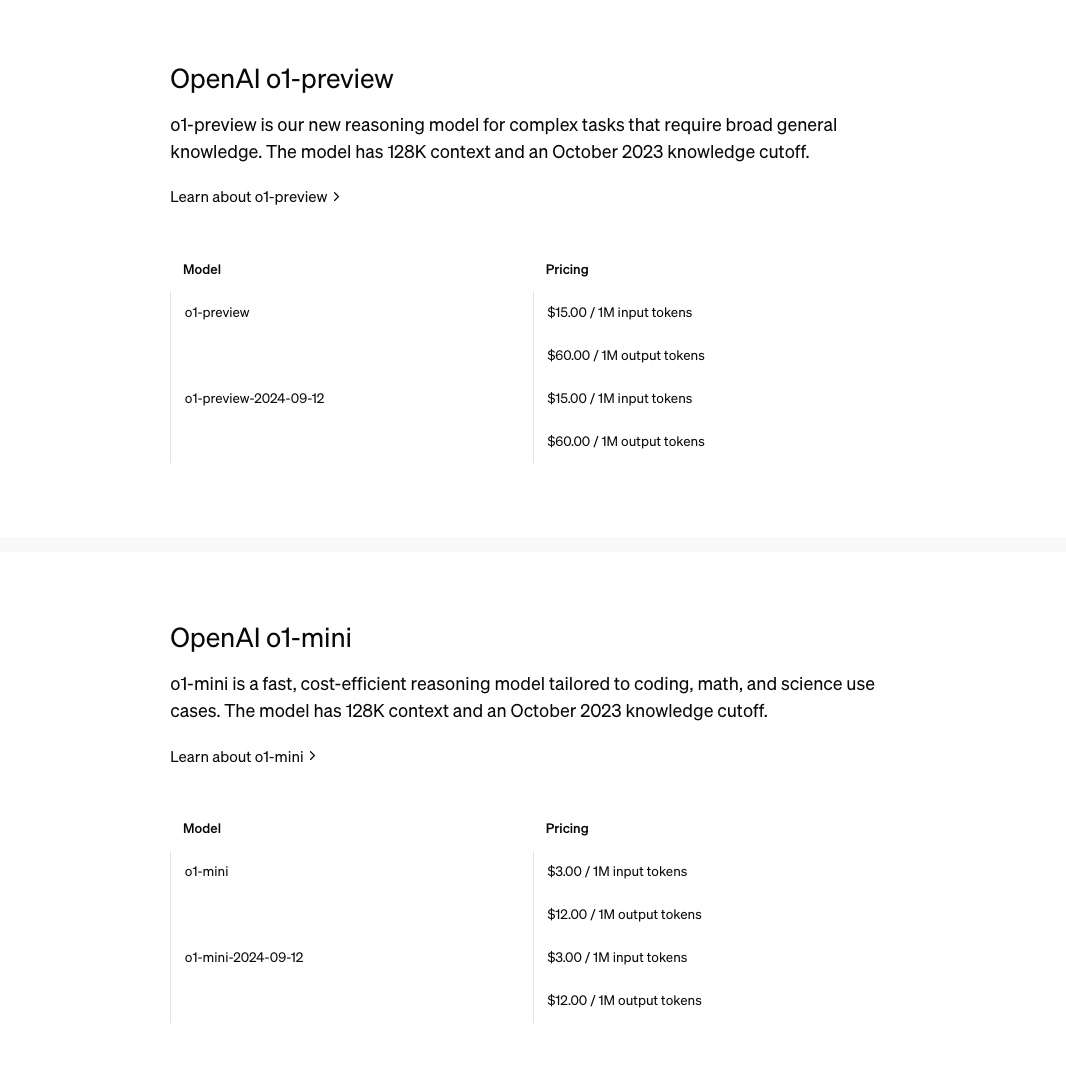
文章目录
- 1. 概念
- 1. 1 队列底层结构选型
- 1. 2 队列定义
- 2. 接口实现
- 2. 1 初始化
- 2. 2 判空
- 2. 3 入队列
- 2. 4 出队列
- 2. 5 队尾元素和队头元素和队列元素个数
- 2. 6 销毁
- 2. 7 接口的意义
- 3. 经典OJ题
- 3. 1 用队列实现栈
- 3. 1. 1 栈的定义
- 3. 1. 2 栈的初始化
- 3. 1. 3 入栈
- 3. 1. 4 出栈
- 3. 1. 5 取栈顶元素
- 3. 1. 6 判空
- 3. 1. 7 销毁
1. 概念
概念:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出FlFO(First In First Out)的特点。
入队列:进行插入操作的一端称为队尾。
出队列:进行删除操作的一端称为队头。

1. 1 队列底层结构选型
和栈一样,队列也可以数组和链表的结构实现,但是使用链表的结构实现更优一些,因为队列需要在队头出数据,如果使用数组的结构,出队列就是在数组头上出数据,效率会比较低。
1. 2 队列定义
既然使用链表实现队列,那么栈就应该有两个自定义结构,一个是节点结构体,一个是整个队列的结构体。
//队列节点
typedef int QDataType;
typedef struct QListNode
{struct QListNode* next;QDataType data;
}QNode;// 队列的结构
typedef struct Queue
{QNode* head;QNode* tail;int size;
}Queue;
队列节点和普通的单链表节点是一样的,而队列的结构中,需要保存队列的头和尾,方便进行出队列和入队列,除此之外还要保存队列中元素的个数。
2. 接口实现
2. 1 初始化
void QueueInit(Queue* q);
我们依然采用先在main函数中创建队列,再在初始化函数中进行初始化处理的方式,原因已经在栈的实现讲解过了。
对一个Queue类型的结构体进行初始化,就是将所有的元素置为NULL或0就可以了。
void QueueInit(Queue* q)
{assert(q);q->head = NULL;q->tail = NULL;q->size = 0;
}
2. 2 判空
判断队列是不是为空,接下来的几个函数会用到这个接口。
只需要判断头节点或者尾节点是否为空就可以了。
int QueueEmpty(Queue* q)
{assert(q);return q->head == NULL;
}
2. 3 入队列
入队列是在队尾入队列,有以下几个步骤:
- 申请新节点。
- 将其接到原来的尾节点的后面,并将尾节点指向新节点。
size++
void QueuePush(Queue* q, QDataType data)
