一、背景
之前看过部分 Megatron-LM 的源码,也详细分析过对应的 Dataset 和 DataLoader,想当然的认为在 LLM 预训练时会使用 Document Level 的 Mask,也就是常说的 Sample Packing 技术。最近我们在做长序列训练相关工作时发现并非如此,并且出现了一些很奇怪的性能问题,因此重新看了相关工作,并进行了部分实验。
Sample Packing 中有很多可以讨论的技术点,比如 Attention 的实现和优化,Sample 的组合及负载均衡问题(有点类似调度问题)以及不同方案对效果的影响等。我们这里只是先简单介绍一下相关问题和实验,后续会进一步探索更多工作,比如 Document Level 的 Mask 到底对预训练效果影响有多大,对 Attention 进行优化还能带来多少提升,如何设计一个比较好的 Packing 策略等?
二、Dataset + Dataloader
简单说来,预训练通常包含很多不同的数据集,每个数据集又包含许多 Document。为了提升训练效率,在实际训练的时候一个 Sample(Sequence)里面可能会包含多个不同的 Document(Sample Packing)。比如 8K 的预训练 Sequence Length,则一个 Sample 可以包含 8 个 1K 的 Document。
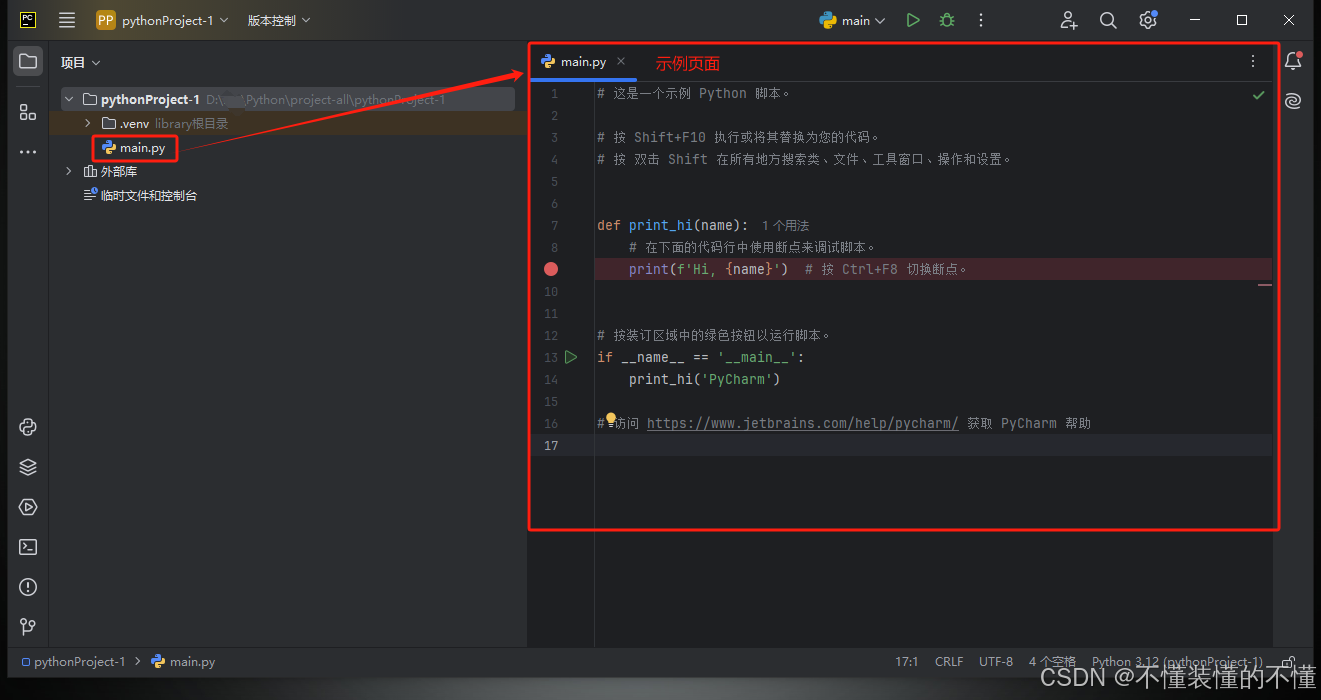
如下图所示,简单展示了 Megatron-LM 中如何 Packing 多个 Document,实际上就是一个多级的索引。需要说明的是,这里其实会引入很多随机读操作,会极大影响读的性能。不过一般 LLM 计算代价都很高,这里也往往不会导致瓶颈。
三、Attention Mask
