第15章 程序的动态加载和执行
该章节讲解了MBR加载内核,然后内核加载用户程序这样一套流程,模拟操作系统的工作原理。
本章代码清单
本章的代码实现的功能位:主引导扇区加载内核,内核加载用户程序,用户程序通过调用内核API接口实现读取硬盘数据,在页面上打印读取到的数据。
内核的结构、功能和加载
内核的结构
内核的结构:初始化代码、公共例程段、内核数据段和内核代码段。
初始化代码,内核头部数据,供加载时定位内核的各个部分SECTION sys_routine vstart=0 ;公共例程段
.....SECTION core_data vstart=0 ;内核数据段
......SECTION core_code vstart=0 ;内核代码段
......SECTION core_trail ;系统结尾,主要是计算内核长度
core_end:
声明内核选择子:将常量声明在代码前,即清晰,编译后又不占用空间。
;以下常量定义部分。内核的大部分内容都应当固定
core_code_seg_sel equ 0x38 ;内核代码段选择子
core_data_seg_sel equ 0x30 ;内核数据段选择子
sys_routine_seg_sel equ 0x28 ;系统公共例程代码段的选择子
video_ram_seg_sel equ 0x20 ;视频显示缓冲区的段选择子
core_stack_seg_sel equ 0x18 ;内核堆栈段选择子
mem_0_4_gb_seg_sel equ 0x08 ;整个0-4GB内存的段的选择子
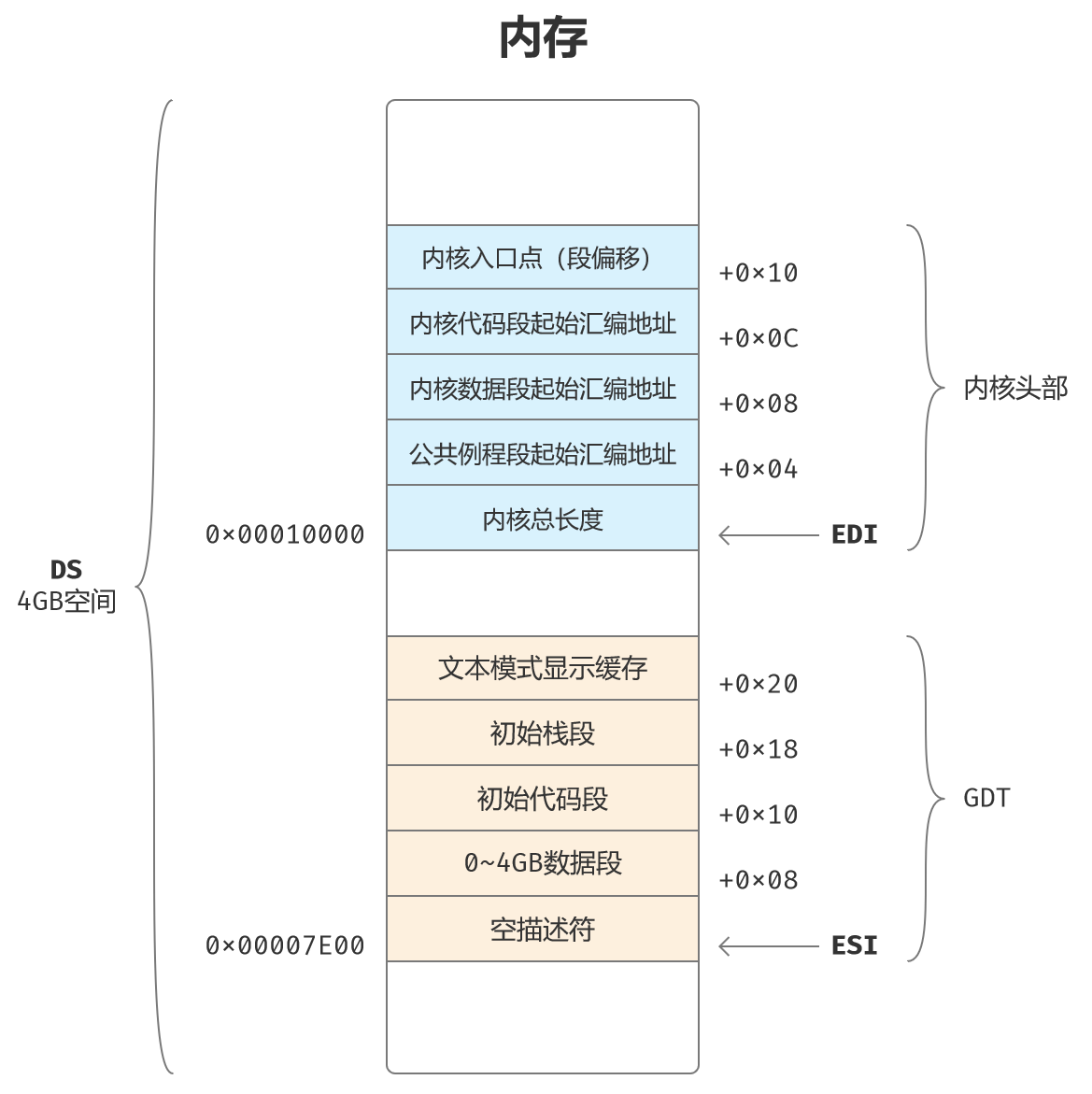
声明核心头部:被加载的程序都需要一个头部,来描述自身的信息。
;以下是系统核心的头部,用于加载核心程序
core_length dd core_end ;核心程序总长度#00sys_routine_seg dd section.sys_routine.start;系统公用例程段位置#04core_data_seg dd section.core_data.start;核心数据段位置#08core_code_seg dd section.core_code.start;核心代码段位置#0ccore_entry dd start ;核心代码段入口点#10dw core_code_seg_sel
内核的加载
内核的加载是由主引导程序 mbr 进行的。
声明内核加载的内存位置和存放在硬盘逻辑扇区号:
core_base_address equ 0x00040000 ;常数,内核加载的起始内存地址
core_start_sector equ 0x00000001 ;常数,内核的起始逻辑扇区号
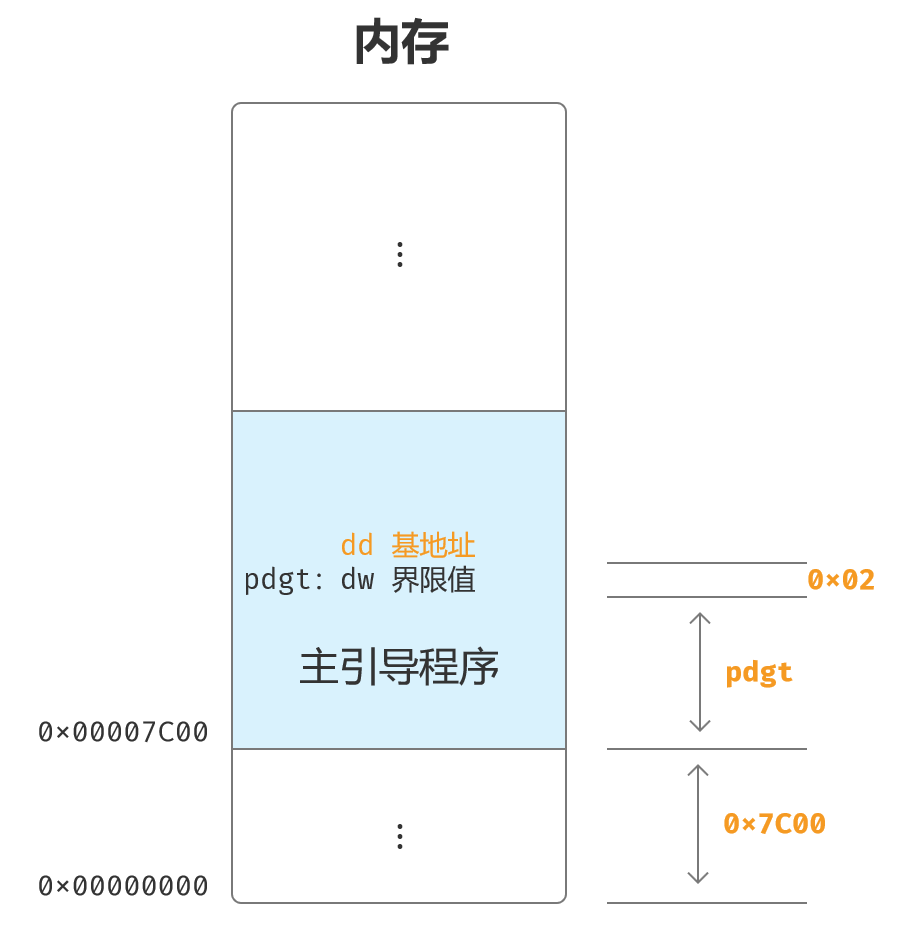
内存映像:后面就开始加载各种程序了,画一个内存映像就很清楚了。
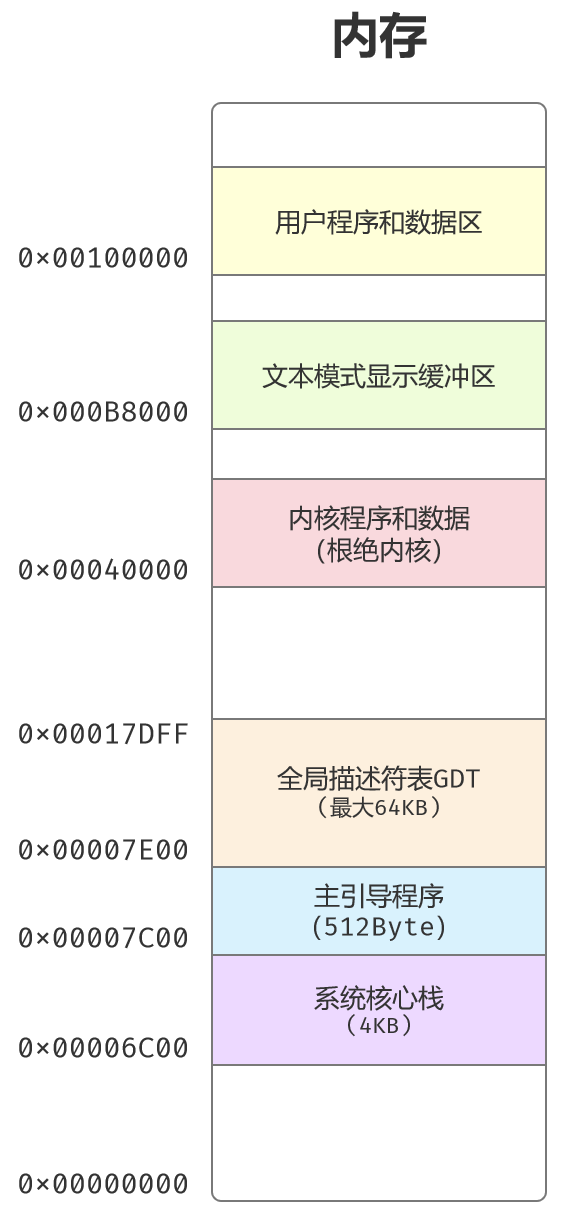
进入保护模式前的准备:基本和上一章节的类似,内存映像可以参考上图。
- 设置主引导程序加载位置是物理地址:0x00007C00。
- GDT的内存物理地址:0x00007E00 ~ 0x0017DFF,逻辑段地址:0x000007E0。
- 创建各段描述符:
- 数据段描述符,对应 0 ~ 4GB 的线性空间,方便访问全局数据。
- 代码段描述符,对应 0x7C00 ~ 0x7E00 ,即主引导扇区的空间。
- 栈段描述符,对应 0x6C00 ~ 0x7C00。
- 显示缓冲区描述符,对应 0xB8000 ~ 0xBFFFF 。
- 初始化GDTR:界限值为39(5*8-1),基地址为0x00007E00。
全局描述符表GDT内部结构如下图:

段之间的描述都是用是十六进制的数值,没有10进制直观。一开始感觉比较难,看多了就习惯了。
进入保护模式:和上一章节基本一样。
- 打开A20线。
- 设置PE位。
