1:概念
在MySQL中,
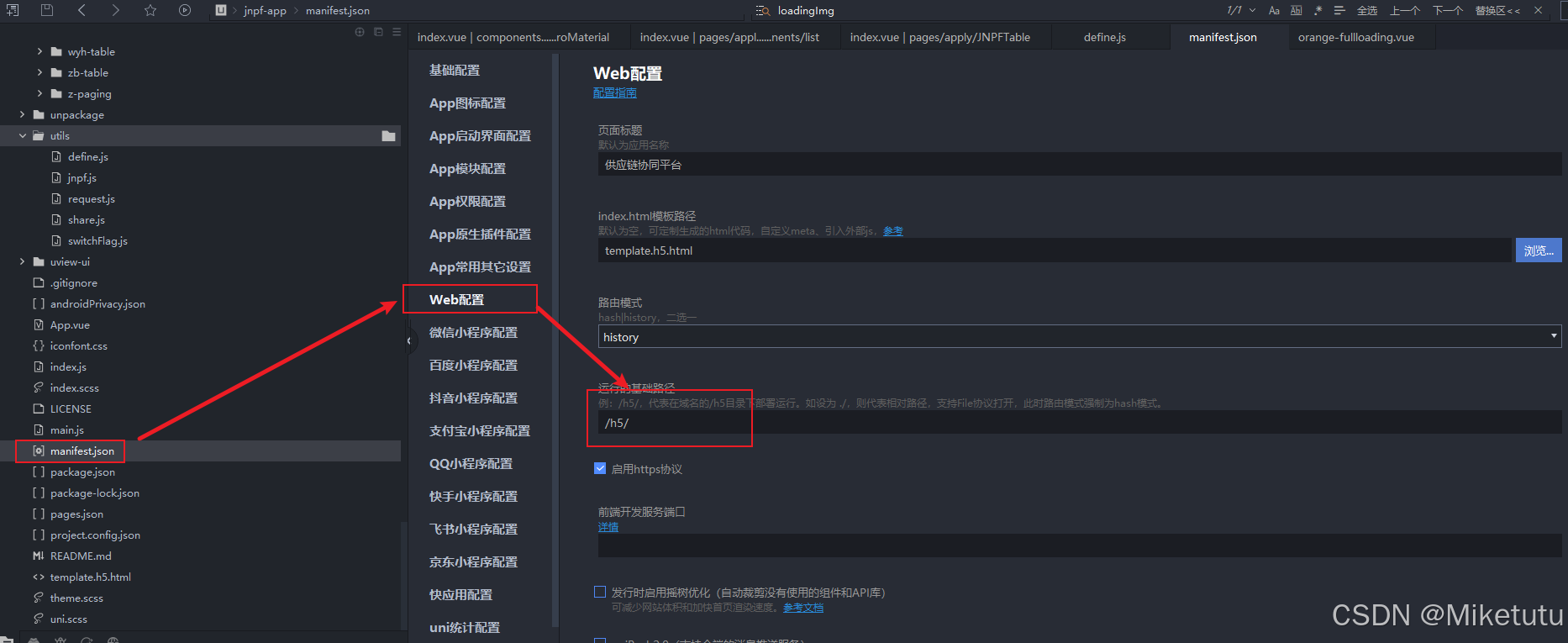
PARTITIONS关键字用于定义表的分区。分区是一种数据库设计技术,用于将表中的数据分散存储在多个物理部分,但逻辑上仍然表现为一个单一表。这样做可以提高查询的性能,特别是在处理大量数据时。详细来说: -PARTITIONS 128指的是为这个表创建128个分区。这意味着数据会被分散到128个不同的部分,这可以帮助提高查询和维护的性能,尤其是对于非常大的数据集。 -PARTITION p0 ENGINE = InnoDB MAX_ROWS = 0 MIN_ROWS = 0这行定义了一个特定的分区p0。其中: -ENGINE = InnoDB指定了此分区使用InnoDB存储引擎。InnoDB 是MySQL默认的存储引擎,支持事务处理,行级锁定和外键。 -MAX_ROWS = 0和MIN_ROWS = 0分别定义了这个分区的最大行数和最小行数。当设置为0时,表示没有指定限制。 综上所述,这些设置用于配置MySQL表的物理存储细节,使得表可以根据指定的参数进行分区管理,旨在优化性能和数据管理效率。使用分区通常适用于数据量极大的情况,可以通过分区来提高查询速度,以及更高效的维护数据。
2:例子
分区能提高查询性能的一个关键理由在于它能够减少需要扫描的数据量,尤其是对于涉及大数据集的查询。分区表是逻辑上的一个整体,但物理上被分割成多个独立的部分,允许数据库优化查询,通过只访问包含所需数据的分区来减少访问的数据量。下面通过一个具体的例子来说明如何通过分区提高查询性能:
示例背景
假设你有一个数据库存储电商平台的订单信息,这个表名为 orders,包含数千万条记录。表结构包括 order_id, customer_id, order_date, amount 等字段。
不使用分区
如果没有应用分区,当执行查询特定时间段内的订单时(比如查询2022年的所有订单),数据库可能需要扫描整个表来查找符合条件的记录。随着数据量的增长,这样的查询将变得越来越慢。
应用分区
假设你按照年份对 orders 表进行分区,每一个年份的数据存储在一个单独的分区中:
CREATE TABLE orders (order_id INT AUTO_INCREMENT,customer_id INT,order_date DATE,amount DECIMAL(10, 2),PRIMARY KEY (order_id, order_date)
) PARTITION BY RANGE (YEAR(order_date)) (PARTITION p2020 VALUES LESS THAN (2021),PARTITION p2021 VALUES LESS THAN (2022),PARTITION p2022 VALUES LESS THAN (2023),PARTITION p2023 VALUES LESS THAN (2024)
);
查询性能的提升
现在,当查询2022年的订单时,SQL只会在 p2022 这一个分区中查找数据:
SELECT * FROM orders WHERE order_date BETWEEN '2022-01-01' AND '2022-12-31';
MySQL数据库知道2022年的数据只存在于 p2022 分区,在处理查询时,它会直接跳过其他分区,只扫描这一个分区。这样做显著减少了需要检查的数据量,从而加快了查询速度。
总结
分区实际上是提供了一种物理上的数据组织方式,使得查询操作能够更加聚焦于相关的数据段,避免了全表扫描,从而提升了查询效率,特别是在数据量非常大的情况下。这种方式特别适合于那些可以根据某些明显的业务逻辑(如时间、地区等)被分割的大表。