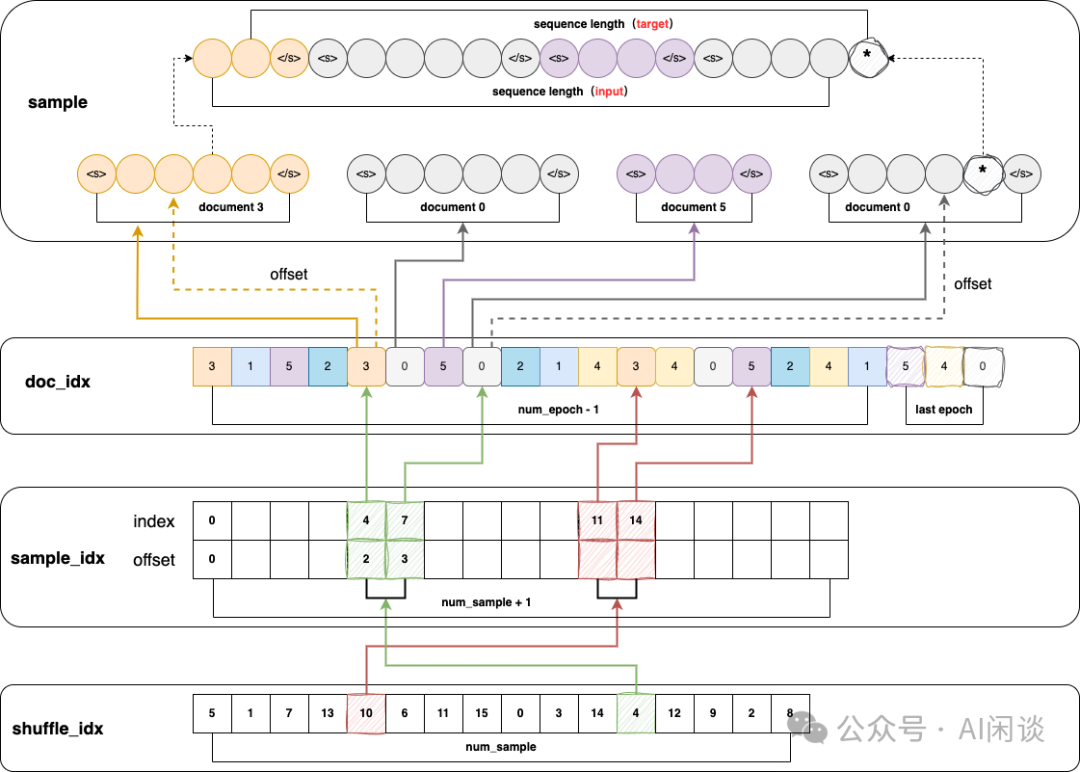
对于单个 Document 而言,Decoder Only 的 GPT 模型具有 Causal 特性,也就是每个 Token 不能看到之后的 Token,因此在实际训练中需要添加 Attention Mask。如下图所示,这种情况下 Attention Mask 是一个标准的下三角矩阵(Causal Mask),也就是绿色部分为 1,其他部分为 0:
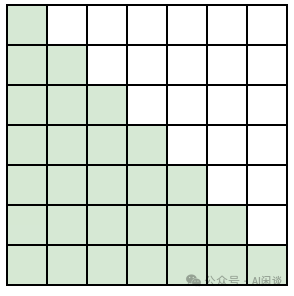
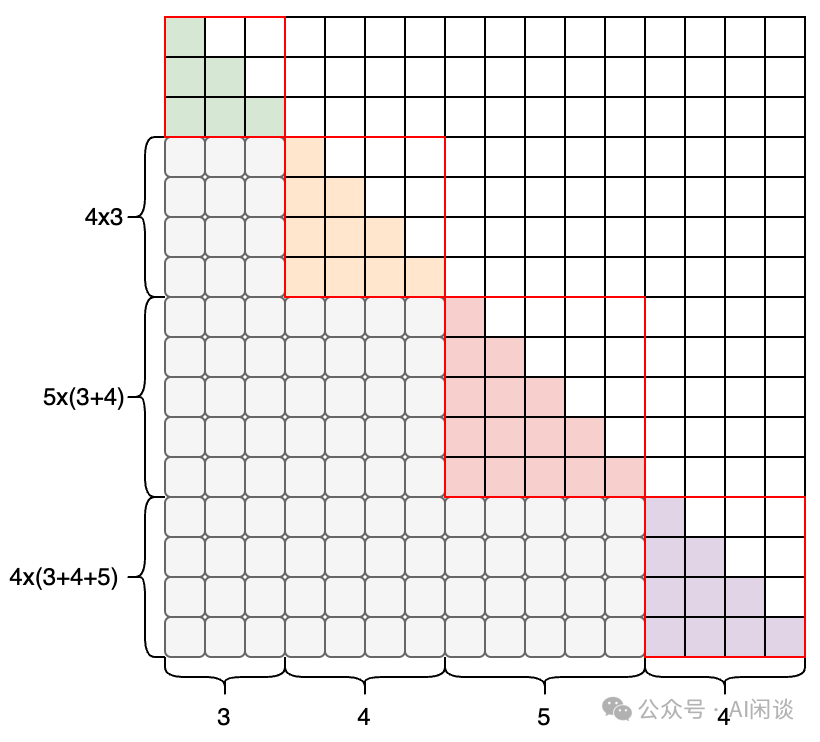
如果一个 Sample 里包含多个样本,则 Attention Mask 矩阵需要变成如下图所示的块对角矩阵形式(Block Diagonal Mask)。比如 Sequence Length 为 16,4 个 Document 的长度分别为 3,4,5,4,则对应 Attention Mask 矩阵如下图所示,对角线上的 4 个矩阵(红框)都是标准的下三角矩阵。按照这种方式可以保证和 4 个 Document 单独作为 Sample 训练是等价的:
四、Reset Attention Mask
4.1 是否需要
那么在实际使用中是否需要严格按照 Block Diagonal Mask 的方式使用呢?答案是否定的,比如 Megatron-LM 可以通过 reset_attention_mask 来控制是使用 Block Diagonal Mask 还是标准的 Causal Mask,默认值为 False。很多模型在预训练时也会采用默认配置,即使用 Causal Mask。
