长文本(Long-context)大模型性能的优劣,在很大程度上取决于其能否全面理解长上下文场景下的复杂信息。
然而,现有的合成有监督微调(SFT)数据由于缺少人类核验,往往会影响长文本大模型的性能,导致 SFT 模型存在固有的缺陷,如幻觉和无法充分利用上下文信息等。
原则上,通过适当的奖励信号进行强化学习已被证明能有效地减少 SFT 模型的缺陷,使其更好地与人类偏好对齐,但在长上下文场景下如何获得可靠的奖励信号,仍是一个未被探索的问题。
如今,来自清华大学、中国科学院大学和智谱的研究团队在这一领域迈出了重要一步——
他们提出了一个名为 LongReward 的新方法,旨在利用现有的大语言模型(LLM)从四个人类价值维度(帮助性、逻辑性、忠实性和完整性)为长文本模型的回复提供奖励,并结合强化学习进一步提升模型的性能,从而有效地改进 SFT 模型。

论文链接:
https://arxiv.org/abs/2410.21252
GitHub 地址:
https://github.com/THUDM/LongReward
Hugging Face:
https://huggingface.co/datasets/THUDM/LongReward-10k
研究表明,LongReward 不仅可以显著提高模型的长文本性能,还能够增强它们遵循简短指令的能力。另外,带有 LongReward 的长文本 DPO 和传统的短文本 DPO 可以同时使用,而不会影响任何一方的性能。
研究方法
LongReward 通过奖励信号解决了 SFT 在长文本模型中因缺少人类标注而导致的数据质量问题。
具体而言,LongReward 利用一个现有的大模型(M_judge,该研究中使用的 GLM-4)从四个人类重视的价值维度——有用性、逻辑性、忠实性和完整性——为长文本模型的回复提供奖励。这些维度覆盖了模型输出的各个关键方面,确保在长文本情境下对生成内容进行全面评估。每个维度的评分范围是 0 到 10,最终奖励是这些分数的平均值。
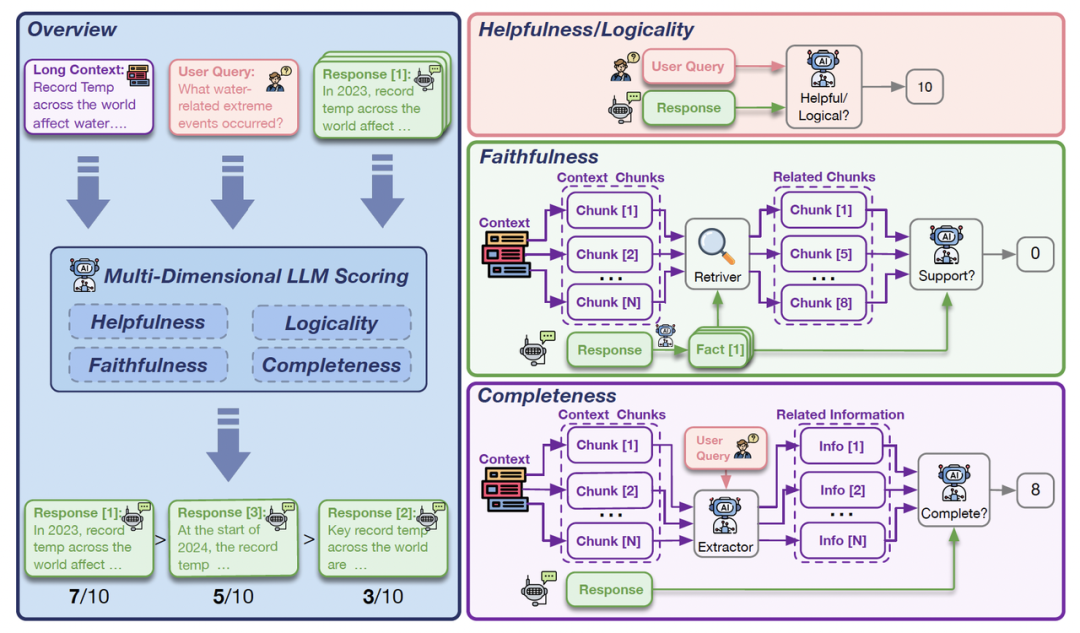
图|LongReward 图示
1.帮助性(Helpfulness)
-
评估模型回复是否与问题相关,是否提供了有用的信息,是否满足了用户的需求和要求。
