全文链接:https://tecdat.cn/?p=38195
股票市场在经济发展中占据重要地位。由于股票的高回报特性,股票市场吸引了越来越多机构和投资者的关注。然而,由于股票市场的复杂波动性,有时会给机构或投资者带来巨大损失。考虑到股票市场的风险,对股价变动的研究与预测能够为投资者规避风险。传统的时间序列模型ARIMA无法描述非线性时间序列,并且在建模前需要满足诸多条件,在股票预测中无法取得显著成果(点击文末“阅读原文”获取完整代码数据)。
本文提出一种混合深度学习模型来预测股票价格。与传统的混合预测模型不同,本文所提模型将时间序列模型ARIMA与神经网络以非线性关系进行整合,结合了这两种基础模型的优势,提高了预测精度。首先通过ARIMA对股票数据进行预处理,经过ARIMA(p = 2,q = 0,d = 1)预处理后,将股票序列输入神经网络(NN)或XGBoost。然后采用预训练 - 微调框架所形成的深度学习架构。预训练模型是基于序列到序列框架的基于注意力机制的CNN-LSTM模型,其中基于注意力机制的CNN作为编码器,双向LSTM作为解码器。该模型首先利用卷积操作提取原始股票数据的深层特征,然后利用长短期记忆网络挖掘长期时间序列特征,最后采用XGBoost模型进行微调,从而能够充分挖掘多个时期的股票市场信息。我们所提出的基于注意力机制的CNN-LSTM与XGBoost混合模型简称为AttCLX。结果表明,该模型更为有效,预测精度相对较高,能够帮助投资者或机构做出决策,实现扩大收益和规避风险的目的。
基于序列数据的深度学习
(一)基本前馈神经网络(FFNN)
在基本前馈神经网络(FFNN)中,当前时刻的输出仅由当前时刻的输入决定,这限制了FFNN对时序数据进行建模的能力。
(二)循环神经网络(RNN)
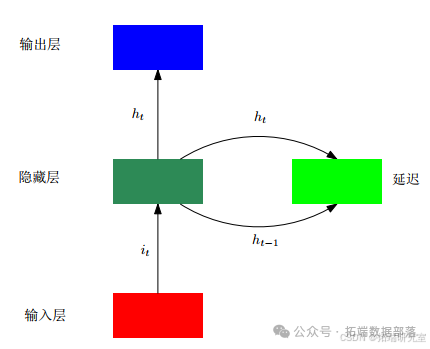
在循环神经网络(RNN)中,通过一个延迟来保存上一时刻的潜在状态,然后当前时刻的潜在状态由上一时刻的潜在状态和当前时刻的输入共同决定。如图所示,有研究指出,随着误差在时间维度上传播,RNN可能会出现梯度消失的情况,这就导致了长期依赖问题。
(三)长短期记忆(LSTM)模型
人类能够有选择性地记住信息。通过门控激活函数,长短期记忆(LSTM)模型能够有选择性地记住更新后的信息并忘记累积的信息。
(四)序列到序列(seq2seq)模型
序列到序列(seq2seq)模型采用自动编码器(即编码器 - 解码器架构)来分析时序数据。序列到序列模型是通过编码器 - 解码器架构构建的,这增强了LSTM通过含噪数据学习隐藏信息的能力。在seq2seq模型中,编码器是一个将输入编码到上下文(通常是最后一个隐藏状态)的LSTM,然后在解码器中对上下文进行解码。在解码器中,上一时刻的输出作为下一时刻的输入。
