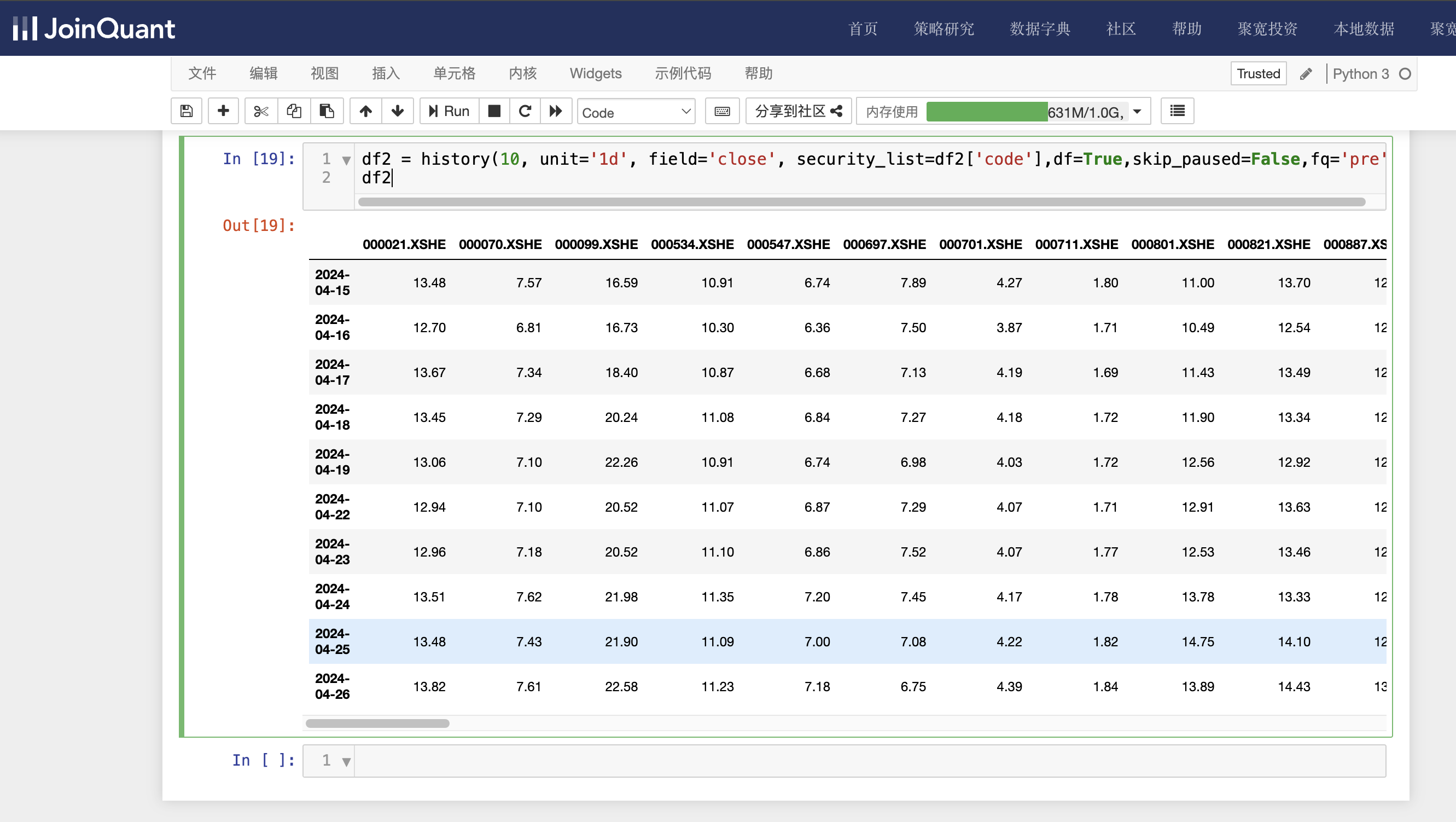
显示营业收入同比增长率大于800的股票近10个交易日的收盘价信息,具体代码如下:
df2 = history(10, unit='1d', field='close', security_list=df2['code'],df=True,skip_paused=False,fq='pre')
df2
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
营业收入环比增长率(inc_revenue_annual)选股
营业收入环比增长率 =(本期营业收入的值 - 上一期营业收入的值)➗上一期营业收入的值✖️100%
需要注意的是,环比增长率是相对于上一期的,而同比增长率是相对于上一年度的同一期的。
单击聚宽JoinQuant量化炒股平台中的“策略研究/研究环境”命令,进入Jupyer Notebook的研究平台。然后单击“新建”按钮,创建Python3文件,接着输入如下代码:
import pandas as pd
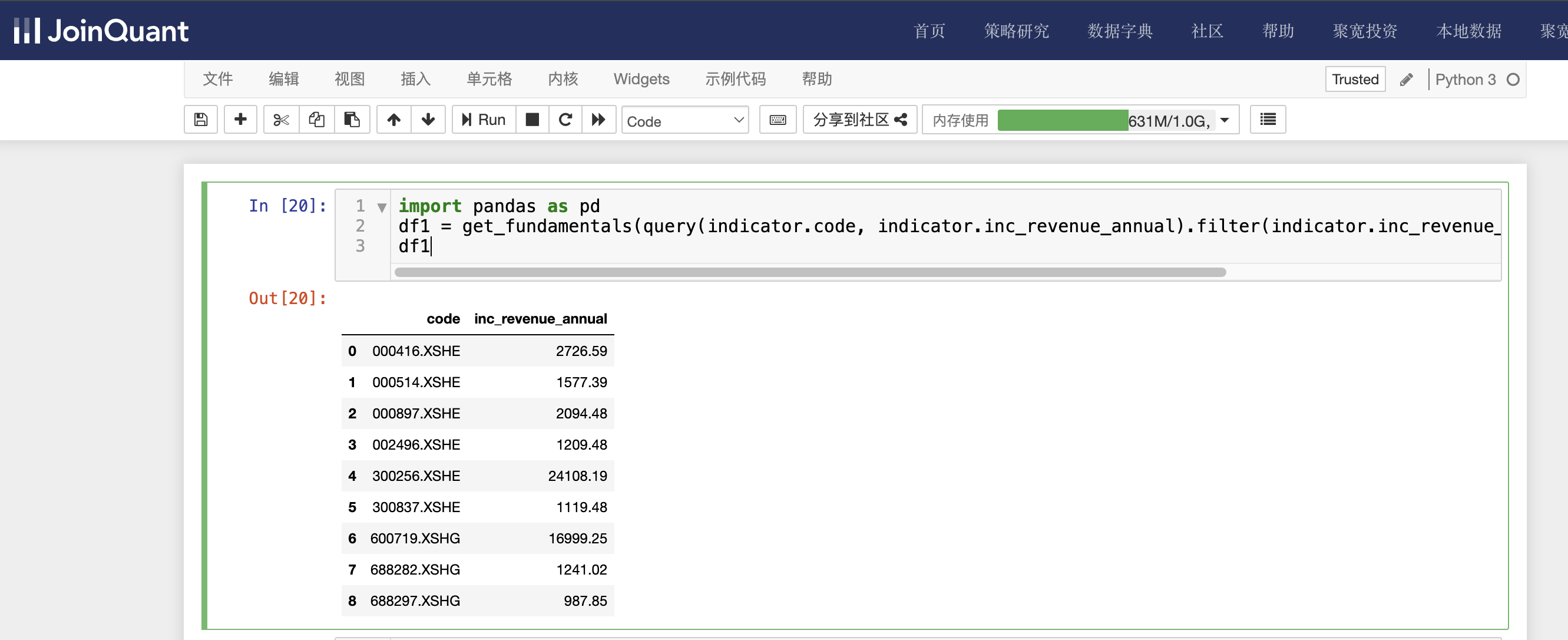
df1 = get_fundamentals(query(indicator.code, indicator.inc_revenue_annual).filter(indicator.inc_revenue_annual > 900), date='2024-04-26')
df1
查询条件是营业收入环比增长率大于900,即indicator.inc_revenue_annual > 900,时间为2024年04月26日。需要注意的是,这里只显示了股票代码和股票的营业收入环比增长率。
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
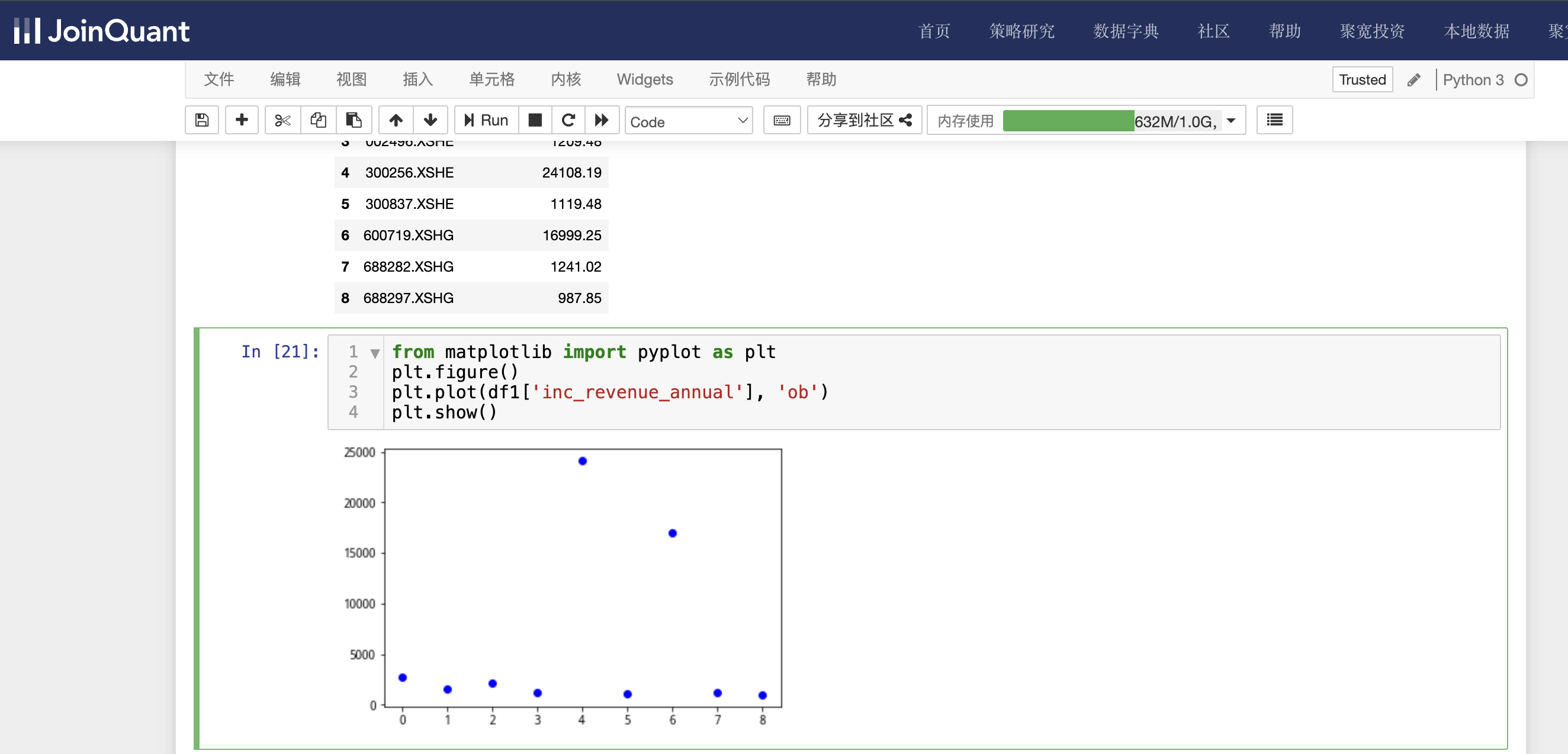
利用图表显示营业收入环比增长率大于900的营业收入环比增长率,具体代码如下:
from matplotlib import pyplot as plt
plt.figure()
plt.plot(df1['inc_revenue_annual'], 'ob')
plt.show()
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
净利润同比增长率(inc_net_profit_year_on_year)选股
净利润是指企业当期利润总额减去所得税后的金额,即企业的税后利润。净利润是一个企业经营的最终成果。净利润多,企业的经营效益就好;净利润小,企业的经营效益就差。它是衡量一个企业经营效益的主要目标。
净利润同比增长率低计算公式如下:
净利润同比增长率 = (当期净利润 - 上期净利润)➗ 上期净利润低绝对值✖️100%
单击聚宽JoinQuant量化炒股平台中的“策略研究/研究环境”命令,进入Jupyter Notebook的研究平台。然后单击“新建”按钮,创建Python3文件,接着输入如下代码:
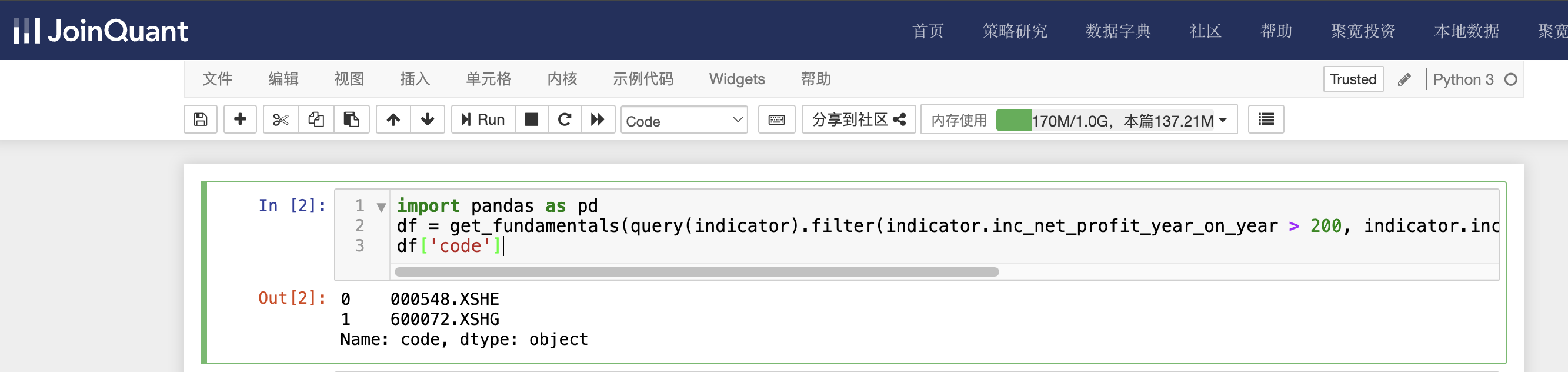
import pandas as pd
df = get_fundamentals(query(indicator).filter(indicator.inc_net_profit_year_on_year > 200, indicator.inc_revenue_year_on_year > 300, indicator.inc_revenue_annual > 300), date='2024-04-26')
df['code']