- 通过jmp跳转到flush开始执行,jmp会隐式设置代码段寄存器CS。
加载内核:
**1)**DS设置为 0~4GB 空间的数据段选择子0x08。
**2)**设置栈段为 0x6C00~0x7C00,即选择子0x18。
**3)**设置栈指针为0,栈指针范围:0xFFFFF000 <= (ESP的内容-操作数的长度) <= 0xFFFFFFFF。
- 压入一个字,ESP减2就是0xFFFFFFFE;
- =压入双字,ESP减4就是0xFFFFFFFC。
**4)**从硬盘把内核程序读入内存。
**4.1)**先读取第一个扇区,获取内核头部的基本信息,这样就能知道内核程序有多大。
;以下加载系统核心程序
mov edi,core_base_address ;内核在内存的基地址mov eax,core_start_sector ;内核在硬盘的扇区号
mov ebx,edi ;起始地址
call read_hard_disk_0 ;以下读取程序的起始部分(一个扇区)
读取硬盘的程序 read_hard_disk_0 和第9章的基本一样,有几个不同地方:
- 传入的参数逻辑扇区号(28位)不同。
- 本章只用一个EAX(32位)寄存器就可以了;
- 第9章还是用DI:SI两个寄存器;
- 传入的参数目标缓冲区偏移地址不同:
- 本章DS固定为0~4GB段的选择子,通过EBX(32位,可以指向4GB空间)偏移进行定位;
- 第9章是通过修改DS,偏移地址始终为0来实现的。
- 增加返回参数EBX为前值加上512,这个就是下一个扇区存储的内存偏移地址。
- 获取内核的长度,计算内核占用扇区数,读取剩余扇区。
**4.2)**取得内核的长度,并计算它所占用的扇区数。
这块的逻辑思路和第9章一样的。通过除以512,有余数就直接用eax,没有余数就减1,然后再验证是否只有1个扇区。
;以下判断整个程序有多大mov eax,[edi] ;ds是指向0~4GB空间,edi指向内核开始的内存地址xor edx,edx mov ecx,512 ;512字节每扇区div ecx ;eax存储商,edx存储余数。or edx,edx ;判断余数是否为0jnz @1 ;未除尽,因此结果比实际扇区数少1 dec eax ;已经读了一个扇区,扇区总数减1
@1:or eax,eax ;考虑实际长度≤512个字节的情况 jz setup ;EAX=0 ?
总扇区数的计算:
总扇区数 = 总字节数/512 的整数部分 + 总字节数/512的余数部分>0 ? 1 : 0= (EAX) + (EDX)>0 ? 1 : 0
因为前面已经读取了一个,所以剩余要读取的扇区数要减1,
剩余扇区数 = 总扇区数 - 1= (EAX) + (EDX)>0 ? 1 : 0 - 1
所以如果有余数,即EDX中的数大于0,那么EAX中存储的就是剩余的扇区数,否则EAX中的就要减1。
考虑实际长度小于512字节的情况:如果内核程序小于512字节,那么就不需要再加载了。
or eax,eax ;考虑实际长度≤512个字节的情况
jz setup ;EAX=0 ?
...
setup:...
**4.3)**读取硬盘剩余扇区。
;读取剩余的扇区mov ecx,eax ;eax就是剩余扇区数,32位模式下的LOOP使用ECXmov eax,core_start_sector ;开始扇区数inc eax ;从下一个逻辑扇区接着读
@2:call read_hard_disk_0inc eax ;从下一个逻辑扇区接着读loop @2 ;循环读,直到读完整个内核
安装内核的段描述符
内核程序加载到内存后,就要切换到内核继续运行。要切换到内核运行,就需要创建内核相关的段描述符。
加载全局描述符表寄存器(GDTR):
lgdt [cs:pgdt+0x7c00]
lgdt就是加载线性地址(0x00007e00)和段界限(39):
;初始化描述符表寄存器GDTR
mov word [cs: pgdt+0x7c00],39 ;描述符表的界限
...
