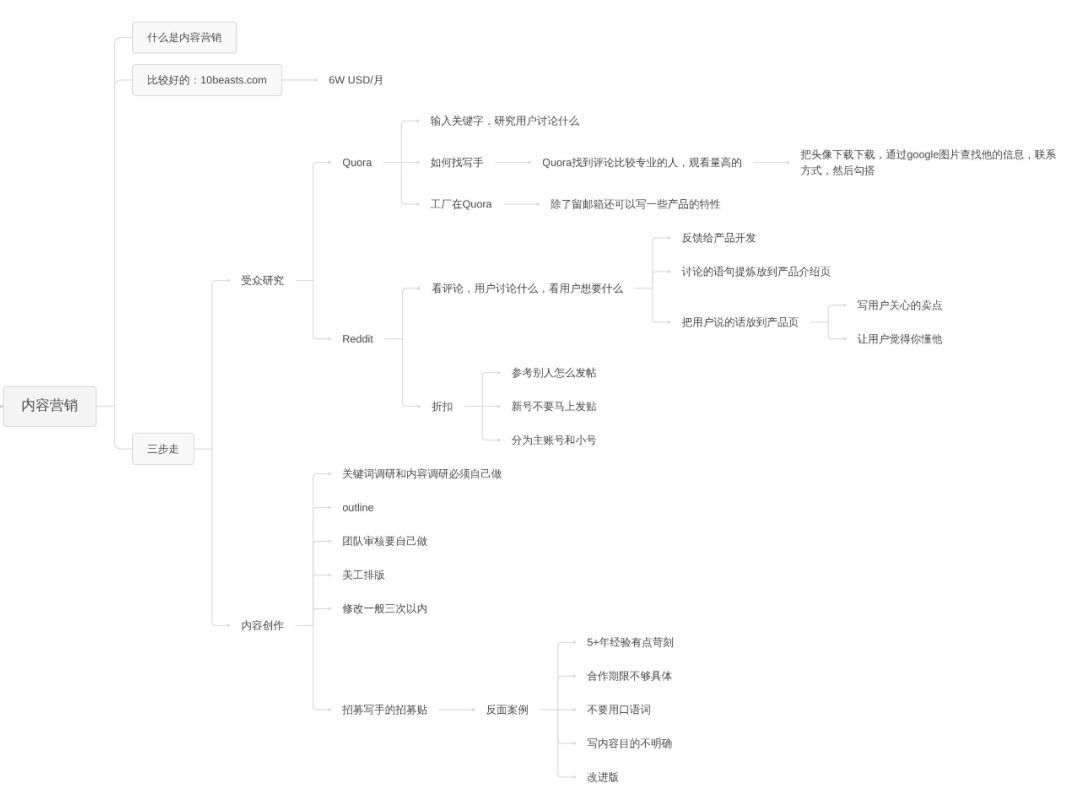
协程的概念与特点
1.1 协程的定义与历史
协程(Coroutine)是一种用户态的轻量级线程,它允许执行被挂起与恢复。与传统的子程序(Subroutine)不同,协程可以在执行过程中暂停,并在之后从暂停点继续执行,而不是从程序的开头重新开始。这种特性使得协程非常适合处理需要等待外部事件(如I/O操作)的任务。
协程的概念最早出现在1963年,由Melvin Conway提出。然而,直到近年来,随着异步编程的兴起,协程才逐渐受到广泛关注。Python在3.4版本中引入了asyncio模块,正式支持协程,并在后续版本中不断完善。
1.2 协程与子程序的区别
协程与子程序(Subroutine)在执行方式上有显著的区别:
-
子程序:子程序是一种线性执行的代码块,当调用子程序时,控制权会完全转移到子程序中,直到子程序执行完毕,控制权才会返回到调用者。子程序的执行是单向的,一旦进入就不能暂停或恢复。
-
协程:协程允许在执行过程中暂停,并在之后从暂停点继续执行。协程的执行是双向的,可以在任意点暂停和恢复。这种特性使得协程非常适合处理需要频繁切换上下文的任务,如网络IO、文件读写等。
1.3 协程的优势与应用场景
协程的主要优势在于其高效的上下文切换和低开销的并发处理能力。与线程相比,协程不需要操作系统的调度,因此避免了线程切换的开销。此外,协程的内存占用也远小于线程,因为协程共享同一进程的内存空间。
协程的应用场景主要包括:
-
I/O密集型任务:如网络爬虫、文件读写、数据库查询等。在这些任务中,协程可以在等待I/O操作完成时暂停,从而提高CPU的利用率。
-
并发编程:协程可以轻松实现并发编程,尤其是在处理大量轻量级任务时,协程的性能优势尤为明显。
-
异步编程:协程是实现异步编程的重要工具。通过使用
async和await关键字,开发者可以编写清晰、易读的异步代码。
代码示例:简单的协程
import asyncioasync def fetch_data():print("Fetching data...")await asyncio.sleep(2) # 模拟I/O操作print("Data fetched!")return {"data": "example"}async def main():print("Starting main function")data = await fetch_data()print("Data received:", data)# 运行协程
asyncio.run(main())
在这个示例中,fetch_data协程模拟了一个耗时的I/O操作(如网络请求),并在等待期间暂停执行。main协程则等待fetch_data完成后再继续执行。通过这种方式,协程可以高效地处理并发任务。
小结
协程是一种强大的并发编程工具,特别适合处理I/O密集型任务。通过使用协程,开发者可以编写高效、易读的异步代码,从而提高程序的性能和响应性。 ## Python中的协程实现
协程(Coroutine)是Python中一种高效的并发编程方式,特别适用于I/O密集型任务。与线程和进程相比,协程更加轻量级,能够在单线程内实现并发,避免了多线程中的上下文切换开销和锁机制的复杂性。本文将详细介绍如何在Python中使用generator实现协程,探讨协程的执行流程,并通过生产者-消费者模型展示协程的应用。
2.1 使用generator实现协程
在Python中,协程可以通过generator(生成器)来实现。生成器是一种特殊的迭代器,允许在函数执行过程中暂停和恢复。通过yield关键字,生成器可以在执行过程中返回值,并在下一次调用时从暂停的地方继续执行。
2.1.1 基本生成器
首先,我们来看一个简单的生成器示例:
def simple_generator():yield 1yield 2yield 3gen = simple_generator()
print(next(gen)) # 输出: 1
print(next(gen)) # 输出: 2
print(next(gen)) # 输出: 3
在这个例子中,simple_generator是一个生成器函数,通过yield关键字返回值。每次调用next(gen)时,生成器会从上一次暂停的地方继续执行,直到遇到下一个yield语句。
2.1.2 协程生成器
协程生成器与普通生成器类似,但可以通过send方法向生成器发送数据。这使得生成器可以在暂停时接收外部数据,并在恢复时处理这些数据。