indicator为财务指标数据表名,查询条件有3个,分别是净利润同比增长率大于200, 营业收入同比增长率大于300,营业收入环比增长率大于300。时间为2024-04-26。这里只显示选出股票的代码。
单击工具栏中的运行按钮,快捷键(shift+enter),运行结果如下图:
净利润环比增长率(inc_net_profit_annual)选股
净利润环比增长率 = (本期净利润的值 = 上一期净利润的值)➗ 上一期净利润的值的绝对值 ✖️ 100%
单击聚宽JoinQuant量化炒股平台中的“策略研究/研究环境”命令,进入Jupyter Notebook的研究平台。然后单击“新建”按钮,创建Python3文件,接着输入如下代码:
import pandas as pd
df = get_fundamentals(query(indicator).filter(indicator.inc_net_profit_annual > 600, indicator.inc_revenue_annual > 500), date='2024-04-26')
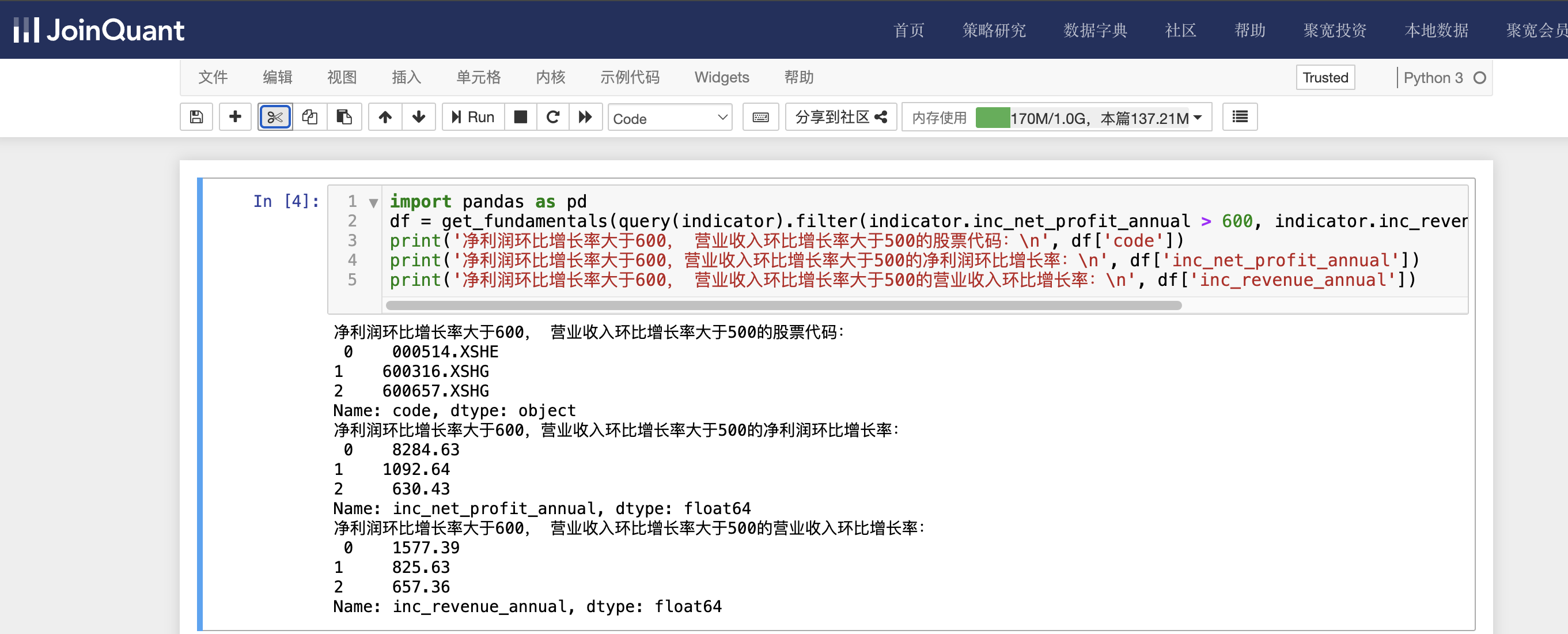
print('净利润环比增长率大于600, 营业收入环比增长率大于500的股票代码:\n', df['code'])
print('净利润环比增长率大于600,营业收入环比增长率大于500的净利润环比增长率:\n', df['inc_net_profit_annual'])
print('净利润环比增长率大于600, 营业收入环比增长率大于500的营业收入环比增长率:\n', df['inc_revenue_annual'])
indicator为财务指标数据名,查询条件有两个,分别是净利润环比增长率大于600,营业收入环比增长率大于500。时间为2024-04-26。
单击工具栏中的运行按钮,快捷键(shift+enter),运行结果如下图:
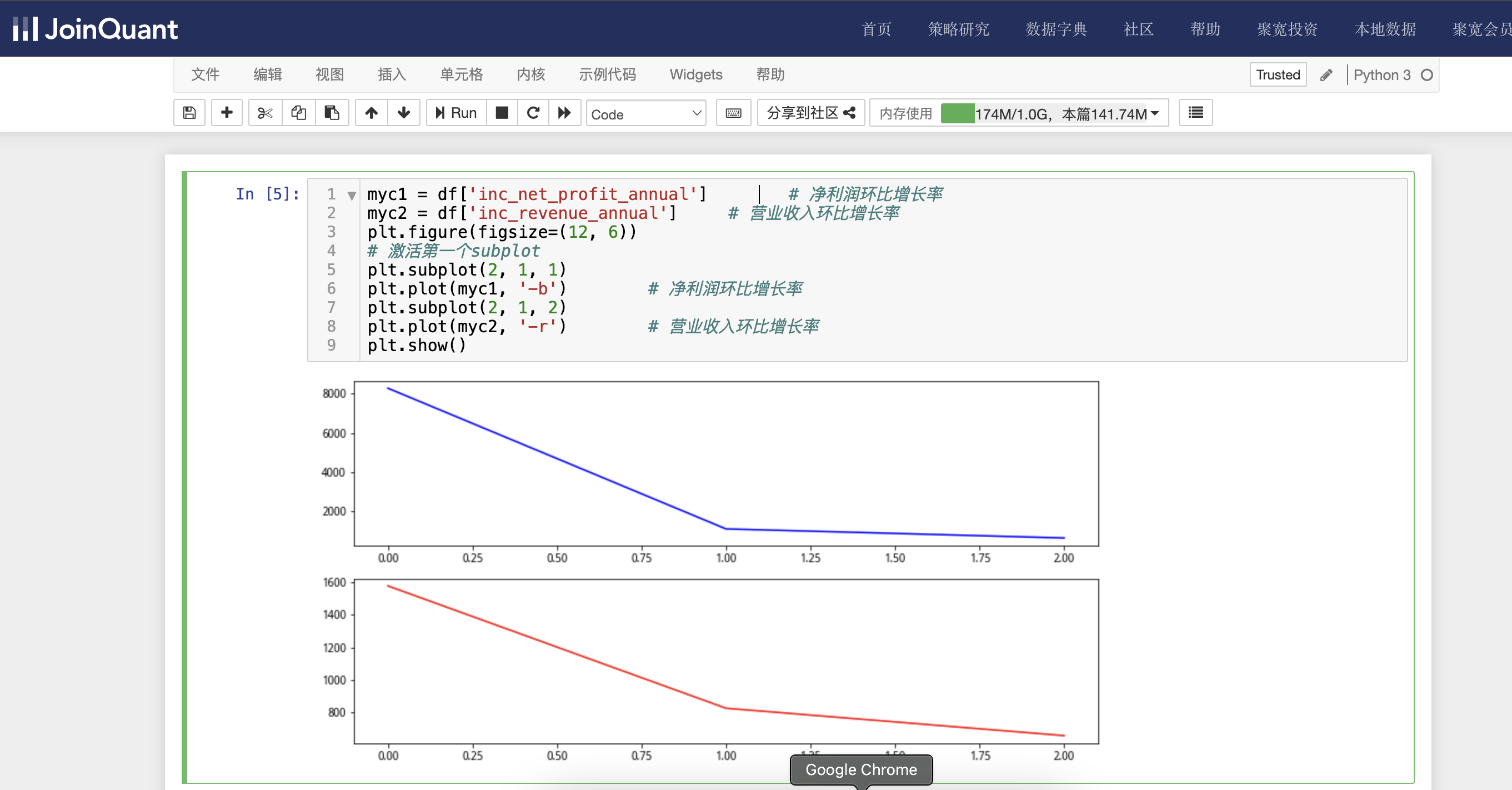
利用图表显示净利润环比增长率大于600,营业收入环比增长率大于500的净利润环比增长率和营业收入环比增长率,具体代码如下:
myc1 = df['inc_net_profit_annual'] # 净利润环比增长率
myc2 = df['inc_revenue_annual'] # 营业收入环比增长率
plt.figure(figsize=(12, 6))
# 激活第一个subplot
plt.subplot(2, 1, 1)
plt.plot(myc1, '-b') # 净利润环比增长率
plt.subplot(2, 1, 2)
plt.plot(myc2, '-r') # 营业收入环比增长率
plt.show()
单击工具栏中的运行按钮,快捷键(shift+enter),运行结果如下图:
营业利润率(operation_profit_to_total_revenue)选股
营业利润率是指经营所得的营业利润占销货净额的百分比,或占投入资本额的百分比,其计算公式如下:
营业利润率 = 营业利润 ➗ 全部业务收入 ✖️ 100%
营业利润率越高,说明企业商品销售额提供的营业利润越多,企业的盈利能力越强。反之,此比率越低,说明企业盈利能力越弱。
单击聚宽JoinQuant量化炒股平台中的“策略研究/研究环境”命令,进入Jupyter Notebook的研究平台。然后单击“新建”按钮,创建Python3文件,接着输入如下代码:
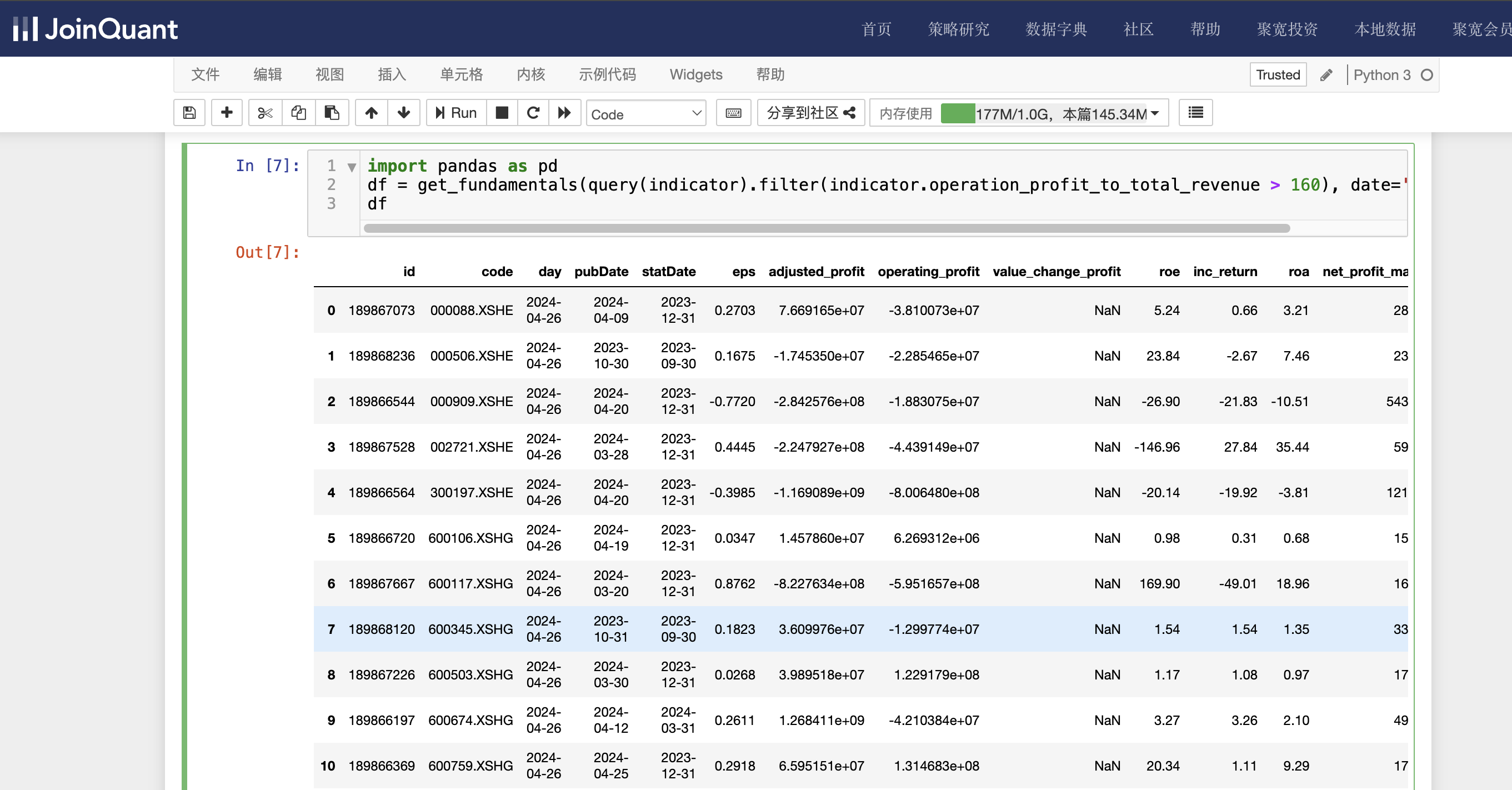
import pandas as pd
df = get_fundamentals(query(indicator).filter(indicator.operation_profit_to_total_revenue > 160), date='2024-04-26')
