批量缓存模版
缓存通常有两种使用方式,一种是Cache-Aside,一种是cache-through。也就是旁路缓存和缓存即数据源。
一般一种用于读,另一种用于读写。参考后台服务架构高性能设计之道。
最典型的Cache-Aside的样例:
//读操作
data = Cache.get(key);
if(data == NULL)
{data = SoR.load(key);Cache.set(key, data);
}
return data;
比如Spring-Cache就是Cache-Aside,只需要写上load逻辑,加上注解,就可以实现Cache-Aside缓存的效果了。
但是这种缓存存在一个缺陷,如果我们需要获取一批用户信息,碰巧用户的缓存全都失效了(也就是缓存雪崩),就需要去数据库中全部拉出来,那么这样一个本来性能很高的循环,就等同于全部查了数据库,缓存一点儿作用都没了。
批量缓存查询
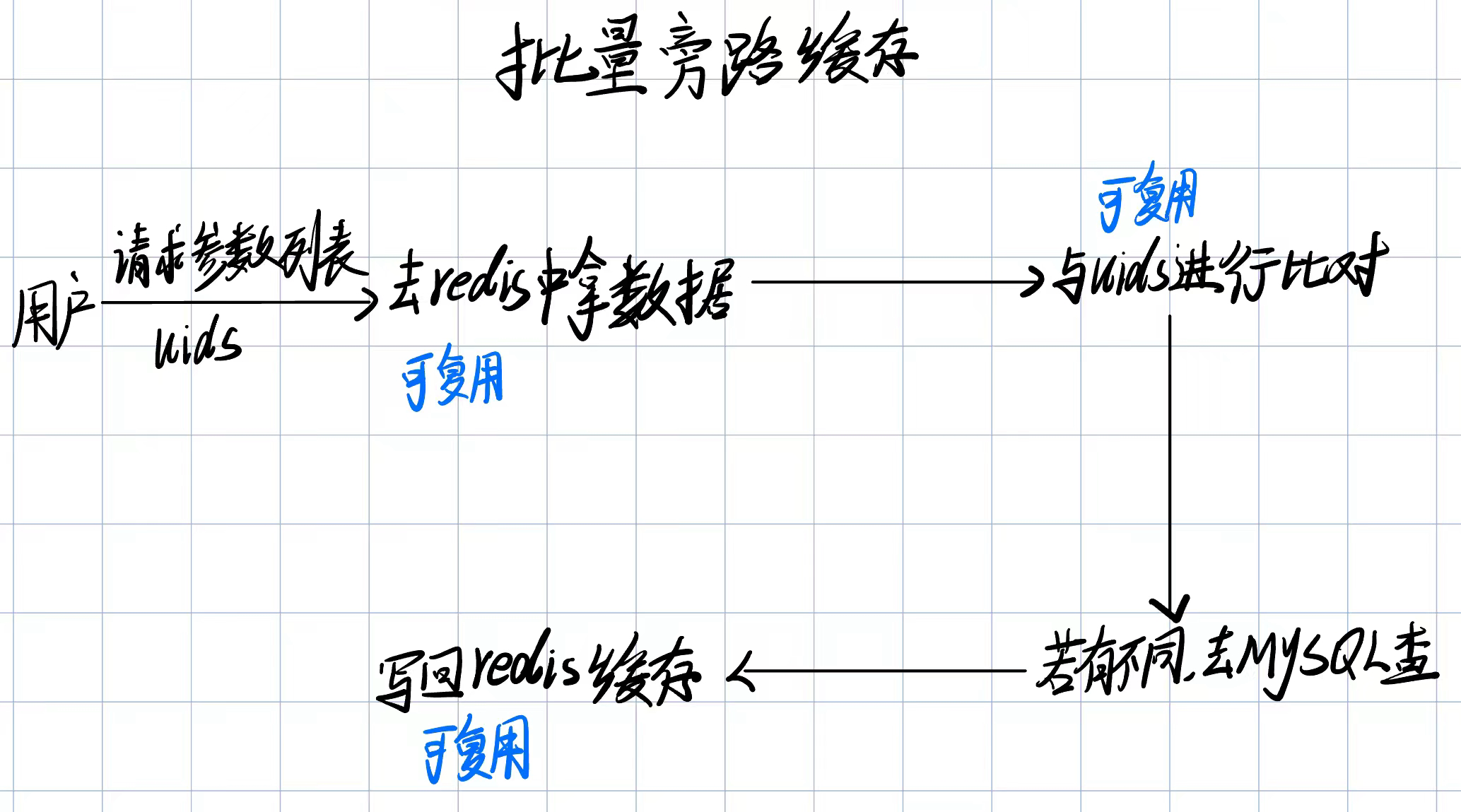
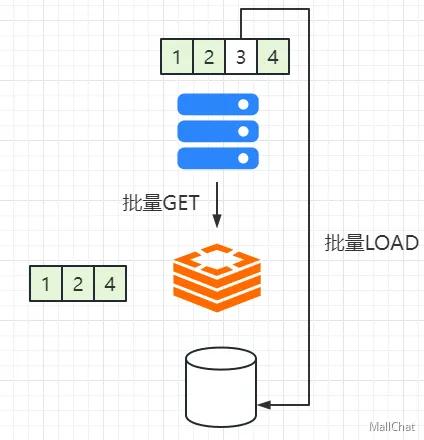
举个栗子🌰:
-
批量请求数据:
- 这里的上方绿色矩形框表示一批需要查询的数据项(例如用户ID
1, 2, 3, 4)。
- 这里的上方绿色矩形框表示一批需要查询的数据项(例如用户ID
-
批量从缓存获取数据:
- 请求首先进入缓存层(例如 Redis),通过批量
GET操作尝试获取所有请求的数据。 - 如果缓存中存在对应数据,则会返回相应的结果;如果缓存中缺少部分数据(例如在缓存中没有
3),那么这些数据就会被标记为“未命中”。 - 图中左侧绿色矩形框
1, 2, 4表示缓存中命中的数据部分。
- 请求首先进入缓存层(例如 Redis),通过批量
-
批量从数据库加载缺失的数据:
- 对于缓存中未命中的数据(例如
3),系统会通过批量LOAD操作从数据库加载。 - 这个步骤不仅可以填充当前请求所需的数据,还可以将这些数据存入缓存中,以便后续请求可以直接从缓存中获取,减少对数据库的访问。
- 对于缓存中未命中的数据(例如
-
将结果返回给调用方:
- 最终返回完整的数据结果(包括从缓存获取的数据和从数据库加载的数据),完成整个批量查询的流程。
/*** 获取用户信息,盘路缓存模式*/
public Map<Long, User> getUserInfoBatch(Set<Long> uids) {//批量组装keyList<String> keys = uids.stream().map(a -> RedisKey.getKey(RedisKey.USER_INFO_STRING, a)).collect(Collectors.toList());//批量getList<User> mget = RedisUtils.mget(keys, User.class);Map<Long, User> map = mget.stream().filter(Objects::nonNull).collect(Collectors.toMap(User::getId, Function.identity()));//发现差集——还需要load更新的uidList<Long> needLoadUidList = uids.stream().filter(a -> !map.containsKey(a)).collect(Collectors.toList());if (CollUtil.isNotEmpty(needLoadUidList)) {//批量loadList<User> needLoadUserList = userDao.listByIds(needLoadUidList);Map<String, User> redisMap = needLoadUserList.stream().collect(Collectors.toMap(a -> RedisKey.getKey(RedisKey.USER_INFO_STRING, a.getId()), Function.identity()));RedisUtils.mset(redisMap, 5 * 60);//加载回redismap.putAll(needLoadUserList.stream().collect(Collectors.toMap(User::getId, Function.identity())));}return map;
}
对这段代码进行抽象,找到可以进行复用的地方
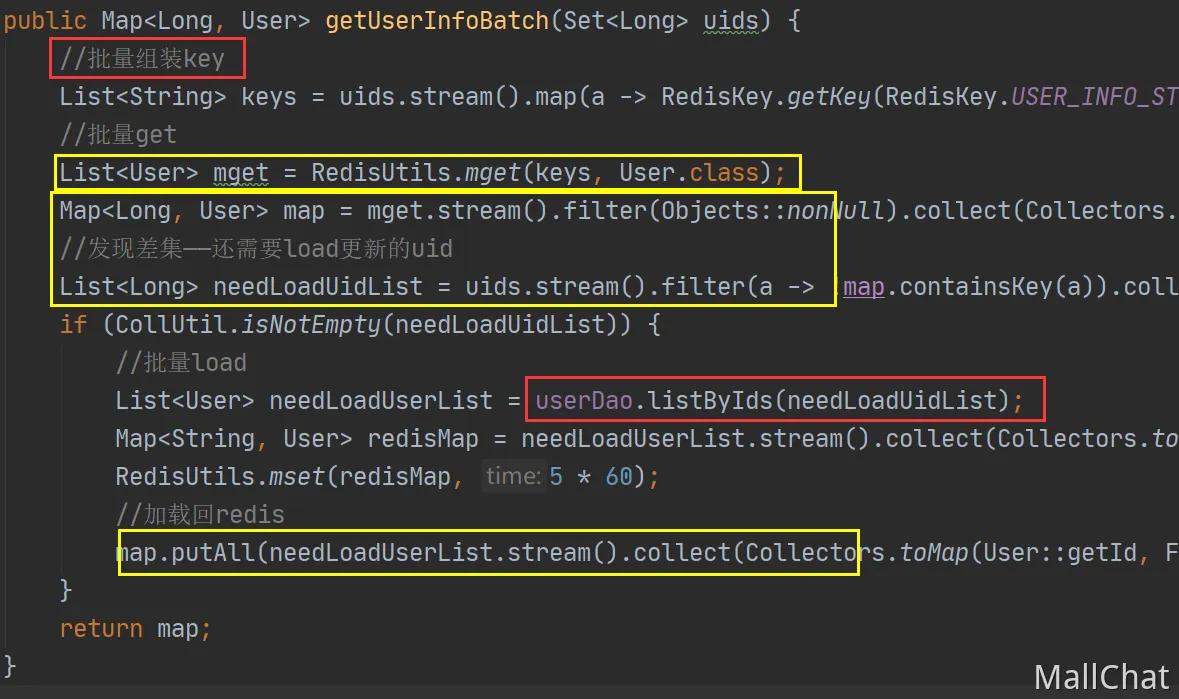
黄色代表可复用的流程,红色代表需要根据不同的数据进行单独的实现。
首先定义一个顶层的抽象接口
public interface BatchCache<IN, OUT> {/*** 获取单个*/OUT get(IN req);/*** 获取批量*/Map<IN, OUT> getBatch(List<IN> req);/*** 修改删除单个*/void delete(IN req);/*** 修改删除多个*/void deleteBatch(List<IN> req);
}
再确定骨架
/*** Description: Redis String类型的批量缓存框架* 这是一个抽象类,用于实现基于Redis的批量缓存框架。* 该框架提供了缓存获取、批量获取、删除、批量删除的功能。*/
public abstract class AbstractRedisStringCache<IN, OUT> implements BatchCache<IN, OUT> {private Class<OUT> outClass; // OUT类型的Class对象,用于反射操作,方便从Redis读取数据/*** 构造方法* 利用反射机制获取泛型OUT的具体类型。* 这样在Redis操作时可以知道OUT类型,用于数据转换。*/protected AbstractRedisStringCache() {ParameterizedType genericSuperclass = (ParameterizedType) this.getClass().getGenericSuperclass();this.outClass = (Class<OUT>) genericSuperclass.getActualTypeArguments()[1];}/*** 抽象方法:获取缓存键* 子类需要实现,用于根据请求参数生成唯一的Redis缓存键。