def coroutine_example():value = yield "Ready to receive"print(f"Received: {value}")yield "Done"coro = coroutine_example()
print(next(coro)) # 输出: Ready to receive
coro.send("Hello, Coroutine!") # 输出: Received: Hello, Coroutine!
在这个例子中,coroutine_example是一个协程生成器。第一次调用next(coro)时,生成器执行到第一个yield语句并返回"Ready to receive"。然后,通过send方法向生成器发送数据"Hello, Coroutine!",生成器从暂停的地方继续执行,并打印接收到的数据。
2.2 协程的执行流程
协程的执行流程与普通函数不同,它可以在执行过程中暂停和恢复。理解协程的执行流程对于编写高效的并发代码至关重要。
2.2.1 协程的生命周期
协程的生命周期可以分为以下几个阶段:
- 创建:通过调用协程函数创建协程对象。
- 启动:通过调用
next()方法启动协程,使其执行到第一个yield语句。 - 暂停:协程在执行到
yield语句时暂停,并返回一个值。 - 恢复:通过
send()方法向协程发送数据,使其从暂停的地方继续执行。 - 结束:当协程执行完毕或遇到
return语句时,协程结束。
2.2.2 协程的调度
在实际应用中,协程通常由事件循环(Event Loop)来调度。事件循环负责管理多个协程的执行,并在I/O操作完成时恢复相应的协程。
import asyncioasync def coroutine_task():print("Coroutine started")await asyncio.sleep(1)print("Coroutine resumed after sleep")async def main():await coroutine_task()asyncio.run(main())
在这个例子中,coroutine_task是一个异步协程,通过await关键字暂停执行,等待asyncio.sleep(1)完成。事件循环负责调度coroutine_task的执行,并在sleep完成后恢复协程。
2.3 生产者-消费者模型中的协程应用
生产者-消费者模型是并发编程中的经典问题,协程可以很好地解决这个问题。生产者生成数据并将其发送给消费者,消费者处理数据。通过协程,生产者和消费者可以在单线程内并发执行,避免了多线程中的锁机制。
2.3.1 生产者-消费者模型的实现
import asyncioasync def producer(queue):for i in range(5):print(f"Producing item {i}")await queue.put(i)await asyncio.sleep(1)async def consumer(queue):while True:item = await queue.get()if item is None:breakprint(f"Consuming item {item}")queue.task_done()async def main():queue = asyncio.Queue()producer_task = asyncio.create_task(producer(queue))consumer_task = asyncio.create_task(consumer(queue))await producer_taskawait queue.join()consumer_task.cancel()asyncio.run(main())
在这个例子中,producer和consumer都是异步协程。producer负责生成数据并将其放入队列中,consumer从队列中取出数据并进行处理。通过asyncio.Queue,生产者和消费者可以在同一个事件循环中并发执行,避免了多线程中的锁机制和上下文切换开销。
2.3.2 协程的优势
在生产者-消费者模型中使用协程有以下优势:
- 简化代码:协程使得生产者和消费者之间的数据传递更加直观和简洁。
- 高效调度:协程可以在同一个线程中运行,避免了线程切换的开销。
- 异步处理:协程可以很好地处理异步任务,提高程序的并发性能。
小结
通过生成器,我们可以在Python中实现轻量级的协程。协程的执行流程与普通函数不同,它可以在执行过程中暂停和恢复,并通过yield和send方法实现双向通信。在生产者-消费者模型中,协程提供了一种简单而高效的方式来处理并发任务,避免了多线程中的线程切换开销和同步问题。通过理解协程的工作原理和优势,我们可以更好地利用协程来提高程序的并发性能。 ## 线程的概念与特点
