线性回归是统计学中的概念,以其建模速度快,不需要很复杂的计算并且模型解释性强等优点在机器学习中广泛应用。线性回归模型主要用于数据预测,其模型参数常用最小二乘法获得。
一、模型:
最开始人们得到了很多组带有测量误差的数据,比如身高与体重的关系,但是这些数据之间貌似存在某种联系,于是人们想要找到一种近似的函数关系来对这些变量的联系进行某种描述,进而获得某种解释或者对于给定身高的样本预测体重。对于这种问题的分析,在统计学发展起来之后将其归为回归分析,回归被视为一种“估计量”,并从统计的角度保证了回归模型的可靠性,随着机器学习的火热,回归模型也逐渐受到重视。
线性回归是回归模型中最简单的模型,采用一种线性的函数描述数据之间的联系时称之为线性回归,线性回归通常可用最小二乘法进行有效的求解。我们将通过最小化误差的平方和寻找数据的最佳函数参数称之为最小二乘法,误差服从高斯分布时最小二乘法等价于极大似然估计,极大似然估计将会在接下来的章节中讲解。
假设有N组观测值(x1,y2),(x2,y2)...(xn,yn),希望可以使用一条线性曲线来估计这些观测点,使得点尽量在曲线上。使得所选择的回归模型应该使所有观察值的残差平方和达到最小。
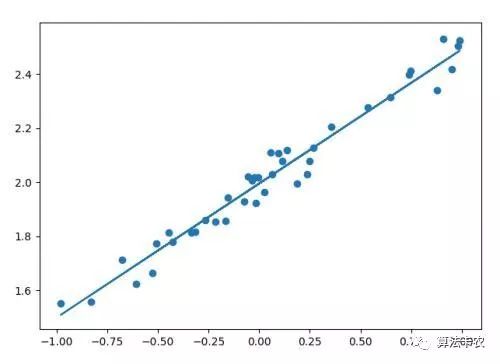
散点为测量得到的数据,直线为要求的函数
假设曲线的函数形式为,以一元一次函数为例:
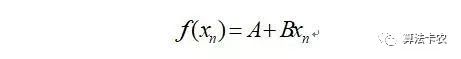
其中第n次误差为:
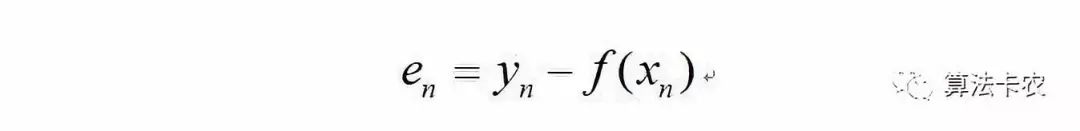
观测值的残差平方和为:
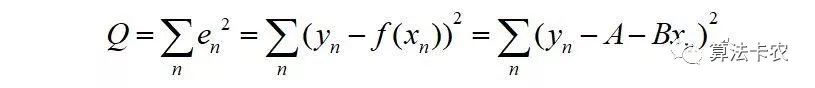
让残差平方和对A和B求偏导,偏导为0时取得极值:
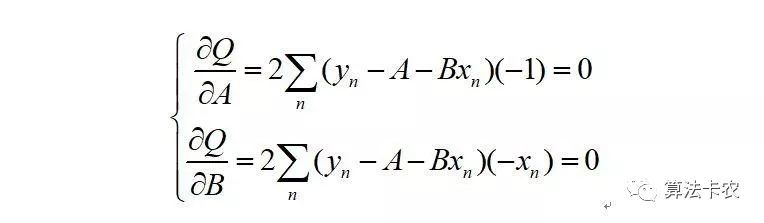
两个方程两个未知数,解出AB的值,即可获得函数的表达式。这种方法对于多元的线性函数也适用,所以对于某些可以转化为线性的函数同样适用。
二、模型评估:
SSE(误差平方和):
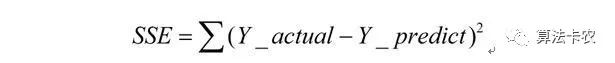
同样的数据集的情况下,SSE越小说明误差越小,模型的效果也就越好;不同数据集下不可比较。
R-square(决定系数):
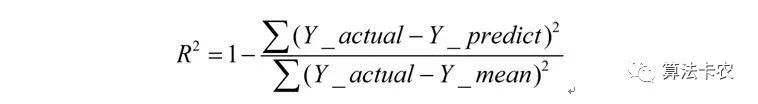
决定系数越接近1,表明方程的变量对数据的解释能力越强,这个模型效果也就越好;决定系数越接近0,表明方程的变量对数据的解释能力越差,这个模型效果也就越差。同样的需要在相同数据集下比较。
三、过拟合问题:
在实际的操作时会发现,训练模型和实际使用模型的效果相差很大,及泛化能太差,这主要是过拟合和欠拟合造成的。对于过拟合是把样本中包含不太一般的特性都学进去了,而欠拟合则是学习能力不够造成的。欠拟合可以通过增加数据量、增加训练轮数等方法克服,过拟合相对比较麻烦,主要有以下几种方法。
留出法是将数据集划分为两个互斥的集合,一个用户训练模型,一个用作测试模型,最后用测试模型的误差作为泛化误差估计。
交叉验证法是从数据集中分层抽样得到k个子集,每次将k-1个子集作为训练集,余下的1个子集作为测试集,获得k个测试结果的均值作为泛化误差估计。
自助法采用有放回的采样获取训练集数据,即每次从数据集D中抽取一个放入训练集D’中,抽中的数据仍然放回D,数据足够多的情况下D中将有36.8%的样本未出现在D’中,可作为测试集用以作为泛化能力的评估。