在浪潮的 Yuan-1.0 报告(“源1.0”大模型技术白皮书)中有提到,为了避免不同 Document 之间的相互干扰而将 reset_attention_mask 设置为 True,也就是 Block Diagonal Mask:

在 Meta 的 LLaMA 3.1 技术报告([2407.21783] The Llama 3 Herd of Models)中也提到,在 LLaMA 3.1 模型的预训练中会打开这个配置。不过作者也做了说明,对于 8K Sequence Length 的预训练而言,对模型最终的效果影响不大,对长序列的 Continuous PreTraining 影响比较大:

在 [2402.08268] World Model on Million-Length Video And Language With Blockwise RingAttention 中作者提出了“世界模型”,为了提升超长序列的训练效率,作者采用了 Sample Packing 的策略,并且做了相关消融实验。如下图 Table 10 所示,采用 Naive Packing(不对 Attention Mask 特殊处理)相比使用了 Block Diagonal Mask 的 LWM 的性能会差很多:

PS:当然,目前还没有更多有关预训练中是否 reset_attention_mask 的消融实验,我们后续会进行相关测试。此外,如果采用绝对位置编码,Position-id 也需要相应的调整,在 Megatron-LM 中对应 reset_position_id 选项。
4.2 性能问题
如下图为 Megatron-LM/megatron/core/datasets/gpt_dataset.py 中 reset_attention_mask 的实现方式,首先会将 attention_mask 初始化为标准的 Causal Mask 形式,然后从第二个 Document 开始,将之前的 mask 置为 0:
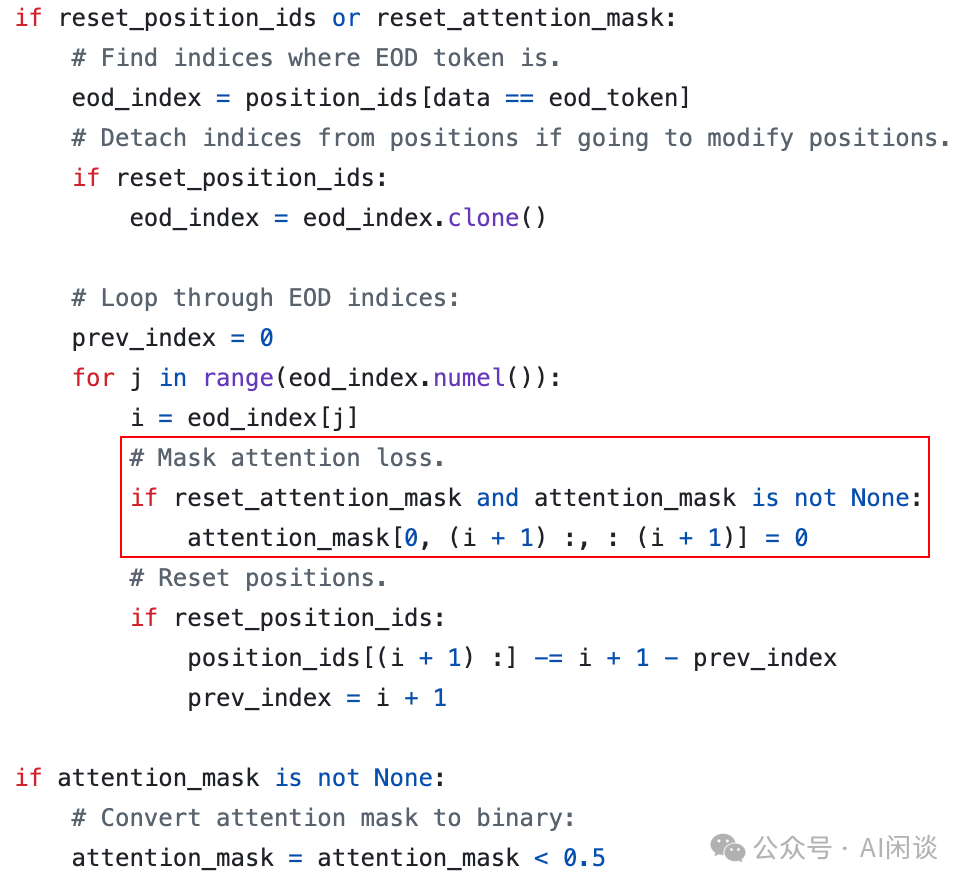
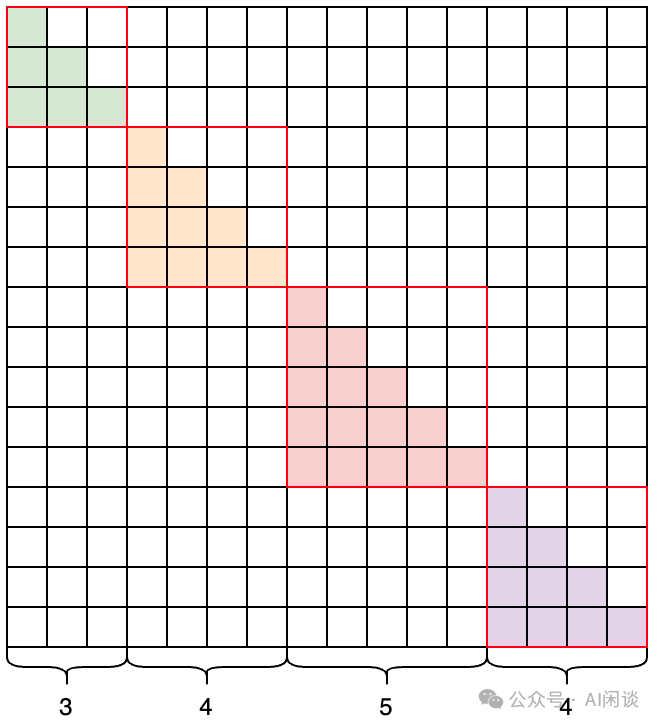
具体来说如下图所示,初始是一个标准的 Causal Mask 矩阵,然后会将 4x3、5x(3+4) 和 4x(3+4+5) 的区域依次置为 0,之后会变成 Block Diagonal Mask:
实际上我们已经知道这里是标准的 Block Diagonal Mask,可以使用 torch.block_diag() 快速创建。实测当序列比较长时(比如 32K),两种方式速度可能会差几十倍,导致 reset_attention_mask 可能成为训练瓶颈:


除此之外,当序列非常长时,Attention Mask 也会占据很大的存储空间,为了计算效率,往往会使用整型而不是 Bool 类型。假设以 int8 存储,32K 序列长度对应的 Mask 大小为 32K * 32K = 1GB,128K 时更是高达 16GB。为了避免显存浪费,其实不必将其拼成大的 Block Diagonal Mask,而保留几个小的 Causal Mask 即可。
五、Attention 优化
5.1 FlashAttention
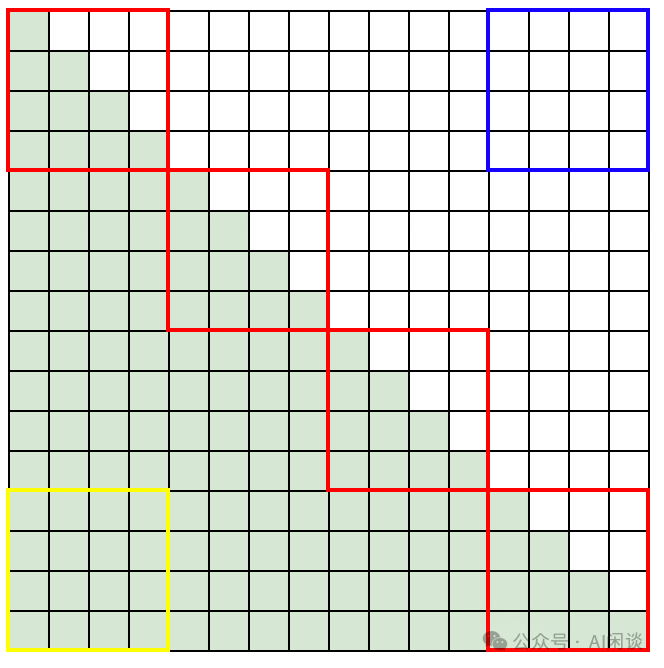
当前 LLM 预训练基本都会使用 FlashAttention,其对 Casual Mask 的方式进行了优化,如下图所示,假设 16x16 的 Attention Mask,在计算时按照 4x4 分块,则可以将其分为 3 种情况:
-
有些块对应的 Mask 都是 0(红框右上部分,比如蓝框),无需再计算。