3.1 线程的定义与工作原理
在计算机科学中,线程(Thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一个进程可以包含多个线程,这些线程共享进程的资源,如内存空间和文件描述符,但每个线程有自己的栈和寄存器状态。
线程的工作原理可以简单概括为以下几个步骤:
- 创建线程:当一个进程启动时,操作系统会为其创建一个主线程。如果需要,进程可以通过调用线程创建函数(如Python中的
threading.Thread)来创建更多的线程。 - 线程调度:操作系统内核负责线程的调度。线程调度器会根据一定的算法(如时间片轮转、优先级调度等)决定哪个线程在何时执行。
- 执行任务:线程执行其指定的任务代码。由于线程共享进程的资源,因此它们可以访问相同的内存空间,这使得线程间的通信和数据共享变得相对简单。
- 线程终止:当线程完成其任务或被显式终止时,它会释放其占用的资源并退出。
在Python中,线程的创建和管理主要通过threading模块来实现。以下是一个简单的线程创建示例:
import threadingdef print_numbers():for i in range(5):print(i)# 创建线程
thread = threading.Thread(target=print_numbers)# 启动线程
thread.start()# 等待线程完成
thread.join()
在这个例子中,我们创建了一个新的线程来执行print_numbers函数,并在主线程中等待该线程完成。
3.2 线程与进程的区别
虽然线程和进程都是并发执行的基本单位,但它们之间存在显著的区别:
-
资源分配:
- 进程是操作系统进行资源分配的基本单位。每个进程都有独立的内存空间、文件描述符等资源。
- 线程是进程中的一个执行路径,多个线程共享同一个进程的资源。
-
切换开销:
- 进程切换需要保存和恢复大量的上下文信息,包括内存映射、文件描述符等,因此开销较大。
- 线程切换只需要保存和恢复少量的寄存器状态和栈信息,因此开销较小。
-
通信方式:
- 进程间通信(IPC)通常需要使用特定的机制,如管道、消息队列、共享内存等,实现起来相对复杂。
- 线程间通信由于共享内存空间,可以直接通过全局变量、共享数据结构等方式进行通信,实现起来相对简单。
-
隔离性:
- 进程之间相互隔离,一个进程的崩溃通常不会影响其他进程。
- 线程之间共享进程的资源,一个线程的错误可能会导致整个进程崩溃。
3.3 线程的优势与挑战
优势
-
资源共享:线程共享进程的内存空间,这使得线程间的数据共享和通信变得非常高效。例如,多个线程可以同时访问和修改同一个数据结构,而不需要复杂的IPC机制。
-
轻量级:相比于进程,线程的创建和销毁开销较小。线程切换的开销也远小于进程切换,这使得线程在处理并发任务时更加高效。
-
响应性:在GUI应用程序中,主线程通常负责处理用户界面事件,而其他线程可以处理后台任务(如网络请求、文件读写等),从而提高应用程序的响应性。
挑战
-
同步问题:由于线程共享进程的资源,多个线程同时访问和修改共享数据时可能会导致数据不一致的问题。为了解决这个问题,需要使用同步机制(如锁、信号量等)来确保线程安全。
-
死锁:当多个线程相互等待对方释放资源时,可能会导致死锁(Deadlock)。死锁会使程序陷入无限等待状态,无法继续执行。
-
调试困难:多线程程序的调试比单线程程序更加复杂,因为线程的执行顺序是不确定的,可能会导致难以重现的bug。
-
GIL限制:在CPython解释器中,全局解释器锁(GIL)限制了多线程的并行执行。GIL确保在任何时刻只有一个线程在执行Python字节码,这限制了多线程在CPU密集型任务中的性能提升。
小结
线程作为操作系统中的基本执行单位,具有资源共享、轻量级和高效并发等优势。然而,线程编程也面临着同步问题、死锁、GIL限制和调试困难等挑战。理解线程的工作原理和特点,合理使用线程同步机制,是编写高效、稳定的多线程程序的关键。 ## Python中的线程实现
在Python编程中,线程是一种轻量级的执行单元,能够在同一进程内并发执行。Python提供了threading模块,使得开发者可以方便地创建和管理线程。本文将详细介绍如何使用threading模块,以及线程同步与锁机制和线程池的应用。
4.1 threading模块的使用
threading模块是Python标准库中用于处理线程的核心模块。通过该模块,开发者可以创建和管理线程,实现多任务并发执行。
创建线程
