书接上文:图数据库 | 4、图数据库三大组件之一 ——图计算 (上)-CSDN博客
结合计算效率来评估与设计图计算所需的数据结构。
存储低效性或许是相邻矩阵或关联矩阵等数据结构的最大缺点,尽管它有着O(1)的访问时间复杂度。例如通过数组下标定位任何一条边或顶点所需的时间是恒定的O(1),相比而言,相邻链表对于存储空间的需求要小得多,在工业界中的应用也更为广泛。例如Facebook的社交图谱(其底层的技术架构代码为Tao/Dragon)采用的就是相邻链表的方式,链表中每个顶点表示一个人,而每个顶点下的链表表示这个人的朋友或关注者。
这种设计方式很容易被理解,但是它可能会遇到热点问题,例如如果一个顶点有1万个邻居,那么链表的长度有10 000步,遍历这个链表的时间复杂度为O(10 000)。在链表上的增删改查操作都是一样的复杂度,更准确地说,平均复杂度为O(5000)。另一个角度来看,链表的并发能力很糟糕,你无法对一个链表进行并发(写)操作。事实上,Facebook的架构中限定了一个用户的朋友不能超过6000人,微信中也有类似的朋友人数限制。
现在,让我们思考一个方法,一种数据结构可以平衡以下两件事情。
·存储空间:相对可控的、占用更小的存储空间来存放更大量的数据。
·访问速度:低访问延迟,并且对并发访问友好。
在存储维度,当面对稀疏的图或网络时,我们要尽量避免使用利用率低下的数据结构,因为大量的空数据占用了大量的空闲空间。
以相邻矩阵为例,它只适合用于拓扑结构非常密集的图,例如全连通图(所谓全连通指的是图中任意两个顶点都直接关联)。前面提到的有向图,如果全部连通,则至少存在30条有向边(2×6×5/2),若还存在自己指向自己的边,则存在36条边,那么用相邻矩阵表达的数据结构是节省存储空间的。
然而,在实际应用场景中,绝大多数的图都是非常稀疏的[我们用公式“图的密度=(边数/全联通图的边数)×100%”来衡量,大多数图的密度远低于5%],因此相邻矩阵就显得很低效了。
另一方面,真实世界的图大多是多边图,即每对顶点间可能存在多条边。例如交易网络中的多笔转账关系,这种多边图不适合采用矩阵数据结构来表达(或者说矩阵只适合作为第一层数据结构,它还需要指向其他外部数据结构来表达多边的问题)。
相邻链表在存储空间上是大幅节省的,然而链表数据结构存在访问延迟大、并发访问不友好等问题,因此突破点应该在于如何设计可以支持高并发、低延迟访问的数据结构。在这里,我们尝试设计并采用一种新的数据结构,它具有如下特点:
·访问图中任一顶点的时耗为O(1);
·访问图中任意边的延迟为O(2)或O(1)。
以上时耗的复杂度假设可以通过某种哈希函数来实现,最简单的例如通过点或边的ID对应的数组下标来访问具体的点、边元素来实现。顶点定位的时间复杂度为O(1);边仅需定位out-node和in-node,时耗为O(2)。在C++中,面向以上特点的数据结构最简单的实现方式是采用向量数组(array of vectors)来表达点和边:
vector <pair<int,int>> a_of_v[n];动态向量数组可以实现极低的访问延迟,且存储空间浪费很小,但并不能解决以下几个问题:
·并发访问支持;
·数据删除时的额外代价(例如存储空白空间回填等)。
在工业界中,典型的高性能哈希表的实现有谷歌的SparseHash库,它实现了一种叫作dense_hash_map的哈希表。在C++标准11中实现了unordered_map,它是一种锁链式的哈希表,通过牺牲一定的存储空间来得到快速寻址能力。但以上两种实现的问题是,它们都没有和底层的硬件(CPU内核)并发算力同步的扩张能力,换句话说是一种单线程哈希表实现,任何时刻只有单读或单写进程占据全部的表资源,这或许可以算作对底层资源的一种浪费。
在高性能云计算环境下,通过并发计算可以获得更高的系统吞吐率,这也意味着底层的数据结构是支持并发的,并且能利用多核CPU、每核多线程,并能利用多机协同,针对一个逻辑上的大数据集进行并发处理。传统的哈希实现几乎都是单线程、单任务的,意味着它们采用的是阻塞式设计,第二个线程或任务如果试图访问同一个资源池,它会被阻塞而等待,以至于无法(实时)完成任务。
从上面的单写单读向前进化,很自然的一个小目标是单写多读,我们称之为single-writer-multiple-reader的并发哈希,它允许多个读线程去访问同一个资源池里的关键区域。当然,这种设计只允许任何时刻最多存在一个写的线程。
在单写多读的设计实现中通常会使用一些技术手段,具体如下:
·versioning:版本号记录。
·RCU(Read-Copy-Update):读-拷贝-更新。
·open-addressing:开放式寻址。在Linux操作系统的内核中首先使用了RCU技术来支持多读,在MemC3/Cuckoo哈希实现中则使用了开放式寻址技术,如图2-7、图2-8所示。


沿着上面的思路继续向前迭代,我们当然希望可以实现多读多写的真正意义上的高并发数据结构。但是,这个愿景似乎与ACID(数据强一致性)的要求相违背——在商用场景中,多个任务或线程在同一时间对同一个数据进行写、读等操作可能造成数据不一致而导致混乱的问题。
下面把以上的挑战和问题细化后逐一解决。实现可扩展的高并发哈希数据结构需要克服上面提到的几个主要问题:
·无阻塞或无锁式设计;
·精细颗粒度的访问控制。
要突破并实现上面提到的两条,两者都和并发访问控制高度相关,有如下要点需要考量。
1)核心区域(访问控制)。
·大小:保持足够小。
·执行时间(占用时间):保持足够短。
2)通用数据访问。
·避免不必要的访问。
·避免无意识的访问。
3)并发控制。
·精细颗粒度的锁实现:例如lock-striping(条纹锁)。
·推测式上锁机制:例如交易过程中的合并锁机制(transactional lock elision)。
对于一个高并发系统而言,它通常至少包含如下三套机制协同工作才能实现充分并发,此三者在图数据库、图计算与存储引擎系统的设计中更是缺一不可。
·并发的基础架构;
·并发的数据结构;
·并发的算法实现。
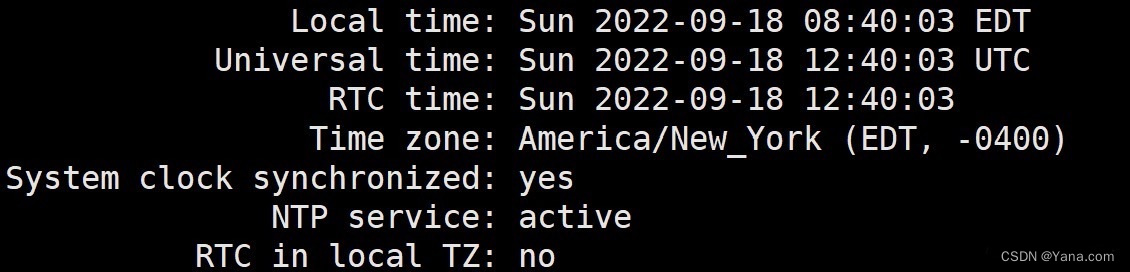
并发的基础架构包含硬件和软件的基础架构,例如英特尔中央处理器的TSX(Transactional Synchronization Extensions,交易同步扩展)功能是硬件级别的在英特尔64位架构上的交易型内存支持。在软件层面,应用程序可以把一段代码声明为一笔交易,而在这段代码执行期间的操作为原子操作。像TSX这样的功能可以实现平均140%的性能加速。这也是英特尔推出的相对于其他X86架构处理器的一种竞争优势。当然这种硬件功能对于代码而言不完全是透明的,它在一定程度上也增加了编程的复杂度和程序的跨平台迁移复杂度。此外,软件层面更多考量的是操作系统本身对于高并发的支持,通常我们认为Linux操作系统在内核到库级别对于并发的支持要好于Windows操作系统,尽管这个并不绝对,但很多底层软件实现(例如虚拟化、容器等)降低了上层应用程序对底层硬件的依赖。
另一方面,有了并发的数据结构,在代码编程层面,依然需要设计代码逻辑、算法逻辑来充分利用和释放并发的数据处理能力。特别是对于图数据集和图数据结构而言,并发对程序员来说是一种思路的转变,充分利用并发能力,在同样的硬件资源基础、同样的数据结构基础、同样的编程语言实现上,可能会获得成百上千倍的性能提升,永远不要忽视并发图计算的意义和价值。
图2-9展示了在Ultipa Graph上一款高性能、高并发实时图数据库服务器,通过高并发架构、数据结构以及算法实现了高性能K邻操作。

图2-10展示的是在700万“点+边”规模且高度联通的一个图数据集上,通过高密度并发实现的鲁汶社区识别算法的效果,毫秒级完成鲁汶社区识别算法的全量数据的迭代运算(engine time)且1~2s内完成数据库回写以及磁盘结果文件回写等一系列复杂操作(total time)。

表2-3很好地示意了不同版本系统性能所出现的指数级差异,是两位图灵奖获得者大卫·帕特森(David Patterson)与约翰·轩尼诗(John Hennessey)于2018年在图灵会议的演讲中所展示的。

·以基于Python实现的系统的数据处理速度为基准;
·C/C++系统的处理速度为其47倍;
·并发实现的C/C++系统的处理速度为其366倍;
·增加了内存访问优化的、并发实现的C/C++系统,处理速度为其6727倍;
·利用了X86 CPU的AVX(高级矢量扩展)指令集的系统,处理速度为其62 806倍。
回顾前面的鲁汶社区识别算法,如果提升6万倍的性能,时间从T+1(约10万s)变为约1.7s,就可以实现完全实时。这种指数级的性能提升与时耗的相应减少所带来的商业价值是不言而喻的。
图2-11形象地解析了如何在图中实现BFS算法并发。以基于BFS的K邻算法为例,为大家解读如何实现高并发。

①在图中定位起始顶点(图中的中心顶点A),计算其直接关联的具有唯一性的邻居数量。如果K=1,直接返回邻居数量;否则,执行下一步。
②K≥2,确定参与并发计算的资源量,并根据第一步中返回的邻居数量决定每个并发线程(任务)所需处理的任务量大小,进入第三步。
③每个任务进一步以分而治之的方式,计算当前面对的(被分配)顶点的邻居数量,以递归的方式前进,直到满足深度为K或者无新的邻居顶点可以被返回而退出,算法结束。
基于以上的算法描述,我们再来回顾一下图2-11中的实现效果,当K邻计算深度为1~2层的时候,内存计算引擎在微秒级内完成计算。从第3层开始,返回的邻居数量呈现指数级快速上涨(2-Hop邻居数量约200,3-Hop邻居数量约8000,4-Hop邻居数量接近5万)的趋势,这就意味着计算复杂度也等比上涨。但是,通过饱满的并发操作,系统的时延保持在了相对低的水平,并呈现了线性甚至亚线性的增长趋势(而不是指数级增长趋势),特别是在搜索深度为第6~17层的区间内,系统时延稳定在约200ms。第17层返回的邻居数量为0,由于此时全图(联通子图)已经遍历完毕,没有找到任何深度达到17层的顶点邻居,因此返回结果集合大小为0。
我们做一个1:1的对标,同样的数据集在同样的硬件配置的公有云服务器上用经典的图数据库Neo4j来做同样的K邻操作,效果如下:
·1-Hop:约200ms,为Ultipa的1/1000;
·从5-Hop开始,几乎无法实时返回(系统内存资源耗尽前未能返回结果);
·K邻的结果默认情况下没有去重,有大量重复邻居顶点在结果集中;
·随着搜索深度的增加,返回时间和系统消耗呈现指数级(超线性)增长趋势;
·最大并发为400%(4线程并发),远低于Ultipa的6400%并发规模。
基于Neo4j的实验(图2-12),我们只进行到7-Hop后就不得不终止了,因为7跳的时候系统耗时超过10s,从8跳开始Neo4j几乎不可能返回结果。而最大的问题是计算结果并不正确,这种不正确包含两个维度:重复顶点未被去重、顶点深度计算错误。

K邻操作中返回的应该是最短路径条件下的邻居,那么如果在第一层的直接邻居中已经被返回的顶点,不可能也不应该出现在第二层或第三层或其他层级的邻居列表中。目前市场上的一些图数据库产品在K邻的实现中并没有完全遵循BFS的原则(或者是实现算法的代码逻辑存在错误),也没有实现去重,甚至没有办法返回(任意深度)全部的邻居。在更大的数据集中,例如Twitter的15亿条边、6000万顶点、26GB大小的社交数据集中,K邻操作的挑战更大,我们已知的很多开源甚至商业化的图数据库都无法在其上完成深度(≥3)的K邻查询。
到这里,我们来总结一下图数据结构的演化:更高的吞吐率可以通过更高的并发来实现,而这可以贯穿数据的全生命周期,如数据导入和加载、数据转换、数据计算(无论是K邻、路径还是……)以及基于批处理的操作、图算法等。
另外,内存消耗也是一个不可忽略的存储要素。尽管业内不少有识之士指出内存就是新的硬盘,它的性能指数级高于固态硬盘或磁盘,但是,它并不是没有成本的,因此谨慎使用内存是必要的。减少内存消耗的策略有:基于数据加速的数据建模;数据压缩与数据去重;算法实现与代码编程中避免过多的数据膨胀、数据拷贝等。







![[运维][Nginx]Nginx学习(2/5)-Nginx高级](https://i-blog.csdnimg.cn/direct/5442910b66e44885a683067c6b169e08.png)