为了优化解码后的序列,在seq2seq模型中采用了束搜索方法。束搜索和隐马尔可夫模型(HMM)中的维特比算法都是基于动态规划的。根据观测值和先前状态来求解当前状态的最优估计,在HMM中被称为解码或推理。分别求解(p(x_{k}|y_{1:k}))和(p(x_{k}|y_{1:N}))等同于HMM中的前向 - 后向算法。通过(x_{k})的分布可以得到最优的双向估计。这就是提出双向LSTM(结合了前向和后向)的概率视角。
注意力机制
(一)注意力机制原理
人类通常会关注显著信息。注意力机制是一种基于人类认知系统的深度学习技术。对于输入(X=(x_{1};x_{2};\cdots;x_{N})),给定查询向量(q),通过注意力(z = 1;2;\cdots;N)来描述所选信息的索引,然后得到注意力的分布。
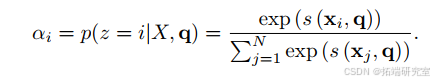
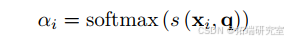
在这里,通过缩放点积得到的是注意力得分,(d)是输入的维度。假设输入的键值对((K;V)=[(k_{1};v_{1});\cdots;(k_{N};v_{N})]),对于给定的(q),注意力函数如下:
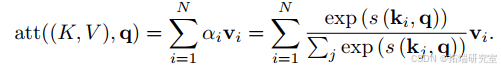
(二)多头机制
通常采用多查询(Q = [q_{1};\cdots;q_{M}])来进行注意力函数的计算。
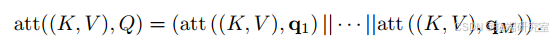
这里,“jj”表示拼接操作。这就是所谓的多头注意力(MHA)。注意力机制可以用来生成由数据驱动的不同权重。在这里,(Q)、(K)、(V)都是通过对(X)进行线性变换得到的,并且(WQ)、(WK)、(WV)可以动态调整。
这就是所谓的自注意力。类似地,输出如下:
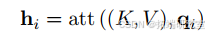
因此,采用缩放点积得分后,输出如下:
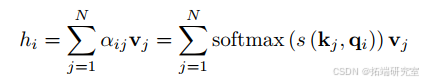
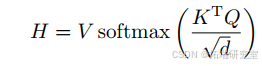
方法
(一)预处理
本文提出一种混合深度学习模型来预测股票价格。与传统的混合预测模型不同,所提模型将时间序列模型ARIMA与神经网络以非线性关系进行整合,结合了两者的优势,提高了预测精度。首先通过ARIMA对股票数据进行预处理。将原始股票市场数据输入ARIMA,能够输出一个更有效地描述状态的新序列。