...
pgdt dw 0dd 0x00007e00 ;GDT的物理地址
得到GDT的基地址:
mov esi,[0x7c00+pgdt+0x02] ;不可以在代码段内寻址pgdt;但可以通过4GB的段来访问
默认的段寄存器是DS,当这条指令执行时,处理器用DS描述符高速缓存器中的32位线性基地址0x00000000加上用该表达式计算出的偏移量来访问内存。
创建与内核相关的其他段描述符:此处需要读取内核头部数据,也要写入GDT表,书中代码是通过4GB数据段访问相关的数据。
**1)**建立公用例程段代码描述符:
;建立公用例程段描述符,默认数据段寄存器DS,esi为GDT的基地址,edi内核程序基地址
mov eax,[edi+0x04] ;公用例程代码段起始汇编地址
mov ebx,[edi+0x08] ;核心数据段汇编地址
sub ebx,eax ;公用例程段的长度
dec ebx ;长度减1就是公用例程段界限
add eax,edi ;公用例程段基地址
mov ecx,0x00409800 ;字节粒度的代码段描述符
call make_gdt_descriptor ;返回eax为描述符低32位,edx为高32位
mov [esi+0x28],eax ;写入GDT表,段描述符低32位
mov [esi+0x2c],edx ;写入GDT表,段描述符高32位
这边又edi,又esi的,画个内存图就容易看了。
这里提取了一个 make_gdt_descriptor 的过程,可以统一调用。过程我额外加了一些注释。这个过程并不难,主要是依据描述符的格式进行计算。
make_gdt_descriptor: ;构造描述符;输入:EAX=线性基地址; EBX=段界限; ECX=属性(各属性位都在原始; 位置,其它没用到的位置0) ;返回:EDX:EAX=完整的描述符mov edx,eax ;eax一会还要用到,用edx先保存一份shl eax,16 ;左移16位,即基地址的低16位移动到EAX的高16位or ax,bx ;段界限的低16位放到ax,描述符前32位(EAX)构造完毕and edx,0xffff0000 ;清除基地址中无关的位,只要高16位rol edx,8 ;左循环移动8位,基地址的31~24在edx的低8位、23~16位在edx的高8位bswap edx ;装配基址的31~24和23~16 (80486+)xor bx,bx ;保留段界限ebx的16~19位or edx,ebx ;装配段界限的高4位or edx,ecx ;装配属性ret
属性值ECX = 0x00409800的含义:P=1、D=1、G=0、DPL=0、S=1,TYPE=1000的(代码)段描述符。
这里有一个代码是xor bx,bx 是为了保留段界限ebx的16~19位,书中提高可以用如下方式处理更加合适。
and ebx, 0x000F0000
**2)**安装核心数据段描述符:有了前面的公共例程段描述符的安装过程,后续核心数据段和核心代码段都类似。
;建立核心数据段描述符
mov eax,[edi+0x08] ;核心数据段起始汇编地址
mov ebx,[edi+0x0c] ;核心代码段汇编地址
sub ebx,eax
dec ebx ;核心数据段界限
add eax,edi ;核心数据段基地址
mov ecx,0x00409200 ;字节粒度的数据段描述符
call make_gdt_descriptor
mov [esi+0x30],eax
mov [esi+0x34],edx
**3)**安装核心代码段描述符:
;建立核心代码段描述符
mov eax,[edi+0x0c] ;核心代码段起始汇编地址
mov ebx,[edi+0x00] ;程序总长度
sub ebx,eax
dec ebx ;核心代码段界限
add eax,edi ;核心代码段基地址
mov ecx,0x00409800 ;字节粒度的代码段描述符
call make_gdt_descriptor
mov [esi+0x38],eax
mov [esi+0x3c],edx
更新描述符标界限:创建核心各段描述符完成后,需要更新描述符表段界限。
mov word [0x7c00+pgdt],63 ;更新描述符表的界限,总8个。lgdt [0x7c00+pgdt] ;更新gdtr寄存器
这里是直接设置描述符表的总个数,当然也可以直接加上新增加的个数:
add word [0x7c00+pgdt],8*3 ;总共增加了3个描述符
内核加载完成后的GDT布局参考如下图:

跳转到内核执行:通过jmp跳转到内核处执行,会隐式修改代码段寄存器CS为内核代码段的选择子。
;mbr文件
jmp far [edi+0x10] ;edi内核基地址,0x10处为核心代码入口点。;core文件,入口点代码结构
core_entry dd start ;核心代码段入口点#10dw core_code_seg_sel ;选择子:0x38
在内核中执行
初始化段寄存器DS:初始化数据段寄存器DS,使它指向内核数据段。
mov ecx,core_data_seg_sel ;使ds指向核心数据段
mov ds,ecx
调用公共例程段内的put_string来显示字符串:
; 一个过程来显示字符串message_1
mov ebx,message_1
call sys_routine_seg_sel:put_string ;系统公共例程代码段的选择子:0x28
message_1在数据段中定义,其中:0x0d表示回车;0x0a 表示换行。
message_1 db ' If you seen this message,that means we 'db 'are now in protect mode,and the system 'db 'core is loaded,and the video display 'db 'routine works perfectly.',0x0d,0x0a,0
put_string过程和前面的类似,就是有一些不同:
- 用于显示0终止的字符串并移动光标,输入:DS:EBX=串地址。
- 使用retf调用,必须通过远过程调用的方法调用。
- 使用了新的指令pushad和popad指令:
- pushad:在32位操作尺寸下执行该指令时,处理器自动按顺序压入EAX、ECX、EDX、EBX、ESP(原始值)、EBP、ESI和EDI。
- popad:它将自动按相反的顺序弹出数据到上述寄存器。
- 访问显存时,不是将逻辑段地址传送到段寄存器,而是段选择子。
- movsb、movsw、movsd:16位DS:SI->ES:DI,32位DS:ESI->ES:EDI。32位操作尺寸时源目的分别是DS:ESI和ES:EDI。
获取处理器信息:cpuid指令(CPU Identification)用于返回处理器的标识和特性信息。
- 传递参数:寄存器EAX用于指定要返回什么样的信息,也就是功能。有时候,还要用到寄存器ECX。
- 返回信息:cpuid指令执行后,处理器将返回的信息放在寄存器EAX、EBX、ECX或者EDX中。
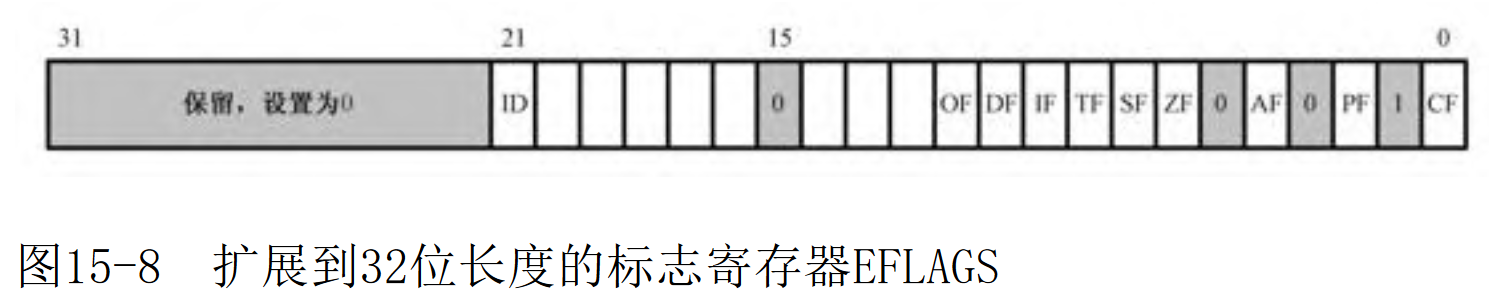
检查处理器是否支持cpuid指令:EFLAGS寄存器ID标志位(位21)如果为“0”,则不支持cpuid指令。
探测处理器最大支持的功能号:为了探测处理器最大能够支持的功能号,应该先用0号功能来执行cpuid指令:
mov eax,0 ;探测处理器最大能够支持的功能号。
cpuid
;cpuid返回信息说明
; 处理器执行后,将在寄存器EAX返回最大可以支持的功能号。
; 还在寄存器EBX、ECX和EDX中返回处理器供应商的信息。
; EBX <- 0x756E6547(对应字符出“Genu",“G"在BL中,其他类推)
; EDX <- 0x49656E69(对应字符串“ineI",“í”在DL中,其他类推)
; ECX <- 0x6C65746E(对应字符串“nte1",“n”在CL中,其他类推)
获取处理器品牌信息:要返回处理器的品牌信息,需要使用0x80000002~0x80000004号功能,分三次进行。该功能仅被奔腾4(Pentium 4)之后的处理器支持,所以,正确的做法是先用0号功能执行cpuid指令,以判断自己的处理器是否支持。
;显示处理器品牌信息
mov eax,0x80000002
cpuid
mov [cpu_brand + 0x00],eax
mov [cpu_brand + 0x04],ebx
mov [cpu_brand + 0x08],ecx
mov [cpu_brand + 0x0c],edxmov eax,0x80000003
cpuid
mov [cpu_brand + 0x10],eax
mov [cpu_brand + 0x14],ebx
mov [cpu_brand + 0x18],ecx
mov [cpu_brand + 0x1c],edxmov eax,0x80000004
cpuid
mov [cpu_brand + 0x20],eax
mov [cpu_brand + 0x24],ebx
mov [cpu_brand + 0x28],ecx
mov [cpu_brand + 0x2c],edx
cpu_brand在核心数据段中定义:
cpu_brand times 49 db 0 ;定义49字节的缓冲区存储cpu品牌信息
为什么定义成49?