-
有些块中部分 Mask 为 0,部分 Mask 为 1(红框),需要相应特殊处理。
-
有些块对应的 Mask 都是 1(红框左下部分,比如黄框),全部计算即可。
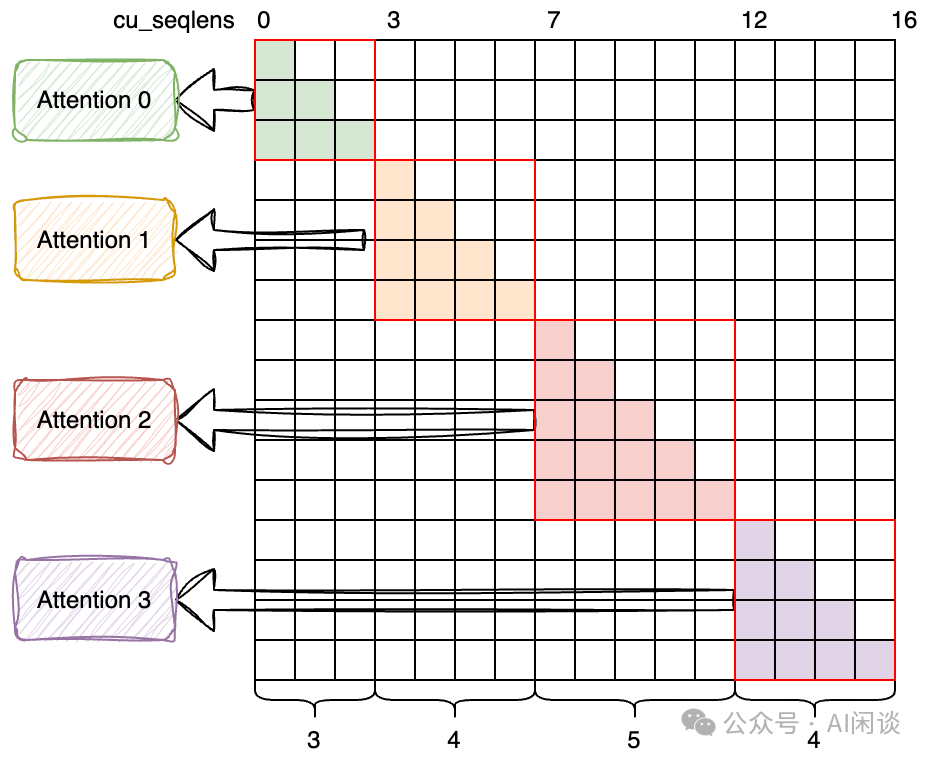
对于上述 Block Diagonal Mask,依然可以使用 Causal Mask 的方式计算,不过会导致大量的无效计算。幸运的是,FlashAttention V2 支持可变序列长度(Varlen)的 Batching Attention 计算,可以避免 Padding 导致的无效计算。因此也就可以借用这种机制来对 Block Diagonal Mask 进行解构,重新分解为多个 Causal Mask 分别计算,可以避免很多无效计算。如下图所示,可以将其看成 4 个独立的 Attention 计算,具体可以参考 FlashAttention Github 上的相关讨论:How to implement example packing with flash_attn v2? · Issue #654 · Dao-AILab/flash-attention · GitHub 和 Will attention_mask be extended to 3D? (concatenate short samples for efficient training) · Issue #432 · Dao-AILab/flash-attention · GitHub。
在 GLM-4([2406.12793] ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools)中也应用了 Sample Packing 方案,并且同样使用了 Block Diagonal Mask 机制来区分不同的 Document。并且作者也是基于 FlashAttention 的 Varlen 功能来实现。