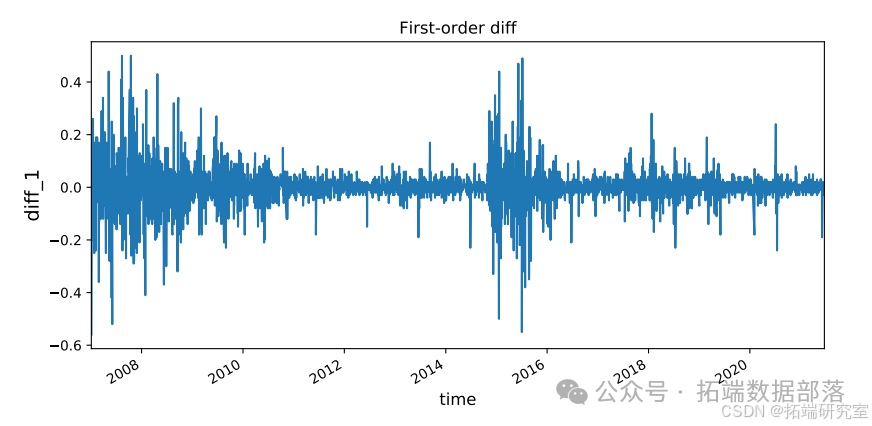
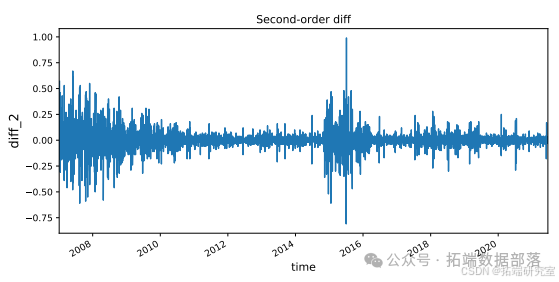
通过对原始序列和一阶差分序列进行ADF检验的结果表明,原始序列是非平稳的,一阶差分序列是平稳的。在确定(d = 1)后,我们需要确定ARIMA中的(AR(p))和(MA(q))。我们利用自相关图(ACF)和偏自相关图(PACF)来确定。原始序列和一阶差分序列的ACF和PACF如图所示
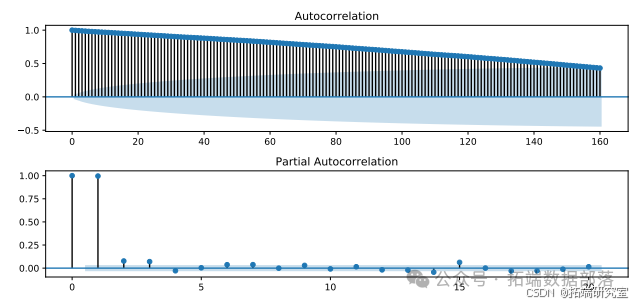
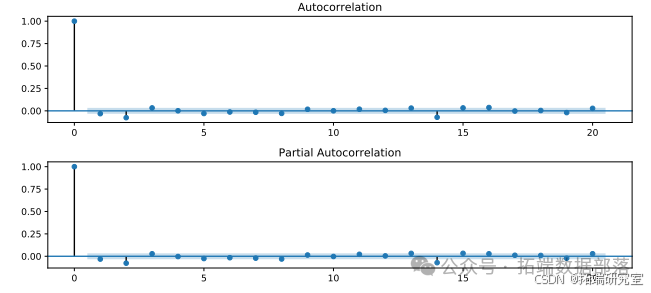
图显示当阶数为2时,PACF截断,这意味着我们应该采用(AR(2));而ACF对于任何阶数都有长尾,这意味着我们应该采用(MA(0))。所以(p = 2),(q = 0)。
(二)预训练
然后,采用预训练 - 微调框架所形成的深度学习架构。预训练模型是基于序列到序列框架的基于注意力机制的CNN-LSTM模型,其中基于注意力机制的CNN作为编码器,双向LSTM作为解码器。该模型首先利用卷积操作提取原始股票数据的深层特征,然后利用长短期记忆网络挖掘长期时间序列特征。
以下是一段用于展示一阶差分和二阶差分情况的代码示例:
# 计算一阶差分
training\_set\['diff\_1'\] = training_set\['close'\].diff(1)
plt.figure(figsize=(10, 6))
training\_set\['diff\_1'\].plot()
plt.title('一阶差分')
plt.xlabel('时间', fontsize=12, verticalalignment='top')
plt.ylabel('diff_1', fontsize=14, horizontalalignment='center')
plt.show()# 计算二阶差分
training\_set\['diff\_2'\] = training\_set\['diff\_1'\].diff(1)
plt.figure(figsize=(10, 6))
training\_set\['diff\_2'\].plot()
plt.title('二阶差分')
plt.xlabel('时间', fontsize=12, verticalalignment='top')
