|记昨日与国内某Top 1&2 医院科室老师及团队探讨技术、医学、信仰与责任而有感而发。

生成式基础大模型正在成为临床辅助甚至医学探索领域的宝贵工具。尽管我们在国内看到了很多企业或实验室联合医疗机构在如医疗记录生成、临床表型辅助诊疗、医疗知识问答交互、医院管理决策甚至于科研探索等方向进行了基于LLM的深入探索与场景落地。
然而,尽管它们前景广阔,但在更复杂的涉及医学深度知识推理与临床过程中的复杂决策任务中如何最好地利用大型语言模型 (LLM) 仍是一个悬而未决的问题。
同时,随着近期OpenAI o1模型的发布以及多模态大模型的快速进展,我们看到了在不管在形式化概念空间领域也好,还是在真实世界空间智能下领域,推理时 (test-time compute) 正在纳入到scaling law整体扩张版图中的一部分,从而也让我们可以想象到不管来自于从模型内部神经网络的reasoning还是到跨多模型间在面向复杂任务领域下诸如协作时、交互时、规划拆解时等更多scaling law下其蕴含于其中相同的本质与延展的可能...如在复杂的跨多学科临床决策 (MDT) 、大型平台型临床试验及多学科交叉科研探索等领域。
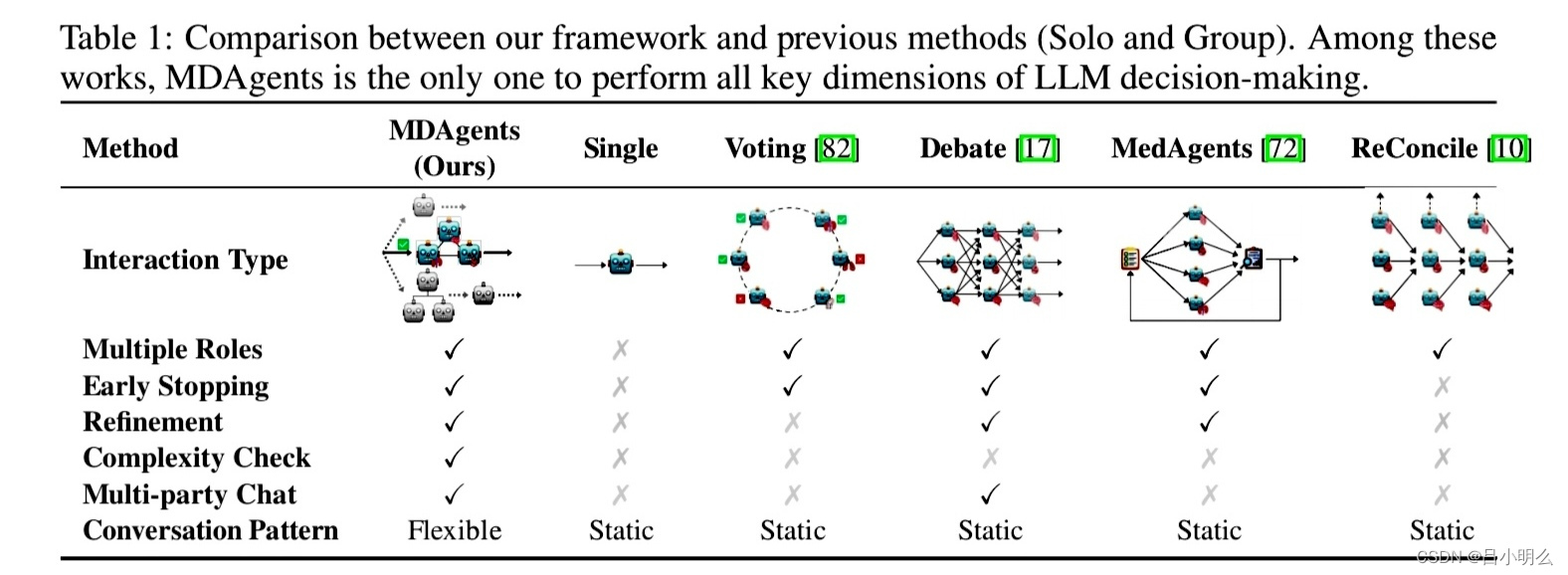
近日,MIT、Google Research和首尔国立大学医院的研究人员提出了一种新颖的多智能体框架 MDAgents,它通过自动为 LLM团队分配协作结构来帮助解决这一差距。