df
单击工具栏中的运行按钮,快捷键(shift+enter),运行结果如下图:
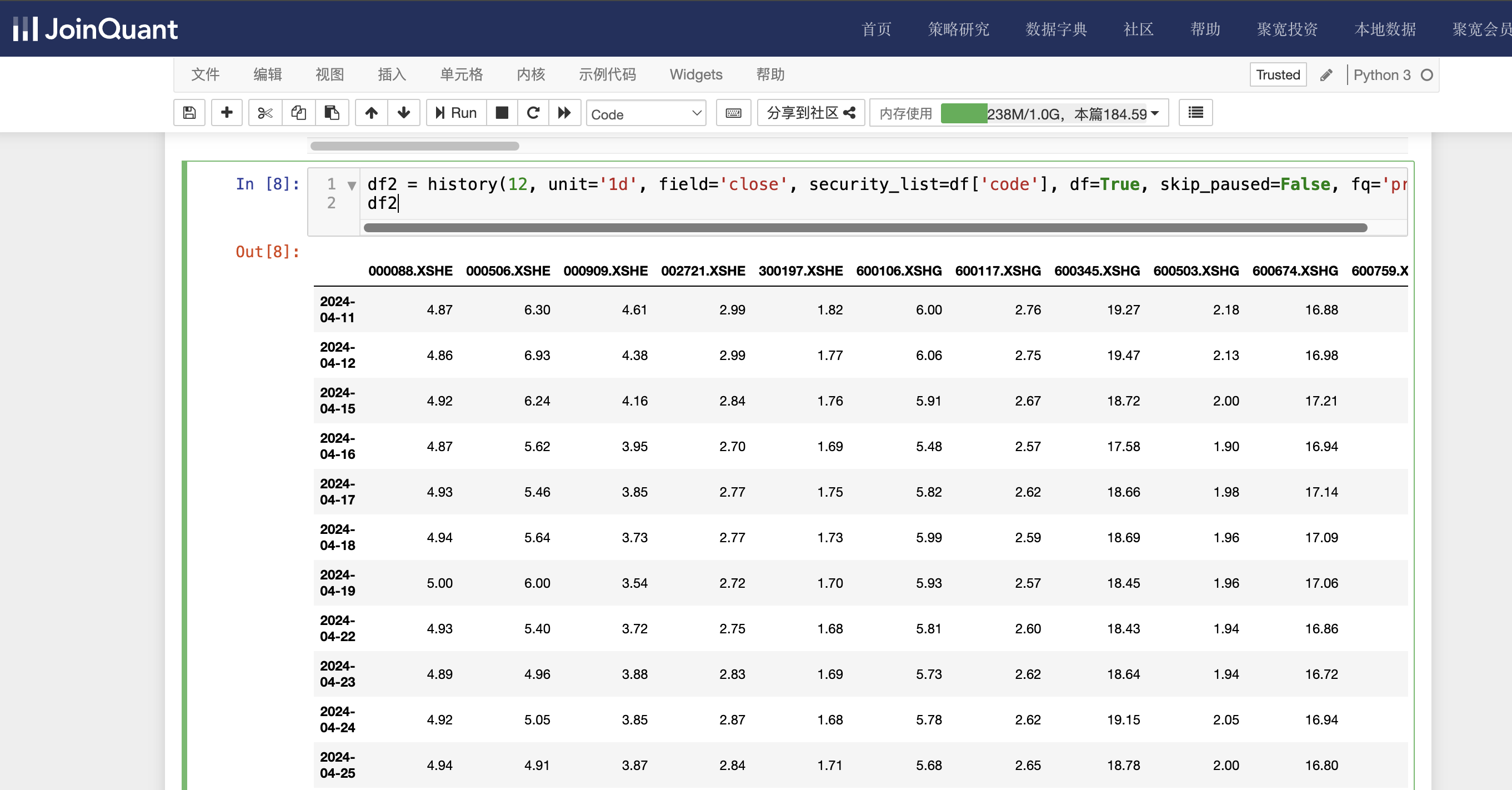
显示营业利润大于160的股票的近12个交易日的收盘价信息,具体代码如下:
df2 = history(12, unit='1d', field='close', security_list=df['code'], df=True, skip_paused=False, fq='pre')
df2
单击工具栏中的运行按钮,快捷键(shift+enter),运行结果如下图:
销售净利率(net_profit_margiin)选股
销售净利润是指企业实现净利润与销售收入的对比关系,用以衡量企业在一定时期的销售收入获取的能力,其计算公式如下:
销售净利润 = 净利润 ➗ 销售收入 ✖️ 100%
销售净利率与净利润成正比关系,与销售收入成反比关系,企业在增加销售收入额的同时,必须相应地获得更多的净利润,才能使销售净利率保持不变或有所提高。
单击聚宽JoinQuant量化炒股平台中的“策略研究/研究环境”命令,进入Jupyter Notebook的研究平台。然后单击“新建”按钮,创建Python3文件,接着输入如下代码:
import pandas as pd
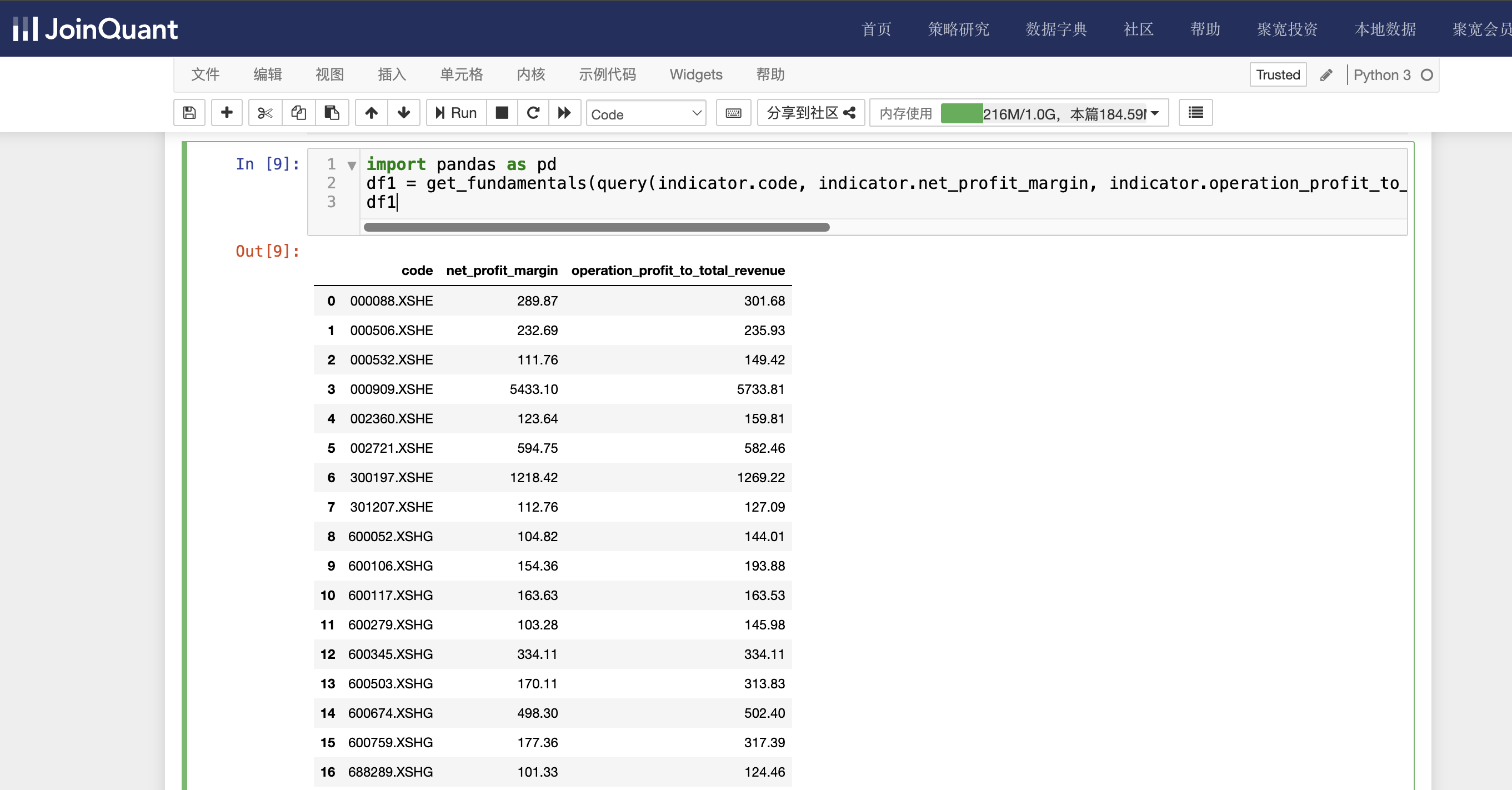
df1 = get_fundamentals(query(indicator.code, indicator.net_profit_margin, indicator.operation_profit_to_total_revenue).filter(indicator.net_profit_margin > 100,indicator.operation_profit_to_total_revenue > 120), date='2024-04-26')
df1
indicator为财务指标数据表名,查询条件有两个,分别是销售净利率大于100,营业利润率大于120。时间为2024-04-26。注意:这里显示的是股票代码、销售净利率和营业利润率。单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
利用图表显示销售净利率大于100,营业利润率大于120的销售净利率和营业利润率,具体代码如下:
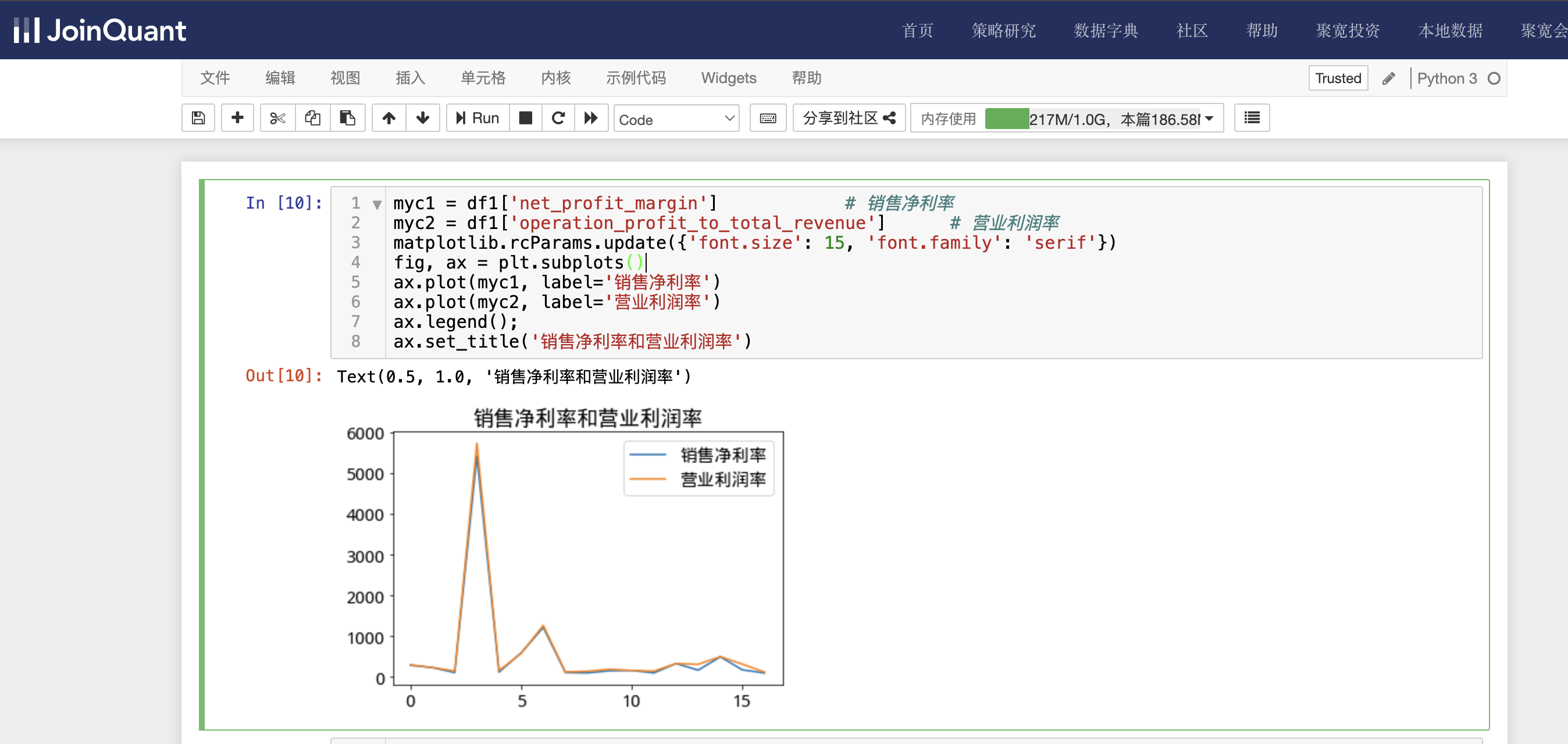
myc1 = df1['net_profit_margin'] # 销售净利率
myc2 = df1['operation_profit_to_total_revenue'] # 营业利润率
matplotlib.rcParams.update({'font.size': 15, 'font.family': 'serif'})
fig, ax = plt.subplots()
ax.plot(myc1, label='销售净利率')
ax.plot(myc2, label='营业利润率')
ax.legend();
ax.set_title('销售净利率和营业利润率')
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
销售毛利率(gross_profit_margin)选股
销售毛利率是毛利占销售净值的百分比,通常称为毛利率。其中,毛利是销售净收入与产品成本的差,其计算公式如下:
销售毛利率 = (销售净收入 - 产品成本) ➗ 销售净收入 ✖️100%