在Python中,创建线程非常简单。首先,我们需要定义一个函数,该函数将作为线程的执行体。然后,使用threading.Thread类创建线程对象,并调用start()方法启动线程。
import threadingdef worker():print("线程正在运行")# 创建线程对象
thread = threading.Thread(target=worker)# 启动线程
thread.start()
在这个例子中,worker函数是线程的执行体。通过threading.Thread类创建线程对象,并传递target参数指定线程的执行函数。调用start()方法后,线程开始执行。
传递参数
有时,我们需要向线程传递参数。可以通过args和kwargs参数来实现。
def worker(name, age):print(f"姓名: {name}, 年龄: {age}")# 创建线程对象并传递参数
thread = threading.Thread(target=worker, args=("张三", 25))# 启动线程
thread.start()
在这个例子中,args参数是一个元组,包含了传递给worker函数的参数。
线程的生命周期
线程的生命周期包括以下几个阶段:
- 创建:通过
threading.Thread类创建线程对象。 - 启动:调用
start()方法启动线程。 - 运行:线程开始执行目标函数。
- 阻塞:线程在执行过程中可能会因为等待资源或条件而阻塞。
- 终止:线程执行完毕或被强制终止。
线程的属性和方法
threading.Thread类提供了多个属性和方法,用于管理和控制线程的行为:
name:线程的名称,可以通过构造函数或setName()方法设置。ident:线程的唯一标识符。is_alive():判断线程是否正在运行。join(timeout=None):等待线程终止,可以设置超时时间。daemon:设置线程为守护线程,守护线程在主线程退出时会自动终止。
4.2 线程同步与锁机制
在多线程编程中,线程同步是一个重要的问题。当多个线程同时访问共享资源时,可能会导致数据不一致或竞态条件。为了解决这些问题,Python提供了多种同步机制,其中最常用的是锁(Lock)。
锁(Lock)
锁是一种简单的同步机制,用于确保在任何时刻只有一个线程可以访问共享资源。Python的threading模块提供了Lock类,用于创建和管理锁。
import threading# 创建一个锁对象
lock = threading.Lock()# 共享资源
counter = 0def increment():global counterfor _ in range(100000):# 获取锁lock.acquire()counter += 1# 释放锁lock.release()# 创建两个线程
thread1 = threading.Thread(target=increment)
thread2 = threading.Thread(target=increment)# 启动线程
thread1.start()
thread2.start()# 等待线程结束
thread1.join()
thread2.join()print("Counter:", counter)
在这个示例中,我们创建了一个全局变量counter,并定义了一个increment函数,该函数会递增counter的值。为了避免多个线程同时修改counter导致数据不一致,我们在修改counter之前获取锁,修改完成后释放锁。
递归锁(RLock)
递归锁(RLock)是一种特殊的锁,允许同一个线程多次获取锁而不会导致死锁。递归锁在需要多次获取锁的情况下非常有用。
import threading# 创建一个递归锁对象
rlock = threading.RLock()def recursive_function(n):if n <= 0:return# 获取锁rlock.acquire()print(f"递归深度: {n}")recursive_function(n - 1)# 释放锁rlock.release()# 创建一个线程
thread = threading.Thread(target=recursive_function, args=(5,))# 启动线程
thread.start()# 等待线程结束
thread.join()
在这个示例中,我们定义了一个递归函数recursive_function,该函数在每次递归调用时都会获取递归锁,并在递归返回时释放锁。
条件变量(Condition)
