论文:FAME: Towards Factual Multi-Task Model Editing
链接:https://arxiv.org/abs/2410.10859
项目:https://github.com/BITHLP/FAME
前言
大语言模型中丰富的知识使得其在如智能助理,法律顾问,医疗咨询等多个领域中表现出色。但是大语言模型中过时的知识或事实错误会导致不正确的输出,进而在实际应用中导致严重后果。微调和重新训练都可以修正大语言模型中的事实,但是微调可能导致灾难性遗忘,而重新训练的代价过高。为了解决这一问题,之前的工作提出了模型编辑任务用于精准高效地修正大语言模型中的知识。
然而,之前的数据集如COUNTERFACT[1]或ZSRE[2]存在以下问题:
使用虚构的数据:编辑的目标是虚构的,使得这些数据集不能真实用于提升模型能力。
包含的任务单一:不能适应真实世界的复杂情景.

这些问题使得之前的数据集既不能真实地用于提升大语言模型的能力,也难以评价之前的模型编辑方法在真实世界中的有效性。
为了推动模型编辑在真实世界中的应用,作者提出了一个新的标准:实用性。这一标准包含以下两个方面:
对于模型编辑数据集来说,它应该真实、多样、高质量
对于模型编辑方法来说,它应该高效、泛化性强、能处理现实世界的复杂变化
为了解决模型编辑数据集和方法实用性不足的问题,推动模型编辑在现实世界中的应用,作者提出了具有实用性的模型编辑数据集 FAME 和模型编辑方法 SKEME。
模型编辑
定义
设一个模型为 ,其中 代表输入集合, 代表输出集合,用 表示一个输入-输出对,特别地,用 表示正在被编辑的事实。
设 为 语义上的等价领域,也即和 具有相同语义的输入输出对的集合,对于在这一集合内的输入,期望的输出即为 。(待编辑事实的输出即是期望输出)。
设 为 将作为先验知识后,可以推导得出的事实的集合,对于这一集合内的输入,期望的输出为 。(模型基于待编辑事实可以推导得出新的输出)。
设 为除 和 之外的输入-输出对,对于这一集合内的输入,期望的输出为 (模型的输出不应该改变)。
相关工作
模型编辑可以分为修改模型参数和不修改模型参数两类方法。
修改模型参数的方法包括元学习和定位然后编辑,前者训练一个超网络来预测编辑模型所需的参数更改;后者定位需要编辑的神经元,之后进行针对性修改。
不修改模型参数可以分为基于额外参数和基于知识库的方法,前者冻结原有模型参数,并添加额外参数进行微调;后者类似于检索增强生成(RAG)模型,知识存储在一个外部知识库中。
FAME:一个实用的模型编辑数据集
为了解决模型编辑数据集实用性不足的问题,作者提出了 FAME (FActual Multi-task model Editing) 数据集。FAME 有以下优势:
真实:FAME 的所有数据从两个在线数据库 Wikidata 和 DBpedia 收集,保证了数据符合真实世界事实。
