
本文字数:13817;估计阅读时间:35 分钟
作者:ClickHouse Team
本文在公众号【ClickHouseInc】首发
又到了新版本发布的时间!
发布概要
本次ClickHouse 24.10 版本包含了25个新功能🎁、15项性能优化🛷、60个bug修复🐛
在本次发布中,clickhouse-local 更加实用,新增了复制和计算器模式。可刷新物化视图已达到生产就绪标准,远程文件支持缓存,表克隆操作也得到了简化。
新贡献者
正如往常,我们热烈欢迎所有 24.9 版本中的新贡献者!ClickHouse 的流行离不开社区的积极贡献,见证这个社区的壮大总是令人感到鼓舞。
以下是新加入的贡献者名单:
Alsu Giliazova, Baitur, Baitur Ulukbekov, Damian Kula, DamianMaslanka5, Daniil Gentili, David Tsukernik, Dergousov Maxim, Diana Carroll, Faizan Patel, Hung Duong, Jiří Kozlovský, Kaushik Iska, Konstantin Vedernikov, Lionel Palacin, Mariia Khristenko, Miki Matsumoto, Oleg Galizin, Patrick Druley, SayeedKhan21, Sharath K S, Shichao, Shichao Jin, Vladimir Cherkasov, Vladimir Valerianov, Z.H., aleksey, alsu, johnnyfish, kurikuQwQ, kylhuk, lwz9103, scanhex12, sharathks118, singhksandeep25, sum12, tuanpach
视频相关 PPT 下载【https://presentations.clickhouse.com/release_24.10/】
clickhouse-local 让文件转换更简单
贡献者:Denis Hananein
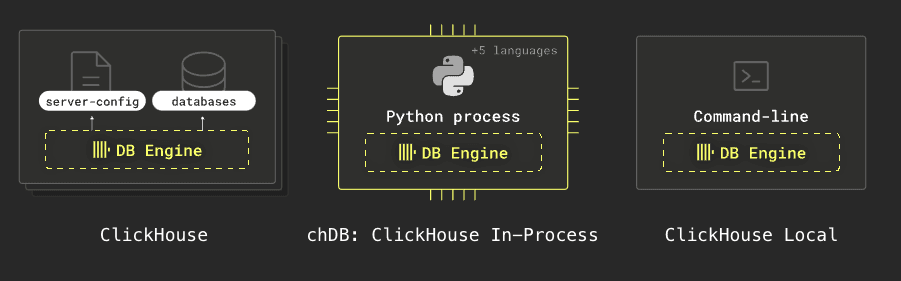
ClickHouse 提供多种形式,其中之一是 clickhouse-local。它无需安装数据库服务器即可使用 SQL 快速处理本地和远程文件。以下是 ClickHouse 各种形式的图示:
clickhouse-local 现在新增了一个标志 --copy,可以作为 SELECT * FROM table 的快捷方式。这使得在不同数据格式之间进行转换变得异常简单。
我们将从 datablist/sample-csv-files GitHub 仓库【https://github.com/datablist/sample-csv-files?tab=readme-ov-file】下载一个包含 100 万人数据的 CSV 文件,然后可以运行以下查询来生成该文件的 Parquet 版本:
clickhouse -t --copy < people-1000000.csv > people.parquet我们可以通过以下查询来查看新文件的内容:
clickhouse -f PrettyCompact \
"SELECT \"Job Title\", count()FROM 'people.parquet'GROUP BY ALLORDER BY count() DESCLIMIT 10"┌─Job Title───────────────────────────────────┬─count()─┐1. │ Dealer │ 1684 │2. │ IT consultant │ 1678 │3. │ Designer, ceramics/pottery │ 1676 │4. │ Pathologist │ 1673 │5. │ Pharmacist, community │ 1672 │6. │ Biochemist, clinical │ 1669 │7. │ Chief Strategy Officer │ 1663 │8. │ Armed forces training and education officer │ 1661 │9. │ Archaeologist │ 1657 │
10. │ Education officer, environmental │ 1657 │└─────────────────────────────────────────────┴─────────┘如果我们想将数据从 CSV 转换为 JSON lines 格式,可以执行以下操作:
clickhouse -t --copy < people-1000000.csv > people.jsonl接下来,我们看看新文件的内容:
head -n3 people.jsonl{"Index":"1","User Id":"9E39Bfc4fdcc44e","First Name":"Diamond","Last Name":"Dudley","Sex":"Male","Email":"teresa26@example.org","Phone":"922.460.8218x66252","Date of birth":"1970-01-01","Job Title":"Photographer"}
{"Index":"2","User Id":"32C079F2Bad7e6F","First Name":"Ethan","Last Name":"Hanson","Sex":"Female","Email":"ufrank@example.com","Phone":"(458)005-8931x2478","Date of birth":"1985-03-08","Job Title":"Actuary"}
{"Index":"3","User Id":"a1F7faeBf5f7A3a","First Name":"Grace","Last Name":"Huerta","Sex":"Female","Email":"tiffany51@example.com","Phone":"(720)205-4521x7811","Date of birth":"1970-01-01","Job Title":"Visual merchandiser"}clickhouse-local 计算器模式
贡献者:Alexey Milovidov
clickhouse-local 现在还提供了“计算器模式”。通过 --implicit-select 标志,您可以直接运行表达式,而无需添加 SELECT 前缀。
例如,以下表达式计算当前时间前 23 分钟的时间:
clickhouse --implicit-select -q "now() - INTERVAL 23 MINUTES"2024-11-04 10:32:58表克隆
贡献者:Tuan Pach
想象一下,您可以几乎瞬间创建一个大型表的一对一副本,并且不需要额外的存储空间。这在您希望对数据进行无风险实验时非常有帮助。
现在,通过使用 CLONE AS 子句,可以轻松实现这一点。使用该子句的效果就相当于创建一个空表并附加所有源表的分区。
当我们运行克隆操作时,ClickHouse 不会为新表复制数据,而是为新表创建了指向现有表部分的硬链接。
ClickHouse 的数据部分是不可变的,这意味着如果我们在任意一个表中添加新数据或修改数据,另一个表将不受影响。
例如,假设我们有一个名为 people 的表,它基于之前提到的 CSV 文件:
CREATE TABLE people
ORDER BY Index AS
SELECT *
FROM 'people*.csv'
SETTINGS schema_inference_make_columns_nullable=0;我们可以通过运行以下查询,将该表克隆到一个名为 people2 的新表:
CREATE TABLE people2 CLONE AS people;现在,这两个表包含相同的数据。
SELECT count()
FROM people┌─count()─┐
1. │ 1000000 │└─────────┘SELECT count()
FROM people2┌─count()─┐
1. │ 1000000 │└─────────┘但我们仍然可以分别向它们添加数据。例如,我们可以将 CSV 文件中的所有行添加到 people2 表中:
INSERT INTO people2
SELECT *
FROM 'people*.csv';现在,让我们分别统计每个表中的记录数:
SELECT count()
FROM people┌─count()─┐
1. │ 1000000 │└─────────┘SELECT count()
FROM people2┌─count()─┐
1. │ 2000000 │└─────────┘客户端中的实时查询指标
贡献者:Maria Khristenko, Julia Kartseva
在 ClickHouse 客户端或 clickhouse-local 中运行查询时,只需按下空格键,即可更细致地查看查询进展情况。
例如,假设我们运行一个查询:
SELECT product_category, count() AS reviews, round(avg(star_rating), 2) as avg
FROM s3('s3://datasets-documentation/amazon_reviews/amazon_reviews_2015.snappy.parquet'
)
GROUP BY ALL
LIMIT 10;如果在查询执行时按下空格键,我们将看到如下内容:
(视频不可播放)
当查询结束时,还会显示以下统计数据:
Event name Value