条件变量(Condition)是一种更高级的同步机制,允许线程在某个条件满足时等待或通知其他线程。条件变量通常与锁一起使用,以确保线程在等待或通知时的同步。
import threading
import time# 创建一个条件变量对象
condition = threading.Condition()# 共享资源
data = []def producer():for i in range(5):with condition:data.append(i)print(f"生产者生产了数据: {i}")# 通知等待的消费者condition.notify()time.sleep(1)def consumer():while True:with condition:while not data:# 等待生产者通知condition.wait()item = data.pop(0)print(f"消费者消费了数据: {item}")# 创建生产者和消费者线程
producer_thread = threading.Thread(target=producer)
consumer_thread = threading.Thread(target=consumer)# 启动线程
producer_thread.start()
consumer_thread.start()# 等待线程结束
producer_thread.join()
consumer_thread.join()
在这个示例中,我们定义了一个生产者函数producer和一个消费者函数consumer。生产者会生成数据并通知消费者,消费者在接收到通知后消费数据。条件变量condition用于同步生产者和消费者的行为。
4.3 线程池的应用
在实际应用中,频繁地创建和销毁线程会带来较大的开销。为了提高效率,可以使用线程池来管理线程的生命周期。Python的concurrent.futures模块提供了ThreadPoolExecutor类,用于创建和管理线程池。
使用ThreadPoolExecutor
ThreadPoolExecutor允许开发者将任务提交给线程池,由线程池自动分配线程来执行任务。线程池会自动管理线程的创建和销毁,从而减少开销。
from concurrent.futures import ThreadPoolExecutor
import timedef task(n):print(f"任务 {n} 开始执行")time.sleep(2)print(f"任务 {n} 执行完毕")return n * n# 创建一个线程池,最大线程数为3
with ThreadPoolExecutor(max_workers=3) as executor:# 提交任务futures = [executor.submit(task, i) for i in range(5)]# 获取任务结果for future in futures:print(f"任务结果: {future.result()}")
在这个示例中,我们定义了一个task函数,该函数会模拟一个耗时的任务。我们使用ThreadPoolExecutor创建了一个最大线程数为3的线程池,并将5个任务提交给线程池执行。线程池会自动分配线程来执行任务,并在任务完成后返回结果。
线程池的优势
使用线程池的主要优势包括:
- 减少线程创建和销毁的开销:线程池会预先创建一定数量的线程,并在任务执行完毕后复用这些线程,从而减少线程创建和销毁的开销。
- 提高任务执行效率:线程池可以自动管理线程的分配和调度,确保任务能够高效地执行。
- 简化并发编程:开发者无需手动管理线程的生命周期,只需将任务提交给线程池即可。
小结
本文详细介绍了Python中threading模块的使用、线程同步与锁机制以及线程池的应用。通过合理使用线程和线程池,开发者可以实现高效的并发编程,提高程序的执行效率。线程同步机制如锁、递归锁和条件变量能够有效避免多线程环境下的数据竞争问题。线程池则能够减少线程创建和销毁的开销,提高任务执行效率。
通过本文的介绍,希望读者能够深入理解Python中线程的实现方式,并在实际项目中灵活应用,提升程序的性能和并发处理能力。 ## 进程的概念与特点
5.1 进程的定义与工作原理
在计算机科学中,进程是操作系统进行资源分配和调度的基本单位。简单来说,一个进程就是一个正在运行的程序的实例。每个进程都有自己的内存空间、文件描述符、寄存器状态等资源。操作系统通过进程管理器来创建、调度和销毁进程。
进程的工作原理
- 创建:当一个程序启动时,操作系统会为其创建一个新的进程。这个过程包括分配内存、初始化进程控制块(PCB)等。
