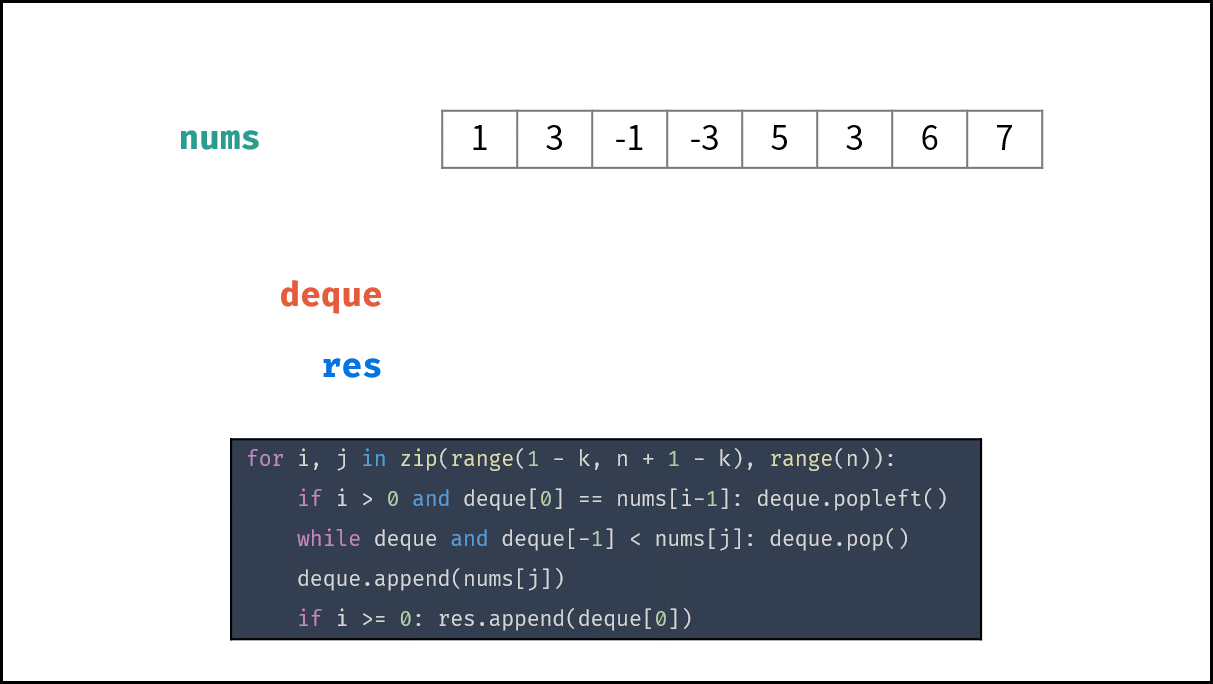
文章目录
- 文章列表
- 十一、SimSiam
- 11.1 研究背景
- 11.2 解决问题
- 11.3 实施方案
- 11.4 论文摘要
- 11.5 文章图示
- 图1:SimSiam架构
- 图2:SimSiam与/无stop-gradient的比较
- 图3:不同孪生网络架构的比较
- 十二、MoCo v3
- 12.1 研究背景
- 12.2 解决问题
- 12.3 论文摘要
- 12.4 论文图示
- 图1:不同批量大小的训练曲线
- 图2:不同学习率的训练曲线
- 图3:使用不同优化器的训练曲线
- 图4:梯度变化和训练曲线的关系
- 图5:随机与学习型patch投影的训练曲线
- 图6:不同自监督学习框架下的训练曲线
- 十三、DINO
- 13.1 研究背景
- 13.2 解决问题
- 13.3 实施方案
- 12.4 论文图示
- 图1:自注意力的可视化
- 图2:DINO方法的示意图
- 图3:不同自监督学习框架的性能比较
- 图4:自注意力图的进一步可视化
- 图5:不同patch大小对性能的影响
- 图6:教师网络的选择对性能的影响
- 十四、上述总结
- 阶段 1
- 阶段 2
- 阶段 3
- 阶段 4
文章列表
文章参考 对比学习论文综述【论文精读】 🌹 🚀
| 是否完成 | 年份 | 文章及其链接 | 简介 | 其他 |
|---|---|---|---|---|
| ✅ | 2018 | InstDisc | 提出实例判别和memory bank做对比学习 | |
| ✅ | 2019 | InvaSpread | 一个编码器的端到端对比学习 | |
| ✅ | 2018 | CPC | 对比预测编码,图像语音文本强化学习全都能做 | |
| ✅ | 2019 | CMC | 多视角下的对比学习 | |
| ✅ | 2019 | MoCov1 | 无监督训练效果也很好 | |
| ✅ | 2020 | SimCLRv1 | 简单的对比学习 (数据增强 + MLP head + 大batch训练久) | |
| ✅ | 2020 | MoCov2 | MoCov1 + improvements from SimCLRv1 | |
| ✅ | 2020 | SimCLRv2 | 大的自监督预训练模型很适合做半监督学习 | |
| ✅ | 2020 | BYOL | 不需要负样本的对比学习 | |
| ✅ | 2020 | SWaV | 聚类对比学习 | |
| ✅ | 2020 | SimSiam | 化繁为简的孪生表征学习 | |