* @param req 请求参数* @return Redis键*/protected abstract String getKey(IN req);/*** 抽象方法:获取缓存的过期时间* 子类需要实现,定义缓存的有效期。* @return 过期时间(以秒为单位)*/protected abstract Long getExpireSeconds();/*** 抽象方法:批量加载数据* 当缓存中没有对应数据时,通过该方法从数据库或其他存储加载数据。* @param req 请求参数列表* @return 加载后的数据映射*/protected abstract Map<IN, OUT> load(List<IN> req);/*** 单个数据的缓存获取方法* 使用getBatch方法来获取单个数据的缓存内容。* @param req 单个请求参数* @return 单个请求对应的OUT对象*/@Overridepublic OUT get(IN req) {return getBatch(Collections.singletonList(req)).get(req);}/*** 批量获取缓存数据的方法* 该方法尝试从缓存中批量获取请求数据,缺失的数据将从数据库加载并写入缓存。* @param req 请求参数列表* @return 返回请求参数和对应OUT对象的映射*/@Overridepublic Map<IN, OUT> getBatch(List<IN> req) {if (CollectionUtil.isEmpty(req)) { // 防御性编程,避免空请求列表的处理return new HashMap<>();}// 去重,避免重复的请求参数req = req.stream().distinct().collect(Collectors.toList());// 组装Redis键列表List<String> keys = req.stream().map(this::getKey).collect(Collectors.toList());// 批量从Redis获取缓存数据List<OUT> valueList = RedisUtils.mget(keys, outClass);// 计算差集,找出缓存中未命中的请求List<IN> loadReqs = new ArrayList<>();for (int i = 0; i < valueList.size(); i++) {if (Objects.isNull(valueList.get(i))) { // 如果某项数据未命中缓存,则添加到loadReqsloadReqs.add(req.get(i));}}Map<IN, OUT> load = new HashMap<>();// 如果有未命中缓存的数据,则从数据库加载并写入缓存if (CollectionUtil.isNotEmpty(loadReqs)) {load = load(loadReqs); // 批量从数据库加载数据Map<String, OUT> loadMap = load.entrySet().stream().map(a -> Pair.of(getKey(a.getKey()), a.getValue())) // 