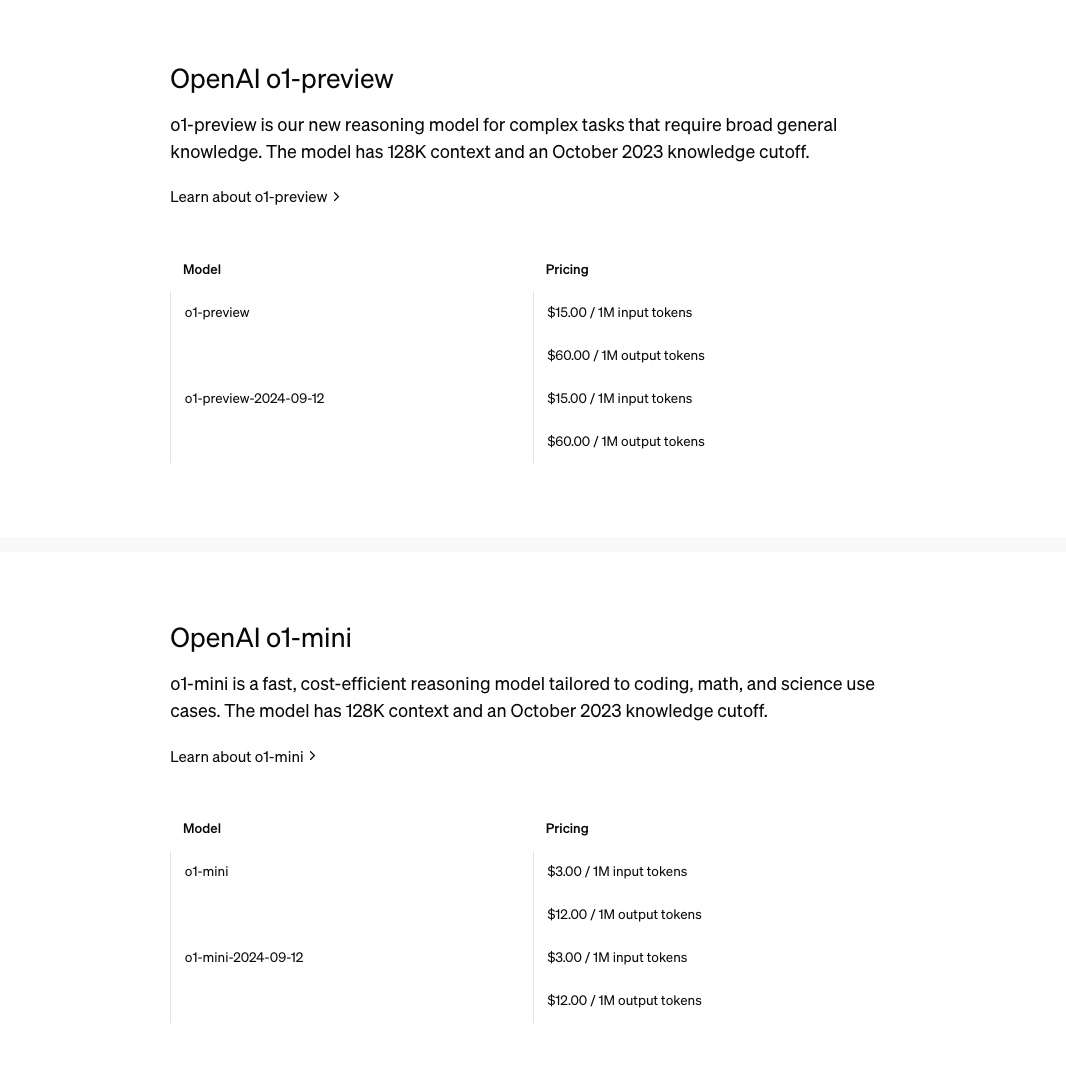
Abstract
3d感知表示非常适合机器人操作,因为它们很容易编码遮挡并简化空间推理。许多操作任务在末端执行器姿态预测中需要较高的空间精度,这通常需要高分辨率的3d特征网格,这对于处理来说计算成本很高。因此,大多数操作policies直接在2d中运行,上述3d归纳偏差。在本文中,我们介绍了act3d,一种操作policy transformer,它使用自适应分辨率的3d特征场来表示机器人的工作空间,该场依赖于手头的任务。该模型利用感知深度将 2d 预训练特征提升到 3d,并关注它们来计算采样 3d 点的特征。它以从粗到细的方式对 3d 点网格进行采样,使用相对位置注意力对其进行特征化,并选择在哪里聚焦下一轮点采样。通过这种方式,它有效地计算了高空间分辨率的3d动作图。act3d 在 rlbench 中设置了新的最先进技术,这是一个已建立的操作基准,它在 74 个 rlbench 任务上比之前的 sota 2d 多视图 policy 实现了 10% 的绝对改进,比之前的 sota 3d policy 减少了 22% 的绝对改进。我们在消融实验中量化了相对空间注意、大规模视觉语言预训练的 2d 主干以及从粗到细的注意力之间的权重绑定的重要性。代码和视频可在我们的项目网站上获得:https://act3d.github.io/。
1 Introduction
许多机器人操纵任务的解决方案可以建模为一系列6-dof末端执行器姿势(3d位置和方向)。许多最近的方法训练神经操纵 neural manipulation policies,使用演示的监督直接从2d图像中预测3d末端执行器姿势序列[1,2,3,4,5,6]。这些方法通常是样本效率低下的:它们通常需要许多轨迹来处理测试时的微小场景变化,并且不能很容易地在相机视点和环境之间进行推广,正如在各自的论文中提到的和我们的实验中所示。
为了使机器人policy在平移、旋转或相机视图变化下进行泛化,它需要具有空间等变性[7],即将输入视觉场景的3d平移和旋转映射到机器人末端执行器的类似3d平移和转动。空间等变要求根据所考虑的动作空间,通过2d或3d动作图预测3d末端执行器位置,而不是从整体场景或图像特征中回归动作位置。Transporter 网络[8]为4自由度机器人操纵引入了一种空间等变架构:它们将RGB-D输入图像重新投影到自上而下的图像中,并通过自上而下的2D动作图预测机器人末端执行器的2D平移。与之前的研究相比,他们在更少的训练演示下表现出了更好的泛化能力。然而,它们仅限于自上而下的2D世界和4-DoF操纵任务。这就引出了一个问题:我们如何将动作预测中的空间等变扩展到一般的6-DoF操纵?
开发空间等变的6-dof操纵policies需要通过将机器人工作空间中的3d点分类为机器人末端执行器未来3d位置的候选者来预测3d动作图。由于额外的空间维度,预测精细操作任务所必需的高分辨率3d动作图比2d动作图更具计算挑战性。对机器人的3d工作空间进行体素化,并以高分辨率对3d体素进行处理,在计算上要求很高[9]。下一个末端执行器姿势可能在自由空间中的任何位置,这防止了使用稀疏的3d卷积[10,11]来选择性地仅对3d自由空间的一部分进行特征化。为了解决这个问题,peract[1]最近的工作使用感知者[12]的潜在集瓶颈自我注意 the latent set bottlenecked self-attention 操作对3d体素进行了特征化,其复杂性与体素数量呈线性关系,而不是二次型,即全对全自我注意操作。然而,由于潜在的集合瓶颈,它放弃了特征的空间解纠缠。其他方法避免在3d自由空间中完全特征化点,而是从检测到的2d图像接触点回归机器人3d位置的偏移[2,13,14],这同样不完全符合空间等变。