5.2 Pytorch FlashAttention
Pytorch 的 scaled_dot_product_attention 提供了高效的 Attention 实现,也集成了 FlashAttention2 的实现,然而其不支持上述的可变序列长度的功能,导致针对 Block Diagonal Mask 场景时会存在大量的重复计算。
此外,我们在之前的文章中也多次提到,当序列比较短时,Attention 部分计算的占比并不是特别大,因此其中的冗余计算可能对整体训练速度影响不大;但当序列比较长时,Attention 部分计算的占比会越来越大,冗余计算可能会对训练速度有比较大的影响,也就需要对其进行优化。
5.3 FlexAttention
Pytorch 在 2.5.0 版本引入了 FlexAttention(FlexAttention: The Flexibility of PyTorch with the Performance of FlashAttention),可以很容易支持各种 Attention Mask 变种,比如标准 Causal Mask、Sliding Window + Causal、Prefix Mask 以及 Document Mask(Block Diagonal Mask)等,相比 FlashAttention 也更加的灵活。
我们基于 FlexAttention 进行了相关测试,以验证使用 Block Diagonal Mask 的性能优势。首先以两个 16K Document 拼接为一个 32K Sample 为例,Attention Mask 大概是如下图所示方式,对应的稀疏度为 74.80%(整个 Mask 中 0 的占比):