| ✅ | 2021 | MoCov3 | 如何更稳定的自监督训练ViT | |
| ✅ | 2021 | DINO | transformer加自监督在视觉也很香 |
十一、SimSiam
- 《Exploring Simple Siamese Representation Learning》, 论文探讨了一种简化的孪生网络(Siamese networks)在无监督视觉表示学习中的应用。
11.1 研究背景
- 孪生网络在无监督视觉表示学习中越来越流行,这些模型通过最大化同一图像的两种增强视图之间的相似性来学习。
- 以往的孪生网络模型通常需要避免输出“塌陷”到一个常数的非理想解,这通常通过引入负样本对、大批量训练或动量编码器等策略来实现。
11.2 解决问题
- 论文提出了一个问题:是否可以在不使用负样本对、大批量或动量编码器的情况下,使用简单的孪生网络学习有意义的表示。
11.3 实施方案
- 网络架构: SimSiam使用一个编码器网络(由一个主干网络和一个投影MLP组成)处理两个随机增强的图像视图,然后应用一个预测MLP在其中一个视图上,而在另一个视图上应用stop-gradient操作。
- 损失函数: 通过最大化两个视图的输出之间的相似度来训练网络,使用负余弦相似度作为损失函数。
- 训练策略: 论文指出,stop-gradient操作在防止模型输出塌陷中起着至关重要的作用,这一点与以往的方法不同。
11.4 论文摘要
- 摘要: 论文报告了令人惊讶的实验结果,即使不使用负样本对、大批量或动量编码器,简单的孪生网络也能学习到有意义的表示。SimSiam方法在ImageNet和下游任务上取得了有竞争力的结果。
- 重点内容:
- 无需负样本对: 论文展示了即使不使用负样本对,孪生网络也能有效地学习,这挑战了对比学习中负样本对的必要性。
- 无需大批量训练: SimSiam在标准批量大小下也能工作,这与需要大批量训练的模型(如SimCLR)不同。
- 无需动量编码器: 论文发现,与BYOL等模型不同,SimSiam不需要动量编码器来防止输出塌陷。
- stop-gradient的作用: 论文提出了一个假设,认为stop-gradient操作可能暗示了另一种正在被解决的优化问题,并提供了概念验证实验来验证这一假设。
11.5 文章图示
图1:SimSiam架构
.SimSiam体系结构。一个图像的两个增强视图由相同的编码器网络f(主干加投影MLP)处理。然后,在一侧上应用预测MLPh,并且在另一侧上应用停止梯度操作。该模型最大化了双方的相似性。它既不使用负对,也不使用动量编码器。