是因为写入品牌信息总共0x2c+0x04=0x30,位十进制的48,刚好余下最后一个为0,表结束。
显示处理器信息:调用put_string公共例程显示获取到的处理器信息。
mov ebx,cpu_brnd0
call sys_routine_seg_sel:put_string
mov ebx,cpu_brand
call sys_routine_seg_sel:put_string
mov ebx,cpu_brnd1
call sys_routine_seg_sel:put_string
用户程序的加载和重定位
显示提示信息:先显示一段信息,说明要加载用户程序了。
mov ebx,message_5
call sys_routine_seg_sel:put_string
message_5在核心数据段定义:
message_5 db ' Loading user program...',0
声明用户程序起始逻辑扇区:执行用户程序,需要先从硬盘加载到内存上,读取内存需要知道逻辑扇区。
mov esi,50 ;用户程序位于逻辑50扇区
call load_relocate_program
书中代码是直接在程序里写死50,最好将这个50放到程序起始处,并且用伪指令equ声明称常数,方便后续修改。
此处声明了一个过程 load_relocate_program 用来加载用户程序。因为内核的主要任务就是加载和执行用户程序。多任务系统必须要创建多个任务,所以这样的工作会反复进行。为了方便,一般要定义成过程,后续可以反复调用。
用户程序的结构
用户程序必须符合规定的格式,才能被内核识别和加载。通常情况下,流行的操作系统会规定自己的可执行文件格式。
文件头:所有操作系统的可执行文件都包括文件头,这也是一贯的做法。文件头定义了程序总长度、头部的长度、程序入口、代码段位置和长度、数据段位置和长度、栈段位置和长度、符号地址检索表。
符号地址检索表,咋一看有点迷糊,实际上就是通过过程的检索表。简单说,这些过程要指向内核相应的通用过程,然后这些过程可以给用户程序调用。
SECTION header vstart=0program_length dd program_end ;程序总长度#0x00head_len dd header_end ;程序头部的长度#0x04prgentry dd start ;程序入口#0x08code_seg dd section.code.start ;代码段位置#0x0ccode_len dd code_end ;代码段长度#0x10data_seg dd section.data.start ;数据段位置#0x14data_len dd data_end ;数据段长度#0x18stack_seg dd section.stack.start ;栈段位置#0x1cstack_len dd stack_end ;栈段长度#0x20......header_end:
符号地址检索表(Symbol-Address Lookup Table):除了加载和重定位用户程序,内核还应当提供一些例程供用户程序调用。操作系统提供的是应用程序编程接口(Application Programming Interface, API),这是一大堆例程(过程),需要的时候直接调用即可。
调用的方法:
- 早的系统中,中断号的方法;
- 使用符号名,例如:PrintString。
书中采用的是符号名的方式:
;符号地址检索表
salt_items dd (header_end-salt)/256 ;#0x24,表示数量salt: ;#0x28,每个标号占用256字节PrintString db '@PrintString' ;打印字符串times 256-($-PrintString) db 0TerminateProgram db '@TerminateProgram' ;中断应用程序times 256-($-TerminateProgram) db 0ReadDiskData db '@ReadDiskData' ;读取硬盘数据times 256-($-ReadDiskData) db 0
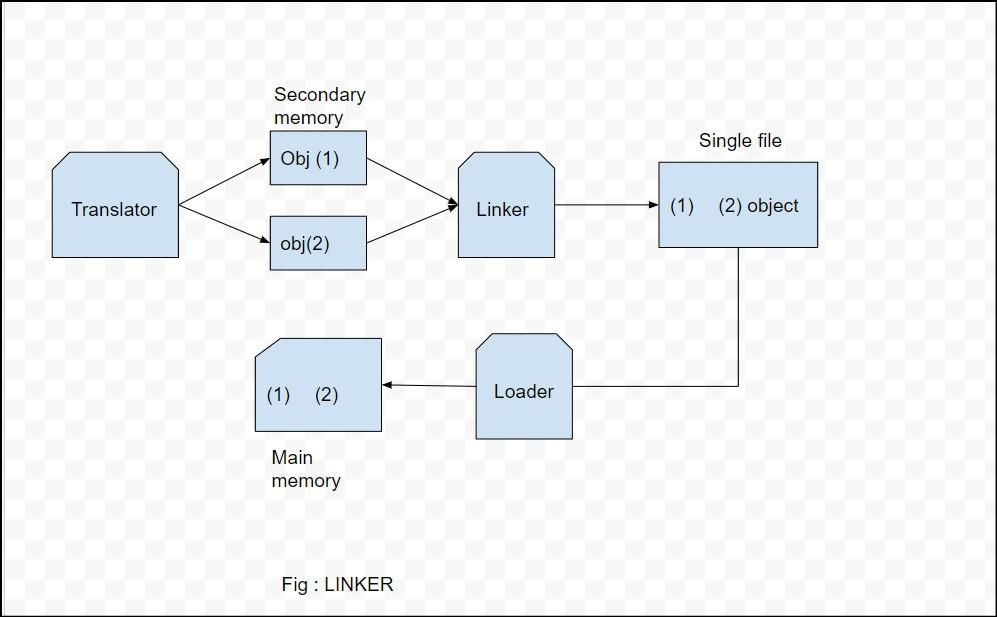
符号地址检索表并不是通用的东西,是作者自行构造方便执行系统调用,主要是不想弄的太复杂。对于大多数汇编语言,也不需要亲自构造文件头,那是链接器(Linker)的工作。
关于链接器(Linker),我查了一些资料,简单的理解就是链接器可以把若干个编译后的文件链接在一起形成一个文件(exe、lib、dll),加载器可以加载或执行,参考下图:
计算用户程序占用的扇区数
书中封装了一个过程 load_relocate_program 来加载用户程序,现在进入这个方法。
切换到内核数据段:这个容易理解,现在在内核中执行,切换到内核数据段方便操作内核数据。
mov eax,core_data_seg_sel
mov ds,eax ;切换DS到内核数据段
预读第一个扇区:预读第一个扇区,获取用户程序头部的信息,知道整个应用程序有多大。
mov eax,esi ;读取程序头部数据,esi逻辑扇区号
mov ebx,core_buf ;将读取的内容存储到core_buf缓冲区
call sys_routine_seg_sel:read_hard_disk_0 ;调用公共例程的读取磁盘的方法
core_buf的定义:
core_buf times 2048 db 0 ;内核用的缓冲区
通过一块内核缓冲区,分析、加工和中转数据都比较方便。
计算用户程序大小:前面读取到了用户程序大小,就可以计算用户程序占用的大小,然后申请对应的内存,因为一次读取512个字节,这里要对程序大小要做512字节对齐。
;以下判断整个程序有多大
mov eax,[core_buf] ;程序尺寸,用户程序0x00~0x03保存了程序大小
mov ebx,eax ;使用ebx存储程序大小512字节对齐的结果
and ebx,0xfffffe00 ;使之512字节对齐(能被512整除的数,低9位都为0)
add ebx,512 ;多加512字节,如果程序的大小不能被512整除,就用ebx
test eax,0x000001ff ;程序的大小正好是512的倍数吗?
cmovnz eax,ebx ;不是。使用凑整的结果
为什么能被512整除的数,低9位都为0?