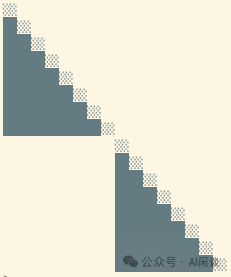
如下图所示我们在 H100 GPU 上进行的 Attention 相关性能测试。可以看出, Pytorch 的 Causal + FlashAttention2 方式确实可以达到非常高的 TFLOPS,明显高于 FlexAttention。然而,因为 FlexAttention 中避免了很多无效计算,实际的 Forward 和 Backward 时间反而更短:

当然,也并不意外着 FlexAttention 总是更优的,还和 Sample 中 Document 长度有关。如下图所示为相应测试结果,32K 表示 Sample 中只有一个 Document,2K + 30K 表示 Sample 中有 2 个 Document,一个长度 2K,一个长度 30K。从下图基本上可以得出这样一个结论:当 Sample 中最长的 Document 的长度 <= Sequence Length/2 时,使用 FlexAttention 可能会带来更大的收益:
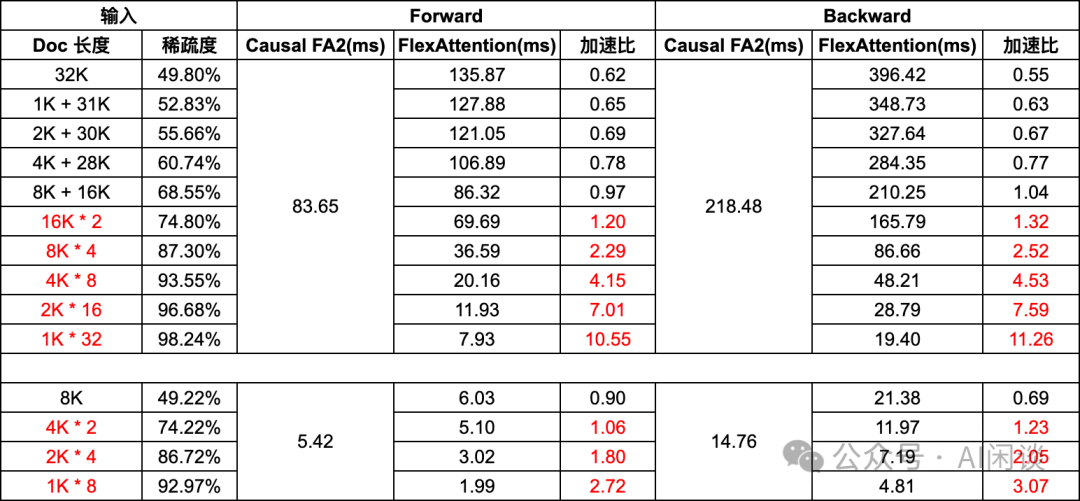
那么为什么“最长的 Document 的长度 <= Sequence Length/2”时会有收益呢?其实可以简单从稀疏度的角度考虑:假设 a1 + a2 + a3 + … + an = S,并且 0 < a1 <= a2 <= a3 <= … <= an <= S/2,那么可以用数学归纳法得出 (a1)^2 + (a2)^2 + (a3)^2 + … + (an)^2 <= S^2/2。也就是说,最长的 Document 的长度 <= Sequence Length/2 时,稀疏度会 >= 75%(还要考虑 Causal 特性),相应的 FlashAttention 中至少有一半的冗余计算。