- 这张图展示了SimSiam方法的神经网络架构。
- 架构包括一个编码器网络( f ),它由一个主干网络(例如ResNet)和一个投影MLP组成。
- 给定一个图像( x )的两个随机增强视图( x1 )和( x2 ),它们被相同的编码器网络( f )处理。
- 然后,一个预测MLP( h )被应用在一个视图的输出上,而另一个视图的输出上应用了stop-gradient操作。
- 模型的目标是最大化两边的相似度,且不使用负样本对或动量编码器。
图2:SimSiam与/无stop-gradient的比较

.SimSiam带与不带停止梯度。左图:训练损失。没有停止梯度,它立即退化。中间图:归一化输出的每通道标准差,绘制为所有通道的平均标准差。右图:kNN分类器[36]作为进度监控器的验证准确性。表:ImageNet线性评估(“w/ stop-grad”是5次试验的平均值±标准差)。
- 左图:展示了有无stop-gradient时的训练损失。
- 中图:展示了( \ell2 )-归一化输出的每个通道的标准差,平均值在所有通道上计算。
- 右图:展示了k最近邻(kNN)分类器的验证准确率,作为进度的监控。
- 表格:展示了ImageNet线性评估的结果,有无stop-gradient的比较。
图3:不同孪生网络架构的比较

编码器包括可以在两个分支之间共享的所有层。虚线表示梯度传播流。在BYOL、SwAV和SimSiam中,缺少虚线意味着停止梯度,并且为了简单起见,没有说明它们的对称化。红色的组件是SimSiam中缺少的组件。
- 这张图将SimSiam与其他几种孪生网络架构进行了对比。
- 包括SimCLR、MoCo v2、BYOL和SwAV等方法。
- 图中用红色标出了SimSiam缺少的组件,如负样本对、动量编码器和Sinkhorn-Knopp变换等。
- 通过对比,展示了SimSiam是如何通过简化这些组件来探索孪生网络的基本作用。
十二、MoCo v3
- 《An Empirical Study of Training Self-Supervised Vision Transformers》,
论文主要研究了在自监督学习环境下训练视觉Transformer(ViT)的基本方法和挑战。
12.1 研究背景
- 自监督学习在自然语言处理(NLP)领域已经取得了巨大成功,而在计算机视觉领域,自监督学习的方法与NLP有所不同,特别是在学习者架构和主干网络的选择上。
- 近期的研究进展表明,Vision Transformers(ViT)在监督学习环境下表现出色,但将其应用于自监督学习环境时,训练方法尚未成熟。
- 为了弥补计算机视觉领域自监督学习与NLP领域之间的差距,并进一步探索自监督学习在视觉任务中的应用,作者决定研究在自监督框架下训练ViT的有效方法。
12.2 解决问题
- 如何在自监督学习环境中有效地训练ViT模型,尤其是在训练过程中遇到的不稳定性问题。
- 论文探讨了ViT在自监督学习框架(如MoCo v3、SimCLR、BYOL和SwAV)下的表现,
并尝试通过实验来解决训练过程中的挑战。
研究实施方案
- 基础实验设置: 作者首先回顾了自监督学习的基本组件,包括批量大小、学习率和优化器,并研究了这些因素如何影响ViT的训练稳定性和性能。
- 不稳定性问题: 论文发现训练过程中的不稳定性是一个主要问题,它可能导致模型性能的轻微下降,但这种下降在没有对比的情况下可能不易被察觉。
- 改进策略: 为了提高训练稳定性,作者提出了一种简单的策略——冻结ViT中的patch投影层,即使用固定的随机patch投影而不是可学习的层。
- 实验验证: 通过在多个自监督学习框架中进行实验,作者验证了冻结patch投影层可以提高模型的稳定性和准确性。
12.3 论文摘要
- 摘要: 论文并没有提出一个新方法,而是对自监督学习环境下训练ViT的基本方法进行了实证研究。作者发现,通过冻结patch投影层这一简单的技巧,可以显著提高ViT在自监督学习中的稳定性和性能。
- 重点内容:
- 训练稳定性: 论文强调了在自监督学习中训练ViT时保持训练稳定性的重要性,并指出不稳定性可能导致性能下降。
- 冻结patch投影层: 作为一种提高稳定性的有效策略,作者展示了冻结patch投影层可以在不同的自监督学习框架中提高ViT的性能。
- 自监督学习框架比较: 论文比较了ViT在不同自监督学习框架下的性能,包括MoCo v3、SimCLR、BYOL和SwAV。
- 实验结果: 通过一系列实验,作者提供了在不同设置下ViT模型性能的数据点,并讨论了自监督学习在视觉任务中的潜力和挑战。
12.4 论文图示
图1:不同批量大小的训练曲线