销售毛利率是上市公司的重要经营指标,能反映公司产品的竞争力和获利潜力。它反映了企业产品销售的初始获利能力,是企业净利润的起点,没有足够高的毛利率便不能形成较大的盈利。与同行业比较,如果公司的毛利率显著高于同行业水平,则说明公司产品附加值高,产品定价高,或与同行业比较公司存在成本上的优势,有竞争力。
与历史比较,如果公司的毛利率显著提高,则可能是公司所在行业处于复苏时期,产品价格大幅上升。在这种情况下投资者需要考虑这种价格的上升是否能持续,公司将来的盈利能力是否有保证。相反,如果公司毛利率显著降低,则可能是公司所在行业竞争激烈,毛利率下降往往伴随着价格战的爆发或成本的失控,这种情况预示产品盈利能力的下降。
单击聚宽JoinQuant量化炒股平台中的“策略研究/研究环境”命令,进入Jupyter Notebook的研究平台。然后单击“新建”按钮,创建Python3文件,接着输入如下代码:
import pandas as pd
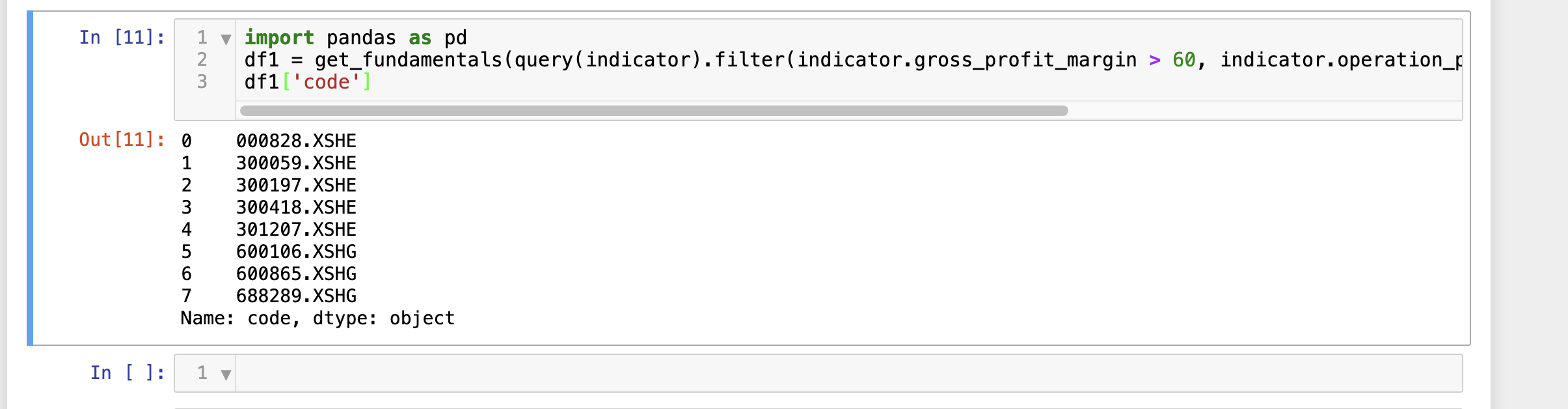
df1 = get_fundamentals(query(indicator).filter(indicator.gross_profit_margin > 60, indicator.operation_profit_to_total_revenue > 80), date='2024-04-26')
df1['code']
indicator为财务指标数据表名,查询条件有两个,分别是销售毛利率大于60,营业利润率大于80,时间为2024-04-26。
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
规模类因子选股
在Python财务因子量化选股中,规模类因子有4个,分别是总市值、流通市值、总股本和流通股本。
需要注意的是,规模类因子都在市值数据表valuation中。
总市值(market_cap)选股
总市值是指在某特定时间内总股本数乘以当时股价得出的股票总市值。沪市所有股票的市值就是沪市总市值。深市所有股票的市值就是深市总市值。总市值用来表示个股权重大小或大盘的规模大小,对股票买卖没有直接作用,但很多时候走强的大多是市值大的个股,由于市值越大在指数中占比的比例越高,庄家往往通过控制这些高市值的股票达到控制大盘的目的。这时候对股票买卖好像又有作用。
单击聚宽JoinQuant量化炒股平台中的“策略研究/研究环境”命令,进入Jupyter Notebook的研究平台。然后单击“新建”按钮,创建Python3文件,接着输入如下代码:
import pandas as pd
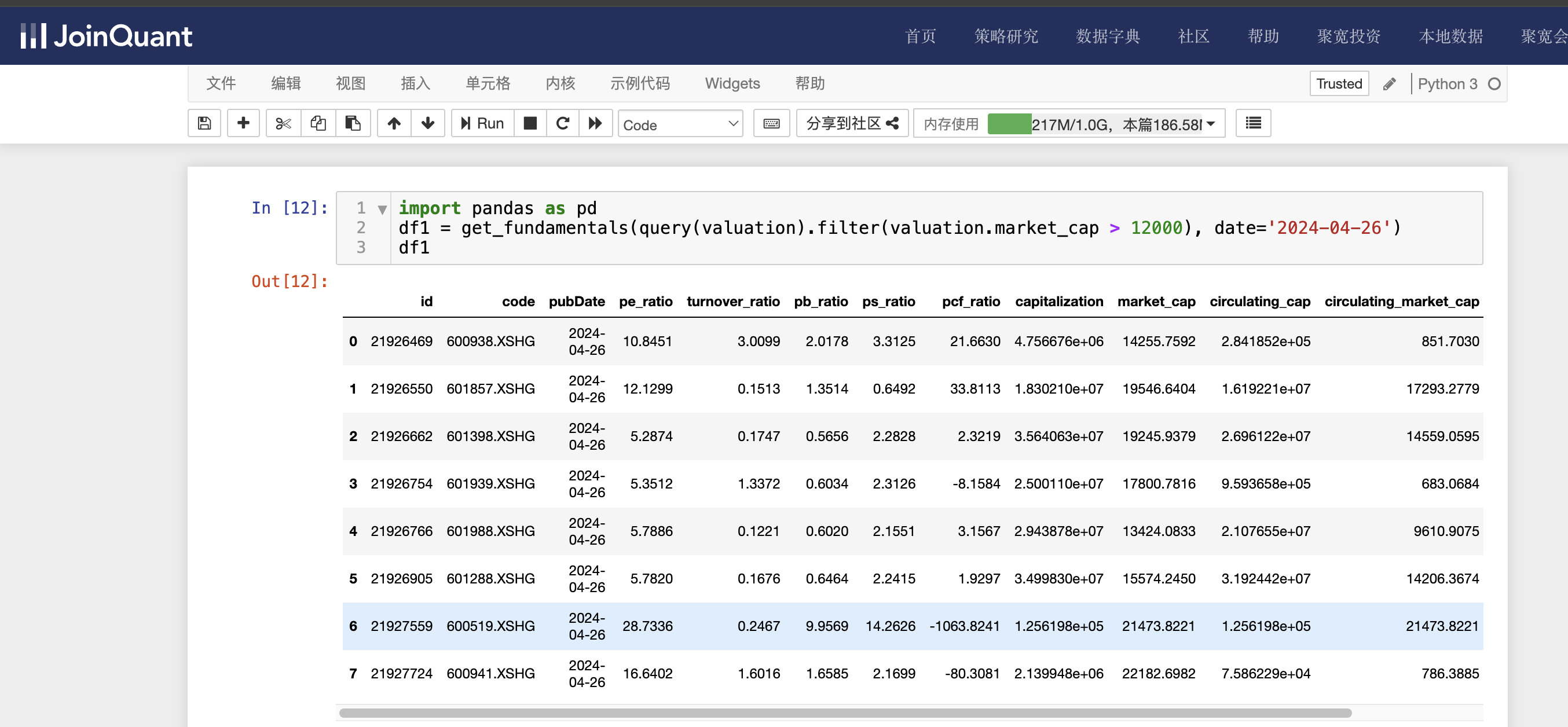
df1 = get_fundamentals(query(valuation).filter(valuation.market_cap > 12000), date='2024-04-26')
df1
valuation为市值数据表名,查询条件是总市值大于12000亿,时间为2024-04-26。
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
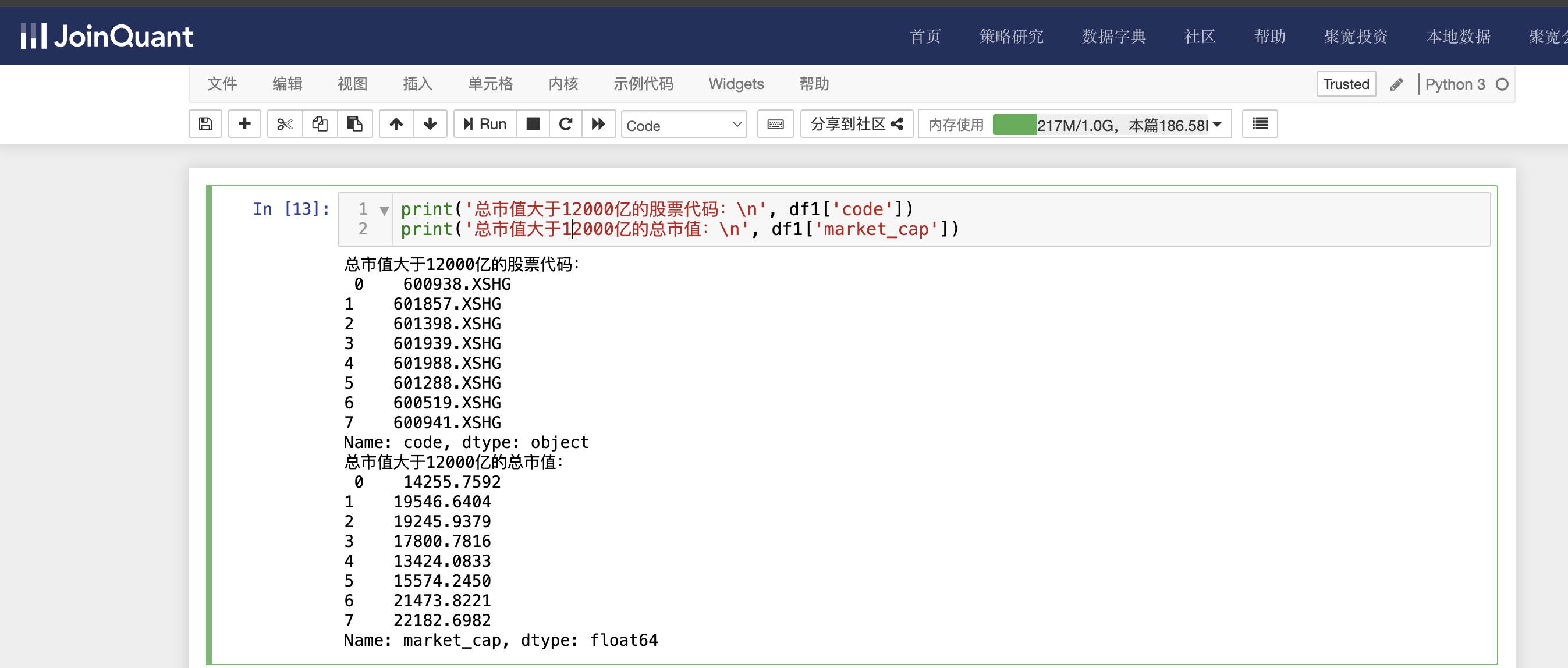
显示总市值大于12000亿的股票代码和总市值信息,具体代码如下:
print('总市值大于12000亿的股票代码:\n', df1['code'])
print('总市值大于12000亿的总市值:\n', df1['market_cap'])
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
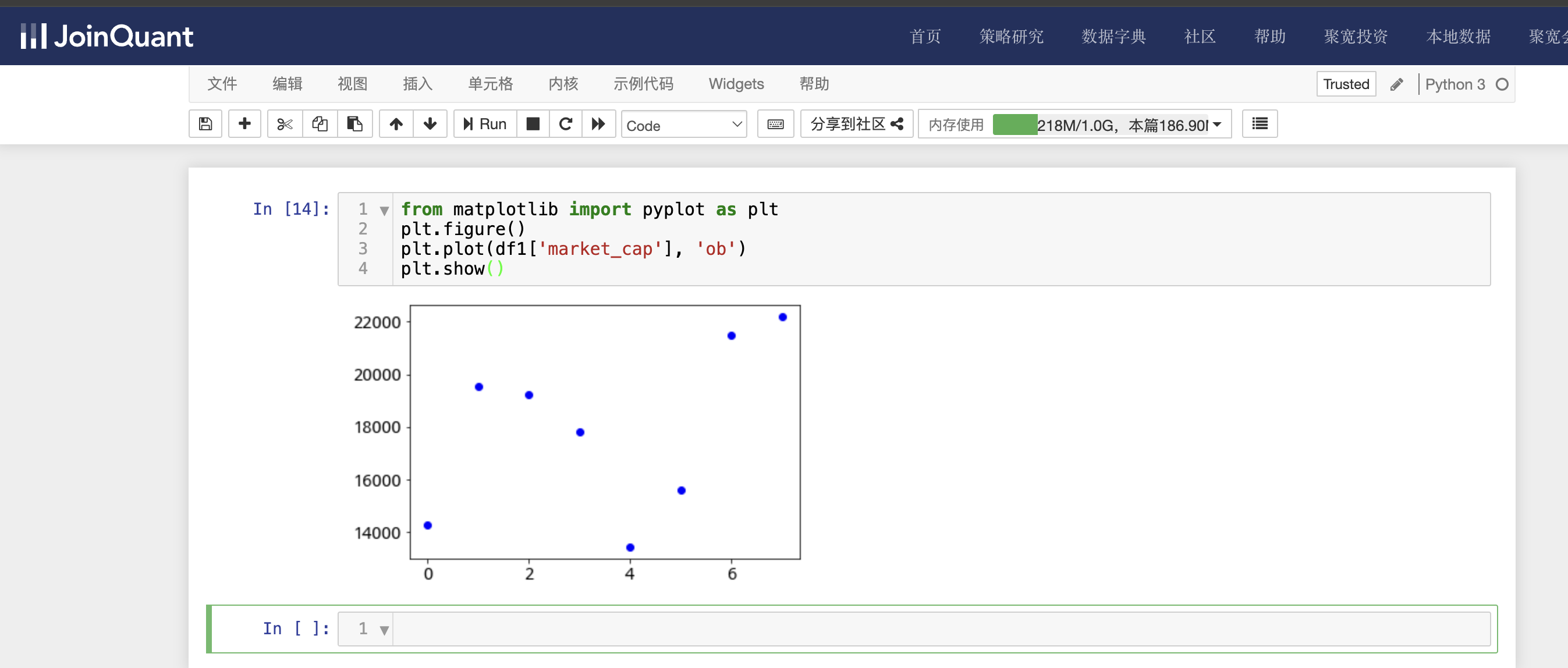
利用图表显示总市值大于12000亿的总市值信息,具体代码如下:
from matplotlib import pyplot as plt
plt.figure()
plt.plot(df1['market_cap'], 'ob')
plt.show()
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
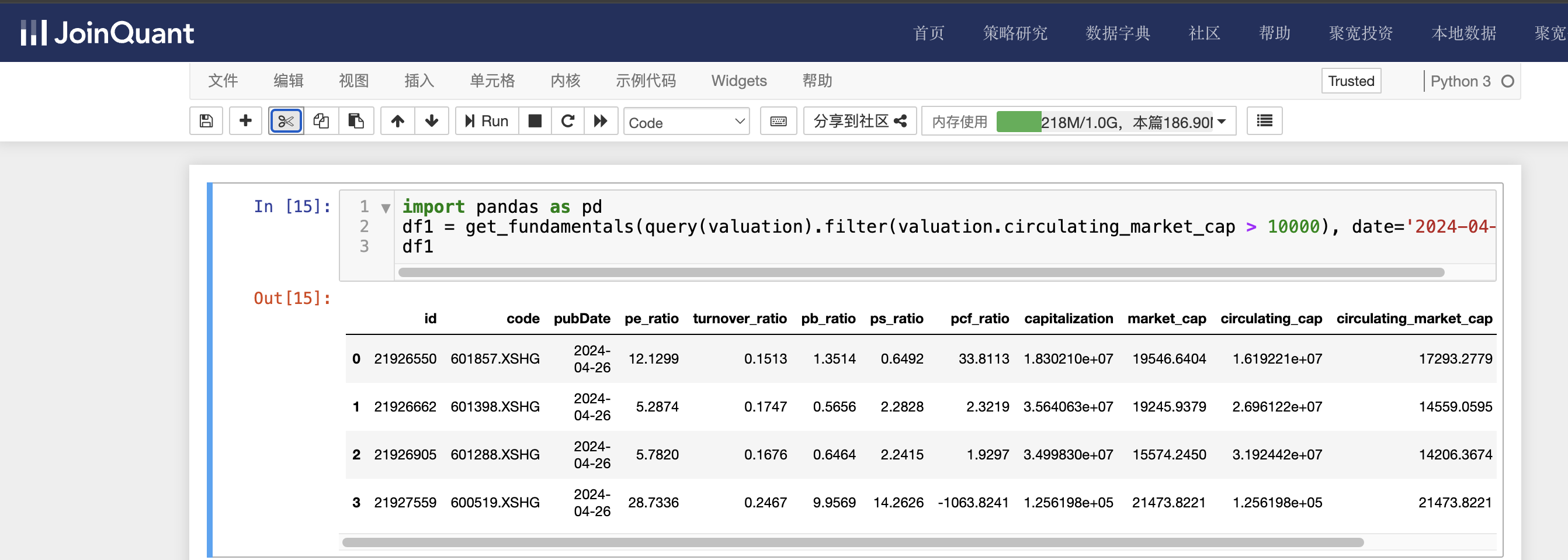
流通市值(circulating_market_cap)选股
流通市值是指在某特定时间内当时可交易的流通股股数乘以当时股价得出的流通股票总价值。在中国,上市公司的股份结构分为国有股、法人股、个人股等。
目前只有个人股可以上市流通交易。这部分流通等股份总数乘以股票市场价格,就是流通市值。需要注意的是,流通市值要小于等于总市值。
单击聚宽JoinQuant量化炒股平台中的“策略研究/研究环境”命令,进入Jupyter Notebook的研究平台。然后单击“新建”按钮,创建Python3文件,接着输入如下代码:
import pandas as pd
df1 = get_fundamentals(query(valuation).filter(valuation.circulating_market_cap > 10000), date='2024-04-26')
df1df2 = history(10, unit='1d', field='close', security_list=df1['code'], df=True, skip_paused=False, fq='pre')
df2
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
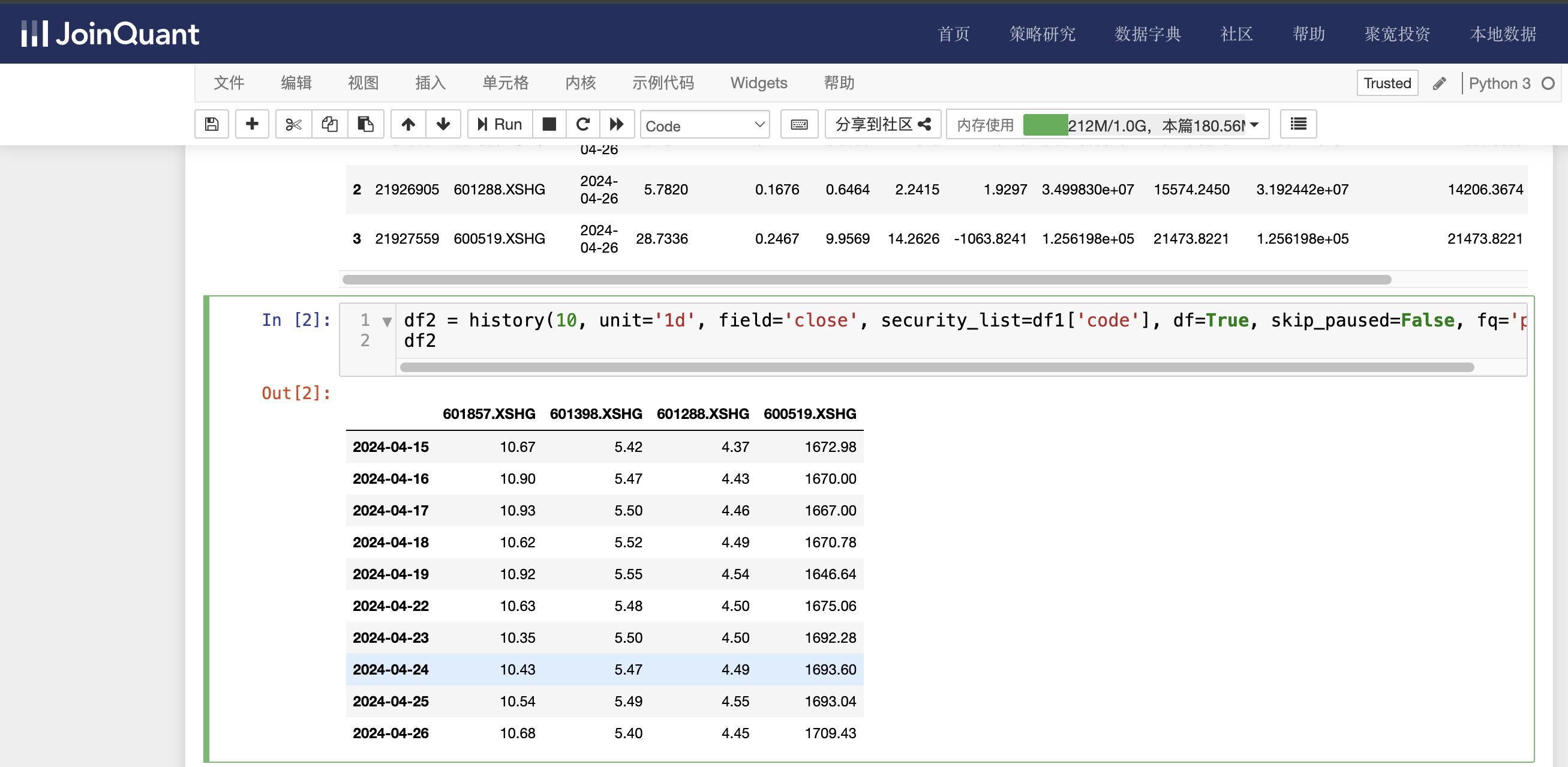
显示流通市值大于10000亿的股票的近10个交易日的收盘价信息,具体代码如下:
df2 = history(10, unit='1d', field='close', security_list=df1['code'], df=True, skip_paused=False, fq='pre')
df2
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
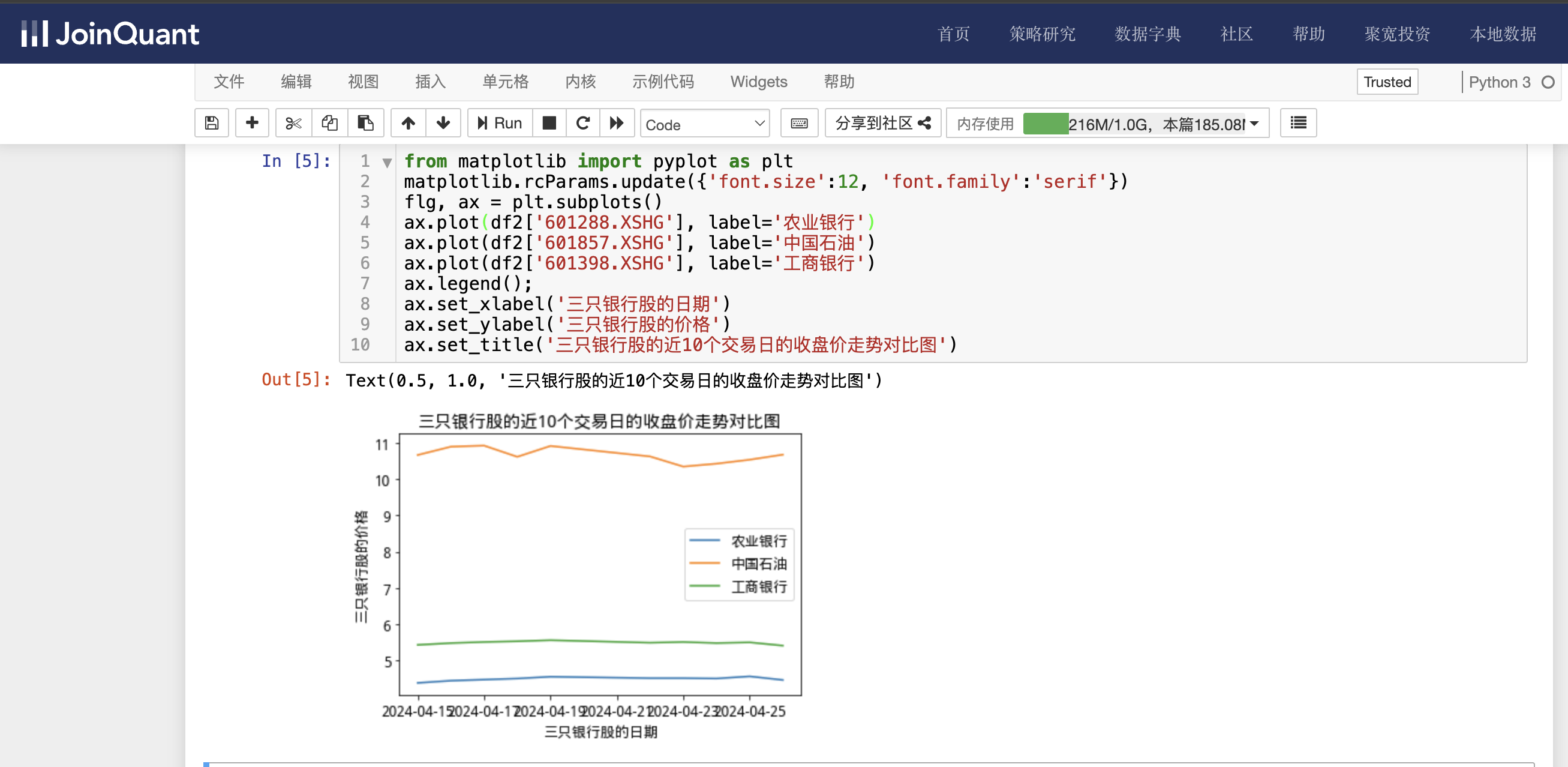
利用图表显示流通市值大于10000亿的股票的近10个交易日的收盘价信息,具体代码如下:
from matplotlib import pyplot as plt
matplotlib.rcParams.update({'font.size':12, 'font.family':'serif'})
flg, ax = plt.subplots()
ax.plot(df2['601288.XSHG'], label='农业银行')
ax.plot(df2['601857.XSHG'], label='中国石油')
ax.plot(df2['601398.XSHG'], label='工商银行')
ax.legend();
ax.set_xlabel('三只银行股的日期')
ax.set_ylabel('三只银行股的价格')
ax.set_title('三只银行股的近10个交易日的收盘价走势对比图')
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
总股本(capitalization)选股
总股本是指公司已发行的普通股股份总数(包含A股、B股和H股的总股本)。
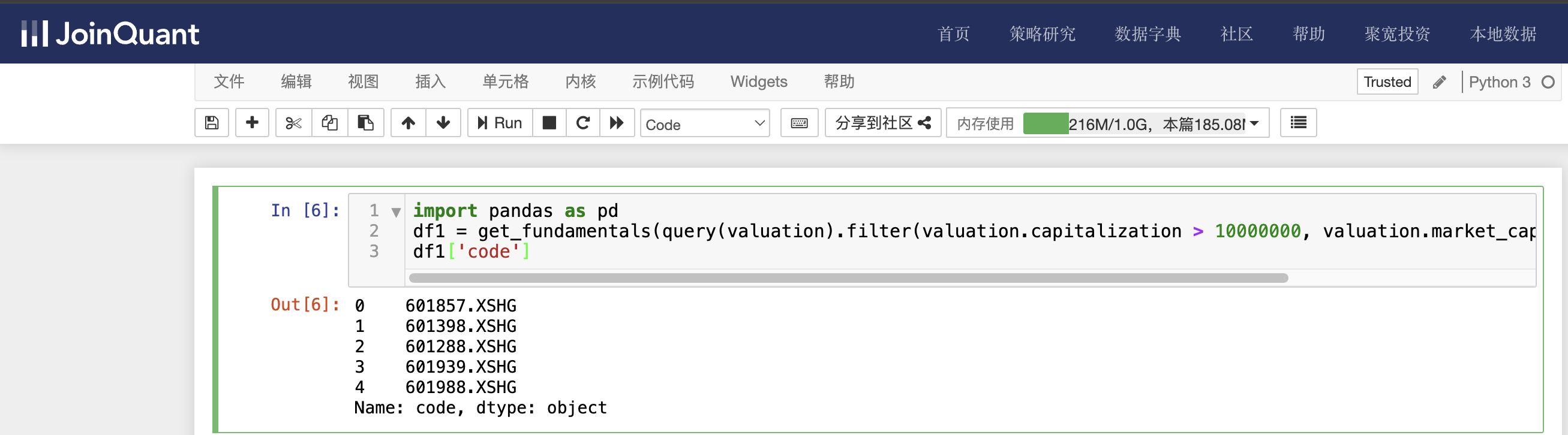