因此,我们也需要充分考虑在长文本训练过程中短文本的占比,极端情况下训练数据全部是超长文本,每个 Sample 中都只有一个 Document,Block Diagonal Mask 会退化为 Causal Mask。不过有些时候为了避免模型出现灾难性遗忘,也会混合一些短文本数据,或者高质量的预训练数据,不可避免的会出现冗余计算的问题。
5.3 Sequence Parallel
针对长序列场景通常会采用 RingAttention 和 USP 等,然而不管是 RingAttention 还是其 LoadBalance 版本(如下图 Figure 3 所示)等都没有太多讨论 Sample Packing 的情况。对于 Block Diagonal Mask 场景,其相应的优化,LoadBalance 策略也可能需要对应调整:
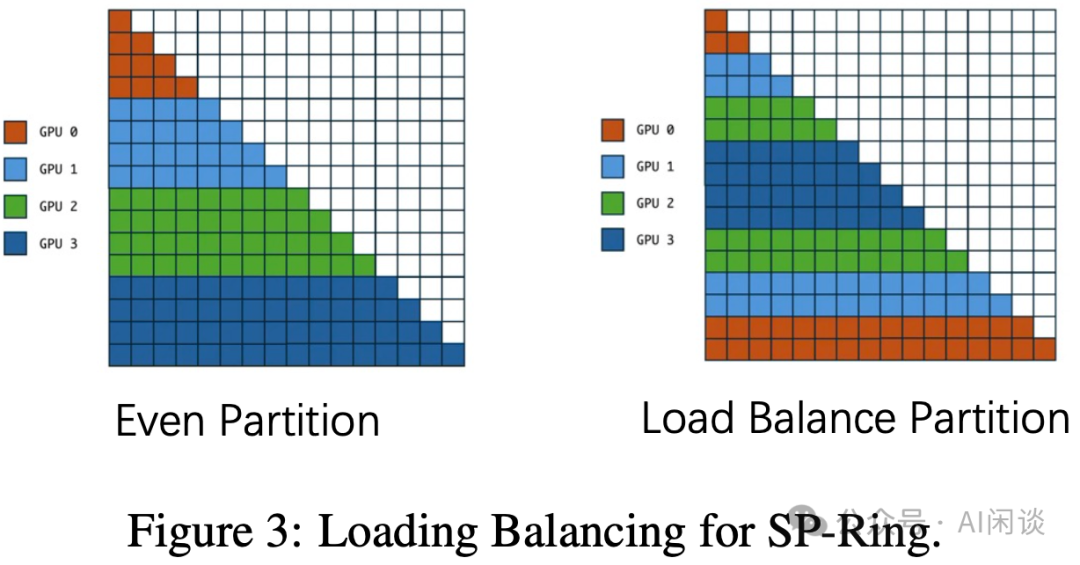
在 [2402.08268] World Model on Million-Length Video And Language With Blockwise RingAttention 中作者(也是 RingAttention 的作者)声称针对 Block Diagonal Mask 场景对 RingAttention 进行相关优化,但并没有对比优化前后训练速度的提升。
PS:整体来说,在各种序列并行技术中更好的兼容 Block Diagonal Mask 场景又会有更多的挑战,我们留作后续介绍。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。