- 调度:操作系统根据一定的调度算法(如时间片轮转、优先级调度等)决定哪个进程获得CPU时间。
- 执行:进程获得CPU时间后,开始执行其代码。
- 阻塞:如果进程需要等待某些资源(如I/O操作),它会进入阻塞状态,CPU时间会被分配给其他进程。
- 唤醒:当阻塞的资源可用时,进程会被唤醒,重新进入就绪状态,等待调度。
- 销毁:当进程完成其任务或被终止时,操作系统会回收其资源,销毁进程。
5.2 进程与线程的对比
虽然进程和线程都是操作系统进行并发执行的基本单位,但它们之间存在显著的区别:
- 资源分配:每个进程拥有独立的内存空间和系统资源,而线程共享其所属进程的资源。这意味着进程之间的切换开销较大,而线程之间的切换开销较小。
- 并发性:进程之间的并发性是通过操作系统调度实现的,而线程之间的并发性是通过线程调度器实现的。多个线程可以在同一个进程中并发执行,共享进程的资源。
- 隔离性:由于进程拥有独立的内存空间,一个进程的崩溃通常不会影响其他进程。而线程共享进程的内存,一个线程的错误可能会导致整个进程崩溃。
- 通信:进程之间的通信通常需要通过操作系统提供的IPC(进程间通信)机制,如管道、消息队列、共享内存等。而线程之间的通信则可以通过共享内存直接进行。
5.3 进程的优势与应用场景
进程在并发编程中有其独特的优势和应用场景:
- 隔离性:由于每个进程拥有独立的内存空间,进程之间的隔离性较好。这使得进程更适合处理需要高度隔离的任务,如服务器进程、数据库进程等。
- 稳定性:一个进程的崩溃通常不会影响其他进程,这使得进程在处理关键任务时更加稳定。例如,Web服务器通常会为每个请求创建一个独立的进程,以确保一个请求的失败不会影响其他请求。
- 多核利用:进程可以充分利用多核CPU的优势。通过创建多个进程,操作系统可以将它们分配到不同的CPU核心上并行执行,从而提高系统的整体性能。
- 复杂任务:对于需要长时间运行的复杂任务,进程是一个理想的选择。例如,数据处理、图像渲染等任务可以通过创建多个进程来并行处理,从而缩短任务的完成时间。
在实际应用中,进程通常用于以下场景:
- Web服务器:如Nginx、Apache等,通常会为每个请求创建一个独立的进程。
- 数据库服务器:如MySQL、PostgreSQL等,通常会为每个连接创建一个独立的进程。
- 并行计算:如科学计算、数据分析等,通常会使用多进程来并行处理大规模数据。
总之,进程在并发编程中扮演着重要的角色,尤其是在需要高度隔离、稳定性和多核利用的场景中。通过合理地使用进程,可以显著提高系统的性能和稳定性。
通过以上内容,我们详细介绍了进程的定义、工作原理、与线程的对比以及其优势和应用场景。希望这些内容能够帮助你更好地理解进程在并发编程中的重要性。 ## Python中的进程实现
在Python中,进程(Process)是实现并行计算的重要手段。通过多进程,我们可以充分利用多核CPU的计算能力,提高程序的执行效率。Python提供了multiprocessing模块,使得创建和管理进程变得非常简单。本文将详细介绍如何使用multiprocessing模块来实现多进程编程,包括进程的创建、进程间通信以及进程池的应用。
6.1 multiprocessing模块的使用
multiprocessing模块是Python标准库中用于创建和管理进程的核心模块。它提供了与threading模块类似的API,使得开发者可以轻松地将线程代码转换为进程代码。
创建进程
在multiprocessing模块中,Process类用于创建进程。每个进程都是一个独立的执行单元,拥有自己的内存空间。创建进程的基本步骤如下:
- 导入模块:首先需要导入
multiprocessing模块。 - 定义目标函数:创建一个函数,该函数将作为新进程的执行任务。
- 创建Process对象:使用
Process类创建一个进程对象,并指定目标函数。 - 启动进程:调用
start()方法启动进程。 - 等待进程结束:使用
join()方法等待进程执行完毕。
以下是一个简单的示例,展示了如何创建并启动一个进程:
import multiprocessing
import osdef worker():print(f"Process ID: {os.getpid()}")print("Worker process is running...")if __name__ == "__main__":print(f"Main process ID: {os.getpid()}")p = multiprocessing.Process(target=worker)p.start()p.join()print("Main process exiting.")