因为2^9=512,要被512整除,后面9个只能是0,不然就会有余数。
其中cmovnz是条件转移指令,表示不为0则传送,类似的还有cmovz、cmove等。使用条件转移指令可以让程序更加易读,不会再程序里有多个分支。
cmovz ax,cx ;为0则传送
cmovnz eax,[0x2000] ;不为0则传送
cmove ebx,ecx ;相等则传送
cmovng cx,[0x1000] ;不大于则传送
cmovl edx,ecx ;小于则传送
条件传送指令和条件跳转指令很类似,可以将条件跳转指令的首字母“j”换成“cmov”即可。
简单的动态内存分配
知道用户程序大小了,那么就可以分配对应的内存空间了。对于操作系统来说,内存的分配、回收和硬盘交换管理等是常规的工作。
分配内存:
mov ecx,eax ;实际需要申请的内存数量,字节数
call sys_routine_seg_sel:allocate_memory ;调用分配内存的例程
书中封装了 allocate_memory 例程用于分配内存。
allocate_memory: ;分配内存;输入:ECX=希望分配的字节数;输出:ECX=起始线性地址 push dspush eaxpush ebxmov eax,core_data_seg_sel ;内核数据段选择子mov ds,eaxmov eax,[ram_alloc] ;ram_alloc初始值为0x00100000add eax,ecx ;加上对应字节数,就是下一次分配时的起始地址; 也可以理解为当前分配的结束地址;这里应当有检测可用内存数量的指令mov ecx,[ram_alloc] ;返回当前分配的起始地址mov ebx,eax ;eax要4字节对齐and ebx,0xfffffffcadd ebx,4 ;强制对齐 test eax,0x00000003 ;下次分配的起始地址最好是4字节对齐cmovnz eax,ebx ;如果没有对齐,则强制对齐 mov [ram_alloc],eax ;下次从该地址分配内存;cmovcc指令可以避免控制转移 pop ebxpop eaxpop dsretf
画个图:
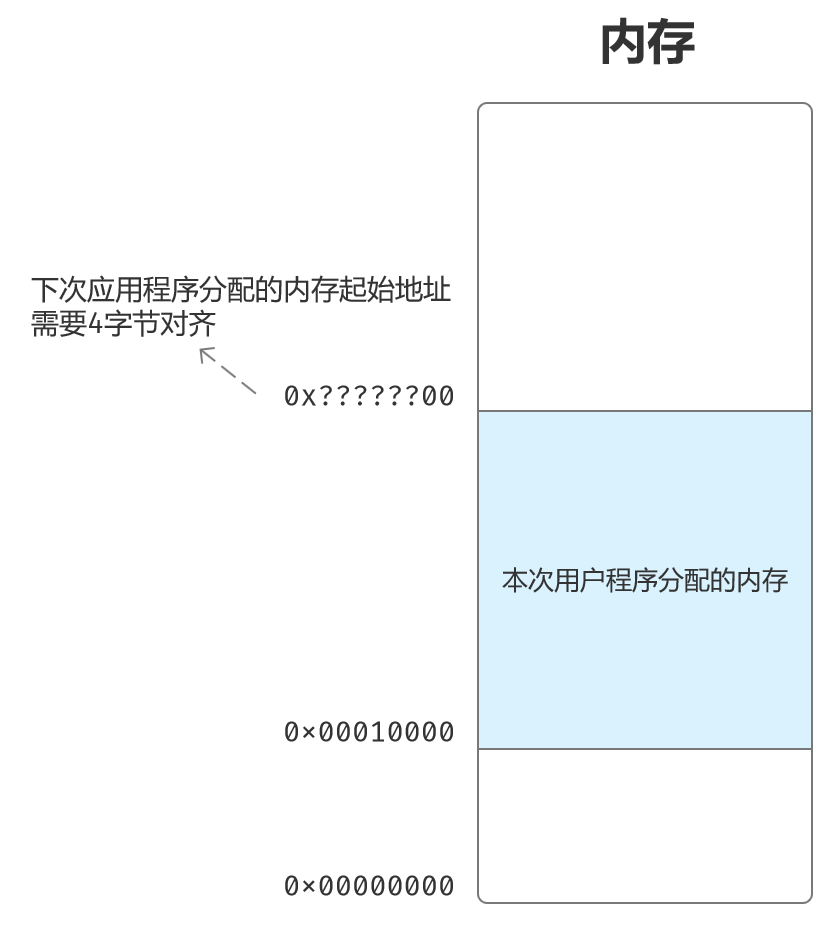
段的重定位和描述符的创建
保存申请到的内存首地址:后续创建描述符还需要用到这个首地址,所以先保存到栈里。
mov ebx,ecx ;ebx -> 申请到的内存首地址
push ebx ;保存该首地址
计算用户程序的总扇区数:eax已经512字节对齐了,直接除512就可以得到扇区数量,这里实现会比前面跳转来跳转去简单多了。
xor edx,edx
mov ecx,512
div ecx ;eax 512字节对齐了,eax保留商
mov ecx,eax ;总扇区数,传送到ecx,控制后面读取循环
将用户程序从硬盘加载到申请都的内存空间:从硬盘逐个扇区循环加载到内存中。
mov eax,mem_0_4_gb_seg_sel ;切换DS到0-4GB的段
mov ds,eax ;要加载到内存,不能用内核的数据段了mov eax,esi ;起始扇区号,传递的参数指定了。
.b1: ;循环读取硬盘数据call sys_routine_seg_sel:read_hard_disk_0 ;ds:ebx决定内存地址inc eaxloop .b1
创建头部段描述符:用户程序全部载入内存后,现在的任务就是根据它的头部信息来创建段描述符。
;建立程序头部段描述符
pop edi ;恢复程序装载的首地址
mov eax,edi ;程序头部起始线性地址
mov ebx,[edi+0x04] ;段长度
dec ebx ;段界限
mov ecx,0x00409200 ;字节粒度的数据段描述符
call sys_routine_seg_sel:make_seg_descriptor ;生成段描述符,存储在EDX:EAX
call sys_routine_seg_sel:set_up_gdt_descriptor ;安装段描述符,参数EDX:EAX,返回CX选择子
mov [edi+0x04],cx ;更新用户程序头部段的选择子
其中 make_seg_descriptor 过程前面mbr代码已经说明过了。
set_up_gdt_descriptor 过程:参数 EDX:EAX 描述符;返回:寄存器CX 选择子。
代码我额外增加了一些注释。
set_up_gdt_descriptor: ;在GDT内安装一个新的描述符;输入:EDX:EAX=描述符 ;输出:CX=描述符的选择子push eaxpush ebxpush edxpush dspush esmov ebx,core_data_seg_sel ;切换到核心数据段mov ds,ebxsgdt [pgdt] ;获取GDT物理地址和大小mov ebx,mem_0_4_gb_seg_sel ;es指向0~4GB数据段mov es,ebxmovzx ebx,word [pgdt] ;GDT界限,pgdt标号前两个字节(0~1字节)存储界限 inc bx ;GDT总字节数,也是下一个描述符偏移 add ebx,[pgdt+2] ;基地址+偏移地址,就是下一个描述符的线性地址 mov [es:ebx],eax ;es:ebx指向要安装的描述符的线性地址,低32位保存eax mov [es:ebx+4],edx ;es:ebx指向要安装的描述符的线性地址,高32位保存edxadd word [pgdt],8 ;增加一个描述符的大小 lgdt [pgdt] ;对GDT的更改生效 mov ax,[pgdt] ;下面几行计算选择子,通过界限进行计算xor dx,dxmov bx,8div bx ;除以8,去掉余数,ax保存的就是选择子索引号mov cx,ax ;ax赋值给cxshl cx,3 ;将索引号移到正确位置 pop espop dspop edxpop ebxpop eaxretf
为什么其中计算GDT的总字节数是inc bx,而不是inc ebx?
