人工智能咨询培训老师叶梓 转载标明出处
由于云上计算部署的不断扩展,手动在线异常RCA工作流程,如创建故障排除工具,常常使网站可靠性工程师(SRE)应接不暇。为了提高云服务可靠性效率,一系列人工智能运维(AIOps)方法已被广泛应用于RCA,以减少平均解决时间(MTTR)。
本文介绍了RCAgent,这是一个工具增强型大型语言模型(LLM)自主智能体框架,用于实际和注重隐私的工业RCA使用。RCAgent在内部部署的模型上运行,而不是GPT家族模型,能够进行自由形式的数据收集和全面分析。该框架结合了多种增强功能,包括独特的行动轨迹自我一致性(Self-Consistency),以及一系列用于上下文管理、稳定化和导入领域知识的方法。
想要掌握如何将大模型的力量发挥到极致吗?叶老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具(限时免费)。
1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其最大潜力。
CSDN教学平台录播地址:https://edu.csdn.net/course/detail/39987
方法
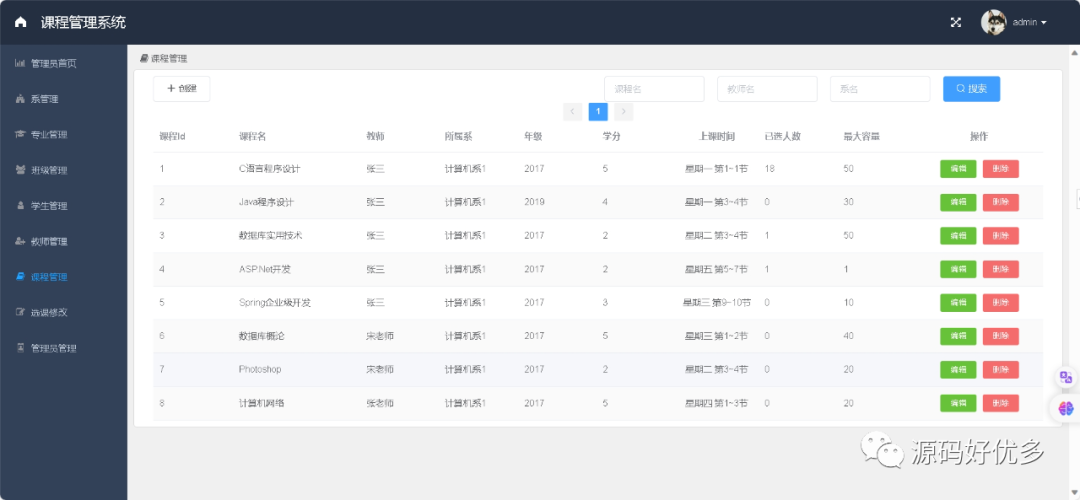
为了系统化和可靠地提示大模型作为工具增强型自主智能体进行云计算的故障根因分析(RCA),提出了RCAgent,这是一个增强型推理和行动框架。Figure 1 展示了决策循环级别的方法论概览。为了清晰起见,将具有思考-行动-观察循环提示的大模型智能体命名为控制器智能体,负责协调行动,而RCAgent还额外使用了称为专家智能体的大模型作为工具,用于特定领域的功能。

与典型的ReAct工具智能体提示框架一致,控制器智能体被注入了三个基本提示:(i)描述思考-行动-观察循环的框架规则,(ii)包含基本云知识的RCA任务指令的任务要求,以及(iii)描述所有可调用工具的工具文档。由于其灵活性和可读性,JSON被选为所有大模型行动步骤中的数据交换格式。还定义了一个名为‘finalize’的工具作为退出点,允许模型自由决定何时以可解析格式报告发现结果。值得注意的是,与原始的ReAct相比,RCAgent因为上下文长度有限而丢弃了少数样本示例。
从ReAct的工具智能体版本开始,提出了几项增强功能,以解决在云RCA中使用工具增强型大模型智能体的挑战。
- 为了应对上下文长度挑战,首先发明了一种压缩令牌使用的观察管理方法。
- 由于大模型本身无法访问并且没有足够的关于云系统领域特定知识,为RCAgent构建了包括大模型增强工具在内的工具。
- 为了解决行动有效性问题,RCAgent具有稳定化方法。
- 最后,为了提高RCAgent的性能,因为使用的是能力较弱的本地托管大模型,所以采用了聚合方法。
观察快照键
在全面的云环境中构建自主智能体时,上下文长度是一个基本挑战。智能体提示中的观察内容,包含大量日志、表项等,是提示膨胀的最主要部分。为了克服从截断和总结观察中丢失信息的问题,提出了观察快照键(OBSK)。Figure 1 展示了OBSK的工作流程。在这个流程中,只向控制器智能体显示观察的头部,并留下一个快照密钥(snapshot key)用于后续引用。构建了一个键值存储,将快照密钥映射到实际观察。当在解析的行动中找到快照密钥时,RCAgent通过键值存储查询并返回相应的观察。这确保了在控制长度的同时,为控制器智能体提供必要的支持信息。
工具准备
数据查询功能被用作信息收集工具,基于大模型的专家智能体作为分析工具,类似于人类SRE执行的数据收集和分析过程。
信息收集工具被设计为易于使用的方式,隐藏了访问云系统数据时的所有无关细节。例如,这些工具只接受简单的参数,如实体的ID。这种语义最小化的工具设置将降低大模型采取有效行动的门槛,防止在大型数据仓库中进行无用探索。此外,为了避免智能体的无效分析,去除了相似信息,并排除了WARNING级别以下的消息。
分析工具被提出以扩展由大模型增强的控制器智能体的领域知识和能力。这种分析工具被称为专家智能体,如Figure 1所示。为RCAgent提供了两个专家智能体作为补充知识工具,称为代码分析工具和日志分析工具。两者都通过零样本链式思考(Chain-of-Thought, CoT)和答案提取指令生成分析和聚合。