-
由于帮助性主要依赖于问题和回复内容,基本与上下文无关,研究团队让 M_judge 通过少样本学习和思维链 (CoT) 对问题和回答进行评分。
2.逻辑性(Logicality)
-
评估模型回复的不同部分是否逻辑一致,观点是否一致,推理和计算是否正确,是否存在自相矛盾。
-
与帮助性类似,研究团队让 M_judge 通过少样本学习和思维链(CoT)对回答进行评分,找出可能的逻辑错误。
3.忠实性(Faithfulness)
-
评估模型回答中事实信息的比例是否与上下文一致。
-
要求 M_judge 首先将回答分解为事实性陈述,再判断每个陈述是否由最相关的上下文支持。
-
为了适应长上下文场景,将回答分解为句子级别的事实性陈述,并忽略不含事实信息的功能性句子。
4.完整性(Completeness)
-
评估模型回答是否涵盖了上下文中与问题相关的所有关键点,是否提供了足够的信息和细节来满足用户的需求。
-
首先将上下文分解为粗粒度的块,并让 M_judge 从每个块中提取与问题相关的信息。
-
然后将所有提取的相关信息拼接起来,再利用 M_judge 评估模型回复的完整性,即是否涵盖了所有重要信息。
在评分机制基础上,LongReward 与离线强化学习(RL)算法 DPO 结合,形成一个完整的 RL 框架。DPO 的目标是通过偏好数据集优化模型输出,使其更符合偏好要求。
具体来说,通过多次采样长文本 SFT 模型的回答并使用 LongReward 给每个回答打分,研究团队可以自动构建 DPO 所需的偏好数据集。
实验结果
他们的实验表明,LongReward 不仅显著提高了模型的长文本性能,还增强了它们遵循简短指令的能力。在 Llama-3.1-8B 和 GLM-4-9B 模型上进行的实验显示,使用 LongReward 的 DPO 模型在长文本任务上的性能分别比 SFT 模型提高了 4.9% 和 5.5%,超过了所有基线方法。
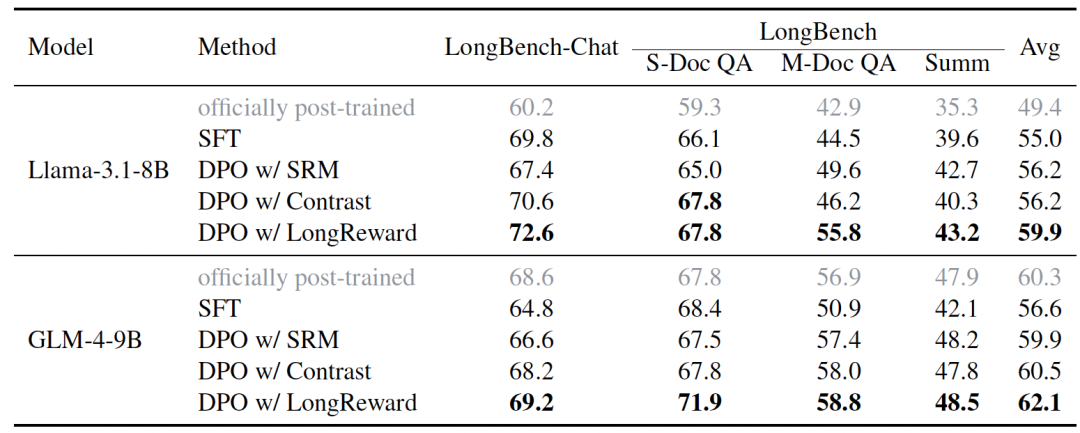
图|使用 GPT-4o 对长文本基准进行自动评估的结果
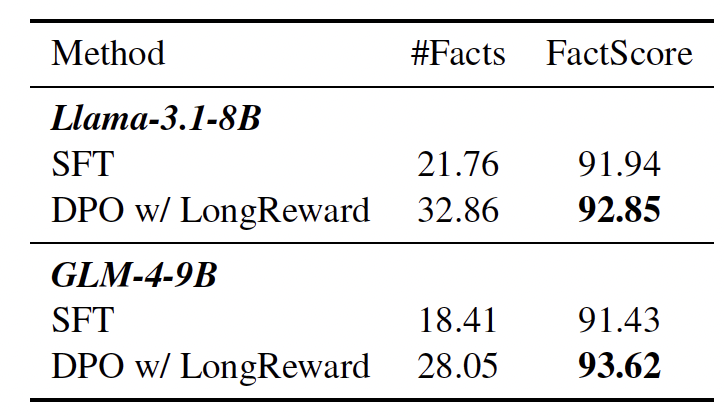