单击聚宽JoinQuant量化炒股平台中的“策略研究/研究环境”命令,进入Jupyter Notebook的研究平台。然后单击“新建”按钮,创建Python3文件,接着输入如下代码:
import pandas as pd
df1 = get_fundamentals(query(valuation).filter(valuation.capitalization > 10000000, valuation.market_cap > 8000), date='2024-04-24')
df1['code']
valuation为市值数据表名,查询条件是总股本大于10000000万股,总市值大于8000亿。时间为2024-04-26。
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
流通股本(circulating_cap)选股
流通股本是指公司已发行的境内上市流通、以人民币兑换的股份总数,即A股市场的流通股本。
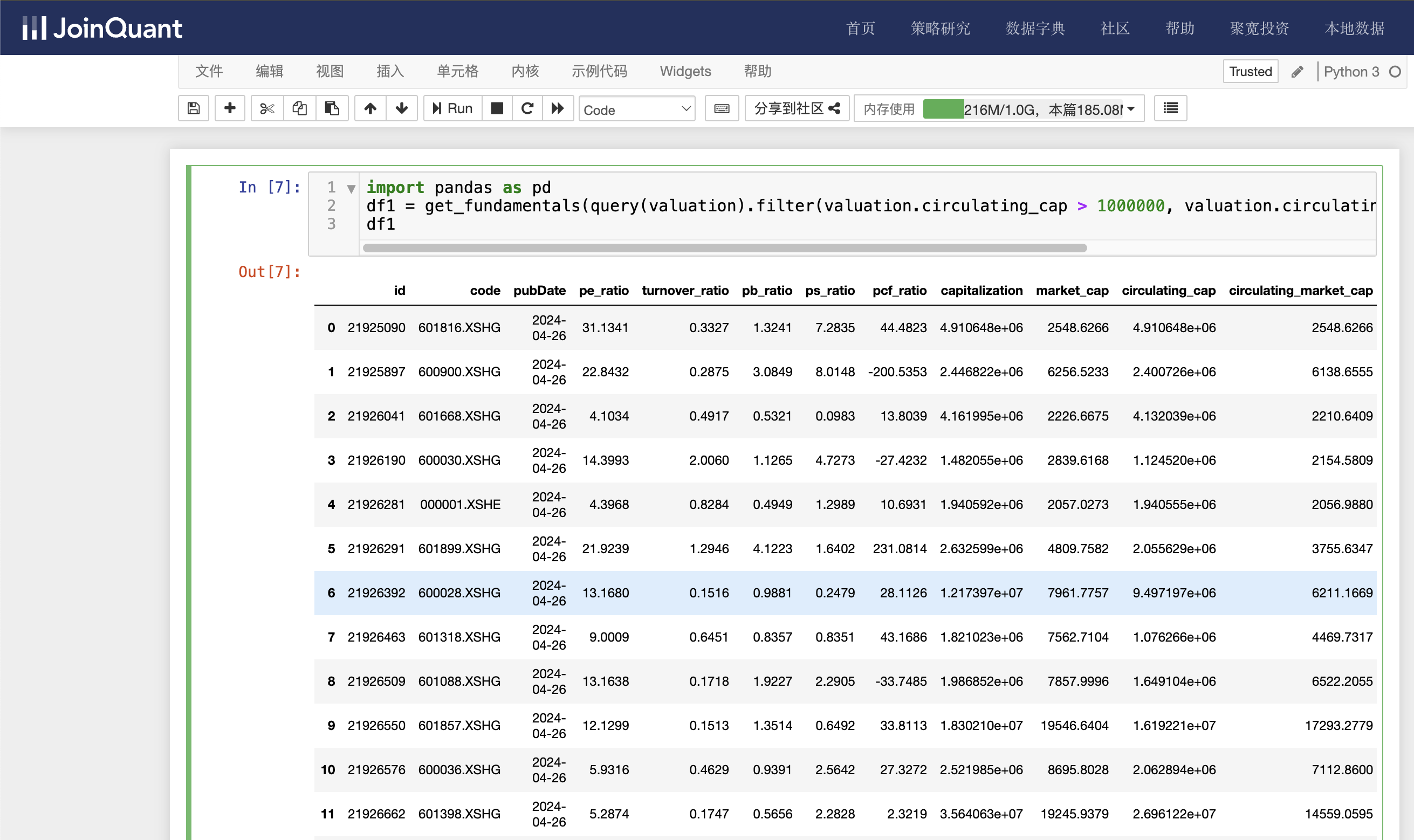
单击聚宽JoinQuant量化炒股平台中的“策略研究/研究环境”命令,进入Jupyter Notebook的研究平台。然后单击“新建”按钮,创建Python3文件,接着输入如下代码:
import pandas as pd
df1 = get_fundamentals(query(valuation).filter(valuation.circulating_cap > 1000000, valuation.circulating_market_cap > 2000), date='2024-04-26')
df1
valuation为市值数据表名,查询条件有两个,分别是流通股本大于1000000万股,流通市值大于2000亿。时间为2024-04-26。
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
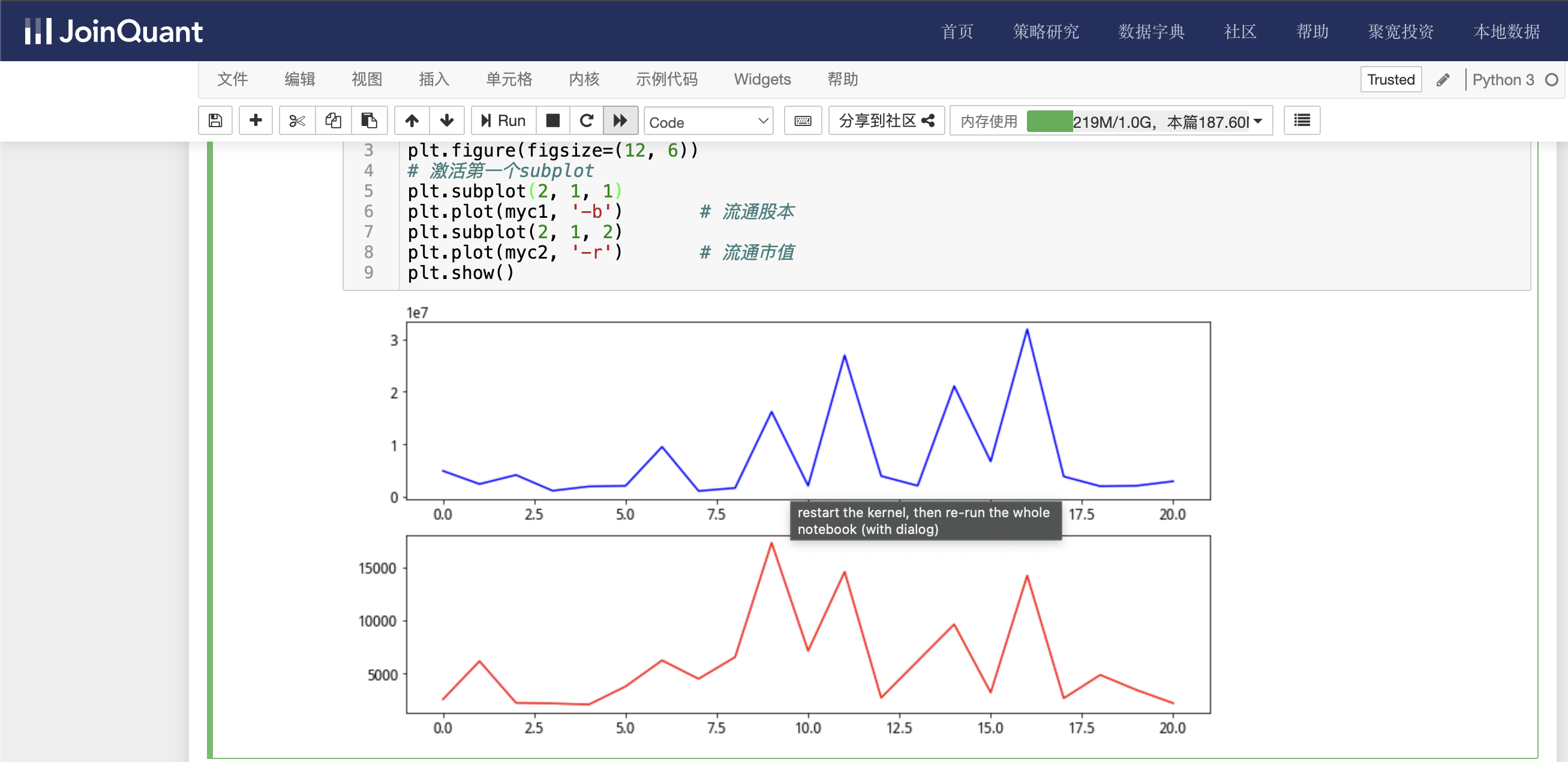
利用图表显示流通股本大于1000000万股,流通市值大于2000亿的流通股本和流通市值,具体代码如下:
myc1 = df1['circulating_cap'] # 流通股本
myc2 = df1['circulating_market_cap'] # 流通市值
plt.figure(figsize=(12, 6))
# 激活第一个subplot
plt.subplot(2, 1, 1)
plt.plot(myc1, '-b') # 流通股本
plt.subplot(2, 1, 2)
plt.plot(myc2, '-r') # 流通市值
plt.show()
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
价值类因子选股
在Python财务因子量化选股中,价值类因子有5个,分别是市净率、市销率、市现率、动态市盈率和静态市盈率。
需要注意的是,价值类因子也都在市值数据表valuation中。
市净率(pb_ratio)选股
市净率是指每股股价与每股净资产的比率,其计算公式如下:
市净率 = 每股市价➗每股净资产
市净率可用于股票投资分析,一般来说市净率较低的股票,投资价值较高,相反,则投资价值较低。但在判断投资价值时还要考虑当时的市场环境以及公司经营情况、赢利能力等因素。
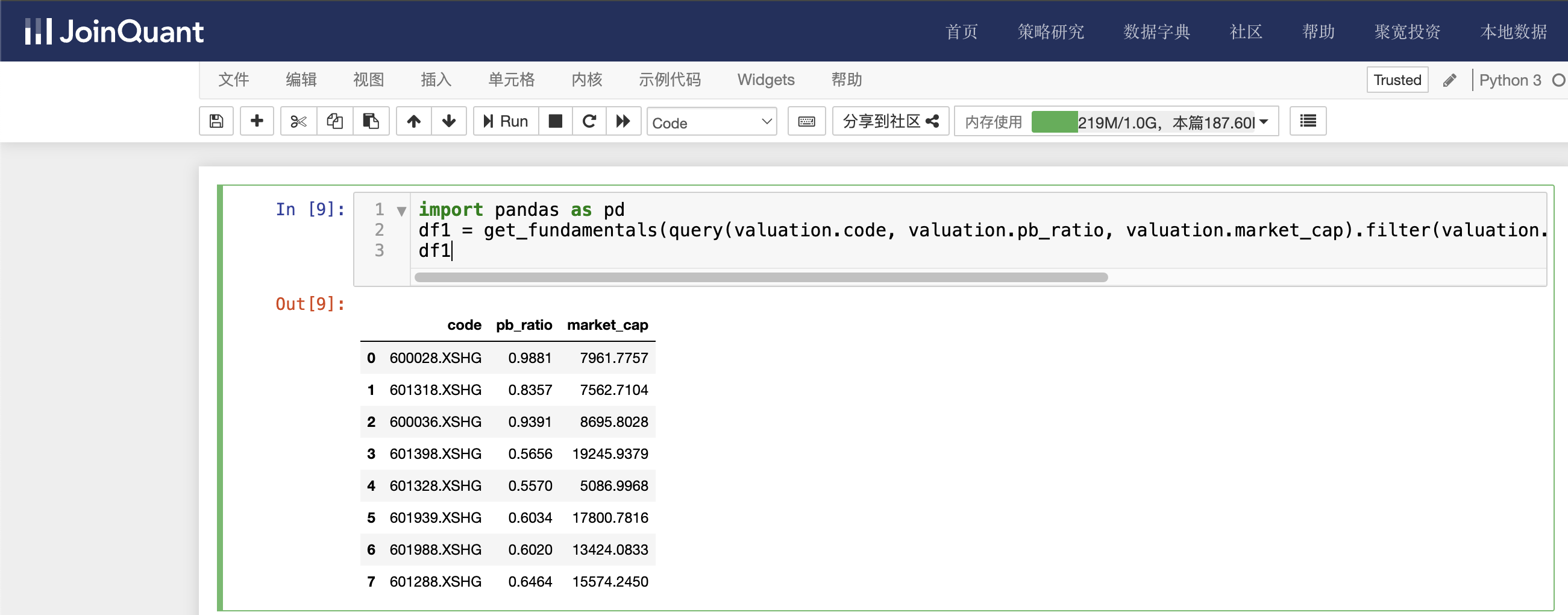
单击聚宽JoinQuant量化炒股平台中的“策略研究/研究环境”命令,进入Jupyter Notebook的研究平台。然后单击“新建”按钮,创建Python3文件,接着输入如下代码:
import pandas as pd