AddressesMarkedAsFailed 2
ContextLock 32
InitialQuery 1
QueriesWithSubqueries 1
Query 1
S3Clients 1
S3HeadObject 2
S3ReadMicroseconds 9.15 s
S3ReadRequestsCount 52
S3WriteRequestsCount 2
S3WriteRequestsErrors 2
SchemaInferenceCacheHits 1
SchemaInferenceCacheSchemaHits 1
SelectQueriesWithSubqueries 1
SelectQuery 1
StorageConnectionsCreated 17
StorageConnectionsElapsedMicroseconds 5.02 s
StorageConnectionsErrors 2
StorageConnectionsExpired 12
StorageConnectionsPreserved 47
StorageConnectionsReset 7
StorageConnectionsReused 35
TableFunctionExecute 1远程文件缓存功能
贡献者:Kseniia Sumarokova
如果您曾运行过类似以下的查询:
SELECTproduct_category,count() AS reviews,round(avg(star_rating), 2) AS avg
FROM s3('s3://datasets-documentation/amazon_reviews/amazon_reviews_2015.snappy.parquet')
GROUP BY ALL
LIMIT 10;您可能会发现,查询后续执行时速度略有提升,但提升不明显。
从 24.10 版本起,这种情况将有所改变!ClickHouse 现在支持直接访问的文件和在 S3、Azure 上的数据湖表的缓存。
缓存条目通过路径 + ETag 进行标识,ClickHouse 会缓存查询中引用的列的数据。要启用该功能,您需要在 ClickHouse 服务器配置文件中添加以下配置(当前不适用于 ClickHouse Local):
<filesystem_caches><cache_for_s3><path>/data/s3_cache_clickhouse</path><max_size>10Gi</max_size></cache_for_s3></filesystem_caches>您可以通过运行 SHOW FILESYSTEM CACHES 来检查 ClickHouse 是否已启用文件系统缓存。随后,在执行查询时启用缓存并指定缓存名称即可:
SELECTproduct_category,count() AS reviews,round(avg(star_rating), 2) AS avg
FROM s3('s3://datasets-documentation/amazon_reviews/amazon_reviews_2015.snappy.parquet')
GROUP BY ALL
LIMIT 10
SETTINGS enable_filesystem_cache = 1, filesystem_cache_name = 'cache_for_s3'除了查询时间外,您还可以在查询运行时按下空格键,实时查看 S3* 指标。以下是上述查询在未启用缓存和启用缓存时的指标对比:
S3Clients 1
S3GetObject 186
S3ListObjects 2
S3ReadMicroseconds 16.21 s
S3ReadRequestsCount 192
S3ReadRequestsErrors 1
S3WriteMicroseconds 475.00 us
S3WriteRequestsCount 1启用缓存后:
S3Clients 1
S3ListObjects 2
S3ReadMicroseconds 122.66 ms
S3ReadRequestsCount 6
S3ReadRequestsErrors 1
S3WriteMicroseconds 487.00 us
S3WriteRequestsCount 1显著差别在于 S3GetObject 请求的次数:未启用缓存时有 186 次,而启用缓存后降为 0 次。不过需要注意,缓存版本依然会发出 S3ListObjects 请求,以检测对象的 ETag 是否发生变化。
缓存采用 LRU(最近最少使用)淘汰策略。
可刷新物化视图正式上线
贡献者:Michael Kolupaev
我们曾在 23.12 和 24.9 版本的发布博客中介绍过可刷新物化视图,当时它还是一项实验功能。
如今在 24.10 版本中,该功能不仅支持 Replicated 数据库引擎,而且已经可以正式应用于生产环境!