plt.ylabel('diff_2', fontsize=14, horizontalalignment='center')
plt.show()在上述代码中,首先通过diff函数计算了股票数据中收盘价的一阶差分,并将结果存储在training_set['diff_1']中,然后绘制了一阶差分的图像并设置了相关的图像标题、坐标轴标签等。接着又计算了一阶差分的二阶差分,并进行了类似的图像绘制操作。这些操作有助于我们更直观地观察股票数据在差分处理后的变化情况。
基于深度学习的编码器 - 解码器架构中,seq2seq能够更有效地描绘状态的隐藏信息,但不满足股价线性特性假设。基于注意力机制的CNN(ACNN)编码器由自注意力层和CNN组成,这就是LSTM解码器块的输入。编码器 - 解码器层描述了当前序列与先前序列之间的关系以及当前序列与嵌入之间的关系。编码器仍然采用多头机制。当对第(k)个嵌入进行解码时,只能看到第(k - 1)个和之前的解码情况。这种多头机制就是掩码多头注意力。
基于注意力机制的CNN(ACNN)能够捕捉LSTM可能无法捕捉的全局和局部依赖关系,从而增强了模型的鲁棒性。在我们所提出的编码器 - 解码器框架中,可以采用ACNN - LSTM结构。在人类认知系统中,注意力通常在记忆之前。ACNN能够捕捉长期依赖关系的原因在于它集成了多头自注意力和卷积。结合LSTM和ACNN能够增强结构优势以及对时序数据建模的能力。通过集成多头注意力和多尺度卷积核,ACNN编码器能够捕捉到LSTM可能无法捕捉的显著特征,而LSTM能够更好地描绘时序数据的特性。
(三)微调
在解码之后,通过一个XGBoost回归器来获得输出,以便进行精确的特征提取和微调。我们所提出的基于注意力机制的CNN-LSTM与XGBoost混合模型简称为AttCLX,其示意图如图所示
作为微调模型,XGBoost具有很强的扩展性和灵活性
点击标题查阅往期内容

Python中TensorFlow的长短期记忆神经网络(LSTM)、指数移动平均法预测股票市场和可视化

左右滑动查看更多
01
02
03
04
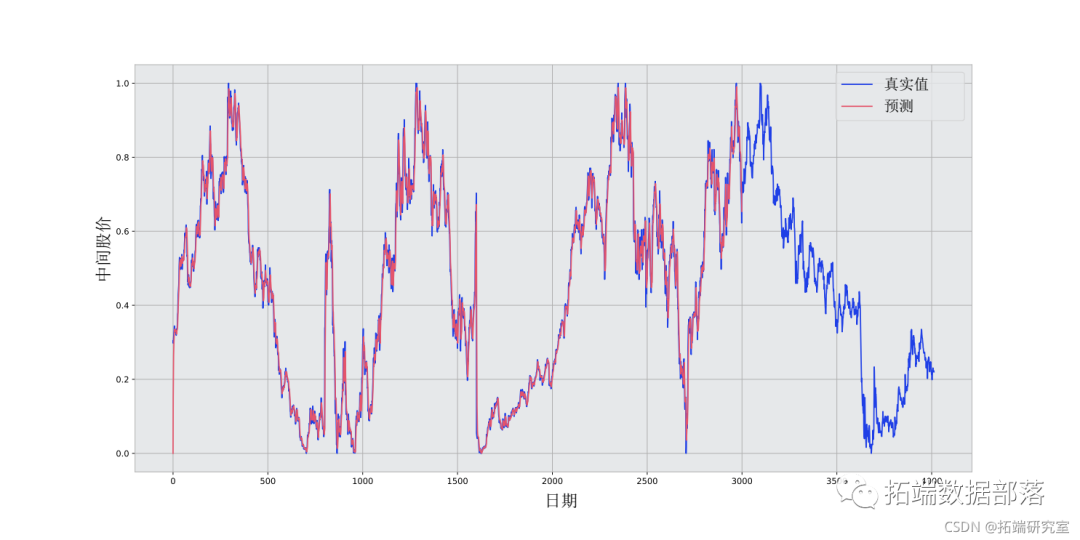
实例
模型修改
经ARIMA预处理后,神经网络的输入是一个按一定时间间隔生成的二维数据矩阵,其大小为TimeWindow×Features。在股票预测的实证研究中,特征包括基本股市数据(开盘价、收盘价、最高价、最低价、交易量、交易额),同时ARIMA处理后的序列以及残差序列也被连接起来作为特征。
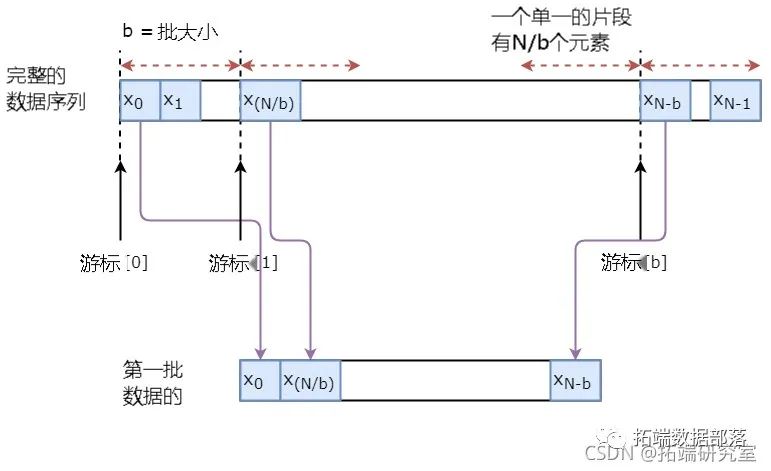