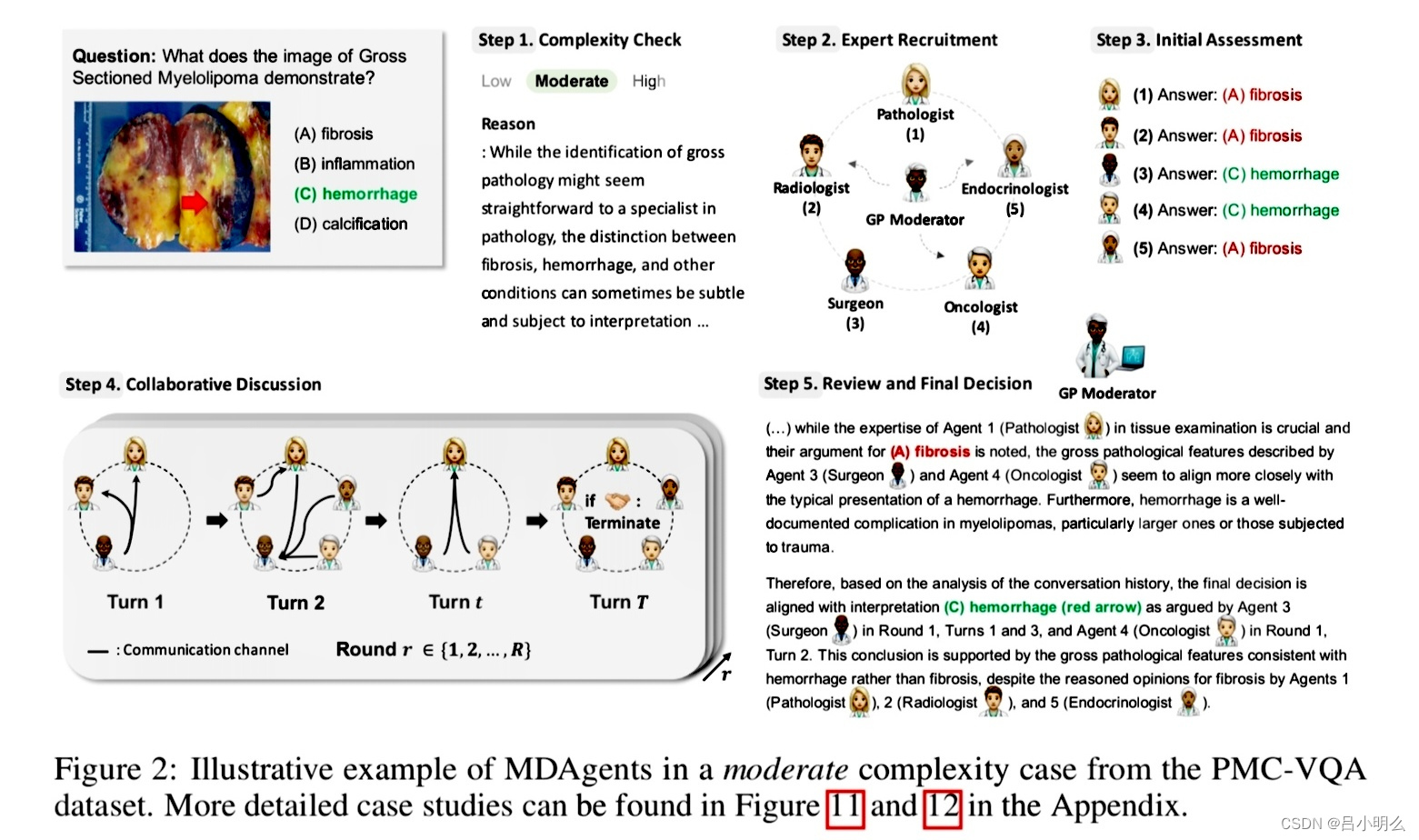
具体来说,MDAgents作为一个多智能体框架,旨在根据医疗任务的复杂性动态分配 LLM 之间的协作,模拟现实世界的医疗决策,其框架围绕医疗决策的四个关键阶段构建:
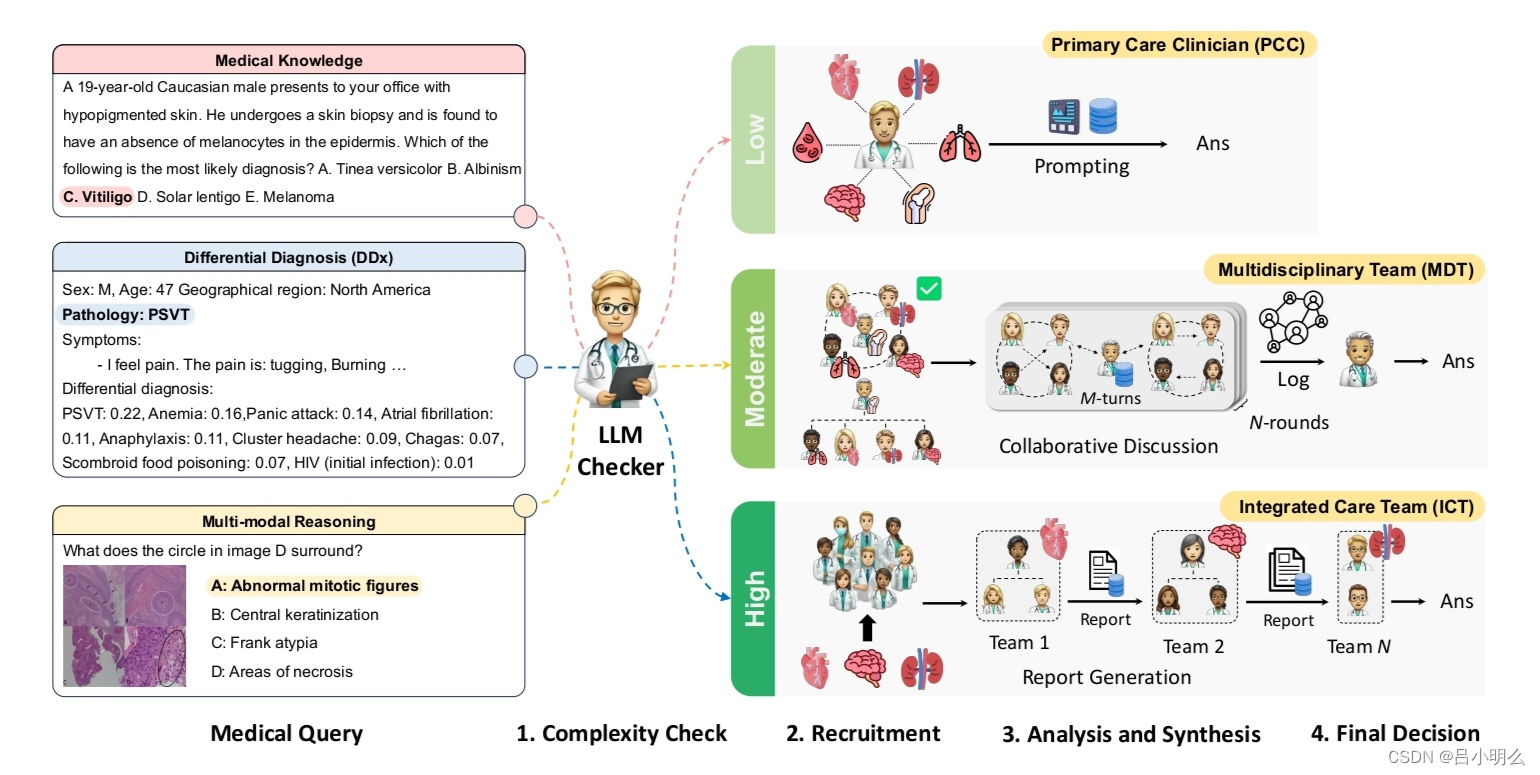
- 首先评估医疗查询的复杂程度,将其分为低、中、高;
- 根据此评估,招募合适的专家:针对较简单的病例,招募单个临床医生;针对较复杂的病例,招募多学科团队;
- 然后,分析阶段将根据案例的复杂程度采用不同的方法,包括从个人评估到协作讨论;
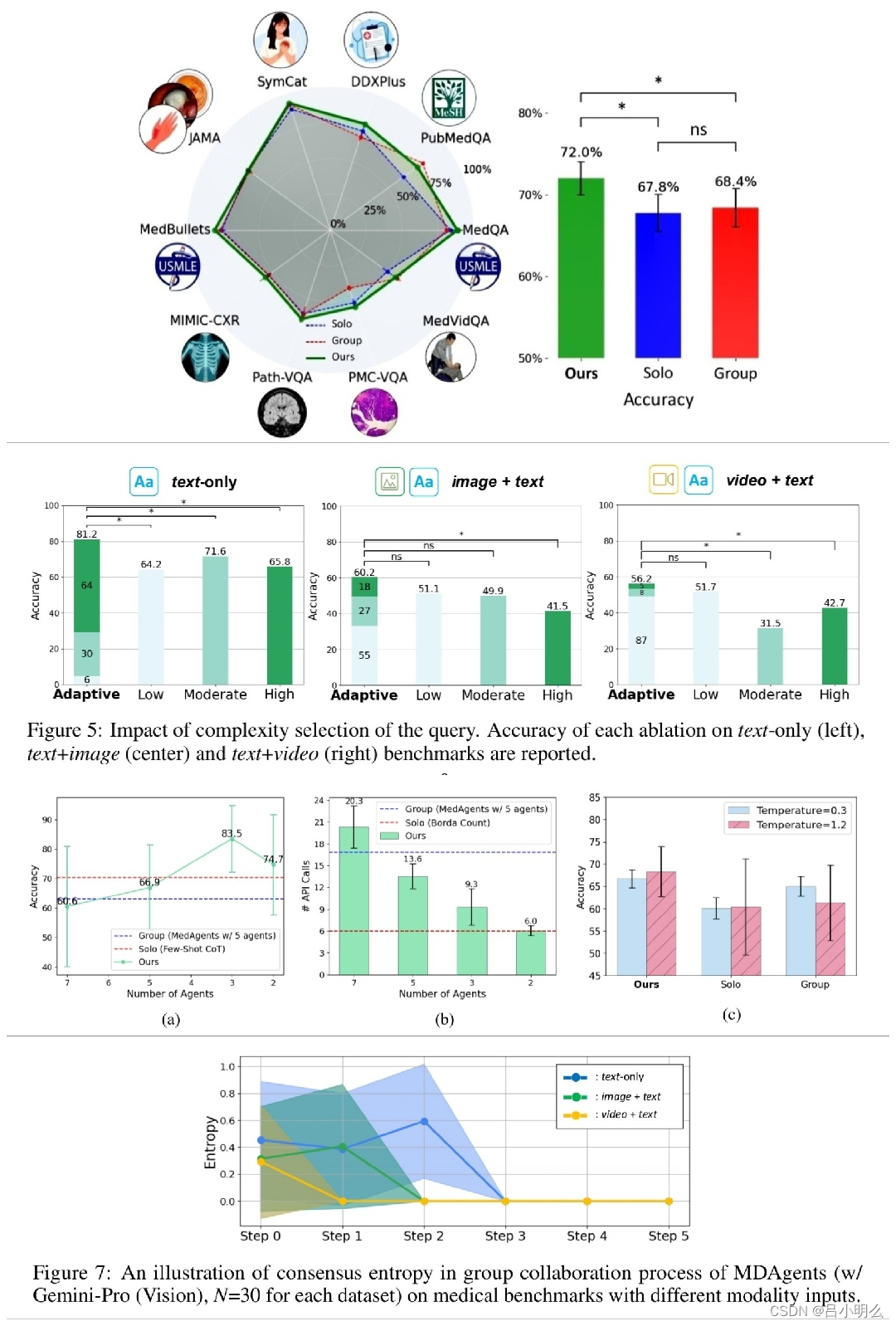