- 这张图展示了使用不同批量大小(1024、2048、4096、6144)进行训练时的k最近邻(kNN)分类准确率曲线。
- X轴表示训练周期,Y轴表示kNN分类准确率。
- 可以看到,当批量大小增加时,训练过程的稳定性会受到影响,导致准确率曲线出现波动(“dips”),这表明训练过程中存在不稳定性。
图2:不同学习率的训练曲线
- 这张图展示了使用不同学习率(0.5e-4、1.0e-4、1.5e-4)进行训练时的kNN分类准确率曲线。
- 可以看到,学习率的大小直接影响训练的稳定性和最终的准确率。较小的学习率可能导致欠拟合,而较大的学习率可能导致训练不稳定。

图3:使用不同优化器的训练曲线
- 这张图展示了使用AdamW和LAMB优化器进行训练时的kNN分类准确率曲线。
- 可以看到,优化器的选择和学习率的设置对训练稳定性和最终准确率有显著影响。
图4:梯度变化和训练曲线的关系

我们监控梯度大小,显示为层的相对值。梯度中的“尖峰”导致训练曲线中的“骤降”。我们观察到尖峰在第一层中发生得更早,并且在最后一层中延迟了数十次迭代。
- 这张图展示了训练过程中梯度的无穷范数变化和对应的训练曲线。
- 可以看到,梯度的突然变化(“spike”)会导致训练曲线出现下降(“dip”),这进一步证实了训练不稳定性的存在。
图5:随机与学习型patch投影的训练曲线

- 这张图展示了在MoCo v3框架下,使用随机和学习型patch投影进行训练时的kNN分类准确率曲线。
- 可以看到,使用随机patch投影可以提高训练的稳定性,并在不同学习率设置下都能提高准确率。
图6:不同自监督学习框架下的训练曲线

- 这张图展示了在SimCLR和BYOL框架下,使用随机patch投影进行训练时的kNN分类准确率曲线。
- 可以看到,随机patch投影同样可以在这些框架下提高训练的稳定性和准确率。
十三、DINO
- 《Emerging Properties in Self-Supervised Vision Transformers》, 论文探讨了
自监督学习在视觉Transformer(ViT)中的应用,并揭示了自监督学习为ViT带来的一些新特性。
13.1 研究背景
- Transformer模型在
自然语言处理(NLP)领域取得了巨大成功,但在计算机视觉(CV)领域,其应用和效果尚不明确。 - 以往的自监督学习方法在卷积神经网络(CNN)上取得了一定的成功,但这些方法是否适用于Transformer结构尚未得到充分研究。
- Vision Transformers(ViT)是将Transformer应用于视觉识别任务的模型,其性能与CNN相当,但是否能够通过自监督学习进一步提升性能和学习特性,是一个值得探索的问题。
13.2 解决问题
- 论文主要解决的问题是探索自监督学习是否能为ViT带来与CNN不同的特性和优势。
- 研究者们观察到自监督学习ViT的特征包含了图像的显式语义分割信息,这在监督学习ViT和CNN中并不明显。
- 论文还探讨了自监督学习ViT的特征在k-NN分类器中的表现,发现其性能非常出色,这在以往的自监督学习方法中并不常见。
13.3 实施方案
- 自监督学习方法: 研究者们采用了多种自监督学习框架,如MoCo v3、SimCLR、BYOL和SwAV,来训练ViT模型。
- 模型架构: 使用了不同大小的ViT模型,包括ViT-Small、ViT-Base、ViT-Large和ViT-Huge。
- 训练策略: 研究了不同的训练策略,如批量大小、学习率、优化器选择等,以及它们对模型性能和稳定性的影响。
- 实验验证: 在ImageNet数据集上进行了广泛的实验,验证了自监督学习ViT模型的性能,并与其他自监督学习方法进行了比较。
论文摘要与重点内容:
- 摘要: 论文指出,自监督学习不仅能够提升ViT模型的性能,还能使ViT模型学习到一些新的、有别于CNN的特性。特别是,自监督学习ViT的特征能够显式地包含图像的语义分割信息,并且在k-NN分类器中表现出色。
- 重点内容:
- 自监督学习的新特性: 论文发现自监督学习能够使ViT模型学习到显式的图像分割信息,这是以往监督学习方法所不具备的。
- k-NN分类器性能: 自监督学习ViT的特征在k-NN分类器中达到了78.3%的top-1准确率,这一性能在以往的自监督学习方法中是非常突出的。
- 自监督学习方法DINO: 论文提出了一种新的自监督学习方法DINO,该方法通过自监督学习的方式进行知识蒸馏,无需标签即可训练出性能优异的ViT模型。
- 实验结果: 在ImageNet数据集上的实验结果表明,DINO训练的ViT模型在线性评估中达到了80.1%的top-1准确率,超过了以往的自监督学习方法。
12.4 论文图示
文章中提到的图示主要是用来直观展示自监督学习在视觉Transformer(ViT)中的应用效果和特性。以下是对这些图示的详细描述:
图1:自注意力的可视化
- 这张图展示了使用
8×8 patches的Vision Transformer在没有任何监督的情况下训练得到的自注意力(self-attention)。 - 它显示了模型最后一个Transformer层中[CLS] token的自注意力头(heads)的激活情况。
- 这些自注意力图揭示了模型自动学习到的类特定特征,这些特征可以用于无监督的目标分割。