我们在时间序列预测中采用了回顾技巧,回顾数量为20,即(o_{t})可通过(o_{t - 1};\cdots;o_{t - 5})获得,这意味着TimeWindow的宽度为20。长短期记忆网络(LSTM)的层数为5,大小为64,训练的轮数(epoch)为50。通过引入丢弃法(dropout)[13]对模型进行训练,丢弃率为0.3,头数为4。
本文所使用的数据来自于Tushare(Tushare数据)为中国股市研究提供的开放免费公共数据集,该数据集具有数据丰富、使用简单、便于实施的特点,通过调用其API获取股票的基本市场数据非常方便。
# 将ARIMA模型的拟合值转换为Series类型,并进行切片操作
predictions\_ARIMA\_diff = pd.Series(model.fittedvalues, copy=True)
predictions\_ARIMA\_diff = predictions\_ARIMA\_diff\[3479:\]如图所示
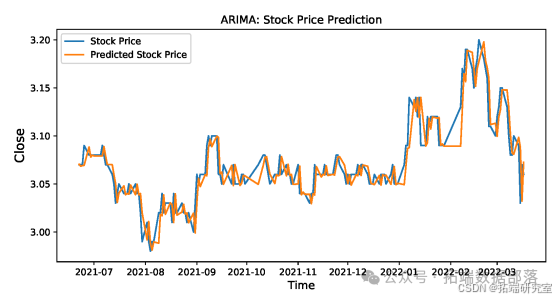
为ARIMA用于股票价格预测的情况。
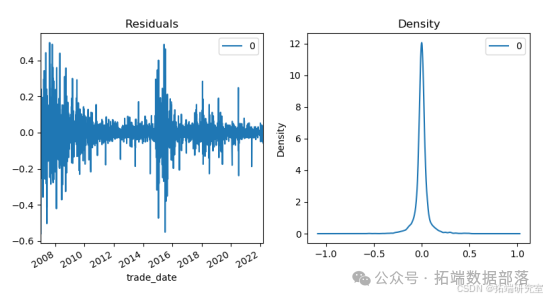
图为残差和残差密度图。
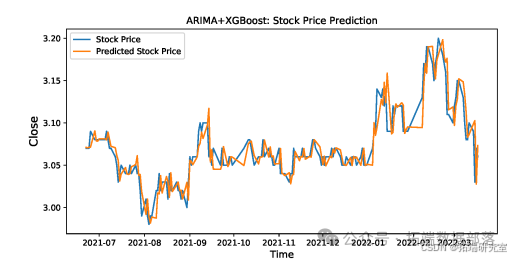
以下是关于ARIMA + XGBoost用于股票价格预测的相关内容:
# 准备数据,划分训练集和测试集
train, test = prepare\_data(merge\_data, n\_test=180, n\_in=6, n_out=1)# 进行前向验证,获取真实值和预测值
y, yhat = walk\_forward\_validation(train, test)
plt.figure(figsize=(10, 6))
plt.plot(time, y, label='Residuals')
plt.plot(time, yhat, label='Predicted Residuals')
plt.title('ARIMA + XGBoost: Residuals Prediction')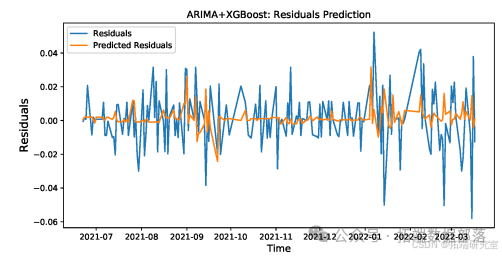
此图为ARIMA + SingleLSTM原始序列的损失曲线。
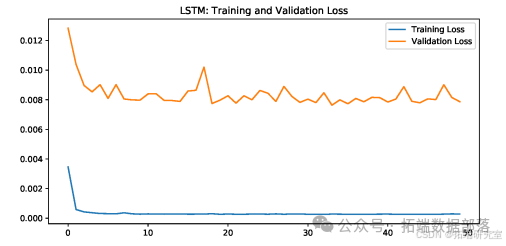
图为ARIMA + SingleLSTM残差序列的损失曲线。
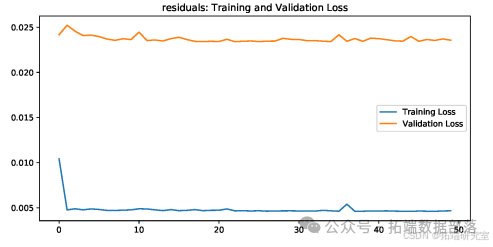