本文介绍了Act3D,这是一种用于多任务6自由度机器人操纵的语言条件transformer,通过自适应3D空间计算预测连续分辨率的3D动作图。Act3D将场景表示为连续的3D特征场。它通过使用感测深度从一个或多个视图中提取2D基础模型的特征来计算场景级物理3D特征云。它通过循环粗到细的3D点采样和特征化来学习任意空间分辨率的3D特征场。在每次迭代中,模型对整个工作空间中的3D点进行采样,并使用对物理3D特征云的相对空间交叉注意力[15]对其进行特征化。Act3D通过对3D点特征进行评分来预测3D末端执行器位置,然后对末端执行器的3D方向和开口进行回归。在推理时,我们可以通过在自由空间中采样比训练时看到的模型更多的3D点来权衡更高的空间精度和任务性能。
我们在rlbench[16]中测试了act3d,rlbench是从演示中学习各种机器人操纵policies的既定基准。我们在单任务和多任务设置中都设定了新的基准。具体来说,在hiveformer[2]引入的74个任务的单任务设置中,我们比之前的sota绝对提高了10%,在peract[1]引入的18个任务和249个变体的多任务设置中比之前的so4绝对提高了22%。我们还使用franka panda验证了我们的方法,该多任务agent从头开始在8个真实任务上训练,总共只进行了100次演示(见图2)。在彻底的消融中,我们展示了我们架构的设计选择的重要性,特别是相对空间注意力、大规模视觉语言预训练的2d骨干、高分辨率特征和从粗到细注意力的权重。
总之,我们的贡献是:
1.一种用于语言条件多任务6-dof操纵的新型神经policy架构,该架构既能在3d中直接推理,又能使用迭代粗到细的平移不变注意力在3d中保持计算的局部性。
2.在一系列模拟和现实世界任务中取得了强有力的实证结果,在rlbench上以较大的绝对优势优于之前的sota 2d和3d方法,并在测试时很好地推广到新的相机放置。
3.彻底消融,量化高分辨率特征、关联注意力权重、预先训练的2d特征和相对位置注意力设计选择的贡献。
2 Related Work
Learning robot manipulation from demonstrations
最近的许多工作训练了多任务操作policies,该操作利用transformer架构[1,2,3,5,17,18]从视频输入和语言指令中预测机器人动作。端到端图像到动作policy模型,如rt1[5]、gato[18]、bc-z[19]和instructrl[3],直接从2d视频和语言输入预测6-dof末端执行器姿势。它们需要成千上万的演示来学习空间推理,并推广到新的场景安排和环境。Transporter 络[8]及其后续变体[20,21,22]将4-dof末端执行器姿态预测作为2d overhead 图像中的像素分类。由于其架构的空间等效性,与之前通过聚合全局场景特征来回归末端效应器姿态的方法相比,他们的模型大大提高了采样效率。然而,它们仅限于具有简单拾取和放置图元的自上而下的二维平面世界。c2f-arm[4]和peract[1]的3d policy模型将机器人的工作空间体素化,并经过训练以检测包含下一个末端执行器按键的3d体素。空间精确的3d姿态预测要求3d体素网格具有高分辨率,这需要很高的计算成本。c2f-arm[4]使用从粗到细的体素化来处理计算复杂性,而peract[1]使用感知器的潜在瓶颈[12]来避免体素到体素的自我关注操作。act3d完全避免了3d体素化,而是将场景表示为连续分辨率的3d特征场。它对空工作空间中的3d点进行采样,并使用对物理3d点特征的交叉关注对其进行特征化。