df1 = get_fundamentals(query(valuation.code, valuation.pb_ratio, valuation.market_cap).filter(valuation.pb_ratio < 1.2, valuation.market_cap > 5000), date='2024-04-26')
df1
valuation为市值数据表名, 查询条件有两个,分别是市净率小于1.2,总市值大于5000亿,时间为2024-04-26。
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
市销率(ps_ratio)选股
市销率为股票价格与每股销售收入之比,市销率越小,通常被认为投资价值越高,市销率的计算公式如下:
市销率 = 股价➗每股销售额
在基本分析的诸多工具中,市销率是常用的参考指标之一。可以认为,成熟期的企业通常使用市盈率(PE)来估值,而尚未盈利的高成长性企业则使用市销率(PS)来估值更为可靠。
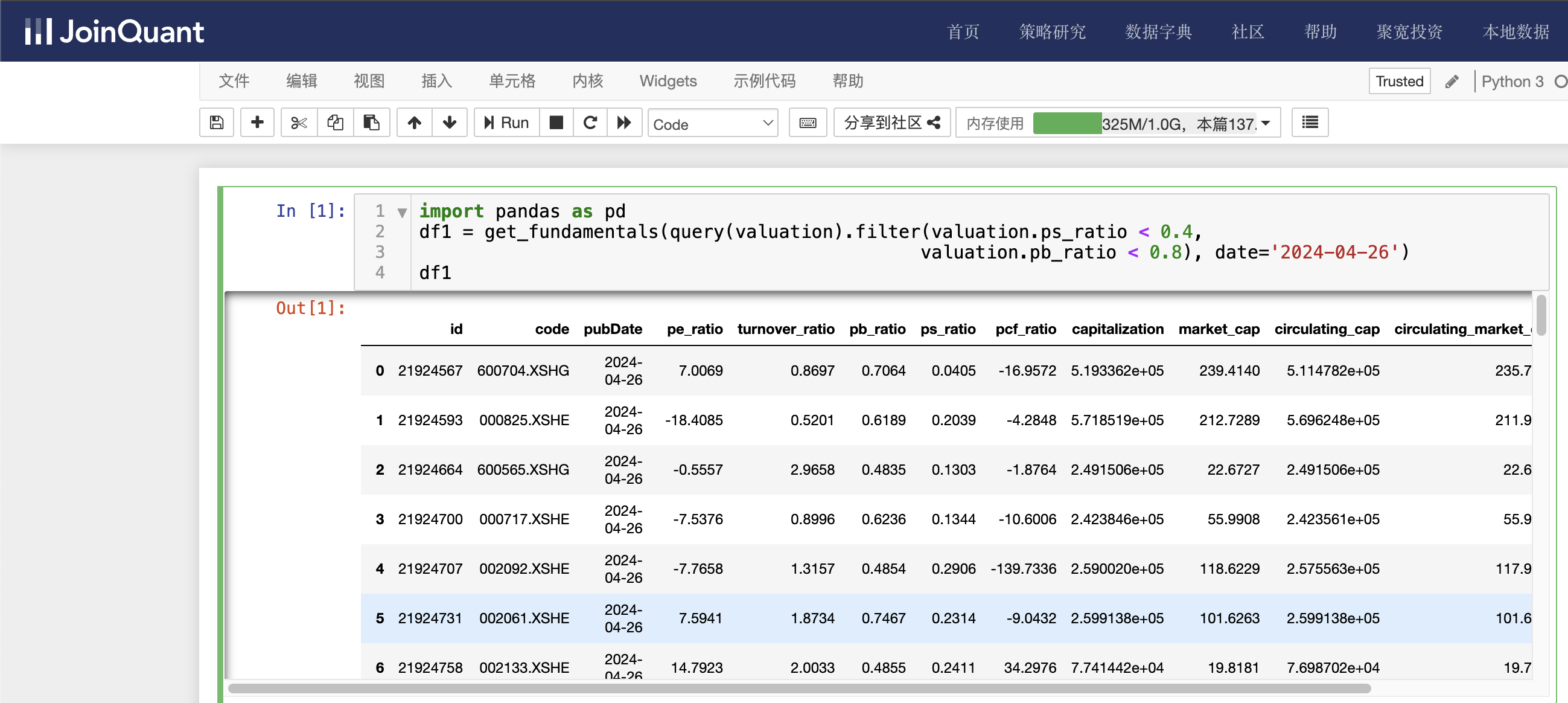
单击聚宽JoinQuant量化炒股平台中的“策略研究/研究环境”命令,进入Jupyter Notebook的研究平台。然后单击“新建”按钮,创建Python3文件,接着输入如下代码:
import pandas as pd
df1 = get_fundamentals(query(valuation).filter(valuation.ps_ratio < 0.4,valuation.pb_ratio < 0.8), date='2024-04-26')
df1
valuation为市值数据表名,查询条件有两个,分别是市销率小于0.4,市净率小于0.8。时间为2024-04-26。
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
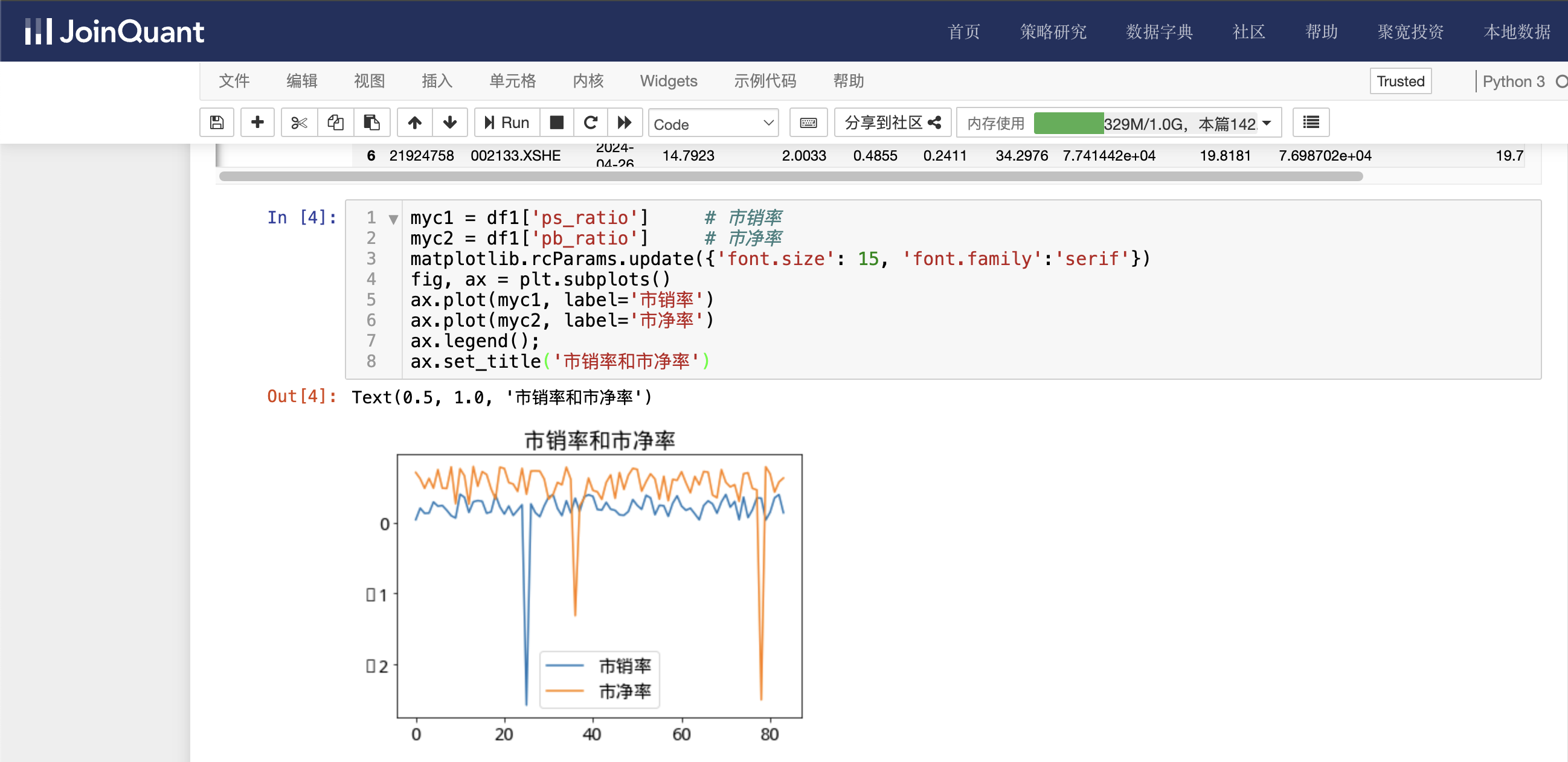
利用图表显示市销率小于0.4,市净率小于0.8的市销率和市净率,具体代码如下:
myc1 = df1['ps_ratio'] # 市销率
myc2 = df1['pb_ratio'] # 市净率
matplotlib.rcParams.update({'font.size': 15, 'font.family':'serif'})
fig, ax = plt.subplots()
ax.plot(myc1, label='市销率')
ax.plot(myc2, label='市净率')
ax.legend();
ax.set_title('市销率和市净率')
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
市现率(pcf_ratio)选股
市现率是股票价格与每股现金流量的比率。市现率可用于评价股票的价格水平和风险水平。市现率越小,表明上市公司的每股现金增加额越多,经营压力越小。对于参与资本运作的投资机构,市现率还意味着其运作资本的增加效率。
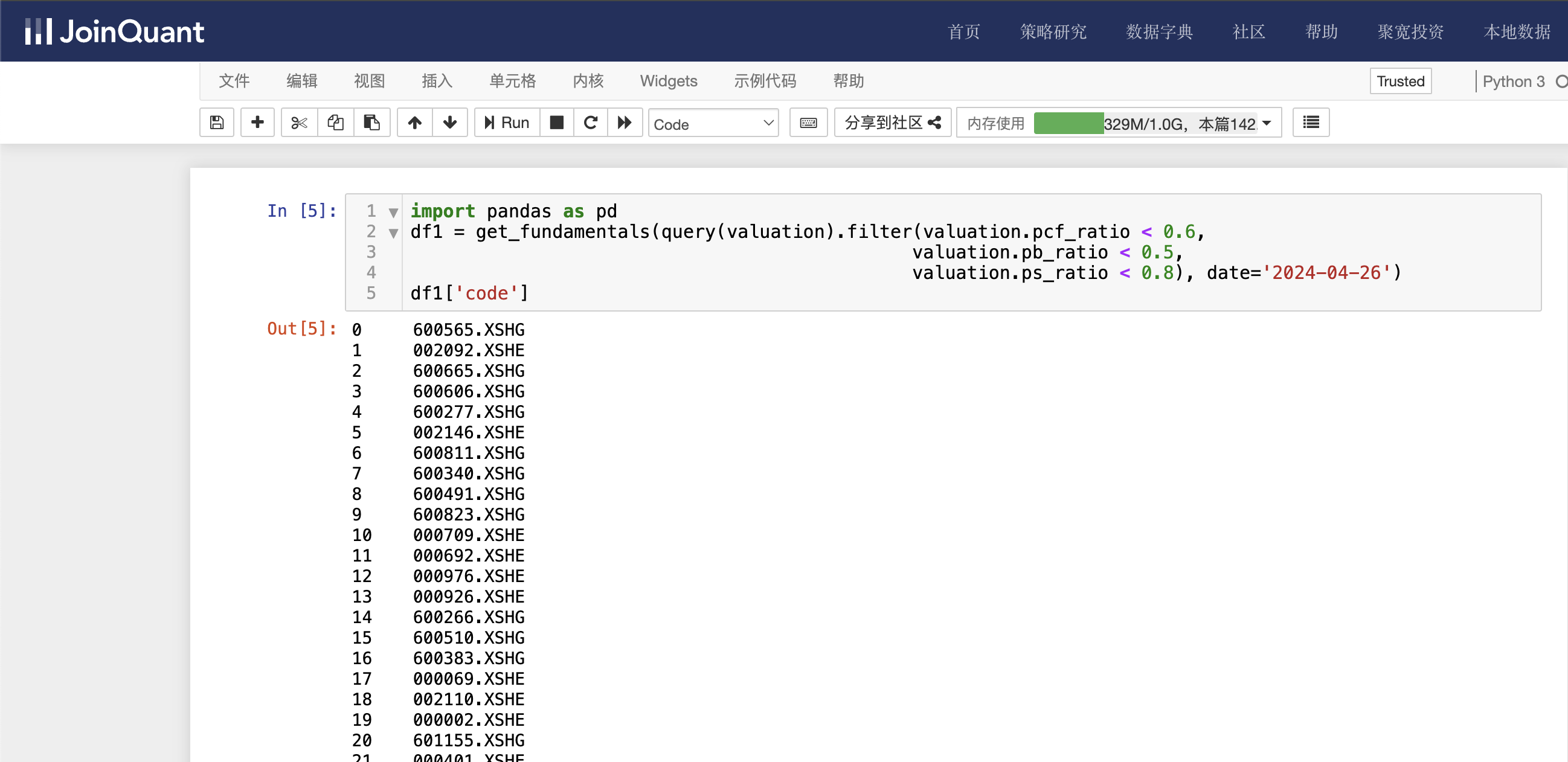
单击聚宽JoinQuant量化炒股平台中的“策略研究/研究环境”命令,进入Jupyter Notebook的研究平台。然后单击“新建”按钮,创建Python3文件,接着输入如下代码:
import pandas as pd
df1 = get_fundamentals(query(valuation).filter(valuation.pcf_ratio < 0.6,valuation.pb_ratio < 0.5,valuation.ps_ratio < 0.8), date='2024-04-26')