答:计算机刚启动时,GDTR中的基地址为0x00000000,界限为0xFFFF。
界限为0xFFFF时,表明GDT中还没有描述符。ebx中此时存储的时=0xFFFF,
- 如果使用ebx,那么0xFFFF+1=0x10000,显示不合理。
- 如果使用bx,那么0xFFFF+1=0x0000,超出的位数被舍弃。即第一个描述符应该从0开始。
movzx:带零扩展的传送(Move with Zero-Extend),指令格式为:
movzx r16,r/m8
movzx r32,r/m8
movzx r32,r/m16
例如:
movzx cx,al ;(al)=0xC0, (cx)=0x00C0
movzx eax,byte [0x2000] ;(eax)=0x24个0+[0x2000]处一个字节。
movzx ecx,bx ; (bx)=0x55AA, (ecx)=0x000055AA
movsx:带符号扩展的传送(Move with Sign-Extension),指令格式为:
movsx r16,r/m8
movsx r32,r/m8
movsx r32,r/m16
例如:
mov al,0x08
movsx cx,al ;(cx)=0x0008, al最高位为0
mov al,0xf5
movsx ecx,al ;(ecx)=0xFFFFFFF5, al最高位为1
后续的代码段、数据段、栈段都是类似的。
创建代码段描述符:
;建立程序代码段描述符
mov eax,edi
add eax,[edi+0x0c] ;代码起始线性地址
mov ebx,[edi+0x10] ;段长度
dec ebx ;段界限
mov ecx,0x00409800 ;字节粒度的代码段描述符
call sys_routine_seg_sel:make_seg_descriptor
call sys_routine_seg_sel:set_up_gdt_descriptor
mov [edi+0x0c],cx ;更新用户程序代码段的选择子
创建数据段描述符:
;建立程序数据段描述符
mov eax,edi
add eax,[edi+0x14] ;数据段起始线性地址
mov ebx,[edi+0x18] ;段长度
dec ebx ;段界限
mov ecx,0x00409200 ;字节粒度的数据段描述符
call sys_routine_seg_sel:make_seg_descriptor
call sys_routine_seg_sel:set_up_gdt_descriptor
mov [edi+0x14],cx ;更新用户程序数据段的选择子
创建栈段描述符:
;建立程序堆栈段描述符
mov eax,edi
add eax,[edi+0x1c] ;数据段起始线性地址
mov ebx,[edi+0x20] ;段长度
dec ebx ;段界限
mov ecx,0x00409200 ;字节粒度的数据段描述符
call sys_routine_seg_sel:make_seg_descriptor
call sys_routine_seg_sel:set_up_gdt_descriptor
mov [edi+0x1c],cx ;更新用户程序栈段的选择子
重定位用户程序内的符号地址
重定位含义:重定位用户程序内的符号地址,其实就是把内核公共例程的调用地址写入到用户程序的符号表内,这样用户程序就可以执行内核的公共例程了。
参考下图:
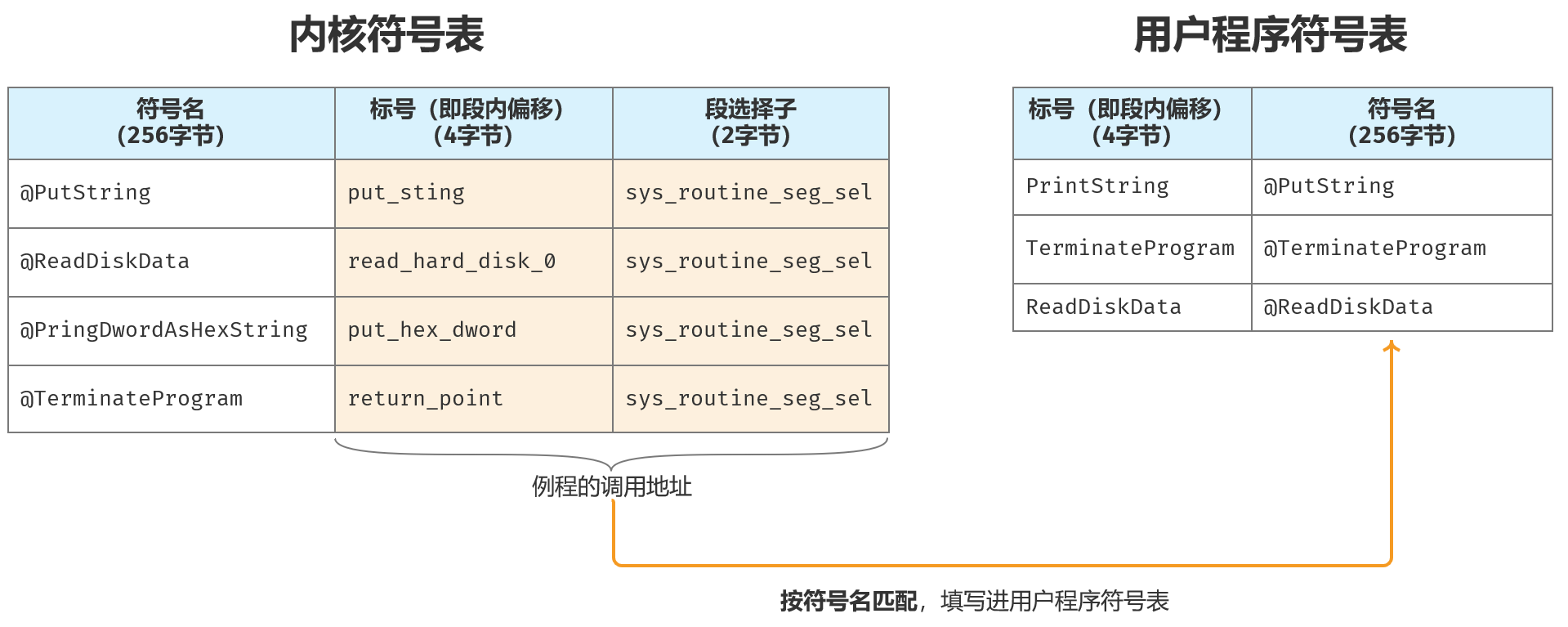
实现的思路:代码有点难理解,但是实现的思路很简单,就是两层循环,从高级语言角度来代码大概如下。
for (uSaltItem in uSaltItems) { // 第一层循环,遍历用户程序符号表for (cSaltItem in cSaltItems) { // 第二层循环,遍历内核符号表// 找到内核符号表中和用户程序符号名一致的// 将段内偏移和段选择子写入到用户程序符号表}
}
汇编语言并没有 item 的概念,所以是通过偏移地址指向下一个项目的,类似如下:
for(u-offset=0; u-offset<=max; u-offset+=256) { // 每次+256指向下一个用户程序符号for(c-offset=0; c-offset<=max; c-offset+=262) { // 每次+262指向下一个内核符号// 找到内核符号表中和用户程序符号名一致的// 将段内偏移和段选择子写入到用户程序符号表}
}
理解这个,看代码就更加容易理解一些了,代码我标注了下层次结构,更加清晰一些。

另外代码我额外加了一些注释:
;重定位SALTmov eax,[edi+0x04]mov es,eax ;es -> 用户程序头部mov eax,core_data_seg_selmov ds,eax ;ds -> 内核数据段cldmov ecx,[es:0x24] ;用户程序的SALT条目数mov edi,0x28 ;用户程序内的SALT位于头部内0x28处
.b2:push ecx ;内层循环还需要用到ecx,这里要暂存一下push edimov ecx,salt_items ;内核的符号表总数mov esi,salt ;esi指向内核符号表首个符号起始地址.b3:push edipush esipush ecxmov ecx,64 ;检索表中,每条目的比较次数,每次比较4字节,比较64次即可repe cmpsd ;每次比较4字节 core_data_seg_sel:salt 和 app中的header:0x28比较jnz .b4 ;不为0,表示不一致,跳转到.b4位置处mov eax,[esi] ;若匹配,esi恰好指向当前符号的段内偏移地址mov [es:edi-256],eax ;将用户程序的字符串前4个字节(0~3)改写成偏移地址mov ax,[esi+4] ;esi+4就是内核符号段选择子的地址mov [es:edi-252],ax ;将用户程序的字符串第5、6个字节(4~5)改写成段选择子.b4:pop ecxpop esiadd esi,salt_item_len ;esi指向下一个内核下一个符号pop edi ;edi恢复到用户符号表首个符号起始地址,从头比较loop .b3pop ediadd edi,256 ;edi指向用户程序符号表下一个符号pop ecxloop .b2
书中也给出了比较的过程:
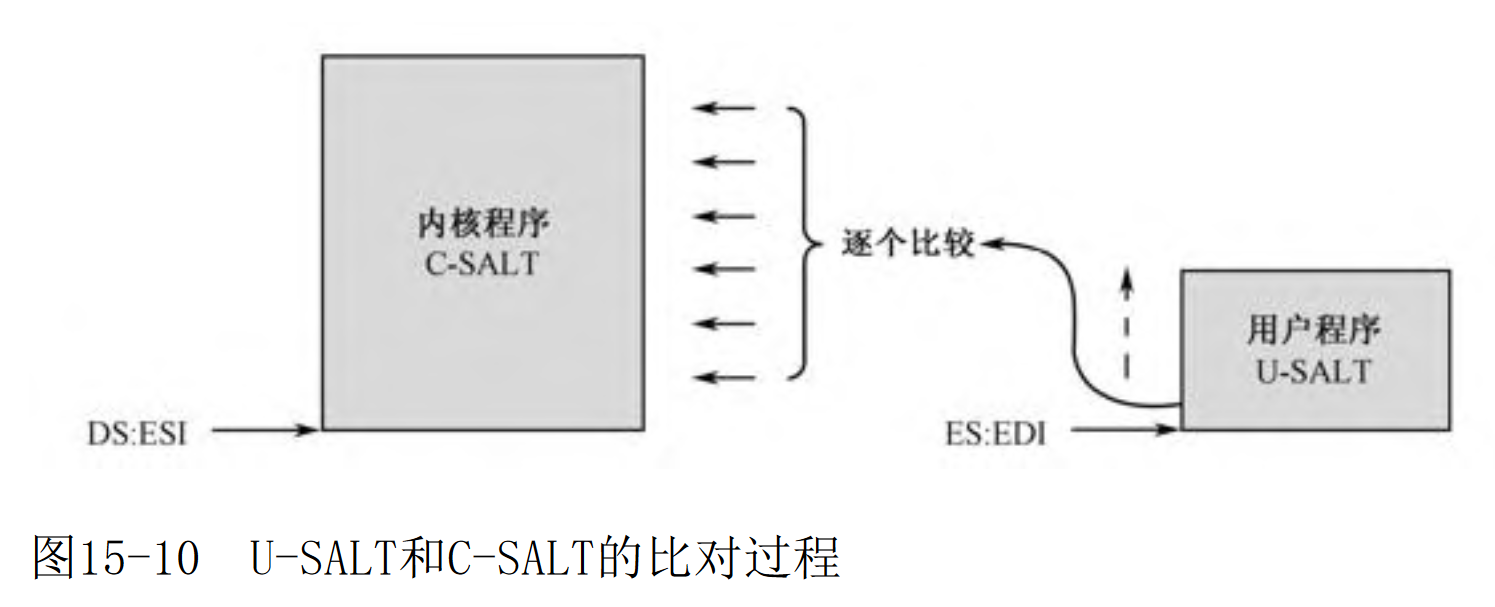
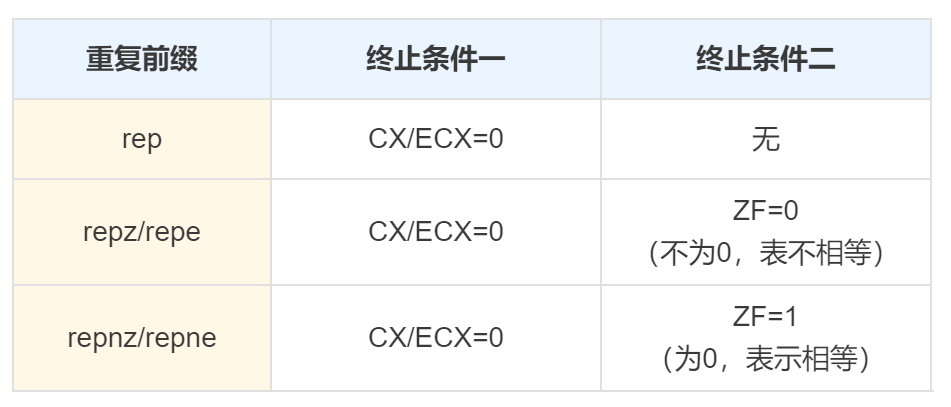
新指令 cmps(Compare String Operands):用于比较字符串是否相同。cmps指令有3种基本的形式,分别用于字节、字和双字的比较:
- comsb:字节比较
- comsw:字比较
- comsd:双子比较
需要结合 rep、repe(repz)、reqne(reqnz) 一起使用。
- rep:重复直到 CX(ECX) 为0
- repe(repz):重复直到 CX(ECX) 为0 或者 比较的内容不相等(ZF=0),该指令用于搜索第一个不匹配的。
- repne(repnz):重复直到 CX(ECX) 为0 或者 比较的内容相等(ZF=1),该指令用于搜索第一个匹配的。
例如:
;比较 SI(ESI) 和 DI(EDI) 处的一个字节的值。
;比较一次后 SI(ESI) 和 DI(EDI) 加1。
;如果 CX(ECX) 为0,则停止
rep comsb ;比较1个字节的值, 每次比较后 SI(ESI) 和 DI(EDI) 加1。
rep comsw ;比较2个字节的值, 每次比较后 SI(ESI) 和 DI(EDI) 加2。
rep comsd ;比较4个字节的值,每次比较后 SI(ESI) 和 DI(EDI) 加4。
重复前缀的含义:
执行用户程序
内核部分:在load_relocate_program过程的最后,把用户程序头部段的选择子传送到寄存器AX,作为返回。
mov ax,[es:0x04]
;用户头部段如下,在前面已经被替换为了用户程序头部的选择子
; head_len dd header_end ;程序头部的长度#0x04
从load_relocate_program过程返回后,显示Done信息:
mov ebx,do_status
call sys_routine_seg_sel:put_string
;do_status在内核数据段定义好了