多样:FAME 包含 QA,句子补全,完形填空,多项选择,事实核查,对话等多种形式的任务。
高质量:FAME 使用人工核查,抽查数据项并逐个核查数据模板,以确保数据的质量。
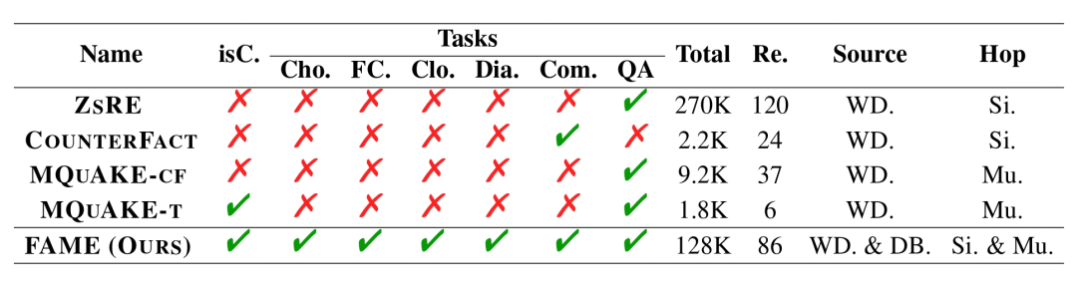
上表展示了FAME和之前模型编辑数据集的对比,可以看出,FAME是少有的使用了真实数据的数据集之一。另外,FAME涵盖了多种任务,并在数据总数、包含的关系数、数据来源、包含的问题形式上均有优势,展现出了其多样性。
SKEME:为真实世界应用设计的模型编辑方法
为了适应模型编辑在现实世界中的需要,作者提出了模型编辑方法 SKEME (Structured Knowledge retrieved by Exact Matching and reranking Editing),这种方法创新地将缓存机制和 RAG 融合,使得其能应对现实世界的变化。

SKEME 分为以下三步:
实体抽取
实体抽取旨在从输入中抽取出关键实体,以使后续的检索过程不受输入形式的影响。
知识检索
受计算机系统中缓存系统的启发,作者设计了类似的机制来存储知识。
知识以知识图谱(knowledge graph)的形式存储,当需要检索时,首先在本地知识库检索。如果在本地知识库未找到,则在外部数据库(如 Wikidata 和 DBpedia)检索,并将检索得到的知识存储在本地。
本地知识库实际上是外部数据的一个缓存。
知识排序和应用
将检索得到的知识按照和输入的相关性重排,并使用 in-context learning 来修正模型的输出。
实验
评价指标
作者分以下几个方面来评价模型编辑方法的效果:
正确率:编辑后的模型输出是否与目标输出精确匹配(EM)。
副作用:作者使用 DD 和 NKL 评价副作用。前者评价模型在不相关事实上的输出是否改变,后者评价编辑前后模型输出改变的剧烈程度。
综合评价:作者提出了一个新的指标 SURE(Statistical and Unbiased Real-world Evaluation)。SURE 将 EM 和 DD 结合起来以评估编辑后模型的实际能力:其中 和 为数据量之比, 和 为指标的重要程度。
效率:作者还评价了方法的时间(Ti)和显存(Me)消耗。
主实验
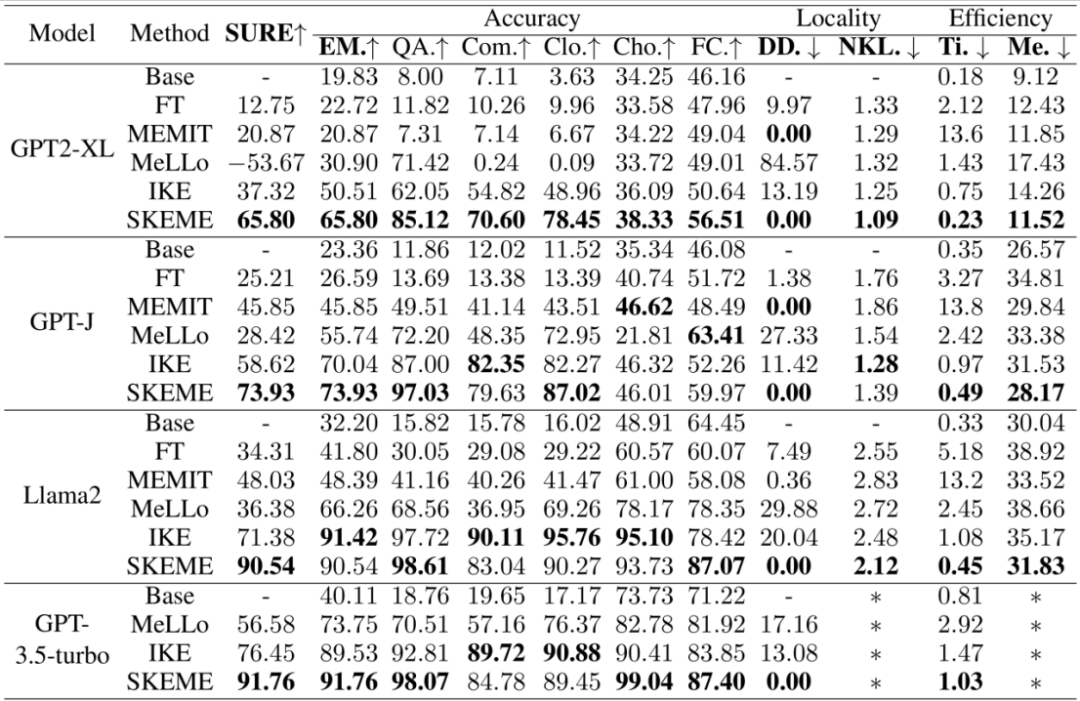
表 2 展示了主实验的结果,结果显示:
base 模型(即未编辑的模型)在各个任务上都表现不佳,显示出这是模型的知识盲区,突出了进行编辑的必要性。
模型在各个任务上的表现展现出了较大的差异。
SKEME仅需要较少的时间和较低的显存消耗,在达到较高准确率的同时有较低的副作用。另外,SKEME 在各个模型、各种任务上均展现出了一致的提升模型能力的效果。
分析实验