代码分析工具以递归方式工作,如Figure 2所示。给定一个类名,代码分析工具在代码库中搜索相应的文件。在大模型读取和分析代码文件后,它被提示建议任何其他有助于分析的类作为支持信息。这些建议将存储在任务队列中,管理所有待处理任务。通过这种穷尽搜索,当没有更多感兴趣的代码文件被推荐,或者所有剩余推荐的文件都是外部依赖时,代码分析工具停止解析。然后,利用大模型总结所有代码文件,其结果作为观察呈现给控制器智能体。

日志分析工具在适应长日志数据的上下文RAG范式中运行。Algorithm 1描述了完整的机制。日志被分割成行,并构建边,边的权重是随着文档距离指数衰减的余弦相似度。这产生了一个加权无向密集图,其中行作为顶点,描述了行之间的相关性,当其他行插入中间时,这种相关性会减弱。然后使用Louvain社区检测对图进行聚类,并通过贪婪切换最小数量的聚类标签来去除聚类之间的重叠。这种聚类作为语义分区,结果的日志块随后以每个块一轮的方式输入到日志智能体中,执行检索增强生成(Retrieval-Augmented Generation, RAG)。此外,指导专家智能体通过直接复制日志内容来输出支持其分析的证据,防止分析示例而非分区块的幻觉。如果大模型列出的证据不能与块进行模糊匹配,则丢弃分析结果。因此,确保了对长非自然语言的可靠RAG。
稳定化
为了克服由噪声数据和能力较弱的本地大模型引起的行动有效性退化,引入了两种稳定化方法。
JSON修复
在工具增强型大模型自主智能体的实际应用中,结构化推断可解析数据(例如JSON)是一个重要问题。采用了一种直观有效的方法来生成结构化交换数据,名为JsonRegen。在大模型推断之前,所有可能对应JSON中控制符号的敏感字符都被替换为不敏感的字符,以获得干净的提示。当简单的清理无法使JSON样式字符串可解析时,将执行再生过程。为了强制大模型理解JSON结构,指导它将内容转换为YAML。然后提示大模型用相同的结构和内容重新生成JSON。再生过程进行几轮,直到解析出有效的JSON。
错误处理
先前的工作表明,工具调用中的大模型倾向于传播错误,限制了探索性行动。这些问题在能力较弱的大模型中更加明显。使用预定义的标准将问题行动或状态标记为错误。向控制器智能体提供错误消息和建议,包括这些情况:使用相同参数集对无状态工具的重复调用,对专家智能体的琐碎输入,以及未经彻底调查就提前完成。这些错误消息可以通过提醒控制器智能体减少无意义行动的频率。
自我一致性聚合
自我一致性(SC)已在各种封闭的NLP任务中证明了其有效性,而在大模型智能体中聚合采样的开放式多步生成(如RCA)尚未充分探索。因此,提出将SC范式应用于大模型自主智能体的自由形式生成。
在实验中,使用了两种方法来将SC应用于文本数据:
-
投票与嵌入:推广了无权重SC(多数投票)的理念,这在所有任务中表现最佳。投票可以重写为arg max𝑖(Sim(a𝑖,1𝐾Í𝐾𝑗(a𝑗))),其中𝐾是样本数量,a𝑖是一个一热向量,代表第𝑖个样本结果,每个位置作为一个候选选择或数值结果。将a替换为文本输出的语义嵌入。直观地说,意味着选择最接近多数的文本结果。
-
用大模型聚合:考虑到生成内容的多样性,提示大模型聚合候选项,并以相似的形式和长度输出。
SC已在CoT推理路径上进行了全面测试,并且可以自然地应用于ReAct风格的轨迹。然而,直接采样多个思考-行动-观察周期可能会很昂贵。当某些行动,如激活专家智能体,需要大量消耗时,这尤其昂贵。此外,没有任何历史行动或少数样本示例的随机采样会导致错误泛滥,例如连续调用不存在的工具。因此,提出了一种名为轨迹级自我一致性(Trajectory-level Self-Consistency, TSC)的中间采样方法,如Figure 3所示。具体来说,只有在控制器智能体进入最终确定阶段时,才开始采样。这种采样策略在轨迹样本之间共享了大部分初步步骤,并减少了不必要的消耗。此外,来自贪婪解码的更稳定的行动历史提供了示例,而无需额外消耗上下文长度的少数样本示例,从而抑制了采样的有效性下降。这种方法在完整过程SC和单步CoT SC之间取得了平衡。