3:PARTITION BY类型
在 MySQL 中,PARTITION BY 可以使用几种不同的分区策略,每种策略适用于不同的使用场景。以下是主要的分区类型:
-
1:RANGE 分区:
- 将数据根据指定的列的值分配到不同的分区中,每个分区包含一个值范围。
- 例子:按年份分区,每年的数据存储在不同的分区。
CREATE TABLE employees (id INT,name VARCHAR(30),hired DATE)PARTITION BY RANGE (YEAR(hired)) (PARTITION p0 VALUES LESS THAN (1991),PARTITION p1 VALUES LESS THAN (1996),PARTITION p2 VALUES LESS THAN (2001));-
2:LIST 分区:
- 类似于 RANGE 分区,但是分区依据是列值匹配一个列表,而不是值范围。
- 例子:按部门编号分区,特定编号的部门在特定分区。
CREATE TABLE employees (id INT,name VARCHAR(30),dept_id INT)PARTITION BY LIST (dept_id) (PARTITION p0 VALUES IN (1, 2, 3),PARTITION p1 VALUES IN (4, 5, 6),PARTITION p2 VALUES IN (7, 8, 9));-
3:HASH 分区:
- 使用用户定义的表达式对某个列的值进行哈希处理,根据哈希结果将数据分配到不同的分区。
- 例子:按员工 ID 的哈希值分区。
CREATE TABLE employees (id INT,name VARCHAR(30))PARTITION BY HASH (id) PARTITIONS 4;-
4:KEY 分区:
- 与 HASH 分区类似,但是哈希键是一个或多个列,由 MySQL 自动管理哈希函数。
- 例子:使用员工名字作为分区键。
CREATE TABLE employees (id INT,name VARCHAR(30))PARTITION BY KEY (name) PARTITIONS 4;-
5:LINEAR HASH 分区和LINEAR KEY 分区:
- 这些是 HASH 和 KEY 分区的变体,区别在于使用线性哈希算法,这种算法在分布数据时更均匀。
- 例子:线性哈希分区。
CREATE TABLE employees (id INT,name VARCHAR(30))PARTITION BY LINEAR HASH (id)PARTITIONS 4;-
6:SUBPARTITION(子分区):
- 子分区是在已经定义的任何分区类型上再次进行分区的方法,提供多级分区策略。
- 例子:按年份分区,每个年份分区内按部门进行子分区。
CREATE TABLE employees (id INT,dept_id INT,hired DATE)PARTITION BY RANGE (YEAR(hired)) SUBPARTITION BY HASH (dept_id) (PARTITION p0 VALUES LESS THAN (1991) ( SUBPARTITION s0, SUBPARTITION s1),PARTITION p1 VALUES LESS THAN (1996) ( SUBPARTITION s2, SUBPARTITION s3));这些分区类型为数据库管理员提供了灵活的数据管理选择,可以根据不同的查询模式和数据访问模式进行优化。