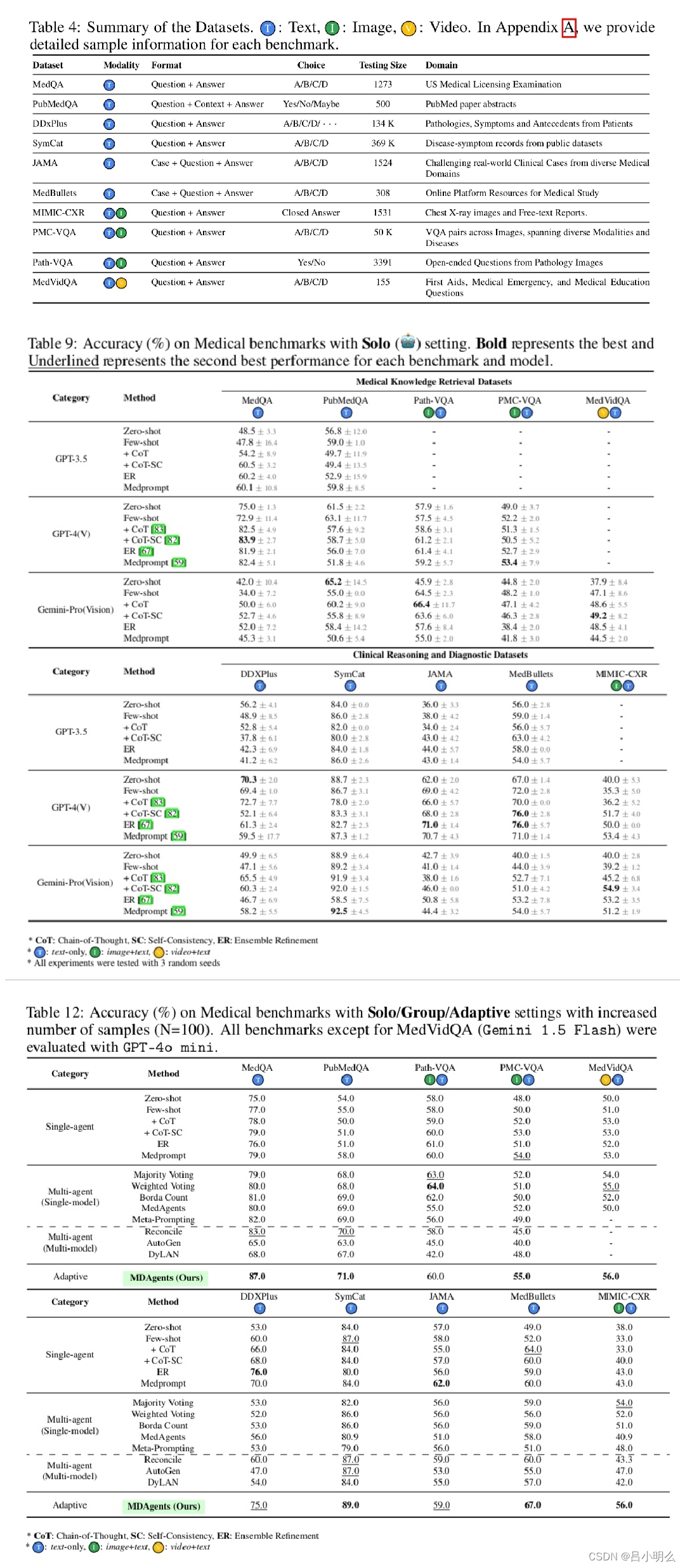
- 最后,系统综合所有见解以形成结论性决策,准确的结果表明,与单智能体和其他多智能体设置相比,MDAgents 在各种医疗基准上都具有有效性。
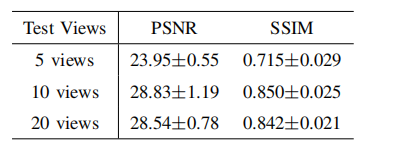
结果上来看,MDAgents在各种医疗基准测试中表现良好,在10个基准测试中的7个中超越了之前的方法,准确率提高了4.2%;关键步骤包括评估任务复杂性、选择合适的智能体和综合响应,通过小组评审可将准确率提高11.8%;MDAgents还通过调整智能体使用来平衡性能和效率等。


我想在新的scaling law下,不管是类o1模型的隐性的参数化reasoning还是显性的设计灵活的模型间或与人类通信协作下的Multi-agent,未来必将touch到更复杂任务领域,那时人类与AI两者的关系亦值得我们当下去思考和规划。
今年,我们也看到国内外很多研究机构或科技公司(如Google,我所服务的企业)均发布了在医疗领域包括基础模型在概念或真实空间中的Self play RL训练框架(Google)、多模态融合框架(Stanford)、循证可解释性框架、复杂推理-时、Multi-agent(清华)、RAG等技术,并依旧尝试在复杂医学领域探索前行,我想这亦不光是医工人才们对技术信仰的追求,而是更多的一份对未来的一种责任。
在我之前多篇博客文章中也有诸多涉及医疗+AI大模型的观点文章,大伙感兴趣阅读可回顾参考,也感谢大家一直以来的捧场与互动。