实验
在阿里巴巴云的实时计算平台上开发和评估了RCAgent,该平台是一个基于Apache Flink的企业级、高性能系统,能够进行实时流数据计算。在高峰时段,该系统每秒可以处理1亿条数据记录。
模型配置
实现基于Vicuna-13B-V1.5-16K模型,使用单个NVIDIA A100 SXM4 GPU(80 GB)上的vLLM后端。默认使用贪婪解码策略,以获得更好的可重复性和稳定性。在需要随机采样的自我一致性过程中,使用Vicuna的默认配置。使用的嵌入模型是GTE-LARGE,因为它在MTEB上的结果略优于text-embedding-ada-002,提供了一个内部可部署的替代品。对于自我一致性结果,默认使用10个输出样本。采用逐步自我一致性(SC),只接受在贪婪解码轨迹后同步完成的样本,不允许额外的行动步骤。
数据集准备
为了根因分析,收集了一个月云系统历史中的15,616个异常作业数据,包括无法恢复的失败或在6分钟内无法启动的作业。过滤数据后,获得约5,000个具有实质性日志内容的非平凡异常作业。使用从经验丰富的SRE领域知识中提炼出的大型规则集Flink Advisor,为这些作业创建分析结果。由于异常的不平衡性,即大部分异常具有相同的根本原因,将成功分析的作业减少到161个离线数据集。减少是按照类别平衡约束进行的,即不超过两个作业具有相同的根本原因。这些作业所需的注释包含四个项目:根本原因、解决方案、证据和责任确定。首先使用大模型从Flink Advisor中总结分析结果,并输出上述四个项目。然后SRE团队进行校对和注释目标输出。保证注释不显示像“此异常的根本原因是...”这样的无信息模式,这会导致一些语义得分不可靠。
可用的数据源,为大模型智能体构建信息收集工具,包括:
- 三个级别的日志数据:平台、运行时和基础设施,存储在阿里巴巴云的SLS(简单日志服务)中。
- 包含顾问服务历史的数据库。
- 包含顾问服务代码的仓库。
对于日志和数据库条目,只能检索到异常检测时间之前的数据,防止分析未来信息,遵循实际使用。

Table 1 和 Table 2 展示了在Flink作业上根本原因预测和解决方案生成的结果。RCAgent在所有方面的综合RCA中优于原始的ReAct,包括根本原因、解决方案和证据预测。性能优势在所有指标中都是明显和一致的,包括在根本原因和解决方案预测子任务中与ReAct相比,METEOR分别提高了+8.71和+6.52。采用LLM总结的TSC聚合,RCAgent的整体性能得到了进一步提升,特别是在解决方案预测方面,METEOR提高了+3.51,BLEURT提高了+4.50,G-Helpfulness提高了2.28%。这种提升可以解释为解决方案采样的多样性更广。
评估指标
除了包括METEOR、NUBIA(6维)、BLEURT和BARTScore(F-Score, CNNDM)的语义指标分数外,还使用了额外的嵌入分数(EmbScore),即实验中默认嵌入模型的余弦相似度。还遵循使用更强大的模型来估计模型预测的常见做法。使用贪婪解码的gpt-4-0613,这是GPT4的一个冻结版本,以获得更好的可重复性。提示模型判断根本原因和解决方案预测的准确性和有用性,分别标记为G-Correctness和G-Helpfulness,并给出0到10的分数。

Table 3 展示了方法的证据的语义分数。RCAgent在所有方面的综合RCA中优于原始的ReAct,包括根本原因、解决方案和证据预测。性能优势在所有指标中都是明显和一致的。

Table 4 展示了不同设置的动作轨迹统计数据。RCAgent实现了99.38%的通过率和7.93%的无效率,意味着几乎完美的稳定性和显著的优势。当LLM专家或OBSK被移除时,控制器智能体仍然保持超过90%的通过率,而两者的缺失都导致了错误倾向的探索,将其一些行动转向冗余的工具调用。移除JsonRegen显著损害了稳定性,因为无效的数据交换激增。

Figure 4 展示了不同规模和方法的自我一致性性能。统计数据显示,每种自我一致性方法都一致地提高了RCAgent在BARTScore和NUBIA方面的性能。当样本数量达到20时,这种增强似乎趋于平稳。在所有指标中,TSC由于其多样化的行动采样而带来优越性。随着样本数量的增加,LLM聚合比嵌入投票表现得更好,并且随着候选池的增长,这种差距扩大,说明了LLM聚合能够提供更全面的结果。
论文链接:https://arxiv.org/pdf/2310.16340