Feature pre-training for robot manipulation
许多2d policy架构从冻结或微调的2d图像主干的演示中引导学习[23,24,19,25],以提高体验数据采样效率。预训练的视觉语言主干可以实现对新指令、对象和场景的泛化[26,21]。相比之下,sota 3d policy模型通常是从彩色点云输入中从头开始训练的[1,4,27]。act3d使用clip预训练的2d主干[28]来增强2d图像视图,并使用深度提升3d 3D using depth中的2d特征[29,30]。我们发现,与从头开始训练相比,2d特征预训练可以显著提高性能。
Relative attention layers
相关研究表明,在许多二维视觉理解任务和语言任务中,性能有所提高[31,32]。旋转嵌入[33]通过将其作为内部产品投射到扩展的位置特征空间中,有效地实现了相对关注。在3d中,由于坐标系是任意的,因此必须相对关注。在3d Transformer架构中,之前已经使用了3d相对注意力进行对象检测和点标记[34,35]。我们在第4节中表明,相对关注显著提高了我们模型的性能。
3 3D Feature Field Transformers for Multi-Task Robot Manipulation
act3d的架构如图1所示。它是一个policy transformer,在给定的时间步长,根据一个或多个rgb-d图像、语言指令和关于机器人当前末端执行器姿势的本体感觉信息来预测6-dof末端执行器的姿势。根据之前的工作[36,1,2,3],我们没有预测每个时间步的末端执行器姿势,而是提取了一组在演示中捕捉瓶颈末端执行器姿态的keyposes。如果
(1)末端执行器改变状态(抓取或释放某物)
或(2)速度接近零(进入抓取前姿势或进入任务的新阶段时常见),则姿势是keypose。然后,预测问题归结为根据当前观察结果预测下一个(最佳)关键动作。在推理时,act3d迭代地预测下一个最佳keypose,并使用基于采样的运动规划器来达到它,遵循之前的工作[1,2]。
图1:Act3D是一个语言条件机器人动作transformer,它通过使用相对位置注意力进行循环的粗到细3D点采样和特征化,学习任意空间分辨率的3D场景特征场。Act3D利用预训练的2D CLIP骨干将多视图RGB图像进行特征化,并使用感测深度将其提升到3D。它使用机器人工作空间的3D点的分类来预测末端执行器的3D位置,这保留了场景到动作映射的空间等变性

我们假设可以访问n个演示轨迹的数据集。每个演示都是一个观察序列![]() ,与连续动作
,与连续动作![]() 配对,并且可选地,还有一个描述任务的语言指令l。每个观察
配对,并且可选地,还有一个描述任务的语言指令l。每个观察![]() 都由来自一个或多个相机视图的RGB-D图像组成;更多细节见附录7.2。动作包括机器人末端执行器的3D位置和3D方向(表示为四元数)、其二进制打开或关闭状态,以及运动规划器是否需要避免碰撞才能达到该姿势:
都由来自一个或多个相机视图的RGB-D图像组成;更多细节见附录7.2。动作包括机器人末端执行器的3D位置和3D方向(表示为四元数)、其二进制打开或关闭状态,以及运动规划器是否需要避免碰撞才能达到该姿势:
![]()