MongoDB 查询支持改进
贡献者:Kirill Nikiforov
ClickHouse 内置了超过 50 种外部系统的集成,包括 MongoDB。
通过 MongoDB 表函数或表引擎,ClickHouse 可以直接查询 MongoDB。表引擎适用于创建持久的代理表以查询远程 MongoDB 集合,而表函数则允许执行临时查询。
此前,这两种集成都存在一些显著的限制。例如,并非所有 MongoDB 数据类型都能被支持,同时 WHERE 和 ORDER BY 条件在查询时无法直接下推,而是先从 MongoDB 集合中读取所有未筛选、未排序的数据后,再在 ClickHouse 端处理。
ClickHouse 24.10 对 MongoDB 集成进行了全面优化和改进,新增了以下功能:
-
支持所有 MongoDB 数据类型
-
下推 WHERE 条件和 ORDER BY
-
支持使用 mongodb:// 模式的连接字符串
为了展示这些改进,我们在 AWS EC2 上安装了 MongoDB 8.0 社区版并导入了一些数据。在 MongoDB Shell (mongosh) 中运行以下命令查看导入的 JSON 文档之一:
github> db.events.aggregate([{ $sample: { size: 1 } }]);
[{_id: ObjectId('672a3659366c7681f18c5334'),id: '29478055921',type: 'PushEvent',actor: {id: 82174588,login: 'denys-kosyriev',display_login: 'denys-kosyriev',gravatar_id: '',url: 'https://api.github.com/users/denys-kosyriev',avatar_url: 'https://avatars.githubusercontent.com/u/82174588?'},repo: {id: 637899002,name: 'denys-kosyriev/gulp-vector',url: 'https://api.github.com/repos/denys-kosyriev/gulp-vector'},payload: {repository_id: 637899002,push_id: Long('13843301463'),size: 1,distinct_size: 1,ref: 'refs/heads/create-settings-page',head: 'dfa3d843b579b7d403884ff7c14b1c0100e6ba2c',before: '3a5211f72354fb85567179018ad559fef77eec4a',commits: [{sha: 'dfa3d843b579b7d403884ff7c14b1c0100e6ba2c',author: { email: 'utross2241@gmail.com', name: 'denys_kosyriev' },message: "feature: setting js radio-buttons 'connection' page",distinct: true,url: 'https://api.github.com/repos/denys-kosyriev/gulp-vector/commits/dfa3d843b579b7d403884ff7c14b1c0100e6ba2c'}]},public: true,created_at: '2023-06-02T01:15:20Z'}
]
接着,我们启动了 ClickHouse 实例,并在服务器配置文件中将 <use_legacy_mongodb_integration> 设置为0,以启用新的 MongoDB 集成功能。
现在,我们可以在 clickhouse-client 中使用以下命令,查询 MongoDB 实例 github 数据库中的 events 集合:
SELECT *
FROM mongodb('<HOST>:<PORT>','github','events','<USER>','<PASSWORD>','id String, type String, actor String')
LIMIT 1
FORMAT VerticalRow 1:
──────
id: 26163418664
type: WatchEvent
actor: {"id":89544871,"login":"Aziz403","display_login":"Aziz403","gravatar_id":"","url":"https:\/\/api.github.com\/users\/Aziz403","avatar_url":"https:\/\/avatars.githubusercontent.com\/u\/89544871?"}亮点功能:全新 JSON 数据类型的实际应用
我们在之前的实验性实现中发现了一些设计缺陷,因此为 ClickHouse 从头构建了一个强大的新 JSON 数据类型。
这个全新的 JSON 类型专为高性能处理 JSON 数据而设计,采用列式存储,提供以下支持:
-
动态数据变化:允许相同 JSON 路径中的值具有不同数据类型(可能互不兼容且不预先确定),确保混合数据类型的完整性。
-
高性能与密集存储:将任意插入的 JSON 键路径存储为本地密集子列,实现高数据压缩并保持经典数据类型的查询性能。
-
可扩展性:可以限制独立存储的子列数量,使 JSON 存储在 PB 级数据集的高性能分析中保持扩展性。
-
灵活调整:支持 JSON 解析提示(例如指定 JSON 路径的类型、忽略解析的路径等)。