为每个数据生成对应的Redis键值对.collect(Collectors.toMap(Pair::getFirst, Pair::getSecond));RedisUtils.mset(loadMap, getExpireSeconds()); // 批量写入Redis,设置过期时间}// 将缓存命中和重新加载的数据合并成最终结果Map<IN, OUT> resultMap = new HashMap<>();for (int i = 0; i < req.size(); i++) {IN in = req.get(i);OUT out = Optional.ofNullable(valueList.get(i)) // 优先使用缓存中的数据.orElse(load.get(in)); // 如果缓存中没有,则使用加载的数据resultMap.put(in, out); // 将结果放入resultMap}return resultMap;}/*** 删除单个数据的缓存* 使用deleteBatch方法删除单个数据的缓存* @param req 单个请求参数*/@Overridepublic void delete(IN req) {deleteBatch(Collections.singletonList(req));}/*** 批量删除缓存数据的方法* @param req 请求参数列表*/@Overridepublic void deleteBatch(List<IN> req) {// 根据请求参数生成对应的Redis键列表List<String> keys = req.stream().map(this::getKey).collect(Collectors.toList());RedisUtils.del(keys); // 从Redis批量删除这些键}
}具体的实现类
@Component
public class UserInfoCache extends AbstractRedisStringCache<Long, User> {@Autowiredprivate UserDao userDao;@Overrideprotected String getKey(Long uid) {return RedisKey.getKey(RedisKey.USER_INFO_STRING, uid);}@Overrideprotected Long getExpireSeconds() {return 5 * 60L;}@Overrideprotected Map<Long, User> load(List<Long> uidList) {List<User> needLoadUserList = userDao.listByIds(uidList);return needLoadUserList.stream().collect(Collectors.toMap(User::getId, Function.identity()));}
}
骨架通过实现类的getKey方法来获取到具体的Redis Key,然后实现接口的复用。
缓存雪崩
缓存雪崩的场景解决方案:
- 缓存失效时间分布随机
- 缓存预热,在系统启动阶段去mysql拉一次数据load到redis
缓存击穿
缓存击穿的场景解决方案:
空缓存+分布式锁