图2:DINO方法的示意图

自蒸馏,无标签。为了简单起见,我们在一对视图(x1,x2)的情况下说明DINO。该模型将输入图像的两种不同的随机变换传递给学生和教师网络。这两种网络具有相同的架构,但参数不同。教师网络的输出以批次计算的平均值为中心每个网络输出一个K维特征,该特征在特征维度上softmax进行归一化。然后用交叉熵损失来衡量它们的相似性。我们在教师上应用停止梯度(sg)算子,仅通过学生传播梯度。教师参数用学生参数的指数移动平均(ema)更新。
- 这张图展示了DINO(Distillation with No Labels)方法的架构,这是一种自监督学习方法。
- 它包括学生网络(student)和教师网络(teacher),两者接收同一输入图像的不同变换。
- 教师网络的输出通过一个中心化(centering)操作,并使用交叉熵损失(cross-entropy loss)与学生网络的输出进行比较。
- 学生网络的参数通过梯度下降法更新,而教师网络的参数是学生网络参数的指数移动平均(EMA)。
图3:不同自监督学习框架的性能比较

- 这张图比较了在ImageNet数据集上,使用不同自监督学习框架(如MoCo v3、SimCLR、BYOL和SwAV)训练的ViT模型的性能。
- 它展示了不同框架在线性评估(linear evaluation)和k-NN分类器(k-NN classifier)上的表现,以及它们在不同ViT模型尺寸下的性能差异。
图4:自注意力图的进一步可视化
- 这张图进一步展示了自监督学习ViT模型中不同自注意力头的激活情况。
- 它揭示了模型如何关注图像中的不同区域,包括被遮挡或较小的对象部分。
图5:不同patch大小对性能的影响
- 这张图展示了使用不同大小的patches(如5x5、8x8、16x16)进行训练时,ViT模型在k-NN分类器上的性能变化。
- 它说明了减小patch大小可以显著提高模型的性能,但同时也会影响模型的推理速度(throughput)。

图6:教师网络的选择对性能的影响
- 这张图展示了使用不同的教师网络更新策略(如动量编码器、前一个epoch的学生网络等)对ViT模型性能的影响。
- 它说明了动量编码器(momentum encoder)在DINO框架中的重要性,以及它如何帮助提高模型的稳定性和性能。
- 图7:避免模型崩溃的策略
- 这张图展示了在DINO框架中,通过中心化(centering)和目标锐化(target sharpening)操作来避免模型输出崩溃(collapse)的效果。
- 它说明了这两种操作如何相互补充,以保持模型输出的多样性和信息量。