为了评价模型编辑方法在复杂的现实世界中的能力,作者设计了一系列的研究问题(Research Questions, RQs),通过模拟现实世界的模型编辑场景来评价模型编辑的能力。
RQ1:事实演变
真实世界中的同一个事实会经历多次变化,如美国总统经历了奥巴马→特朗普→拜登的变化,这要求模型编辑方法能对同一个事实进行多次更新。
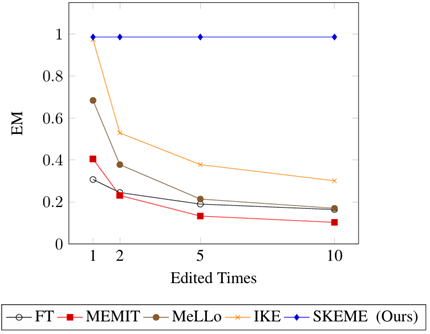
如图所示,即使一个事实只编辑两次,之前的方法效果仍然会有较大下降。作者认为,基于修改参数的方法会因为累积误差而减低模型的能力,而不修改参数的方法因为没有更新机制而导致可能检索得到过时知识。
RQ2:事实推理
一个常见的事实推理情形是多跳问题,为了区分模型内部知识错误和模型推理错误,作者将多跳问题拆分为了多个子问题并将子问题重组为对话任务。
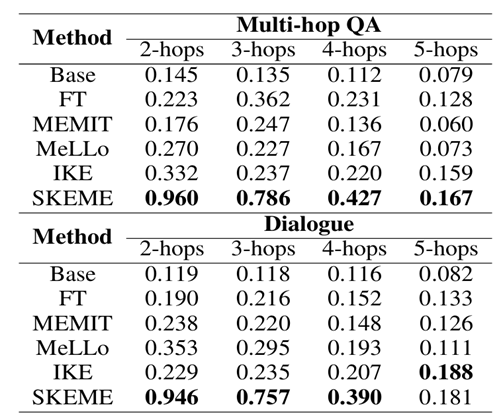
结果显示,SKEME 能在问题跳数较少的时候较好地处理问题,但所有模型编辑方法都难以应对问题跳数较多的情况。
RQ3:大量待编辑的事实
由于真实世界是迅速变化的,可能有大量不同的事实需要编辑,这要求模型编辑方法能处理多个编辑请求。
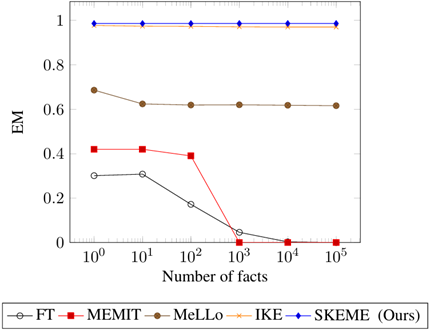
结果显示,修改模型参数的方法在事实数量较多时表现下降,而不修改模型参数的方法表现较为稳定。
RQ4:泛化能力
为了衡量模型编辑方法是否有在多个数据集上泛化的能力,作者使用了几个通用的数据集来评价模型编辑方法的效果。
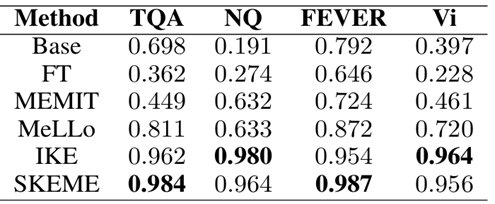
结果显示,SKEME 在多个数据集上展现出了一致的能力,显示出其在现实世界模型编辑上的通用性。
结论
作者提出了模型编辑的实用性需求。
作者提出了 FAME,一个真实、多样、高质量的模型编辑数据集。
作者提出了 SKEME,一种高效、泛化性强、能处理现实世界的复杂变化的模型编辑方法。
作者提出了一系列实验来评价模型编辑方法在现实世界中的可用性,SKEME 在多数任务上表现得很好。
参考文献
[1] Meng K, Bau D, Andonian A, et al. Locating and editing factual associations in GPT[J]. Advances in Neural Information Processing Systems, 2022, 35: 17359-17372.
[2] Levy O, Seo M, Choi E, et al. Zero-shot relation extraction via reading comprehension[J]. arXiv preprint arXiv:1706.04115, 2017.
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