此图为ARIMA + SingleLSTM的股票价格预测结果。
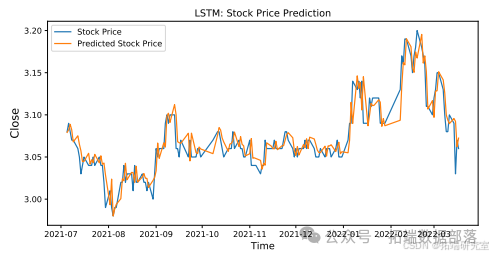
ARIMA + SingleLSTM模型和ARIMA + BiLSTM模型的股票价格预测结果分别如图所示。
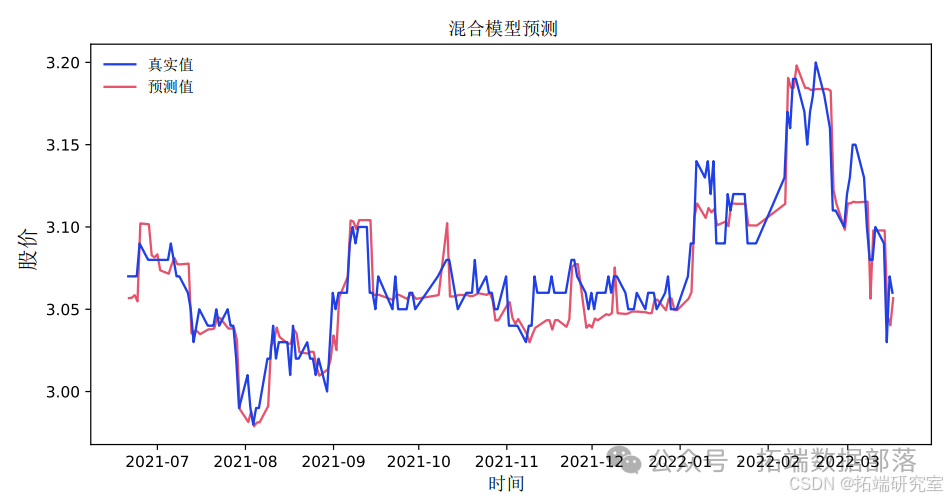
本文所提模型的损失曲线如图所示
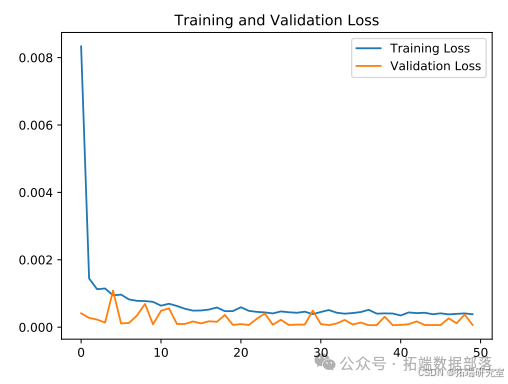
本文所提模型的股票价格预测结果如图所示。
与其他方法比较
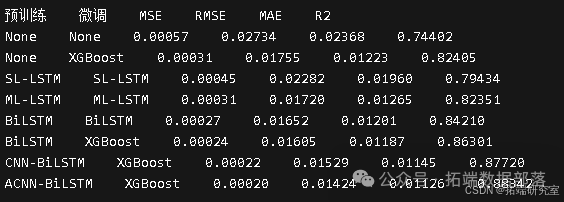
采用的评估指标有平均绝对误差(MAE)、均方根误差(RMSE)、平均绝对百分比误差(MAPE)和(R^{2})。
不同预训练和微调模型的比较情况如下:
结论
股票市场在金融和经济发展中具有极其重要的地位。由于股票市场的复杂波动性,对股票价格趋势的预测能够保障投资者的收益。传统的时间序列模型ARIMA无法描述股票预测中的非线性关系。鉴于神经网络具有强大的非线性建模能力,本文提出了一种基于注意力机制的CNN-LSTM与XGBoost混合模型来预测股票价格。本文中的模型将ARIMA模型、带注意力机制的卷积神经网络、长短期记忆网络以及XGBoost回归器以非线性关系进行整合,提高了预测精度。该模型能够捕捉多个时期的股票市场信息。首先通过ARIMA对股票数据进行预处理,然后采用预训练 - 微调框架所形成的深度学习架构。预训练模型是基于序列到序列框架的基于注意力机制的CNN-LSTM模型,该模型首先利用基于注意力机制的多尺度卷积来提取原始股票数据的深层特征,然后利用长短期记忆网络挖掘时间序列特征,最后采用XGBoost模型进行微调。结果表明,该混合模型更为有效,能够帮助投资者或机构实现扩大收益和规避风险的目的。

本文中分析的数据、代码分享到会员群,扫描下面二维码即可加群!

资料获取
在公众号后台回复“领资料”,可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《Python注意力机制Attention下CNN-LSTM-ARIMA混合模型预测中国银行股票价格|附数据代码》。
点击标题查阅往期内容
R语言KERAS用RNN、双向RNNS递归神经网络、LSTM分析预测温度时间序列、 IMDB电影评分情感
Python用CNN-LSTM、ARIMA、Prophet股票价格预测的研究与分析|附数据代码
【视频讲解】线性时间序列原理及混合ARIMA-LSTM神经网络模型预测股票收盘价研究实例
RNN循环神经网络 、LSTM长短期记忆网络实现时间序列长期利率预测