{assert(q);//1. 申请新节点QNode* newnode = (QNode*)malloc(sizeof(QNode));if (!newnode){perror("malloc");exit(1);}newnode->data = data;//next记得置空newnode->next = NULL;//2. 插入节点if (!QueueEmpty(q)){q->tail->next = newnode;q->tail = q->tail->next;}//如果队列为空,要让头结点和尾节点都指向新节点elseq->tail = q->head = newnode;//3. size++q->size++;
}
2. 4 出队列
void QueuePop(Queue* q);
从队头出队列,有以下几个步骤:
- 对链表进行前删,并修改
head和tail的指向 size--
void QueuePop(Queue* q)
{assert(q);//出队列时要判空,如果为空,就非法assert(!QueueEmpty(q));//1. 链表前删//将头节点的下一个节点保存起来,作为新的头节点QNode* next = q->head->next;free(q->head);//如果原本队列中只有一个元素,那么出队列后tail就指向的是一个野指针了,要置为空if (q->size == 1)q->tail = NULL;q->head = next;//2. size--q->size--;
}
2. 5 队尾元素和队头元素和队列元素个数
// 获取队列头部元素
QDataType QueueFront(Queue* q);
// 获取队列队尾元素
QDataType QueueBack(Queue* q);
// 获取队列中有效元素个数
int QueueSize(Queue* q);
直接返回就可以了,不过要注意判空,否则会发生空指针的解引用。
QDataType QueueFront(Queue* q)
{assert(q);assert(!QueueEmpty(q));return q->head->data;
}QDataType QueueBack(Queue* q)
{assert(q);assert(!QueueEmpty(q));return q->tail->data;
}int QueueSize(Queue* q)
{assert(q);return q->size;
}
2. 6 销毁
void QueueDestroy(Queue* q);
将底层链表中所有节点free掉,再将Queue结构中所有成员置为NULL或0就可以了。
void QueueDestroy(Queue* q)
{assert(q);//需要判空吗?//assert(!QueueEmpty(q));//释放链表节点QNode* pcur = q->head;while (pcur){QNode* next = pcur->next;free(pcur);pcur = next;q->size--;}//将Queue结构体中所有成员置为NULL或0q->head = q->tail = NULL;q->size = 0;
}
2. 7 接口的意义
在队列这个数据结构上,我们实现了8个接口,可是其中有些接口,比如判空,元素个数等几个接口内部除了断言以外就一两行代码,为什么还要费力去实现呢?