在这个示例中,worker函数将在一个新的进程中执行,输出当前进程的ID和一条消息。主进程通过join()方法等待子进程执行完毕后再继续执行。
传递参数
与线程类似,进程也可以传递参数。Process类的构造函数接受args和kwargs参数,用于传递给目标函数的位置参数和关键字参数。
import multiprocessingdef worker(name, age):print(f"Hello, {name}! You are {age} years old.")if __name__ == "__main__":p = multiprocessing.Process(target=worker, args=("Alice", 30))p.start()p.join()
在这个示例中,worker函数接收两个参数name和age,并在新进程中打印出来。
6.2 进程间通信
由于进程拥有独立的内存空间,因此它们之间的数据共享不像线程那样直接。为了实现进程间通信(IPC),Python的multiprocessing模块提供了多种机制,包括队列(Queue)、管道(Pipe)和共享内存(Shared Memory)。
使用队列(Queue)
队列是一种先进先出(FIFO)的数据结构,适用于在多个进程之间传递数据。multiprocessing.Queue类提供了线程和进程安全的队列实现。
import multiprocessingdef producer(queue):for i in range(5):queue.put(i)print(f"Produced: {i}")def consumer(queue):while True:item = queue.get()if item is None:breakprint(f"Consumed: {item}")if __name__ == "__main__":queue = multiprocessing.Queue()p1 = multiprocessing.Process(target=producer, args=(queue,))p2 = multiprocessing.Process(target=consumer, args=(queue,))p1.start()p2.start()p1.join()queue.put(None) # Signal the consumer to stopp2.join()
在这个示例中,producer进程将数据放入队列,而consumer进程从队列中取出数据。当producer完成任务后,它会向队列中放入一个None,通知consumer进程停止。
使用管道(Pipe)
管道是另一种进程间通信的方式,它提供了一个双向通信通道。multiprocessing.Pipe类返回两个连接对象,分别代表管道的两端。
import multiprocessingdef sender(conn):conn.send("Hello from sender!")conn.close()def receiver(conn):msg = conn.recv()print(f"Received: {msg}")conn.close()if __name__ == "__main__":parent_conn, child_conn = multiprocessing.Pipe()p1 = multiprocessing.Process(target=sender, args=(child_conn,))p2 = multiprocessing.Process(target=receiver, args=(parent_conn,))p1.start()p2.start()p1.join()p2.join()
在这个示例中,sender进程通过管道发送消息,receiver进程接收消息。管道是双向的,因此两端的进程可以互相发送和接收数据。
6.3 进程池的应用
在实际应用中,频繁地创建和销毁进程会带来较大的开销。为了提高效率,可以使用进程池(Process Pool)来管理一组预先创建的进程。multiprocessing.Pool类提供了一个方便的接口来创建和管理进程池。
创建进程池
Pool类的构造函数接受一个整数参数,表示池中进程的数量。如果不指定参数,默认使用CPU的核心数。
import multiprocessingdef square(x):return x * xif __name__ == "__main__":with multiprocessing.Pool(processes=4) as pool:results = pool.map(square, range(10))print(results)
在这个示例中,我们创建了一个包含4个进程的进程池,并使用map方法将square函数应用到range(10)中的每个元素。map方法会自动将任务分配给池中的进程,并收集结果。
异步执行
Pool类还提供了apply_async方法,用于异步执行任务。异步执行允许任务在后台运行,而不阻塞主进程。
import multiprocessing
import timedef slow_square(x):time.sleep(1)return x * xif __name__ == "__main__":with multiprocessing.Pool(processes=4) as pool:results = []for i in range(10):result = pool.apply_async(slow_square, args=(i,))results.append(result)for result in results:print(result.get())
在这个示例中,slow_square函数模拟了一个耗时的操作。通过apply_async方法,我们可以异步地执行这些任务,并在所有任务完成后获取结果。
小结
通过multiprocessing模块,Python提供了强大的多进程编程能力。无论是简单的进程创建,还是复杂的进程间通信和进程池管理,multiprocessing模块都提供了丰富的工具和API。掌握这些技术,可以帮助开发者充分利用多核CPU的计算能力,提高程序的执行效率。
在下一节中,我们将探讨协程、线程与进程的综合应用,以及如何在实际项目中选择和优化这些并发模型。 ## 协程、线程与进程的综合应用
在现代编程中,协程、线程和进程是实现并发和并行的三种主要方式。每种方式都有其独特的优势和适用场景。本文将深入探讨如何在多核CPU环境下结合协程与进程,以及在异步IO模型中如何应用协程,并提供实际项目中的选择与优化建议。