; do_status db 'Done.',0x0d,0x0a,0
在进入用户程序后,用户程序应当切换到它自己的栈。所以临时保存内核的栈指针:
mov [esp_pointer],esp ;临时保存内核堆栈指针
;标号esp_pointer在内核数据段定义好了。双字(4个字节)
; esp_pointer dd 0 ;内核用来临时保存自己的栈指针
从用户程序返回时,还要从这个内存位置还原内核栈指针。
现在要跳转到用户程序执行,那么需要使段寄存器DS指向用户程序头部,然后使用远转移跳转到用户程序0x08开始处实现:
mov ds,ax ;数据段DS修改为用户程序头部选择子。
jmp far [0x08] ;用户程序0x08存储了用户程序起始地址。;用户程序内堆栈可能切换
;用户程序0x08位置的数据:
; prgentry dd start ;程序入口#0x08,即段内偏移
; code_seg dd section.code.start ;代码段位置#0x0c,存储了代码段选择子
我第一遍阅读的时候,感觉还是蛮难理解的,之所以难理解就是因为所有的程序都共用那么些寄存器,执行到哪里,寄存器保存了什么值,都要非常清楚,不然就是懵逼。
用户程序部分:因为用户程序后续要使用到DS段寄存器,而DS段寄存器此时指向的是头部,所以把DS段寄存器的值用FS进行保存。
mov eax,ds ;DS指向头部,用fs来指向头部,ds另作它用
mov fs,eax
设置用户程序栈段:
mov ss,[fs:stack_seg] ;fs指向头部段,栈段选择子
mov esp,stack_end ;栈指针指向栈段结束处,栈是向下的。
设置用户数据段:
mov ds:[fs:data_seg] ;fs指向头部段,数据段选择子
调用内核PrintString例程打印字符串:
mov ebx,message_1
call far [fs:PrintString] ;调用PrintString打印字符串
messag_1定义如下:
message_1 db 0x0d,0x0a,0x0d,0x0adb '**********User program is runing**********'db 0x0d,0x0a,0
读取用户程序一个逻辑扇区:
mov eax,100 ;逻辑扇区号100
mov ebx,buffer ;缓冲区偏移地址
call far [fs:ReadDiskData] ;段间调用
打印消息2:
mov ebx,message_2
call far [fs:PrintString]
;消息2定义:
; message_2 db ' Disk data:',0x0d,0x0a,0
打印buffer的内容:
mov ebx,buffer
call far [fs:PrintString]
将控制权返回到系统:
jmp far [fs:TerminateProgram] ;将控制权返回到系统
回到内核部分:
数据段重新指向内核数据段:
mov eax,core_data_seg_sel ;使ds指向核心数据段
mov ds,eax
切回内核自己的堆栈:
mov eax,core_stack_seg_sel ;切换回内核自己的堆栈
mov ss,eax
mov esp,[esp_pointer]
打印消息:
mov ebx,message_6
call sys_routine_seg_sel:put_string
; message_6定义如下:
; message_6 db 0x0d,0x0a,0x0d,0x0a,0x0d,0x0a
; db ' User program terminated,control returned.',0
进入停机状态:
hlt
对于一个操作系统来说,下面的任务是回收前一个用户程序所占用的内存,并启动下一个用户程序。
代码的编译、运行和调试
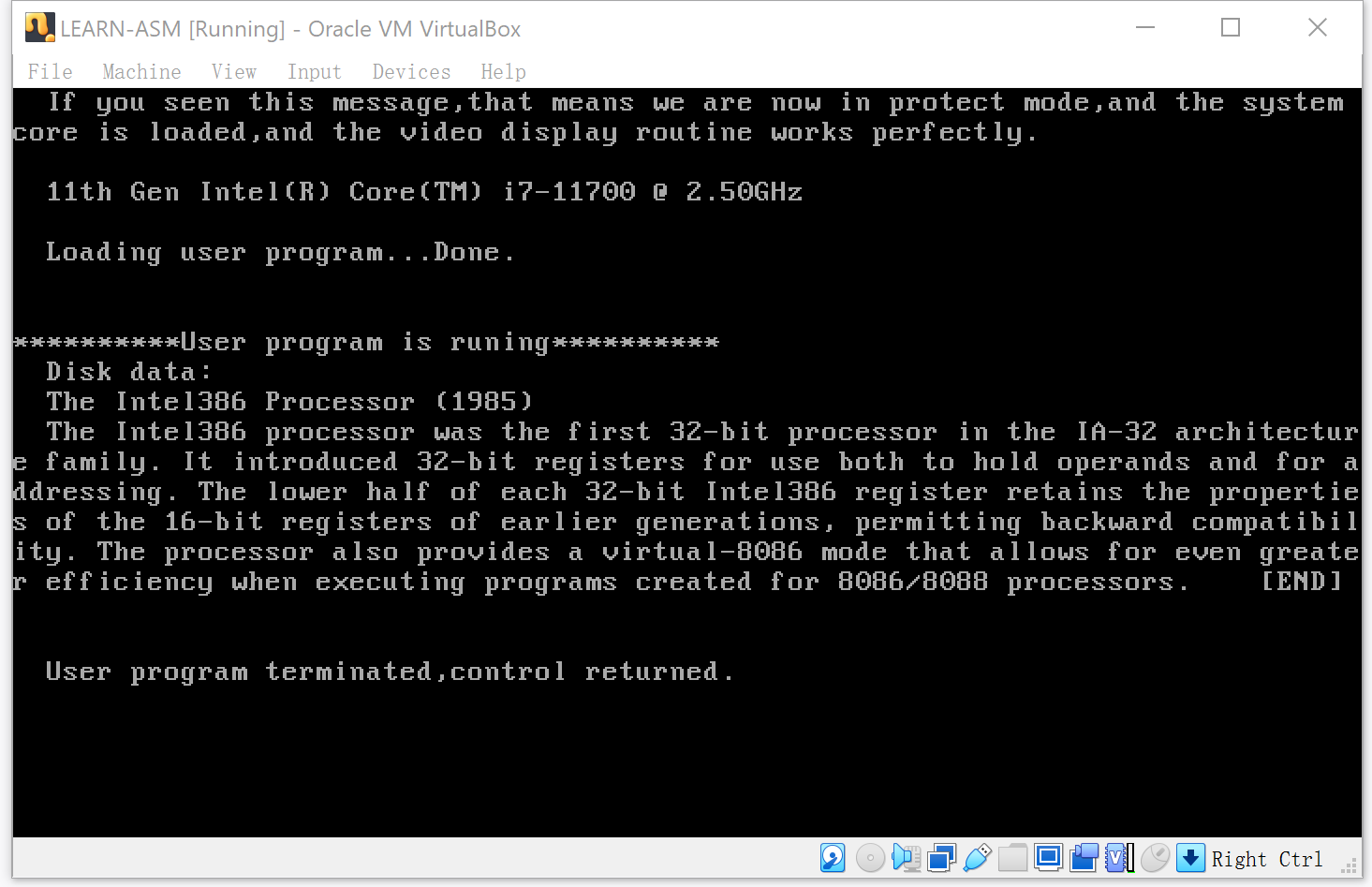
一开始没有写入diskdata.txt数据,实际运行结果:
出现问题的原因是需要将diskdata.txt文本文件写入到100扇区。重新运行后才能读取到100扇区的内容。
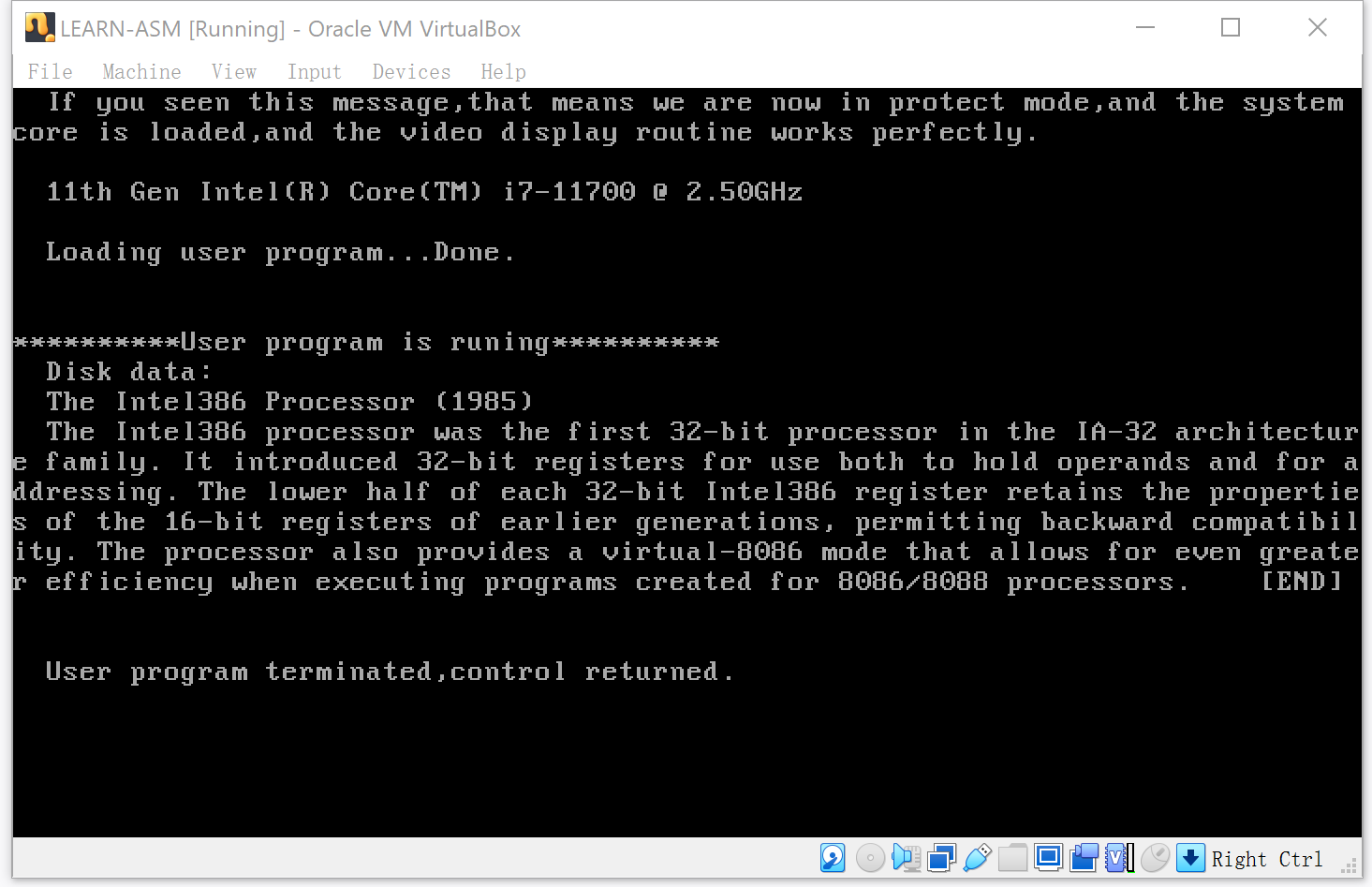
完