图|以 GPT-4o-mini 为评判标准,随机抽取了 260 道来自 LongBench-Chat 和 LongBench 的问题,得出 SFT 和 dLongReward+DPO 版本的事实分数。

图|在一组 464 个人工标注的长文本偏好对中,将不同评分方法与人类偏好进行比对,其中的提问和回答分别来自 LongBench-Chat 和 Llama-3.1-8B 的 SFT 检查点。
此外,人类评估进一步验证了 LongReward 与人类偏好的良好一致性,并从所有维度(即有用性、逻辑性、忠实性和完整性)帮助改善了长文本模型,比 SFT 基线高出 46%。
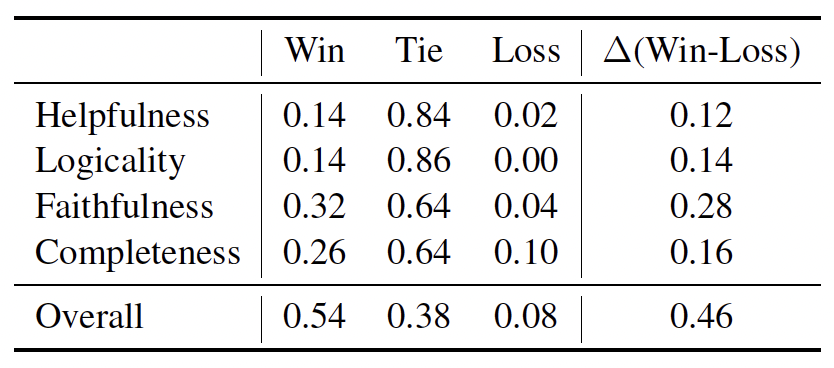
图|LongReward+DPO 版本的 Llama-3.1-8B 在 LongBench Chat 上与 SFT 基线对比的人工评估结果
同时,他们发现 LongReward 也有助于模型的简短指令遵循能力,并且可以很好地融入标准的短文本 DPO 中,共同提升长文本和短文本性能。
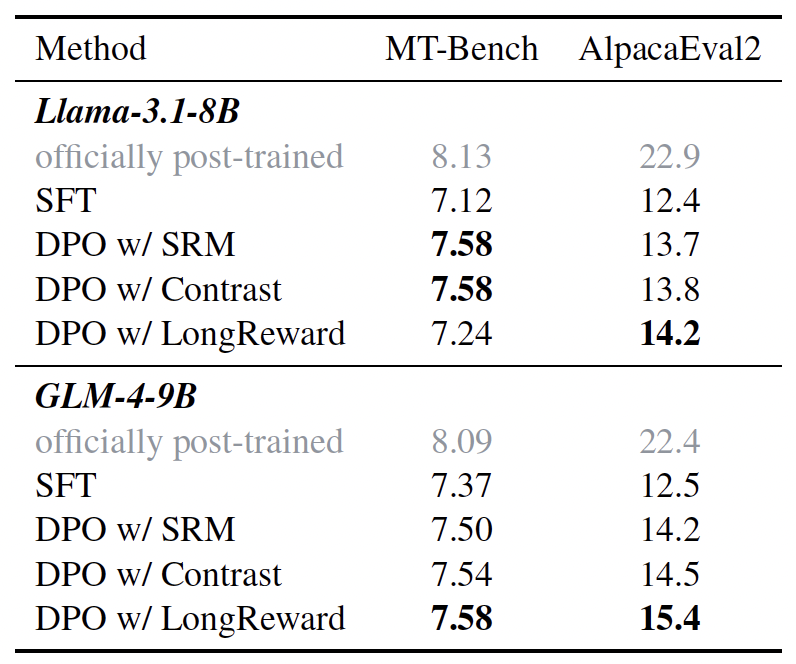
图|不同模型在短文本指令跟随 benchmarks 上的表现
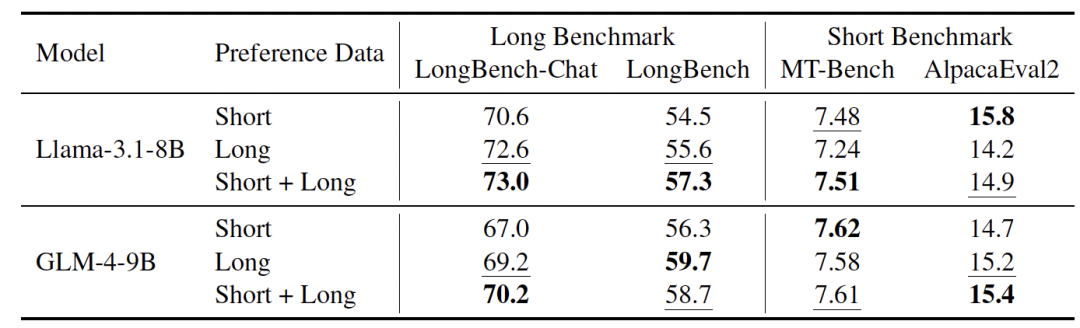
图|使用不同偏好数据集的 DPO 模型性能
不足与展望
当然,这一研究也存在一定的局限性,主要包括以下三点:
首先,LongReward 的评估依赖于高精度、对齐良好的 LLM 模型(如 GLM-4),并且每个 QA 实例需要花费数十次 API 调用。未来,还需要尝试训练更小的长文本奖励模型,从而实现更快、更便宜的奖励计算。
此外,由于计算资源有限,该研究只在最大训练长度为 64k 的 10B 级模型上进行,限制了对更大规模模型和长序列的探索。
最后,从数据角度来看,该研究主要关注用户密集型的长上下文场景,如长文档 QA 和总结。未来可以尝试将 LongReard 推广到其他更高级的长指令任务,如终身对话和长历史 agent 任务,也是一个很有前景的方向。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