7.1 多核CPU下的协程与进程结合
在多核CPU环境下,充分利用硬件资源是提高程序性能的关键。协程和进程的结合可以有效地提升并发处理能力。
协程的优势
协程是一种轻量级的并发机制,能够在单线程内实现高效的并发操作。协程的优势在于其上下文切换的开销远小于线程,且不需要复杂的锁机制,避免了死锁和竞态条件的问题。
进程的优势
进程是操作系统资源分配的基本单位,每个进程都有独立的内存空间,因此进程之间的隔离性非常好。在多核CPU环境下,使用进程可以充分利用多个CPU核心,实现真正的并行计算。
结合使用
在多核CPU环境下,可以将协程与进程结合使用,以发挥各自的优势。具体做法是:
- 主进程管理任务分发:主进程负责将任务分发到不同的子进程中。
- 子进程运行协程:每个子进程内部运行多个协程,以实现高效的并发操作。
import asyncio
import multiprocessingasync def worker(task):print(f"Processing task: {task}")await asyncio.sleep(1) # 模拟耗时操作print(f"Completed task: {task}")def process_tasks(tasks):loop = asyncio.get_event_loop()loop.run_until_complete(asyncio.gather(*(worker(task) for task in tasks)))if __name__ == "__main__":tasks = [1, 2, 3, 4, 5]num_processes = 2with multiprocessing.Pool(num_processes) as pool:pool.map(process_tasks, [tasks[i::num_processes] for i in range(num_processes)])
在这个示例中,主进程将任务分发到两个子进程中,每个子进程内部使用协程来处理任务。这种方式既利用了多核CPU的并行能力,又发挥了协程的高效并发特性。
7.2 异步IO模型中的协程应用
异步IO模型是现代高性能网络编程的基础。协程在异步IO模型中的应用,可以显著提高程序的响应速度和吞吐量。
异步IO模型的优势
异步IO模型通过非阻塞IO操作和事件驱动的方式,避免了传统阻塞IO模型中的线程切换开销。协程作为异步IO模型的核心组件,能够在单线程内实现高效的IO操作。
协程在异步IO中的应用
在异步IO模型中,协程通常与事件循环(Event Loop)结合使用。事件循环负责调度协程的执行,并在IO操作完成时恢复协程的执行。
import asyncioasync def fetch_data(url):print(f"Fetching data from {url}")await asyncio.sleep(1) # 模拟网络请求print(f"Data fetched from {url}")async def main():urls = ["http://example.com", "http://example.org", "http://example.net"]tasks = [fetch_data(url) for url in urls]await asyncio.gather(*tasks)if __name__ == "__main__":asyncio.run(main())
在这个示例中,fetch_data协程模拟了一个网络请求操作。main协程使用asyncio.gather来并发执行多个网络请求,从而提高了程序的响应速度。
7.3 实际项目中的选择与优化
在实际项目中,选择合适的并发模型是提高程序性能的关键。以下是一些选择与优化的建议:
选择合适的并发模型
- IO密集型任务:优先选择协程,因为协程在IO密集型任务中表现出色,且不需要复杂的线程管理。
- CPU密集型任务:优先选择进程,因为进程可以充分利用多核CPU的并行计算能力。
- 混合型任务:可以结合使用协程和进程,以发挥各自的优势。
优化并发模型
- 减少上下文切换:尽量减少线程和进程的上下文切换,可以通过合理分配任务和使用线程池/进程池来实现。
- 避免竞态条件:在多线程或多进程环境中,注意避免竞态条件和死锁问题,可以使用锁机制或无锁数据结构。
- 监控与调优:使用性能监控工具(如
cProfile、py-spy等)来监控程序的运行情况,并根据监控结果进行调优。
import multiprocessing
import threading
import timedef cpu_bound_task(n):return sum(i * i for i in range(n))def io_bound_task(url):time.sleep(1) # 模拟网络请求return f"Data fetched from {url}"def main():# CPU密集型任务使用进程池with multiprocessing.Pool(4) as pool:results = pool.map(cpu_bound_task, [10**6, 10**6, 10**6, 10**6])print(results)# IO密集型任务使用线程池with threading.ThreadPoolExecutor(max_workers=4) as executor:futures = [executor.submit(io_bound_task, f"http://example.com/{i}") for i in range(4)]results = [future.result() for future in futures]print(results)if __name__ == "__main__":main()
在这个示例中,CPU密集型任务使用进程池来并行处理,IO密集型任务使用线程池来并发处理。通过合理选择并发模型,可以显著提高程序的性能。
小结
协程、线程和进程是实现并发和并行的三种主要方式。在多核CPU环境下,结合协程与进程可以充分利用硬件资源,提高程序的并发处理能力。在异步IO模型中,协程的应用可以显著提高程序的响应速度和吞吐量。在实际项目中,选择合适的并发模型并进行优化,是提高程序性能的关键。
通过本文的介绍,希望读者能够更好地理解协程、线程和进程的综合应用,并在实际项目中灵活运用这些技术,提升程序的并发性和性能。





![[Matplotlib教程] 02 折线图、柱状图、散点图教程](https://img-blog.csdnimg.cn/img_convert/eb0d2849d0b92c7e744e3d7d2bdf29bb.png)