- 图8:t-SNE可视化
- 这张图通过t-SNE可视化展示了使用DINO预训练的ViT模型在特征空间中的类表示。
- 它揭示了模型如何将相似的类别聚集在一起,形成有意义的聚类,这表明自监督学习能够捕捉到类别之间的语义关系。
t-SNE(t-distributed Stochastic Neighbor
Embedding)是一种非线性维度缩减技术,用于将高维数据集映射到二维或三维空间中,以便进行可视化。t-SNE
特别适合于展示高维数据集中的局部结构,因为它能够揭示数据点之间的相似性。
在论文中,t-SNE可视化通常用于以下目的:
-
展示数据点的聚类结构:通过t-SNE,可以观察到数据点是如何聚集在一起形成不同的簇的,从而验证模型是否能够学习到有意义的表示。
-
理解模型的特征表示:通过可视化模型学习到的特征,可以直观地看到不同类别的数据点在特征空间中的分布情况,以及它们之间的距离关系。
-
比较不同模型或方法的效果:使用t-SNE可视化不同模型或不同训练条件下的特征表示,可以比较它们在数据聚类和特征区分度方面的表现。 使用了t-SNE来可视化自监督学习下Vision Transformers(ViT)学习到的特征。通过这种可视化,作者可能展示了以下内容:
十四、上述总结

阶段 1
- InstDisc 提出
个体判别的任务,使用memory bank外部数据结构存储负样本,获得又大又一致的的字典。 - Inva Spread (端到端的学习)只用一个编码器。缺点:受限于batch size大小的限制,性能不够好。
- CPC V1 提出infoNCE loss。 它为预测型的代理任务,可以做图像,音频,视频文字和加强学习等。
- CMC 将两个视角的任务拓展到多视角,铺垫了多模态我的对比学习。
- DeepCluster 基于聚类学习
阶段 2
MoCo v1延伸于InstDisc。将memory bank变为队列,加入了动量更新编码器。一个比有监督预训练模型变现更好的无监督预训练模型。SimCLR v1:延伸于Inva Spread。改进:加大batchsize,使用更多数据增强,加入projection head,增加训练时间。
CPC v2 :借鉴前者的技术,性能提升30多个点CMC分析近期技术,提出info Min原则(两个样本或者两个视角之间的互信息,要不多不少才是最好的)Moco v2.将SimCLR v1技术用在 moco v1上,提出Moco v3。SimCLR v2主要做半监督学习。SwAV结合聚类和对比学习。 使用了multi crop技术。
阶段 3
- BYOL:不要负样本,自己学自己,左脚踩右脚。使用mse loss。
- 有博客BN Blog质疑BYOL可以工作是因为batch norm提供一种隐式的负样本,导致模型不会坍塌。
- 新论文BYOL v2,通过消融实验证明BYOL不需要batch norm也可以正常训练。
- SimSiam:化繁为简,总结最近技术,提出简单的孪生网络学习方法,不需要大batch size,也不需要动量编码器和负样本。
- 加入了Stop gradient 操作,使得SimSiam可以被看做EM算法,通过逐步更新的方法,避免模型坍塌。
barlow twins改变了目标函数,使用两个矩阵比较相似性。
阶段 4
- MocoV3:将backbone网络从ResNet改为Vision Transformer,将patch projection layer冻住。
- DINO:同上,方法为把teacher 网络输出做归一化。目的都是使得模型可以稳定训练,防止模型坍塌。
几个改进模型的方法:
- 增加batch size;
- 增加训练时长;
- 加入动量编码器;
- 使用data augmentation;
- 对比学习还有可能会和其他方法进行结合。
- 未来NLP和CV大一统的时代就要到来。
- transformer简单又好用,扩展性也好,可参考方向:tokenization和目标函数。