本次发布除了若干小的性能和易用性改进之外,我们在 24.8 版本中也宣布了该 JSON 重构几乎已完成,并预计在 Beta 阶段达到理论上的最佳实现。
ClickHouse 现在已成为 MongoDB 等专用文档数据库的强大替代方案。
作为亮点测试,我们将 2023 年前六个月的 GitHub 事件数据【https://ghe.clickhouse.tech/】(仅提供 JSON 格式)分别加载到 MongoDB 8.0 社区版和 ClickHouse 24.10 中,两者均在独立的 AWS EC2 m6i.8xlarge 实例上运行,配备 32 核 CPU、128 GB 内存、5 TB EBS gp3 存储,操作系统为 Ubuntu 24.04 LTS("Noble")。导入的 GitHub 事件数据原始大小约为 2.4 TB。
我们的测试目的是在不创建任何预定义架构或索引的情况下,加载数据并进行即席分析。例如,在 ClickHouse 中,我们创建了如下数据库和表,并用一个简单脚本【https://gist.github.com/tom-clickhouse/f993107ffd3fb4756c4125594014f79c】加载数据:
CREATE DATABASE github;USE github;
SET allow_experimental_json_type = 1;CREATE TABLE events
(docs JSON()
)
ENGINE = MergeTree
ORDER BY ();加载了 2023 年前六个月的 GitHub 事件数据后,上述表现在包含了大约 7 亿个 JSON 文档:
SELECT count()
FROM events;┌───count()─┐
1. │ 693137012 │ -- 693.14 million└───────────┘磁盘使用量约为 675 GiB:
SELECT formatReadableSize(sum(bytes_on_disk)) AS size_on_disk
FROM system.parts
WHERE active AND (database = 'github') AND (`table` = 'events')┌─size_on_disk─┐
1. │ 674.25 GiB │└──────────────┘我们可以查看其中存储的一个 JSON 文档的结构:
SELECT docs
FROM events
LIMIT 1
FORMAT PrettyJSONEachRow;{"docs": {"actor" : {"avatar_url" : "https:\/\/avatars.githubusercontent.com\/u\/119809980?","display_login" : "ehwu106","gravatar_id" : "","id" : "119809980","login" : "ehwu106","url" : "https:\/\/api.github.com\/users\/ehwu106"},"created_at" : "2023-01-01T00:00:00Z","id" : "26163418658","payload" : {"before" : "27e76fd2920c98cf825daefa9469cb202944d96d","commits" : [{"author" : {"email" : "howard.wu@travasecurity.com","name" : "Howard Wu"},"distinct" : 1,"message" : "pushing","sha" : "01882b15808c6cc63f4075eea105de4f608e23aa","url" : "https:\/\/api.github.com\/repos\/ehwu106\/Gmail-Filter-Solution\/commits\/01882b15808c6cc63f4075eea105de4f608e23aa"},{"author" : {"email" : "hwu106@ucsc.edu","name" : "hwu106"},"distinct" : 1,"message" : "push","sha" : "8fbcb0a5be7f1ae98c620ffc445f8212da279c4b","url" : "https:\/\/api.github.com\/repos\/ehwu106\/Gmail-Filter-Solution\/commits\/8fbcb0a5be7f1ae98c620ffc445f8212da279c4b"}],"distinct_size" : "2","head" : "8fbcb0a5be7f1ae98c620ffc445f8212da279c4b","push_id" : "12147229638","ref" : "refs\/heads\/main","size" : "2"},"public" : 1,"repo" : {"id" : "582174284","name" : "ehwu106\/Gmail-Filter-Solution","url" : "https:\/\/api.github.com\/repos\/ehwu106\/Gmail-Filter-Solution"},"type" : "PushEvent"}
}对于 MongoDB,我们用类似的脚本【https://gist.github.com/tom-clickhouse/d48fd00b09a3974e5ba392aca415c8bd】加载相同数据集至集合中(未使用任何额外的索引或架构提示),并在 mongosh 中查看存储的 JSON 文档数量和磁盘占用情况:
github> db.events.stats();
...