结合新冠疫情COVID-19股票价格预测:ARIMA,KNN和神经网络时间序列分析
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
用PyTorch机器学习神经网络分类预测银行客户流失模型
PYTHON用LSTM长短期记忆神经网络的参数优化方法预测时间序列洗发水销售数据
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
R语言深度学习卷积神经网络 (CNN)对 CIFAR 图像进行分类:训练与结果评估可视化
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言深度学习Keras循环神经网络(RNN)模型预测多输出变量时间序列
R语言KERAS用RNN、双向RNNS递归神经网络、LSTM分析预测温度时间序列、 IMDB电影评分情感
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言中的神经网络预测时间序列:多层感知器(MLP)和极限学习机(ELM)数据分析报告
R语言深度学习:用keras神经网络回归模型预测时间序列数据
Matlab用深度学习长短期记忆(LSTM)神经网络对文本数据进行分类
R语言KERAS深度学习CNN卷积神经网络分类识别手写数字图像数据(MNIST)
MATLAB中用BP神经网络预测人体脂肪百分比数据
Python中用PyTorch机器学习神经网络分类预测银行客户流失模型
R语言实现CNN(卷积神经网络)模型进行回归数据分析
SAS使用鸢尾花(iris)数据集训练人工神经网络(ANN)模型
【视频】R语言实现CNN(卷积神经网络)模型进行回归数据分析
Python使用神经网络进行简单文本分类
R语言用神经网络改进Nelson-Siegel模型拟合收益率曲线分析
R语言基于递归神经网络RNN的温度时间序列预测
R语言神经网络模型预测车辆数量时间序列
R语言中的BP神经网络模型分析学生成绩
matlab使用长短期记忆(LSTM)神经网络对序列数据进行分类
R语言实现拟合神经网络预测和结果可视化
用R语言实现神经网络预测股票实例
使用PYTHON中KERAS的LSTM递归神经网络进行时间序列预测
python用于NLP的seq2seq模型实例:用Keras实现神经网络机器翻译
用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类



![]()



















