论文速读|Self-Consistency Preference Optimization
论文信息:

简介:
这篇论文试图解决的问题是如何在没有人类标注数据的情况下,提高大型语言模型(LLMs)在复杂推理任务上的性能。现有的自我对齐技术往往因为难以分配正确的奖励而未能在这些任务上取得进展。此外,这些技术在处理需要复杂推理的问题时,由于模型难以评估自身响应的正确性,导致自我评估方法效果不佳。动机在于现有的训练方法依赖于人类数据,而这些数据的收集过程在成本、时间和专业知识方面都非常耗费资源。为了克服这些限制,研究者们开始探索通过自我训练的方式,从模型生成的数据中迭代训练模型。然而,这种方法在评估模型自身响应的正确性时遇到了困难,尤其是在面对复杂问题求解任务时。因此,本文提出了一种新的方法——自我一致性偏好优化(SCPO),旨在通过自我一致性的概念来改善模型的训练过程。
论文方法:
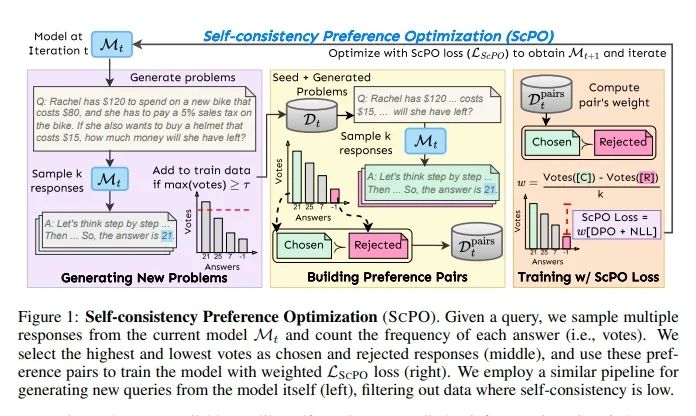
自我一致性偏好优化(SCPO)是一种无监督的迭代训练方法,它利用自我一致性的概念来训练模型,以便在推理任务中更倾向于选择一致的答案而非不一致的答案。
具体方法如下:
假设我们有一个初始的基础模型M0和一些高质量的未标记查询。模型将在每次训练迭代中被训练和更新,产生M1, M2, ..., MT等模型,其中T是迭代的总次数。SCPO不依赖于响应的金标签(答案),而是使用模型Mt的一致性来评估和排名每个响应的质量。使用少量示例问题作为种子集,随机选择多个示例问题并放置在上下文中以生成新问题。SCPO不依赖于准确生成相应的答案,允许模型生成更多样化的问题,只要问题是结构良好且至少有一些是可以回答的。对于训练数据Dt中的每个问题x,使用当前模型Mt基于温度采样生成k个响应。然后,根据响应的一致性创建偏好对Dpairs t,选择最一致的响应作为被选中(获胜)响应,选择最不一致的响应作为被拒绝(失败)响应。SCPO假设当多个响应映射到同一个答案时,预测的答案可能是正确的。因此,使用一致性作为一个代理来创建偏好对。同时,一个响应获得的投票数也可以反映模型对该响应的信心,这意味着投票差距更大的对是更高质量的。从初始种子模型M0开始,训练一系列模型M1, M2,即进行T=2次迭代。每个模型Mt+1都使用LSCPO在Dpairs t上进行训练,这些数据由第t个模型生成。
论文实验:
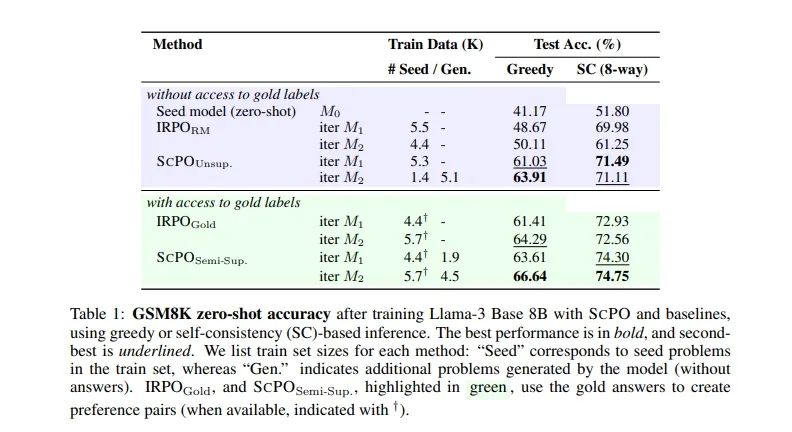
实验旨在评估SCPO在数学推理任务上的有效性。具体来说,实验使用了GSM8K数据集,该数据集包含了小学级别的数学问题,分为训练集、验证集和测试集。实验中,SCPO方法在无监督(SCPOUnsup.)和半监督(SCPOSemi-Sup.)两种设置下进行了测试。
在无监督设置中,SCPO不依赖于金标准答案,而是通过模型生成的数据来自我训练。在半监督设置中,SCPO结合了金标准答案和模型生成的问题。在GSM8K数据集上,经过一次迭代的SCPO(M1)在贪婪解码下将零样本准确率从41.17%提高到61.03%,提高了22.74%。经过两次迭代(M2)后,准确率进一步提高到63.91%,提高了5.26%。使用基于自我一致性的推理(SC),经过一次迭代的SCPO(M1)将准确率从51.80%提高到71.49%,提高了19.69%。经过两次迭代(M2)后,准确率进一步提高到71.11%,提高了3.31%。在GSM8K数据集上,经过一次迭代的SCPO(M1)在贪婪解码下将准确率从41.17%提高到63.61%,提高了22.44%。经过两次迭代(M2)后,准确率进一步提高到66.64%,提高了5.47%。
论文链接:
https://arxiv.org/abs/2411.04109
原文来自:
NLP论文速读|ScPO:自我一致性的偏好优化