count: 693137012,
storageSize: 746628136960文档数与 ClickHouse 相同,但存储占用略大,为 695.35 GiB。
我们还可以查看 MongoDB 中存储的一个 JSON 文档的结构:
github> db.events.aggregate([{ $sample: { size: 1 } }]);
[{_id: ObjectId('672ab1430e44c2d6ce0433ee'),id: '28105983813',type: 'DeleteEvent',actor: {id: 10810283,login: 'direwolf-github',display_login: 'direwolf-github',gravatar_id: '',url: 'https://api.github.com/users/direwolf-github',avatar_url: 'https://avatars.githubusercontent.com/u/10810283?'},repo: {id: 183051410,name: 'direwolf-github/my-app',url: 'https://api.github.com/repos/direwolf-github/my-app'},payload: { ref: 'branch-58838bda', ref_type: 'branch', pusher_type: 'user' },public: true,created_at: '2023-03-31T00:43:36Z'}
]接下来,我们想分析该数据集,查看不同的 GitHub 事件类型,并按文档数进行排序。在 ClickHouse 中,通过一个简单的聚合 SQL 查询即可实现:
SELECTdocs.type,count() AS count
FROM events
GROUP BY docs.type
ORDER BY count DESC┌─docs.type─────────────────────┬─────count─┐1. │ PushEvent │ 378108538 │2. │ CreateEvent │ 95054342 │3. │ PullRequestEvent │ 55578642 │4. │ WatchEvent │ 41269499 │5. │ IssueCommentEvent │ 32985638 │6. │ DeleteEvent │ 22395484 │7. │ PullRequestReviewEvent │ 17029889 │8. │ IssuesEvent │ 14236189 │9. │ PullRequestReviewCommentEvent │ 10285596 │
10. │ ForkEvent │ 9926485 │
11. │ CommitCommentEvent │ 6569455 │
12. │ ReleaseEvent │ 3804539 │
13. │ PublicEvent │ 2352553 │
14. │ MemberEvent │ 2304020 │
15. │ GollumEvent │ 1235200 │└───────────────────────────────┴───────────┘15 rows in set. Elapsed: 7.324 sec. Processed 693.14 million rows, 20.18 GB (94.63 million rows/s., 2.76 GB/s.)
Peak memory usage: 7.33 MiB.该查询对整个数据集(约 7 亿个 JSON 文档)进行聚合并排序,查询时间为 7.3 秒,峰值内存占用 7.33 MiB。查询吞吐量为每秒 9400 万行,2.76 GB/s。
在 MongoDB 中,推荐使用聚合管道完成此类聚合操作。我们在 MongoDB 中运行了一个等效的聚合管道,与上述 ClickHouse SQL 查询相同:
github> start = new Date();
ISODate('2024-11-06T09:33:11.295Z')
github> db.events.aggregate([
{$group: {_id: "$type", // Group by docs.typecount: { $sum: 1 } // Count each occurrence}
},
{$sort: { count: -1 } // Sort by count in descending order
},
{$project: { // Project the fields to match SQL outputtype: "$_id",count: 1,_id: 0}
}
]);[{ count: 378108538, type: 'PushEvent' },{ count: 95054342, type: 'CreateEvent' },{ count: 55578642, type: 'PullRequestEvent' },{ count: 41269499, type: 'WatchEvent' },{ count: 32985638, type: 'IssueCommentEvent' },{ count: 22395484, type: 'DeleteEvent' },{ count: 17030832, type: 'PullRequestReviewEvent' },{ count: 14236189, type: 'IssuesEvent' },{ count: 10285596, type: 'PullRequestReviewCommentEvent' },{ count: 9926485, type: 'ForkEvent' },{ count: 6569455, type: 'CommitCommentEvent' },{ count: 3804539, type: 'ReleaseEvent' },{ count: 2352553, type: 'PublicEvent' },{ count: 2304020, type: 'MemberEvent' },{ count: 1235200, type: 'GollumEvent' }
]
github> print(EJSON.stringify({t: new Date().getTime() - start.getTime()}));
{"t":13779342}在相同硬件和数据集上,MongoDB 上的查询耗时 1377934 毫秒,即约 4 小时,比 ClickHouse 慢了约 2000 倍。此外,MongoDB 的内存消耗(通过 top 查看)约为 50 GB,比 ClickHouse 高出约 7000 倍。
默认情况下,MongoDB 的 WiredTiger 存储引擎会预留 50% 的可用内存。在我们的测试机器上,这大约是 60 GB(即 128 GB 总内存的一半),我们可以通过 top 命令来验证这一点。与 ClickHouse 不同的是,MongoDB 并不会在引擎中直接跟踪查询的峰值内存使用情况。而 ClickHouse 服务器进程的内存需求则约为 1 GB,再加上查询的峰值内存使用。综上所述,在运行测试查询时,MongoDB 的内存消耗约为 ClickHouse 的 7000 倍。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求








![HTB:Precious[WriteUP]](https://i-blog.csdnimg.cn/direct/225e71aa7d904e928e10dd343c678e1a.png)