assert(!QueueEmpty(q));
assert(q->head!=NULL);
下面的写法难道不是更简洁吗?
事实上,这是因为每个人实现的队列中的成员名称可能不同,比如可能有个人的实现中,Queue是这么定义的:
typedef struct Queue
{QNode* _head;QNode* _tail;int _size;
}Queue;
那么上面的代码就会报错了。
这样一比较,使用原来的开发者制作的接口就比较安全了。
3. 经典OJ题
3. 1 用队列实现栈
题目链接

//题目给出代码:
typedef struct {} MyStack;MyStack* myStackCreate() {}void myStackPush(MyStack* obj, int x) {}int myStackPop(MyStack* obj) {}int myStackTop(MyStack* obj) {}bool myStackEmpty(MyStack* obj) {}void myStackFree(MyStack* obj) {}/*** Your MyStack struct will be instantiated and called as such:* MyStack* obj = myStackCreate();* myStackPush(obj, x);* int param_2 = myStackPop(obj);* int param_3 = myStackTop(obj);* bool param_4 = myStackEmpty(obj);* myStackFree(obj);
*/
这道题需要我们实现以上给出接口和结构体定义。
在开始写这道题之前,我们先想一下怎么用两个队列去实现栈。
首先,保证所有元素都在同一个队列(先称其为q1,另一个为q2)中,插入时只需要直接向q1入队列就可以了。
那么怎么出栈呢?
我们把q1中的元素依次出队列并入队列至q2,这样元素的顺序不会变,直到q1中只剩下一个元素,把这个元素出队列而不入队列,不就实现了出栈了吗?
当然,在出栈之后,q1和q2是否存储数据的情况就颠倒了,也就是说,q1和q2哪个存储数据是不一定的,在实现时要注意这一点。
我们正式来写这道题,第一步是实现队列这个数据结构,因为C语言是没有库提供其实现的,这里做了一些简化:
typedef struct QueueNode{struct QueueNode* next;int data;
}QNode;typedef struct Queue{QNode *head;QNode *tail;int size;
}QU;
//判空
int IsEmpty(QU* qu)
{return qu->head == NULL;
}
//入队列
void PushToBack(QU* qu,int x)
{QNode* newnode = (QNode*)malloc(sizeof(QNode));newnode->data = x;newnode->next = NULL;if(IsEmpty(qu)){qu->head = qu->tail=newnode;}else{qu->tail->next = newnode;qu->tail = newnode;}qu->size++;
}
//出队列,在这道题中由于不允许使用其他接口,所以出队列函数要额外返回出队列的数据。
int PeekFromFront(QU* qu)
{QNode* newhead = qu->head->next;int ret = qu->head->data;free(qu->head);qu->head = newhead;if(!qu->head)qu->tail = NULL;qu->size--;return ret;
}
//初始化
void InitQU(QU* qu)
{qu->head = qu->tail=NULL;qu->size = 0;
}
//销毁,其实在OJ题中,一般不会出现内存溢出,所以可以不考虑内存溢出,但为了代码的严谨性,最好还是释放掉内存。
void Destroy(QU* qu)
{QNode* cur = qu->head;while(cur){QNode* next = cur->next;free(cur);cur = next;}qu->head = qu->tail = NULL;qu->size = 0;
}