df1['code']
valuation为市值数据表名,查询条件有3个,分别是市现率小于0.6,市净率小于0.5,以及市销率小于0.8。时间为2024-04-26。
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
动态市盈率(pe_ratio)选股
动态市盈率(PE)是指还没有真正实现的下一年度的预测利润的市盈率,其计算公式如下:
动态市盈率 = 股票现价 ➗ 未来每股收益的预测值
动态市盈率和市盈率是全球资本市场通用的投资参考指标,用以衡量某一阶段资本市场的投资价值和风险程度,也是资本市场之间用来相互参考与借鉴的重要依据。
单击聚宽JoinQuant量化炒股平台中的“策略研究/研究环境”命令,进入Jupyter Notebook的研究平台。然后单击“新建”按钮,创建Python3文件,接着输入如下代码:
import pandas as pd
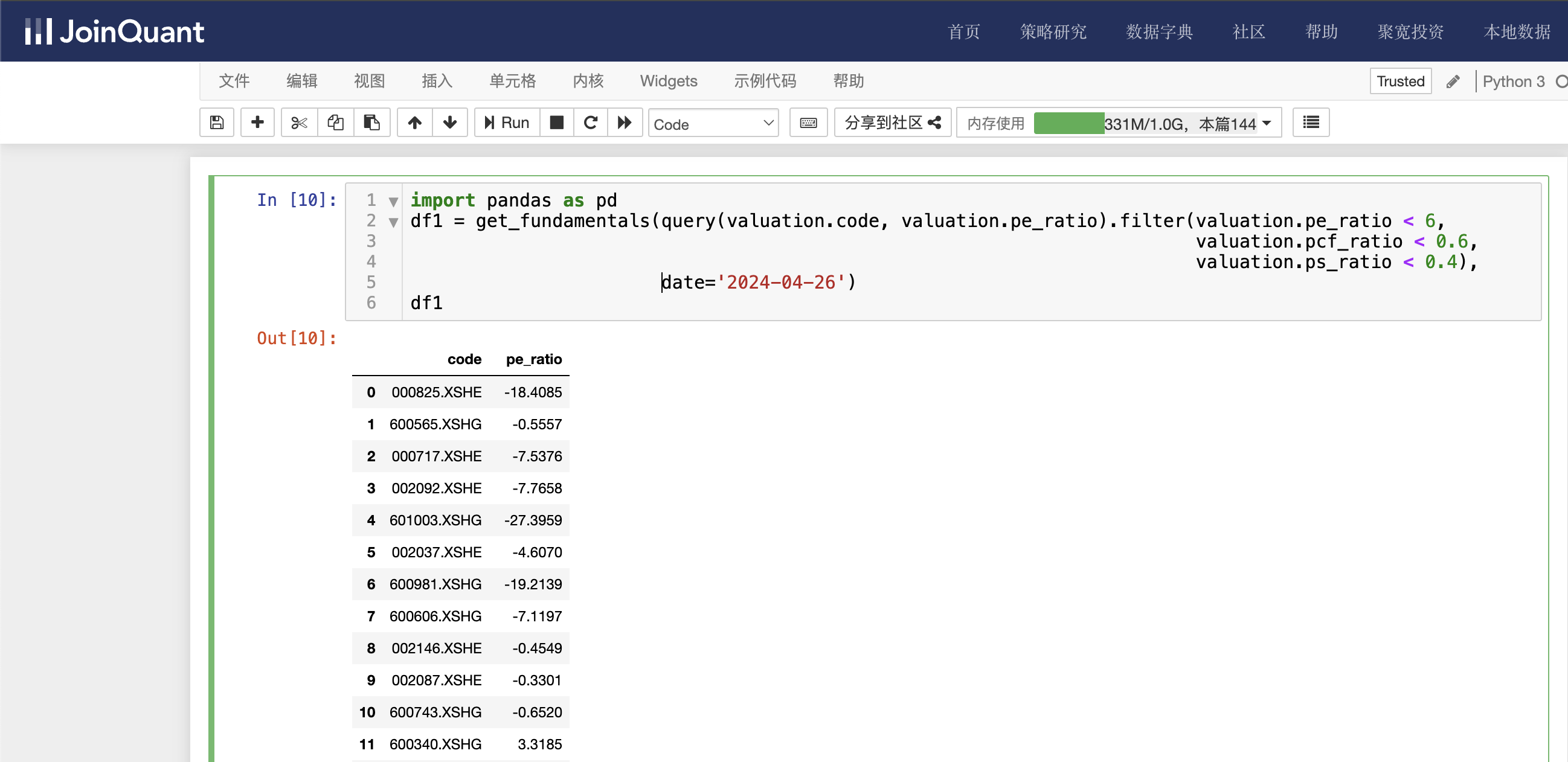
df1 = get_fundamentals(query(valuation.code, valuation.pe_ratio).filter(valuation.pe_ratio < 6, valuation.pcf_ratio < 0.6, valuation.ps_ratio < 0.4), date='2024-04-26')
df1
valuation为市值数据表名,查询条件有3个,分别是动态市盈率小于6,市现率小于0.5,以及市销率小于0.4。时间为2024-04-26。
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
静态市盈率(pe_ratio_lyr)选股
静态市盈率,即市场广泛谈及的市盈率,是用当前每股市场价格除以该公司的每股税后利润,其计算公式如下:
市盈率 = 股票每股市价 ➗ 每股税后利润, 即市盈率 = 股价 ➗ 每股收益
一般来说,市盈率表示该公司需要累积多少年的盈利才能达到如今的市价水平,所以市盈率指标数值越小越好,越小说明投资回收期越短,风险越小,投资价值一般就越高。倍数大则意味着翻本期长,风险大。
单击聚宽JoinQuant量化炒股平台中的“策略研究/研究环境”命令,进入Jupyter Notebook的研究平台。然后单击“新建”按钮,创建Python3文件,接着输入如下代码:
import pandas as pd
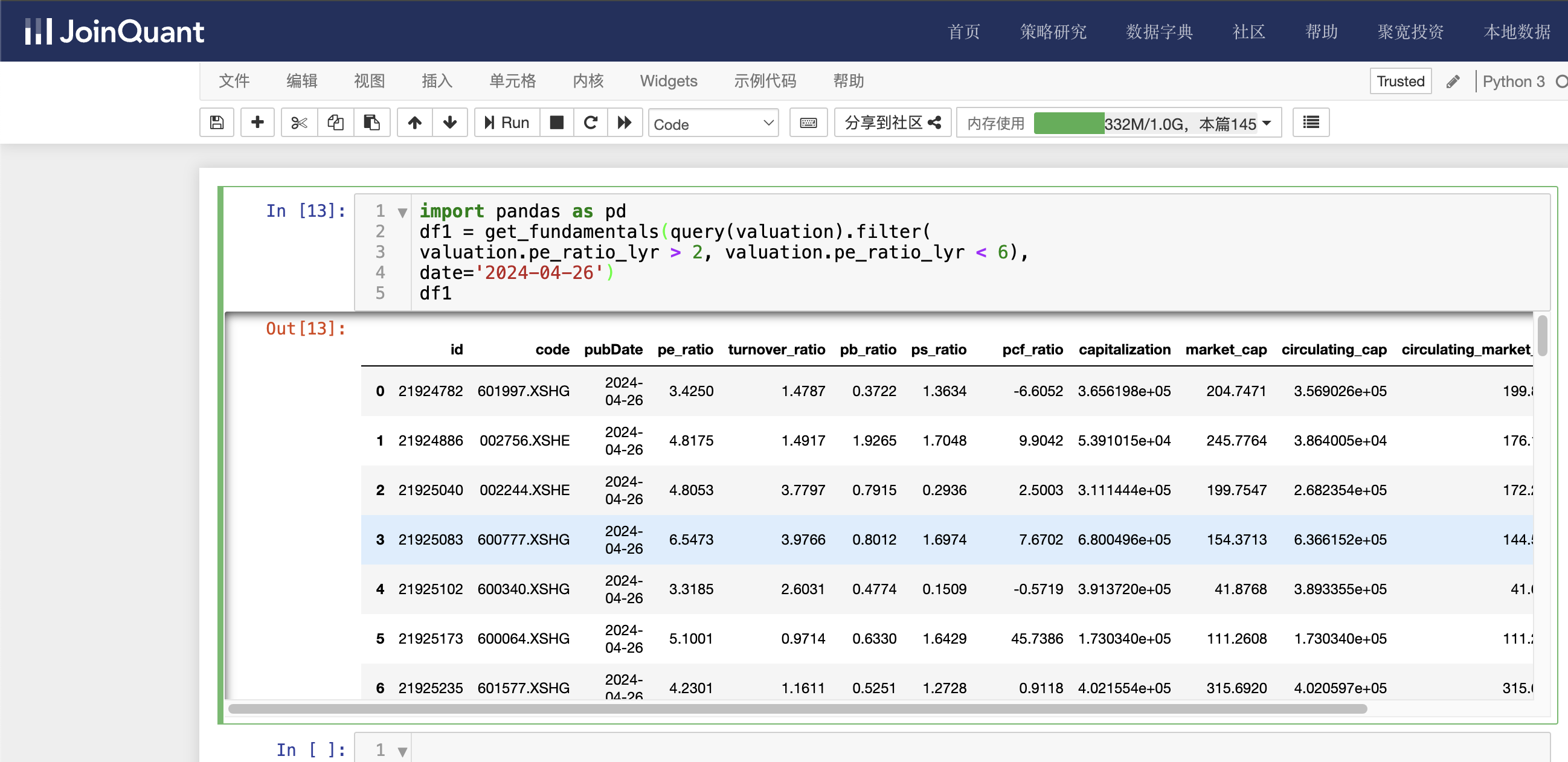
df1 = get_fundamentals(query(valuation).filter(
valuation.pe_ratio_lyr > 2, valuation.pe_ratio_lyr < 6),
date='2024-04-26')
df1
valuation为市值数据表名,查询条件是静态市盈率大于2而小于6,即在2~6之间。时间为2024-04-26。
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图:
利用图表显示静态市盈率大于2而小于6的股票的静态市盈率,具体代码如下:
myc1 = df1['pe_ratio_lyr'] # 静态市盈率
matplotlib.rcParams.update({'font.size': 15, 'font.family': 'serif'})
fig, ax = plt.subplots()
ax.plot(myc1, label='静态市盈率')
ax.legend();
ax.set_title('静态市盈率')
单击工具栏运行按钮,快捷键(shift+enter),运行结果如下图: