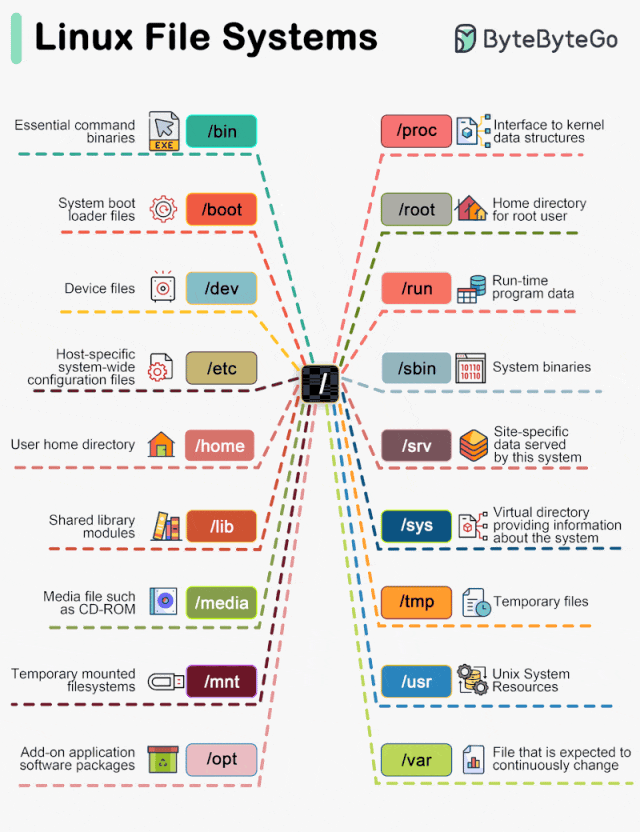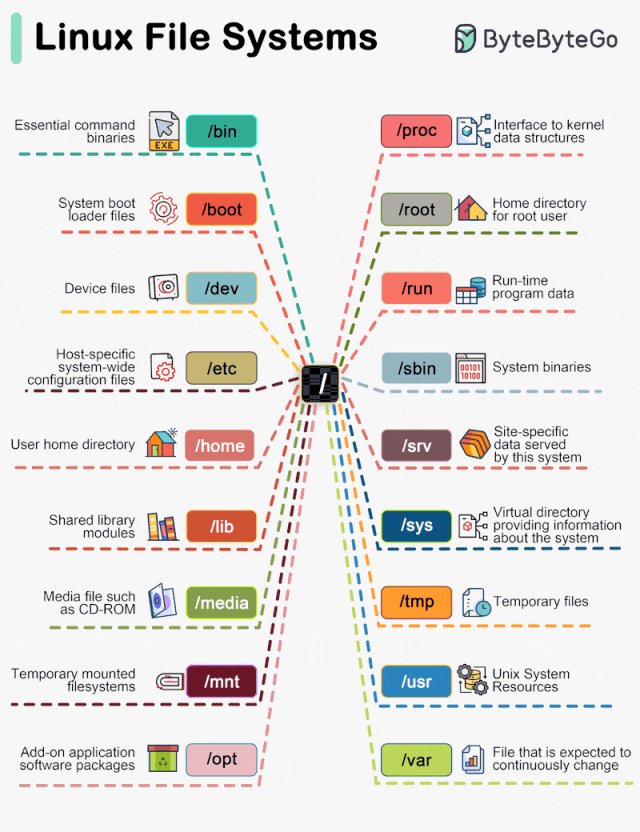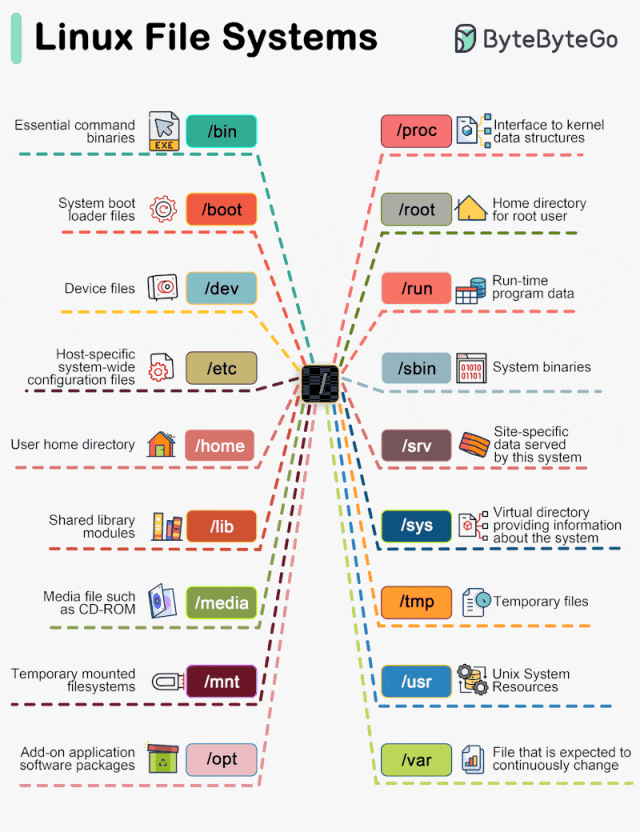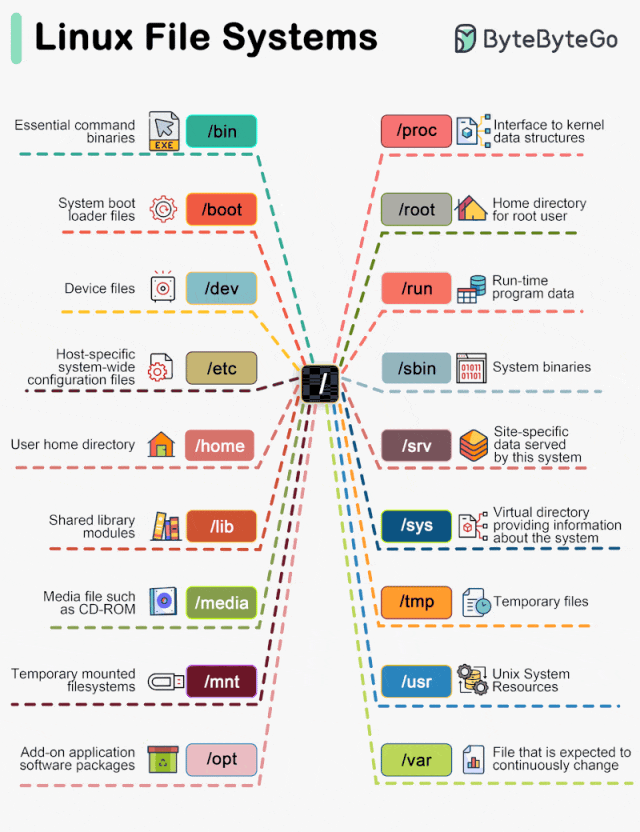
在现代的分布式系统中,消息队列扮演着至关重要的角色,而Apache Kafka以其高吞吐量、可扩展性和容错性而广受欢迎。本文将带你了解如何使用Kafka的Java客户端库来实现生产者(Producer)和消费者(Consumer)的基本操作。
Kafka简介
Apache Kafka是一个分布式流处理平台,主要用于构建实时数据管道和流式应用程序。它具有高吞吐量、可扩展性和容错性,适用于处理实时数据。
环境准备
在开始之前,请确保你已经安装了以下环境:
- Java开发环境(JDK)
- Kafka服务器(可以是本地安装或远程服务器)
- Kafka客户端库(通常通过Maven或Gradle引入)
Maven依赖
如果你使用Maven来管理项目依赖,可以在pom.xml文件中添加以下依赖:
<dependencies><!-- Kafka客户端依赖 --><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.2.0</version></dependency>
</dependencies>Kafka生产者(Producer)
生产者负责将消息发送到Kafka的特定主题(Topic)。
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;public class KafkaProducerExample {public static void main(String[] args) {// 配置属性Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 创建生产者Producer<String, String> producer = new KafkaProducer<>(props);// 创建消息ProducerRecord<String, String> record = new ProducerRecord<>("test-topic", "key", "value");// 发送消息producer.send(record, (metadata, exception) -> {if (exception != null) {exception.printStackTrace();} else {System.out.println("Message sent successfully");}});// 关闭生产者producer.close();}
}Kafka消费者(Consumer)
消费者负责从Kafka的特定主题(Topic)接收消息。
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;import java.time.Duration;
import java.util.Collections;
import java.util.Properties;public class KafkaConsumerExample {public static void main(String[] args) {// 配置属性Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");props.put(ConsumerConfig.GROUP_ID_CONFIG, "test-group");// 创建消费者Consumer<String, String> consumer = new KafkaConsumer<>(props);// 订阅主题consumer.subscribe(Collections.singletonList("test-topic"));// 消费消息while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());}}}
}运行截图
生产者:

消费者:

总结
通过上述示例,我们了解了如何使用Kafka的Java客户端库来创建生产者和消费者。这些基本操作是构建基于Kafka的分布式应用的基石。Kafka的强大功能远不止于此,包括但不限于消息持久化、分区、复制等高级特性,这些都需要在实际项目中根据具体需求进行深入学习和应用。
希望这篇文章能帮助你快速入门Kafka的Java客户端库使用。如果你有任何问题或需要进一步的指导,请随时留言讨论。


![HTB:OpenAdmin[WriteUP]](https://i-blog.csdnimg.cn/direct/c920c8ed2ba34e13b64b9803ac2122ef.png)