在写OJ题时,不需要考虑malloc失败的情况,也不需要任何断言(当然加上也可以)。
以上是队列的实现,下面我们逐一来看栈的实现:
3. 1. 1 栈的定义
typedef struct {QU* q1;QU* q2;int size;
} MyStack;
两个队列指针,一个int变量存储数据的个数。
3. 1. 2 栈的初始化
MyStack* myStackCreate();
由于函数声明由题目给出,所以我们必须写成在函数内部动态申请内存然后返回的形式。
不仅申请MyStack这个结构体的内存,还要为其中的两个队列申请内存,因为MyStack结构体中只存在两个指向QU类型的指针变量而不是QU变量。
MyStack* myStackCreate() {MyStack* MS = (MyStack*)malloc(sizeof(MyStack));//为两个队列申请空间MS->q1 = (QU*)malloc(sizeof(QU));MS->q2 = (QU*)malloc(sizeof(QU));//分别对两个队列进行初始化InitQU(MS->q1);InitQU(MS->q2);MS->size = 0;return MS;
}
3. 1. 3 入栈
void myStackPush(MyStack* obj, int x);
上面已经说过了,只需要向有数据的队列入队列这个数据就可以了**,如果都没有数据,向任意队列入数据**就行。
void myStackPush(MyStack* obj, int x) {//找有数据的队列,都没有就用 q1QU* use = obj->q1;if (IsEmpty(use))use = obj->q2;//在找到的队列入队列这个数据PushToBack(use, x);obj->size++;
}
3. 1. 4 出栈
int myStackPop(MyStack* obj);
这个出栈函数需要返回出栈的数据。
按照我们前面所说的,有几个步骤:
- 找到有数据的队列
- 将有数据的队列中的除了最后一个元素外全部出队列并入队列到另一个队列中
- 将原本有数据的队列的最后一个元素出队列并返回
int myStackPop(MyStack* obj) {// 1. OJ题一般不需要考虑两个队列都为空的情况QU* use = obj->q1;QU* other = obj->q2;if (IsEmpty(use)) {use = obj->q2;other = obj->q1;}// 2while (use->head->next) {PushToBack(other, PeekFromFront(use));}// 3return PeekFromFront(use);
}
3. 1. 5 取栈顶元素
int myStackTop(MyStack* obj);
其实步骤和出栈是几乎一样的,只是最后的那个元素在出队列之后还需要入队列到另一个队列中。
int myStackTop(MyStack* obj) {QU* use = obj->q1;QU* other = obj->q2;if (IsEmpty(use)) {use = obj->q2;other = obj->q1;}while (use->head->next) {PushToBack(other, PeekFromFront(use));}//以上都和出栈一样//将最后一个元素的值保存起来方便返回int ret = PeekFromFront(use);//将其入队列到另一个队列中PushToBack(other, ret);return ret;
}
3. 1. 6 判空
如果两个队列都为空,那么这个栈就是空的。
bool myStackEmpty(MyStack* obj)
{ return IsEmpty(obj->q1) && IsEmpty(obj->q2);
}
3. 1. 7 销毁
将两个队列销毁,再将两个队列本身和栈本身都free掉就可以了。
void myStackFree(MyStack* obj) {Destroy(obj->q1);Destroy(obj->q2);//栈和队列都是动态开辟的,所以都需要释放free(obj->q1);free(obj->q2);free(obj);
}
这道题的Leetcode官方题解使用的是以数组为底层的队列去实现栈,但是由于本文是用的链表,所以还是用的链表,感兴趣可以研究一下怎么使用数组实现队列。
谢谢你的阅读,喜欢的话来个点赞收藏评论关注吧!
我会持续更新更多优质文章