Visual and language encoder
我们的视觉编码器将多视图rgb-d图像映射到多尺度3d场景特征云中。我们使用大规模预训练的2d特征提取器,然后使用特征金字塔网络[37]为每个相机视图提取多尺度视觉tokens。我们的输入是rgb-d,因此每个像素都与一个深度值相关联。我们根据针孔相机方程和相机内部函数的平均深度,将提取的2d特征向量“提升”为3d。语言编码器通过大规模预训练的语言编码器来处理指令。我们使用clip resnet50[28]视觉编码器和语言编码器来利用它们的共同视觉语言特征空间来解释指令和参考基础。在act3d的训练过程中,我们预先训练的视觉和语言编码器是冻结的,而不是微调的。
Iterative 3D point sampling and featurization
我们的关键思想是通过学习具有任意空间分辨率的自由空间的3D感知表示,通过循环的粗到细的3D点采样和特征化来估计高分辨率的3D动作图。通过对物理3D场景特征云的相对交叉关注[15],从输入图像视图的2D特征图中提取,对3D候选点(我们称之为重影点)进行采样、特征化和迭代评分。我们首先在整个工作空间中粗略采样,然后在上一次迭代中选择作为关注焦点的重影点附近精细采样,如图1所示。最粗糙的重影点 ghost points关注全局粗糙场景特征云,而更精细的重影点将关注局部精细场景特征云。
Relative 3D cross-attentions
我们通过对多尺度3d场景特征云、语言tokens和本体感觉的交叉关注,独立地对每个3d重影点和参数查询(用于通过内积选择一个重影点作为解码器中下一个最佳末端执行器位置)进行特征化。独立地对重影点进行特征化,而不相互关注,可以在推理时采样更多的重影点以提高性能,如我们在第4节中所示。我们的交叉注意力使用相对的3d位置信息,并通过旋转位置嵌入有效地实现[15]。我们的特征化中从不使用3d点的绝对位置,注意力只取决于两个特征的相对位置。
Decoding actions
我们通过内积和参数查询对重影点tokens进行评分,以选择一个作为下一个最佳末端执行器位置![]() 。然后,我们使用2层 多层感知器(mlp)从最后一次迭代参数查询中回归末端执行器的方向
。然后,我们使用2层 多层感知器(mlp)从最后一次迭代参数查询中回归末端执行器的方向![]() 和开口
和开口![]() ,以及运动规划器是否需要避免碰撞才能达到姿势
,以及运动规划器是否需要避免碰撞才能达到姿势 ![]() 。
。
Training
Act3D是在操纵演示数据集的输入动作元组的监督下训练的。这些元组由RGB-D观察、语言目标和关键动作![]() 组成。在训练过程中,我们随机抽取一个元组,并监督Act3D在给定观察值和目标(o,l)的情况下预测关键动作k。我们通过重影点上的softmax交叉熵损失来监督每一轮从粗到细的位置预测apos,通过四元数预测上的MSE损失来监督旋转预测apot,并打开二进制末端执行器,以及规划器是否需要避免碰撞acol和二元交叉熵损失。
组成。在训练过程中,我们随机抽取一个元组,并监督Act3D在给定观察值和目标(o,l)的情况下预测关键动作k。我们通过重影点上的softmax交叉熵损失来监督每一轮从粗到细的位置预测apos,通过四元数预测上的MSE损失来监督旋转预测apot,并打开二进制末端执行器,以及规划器是否需要避免碰撞acol和二元交叉熵损失。
Implementation details
我们使用三个重影点采样阶段:首先在整个工作空间(大约1米立方体)内均匀分布,然后在直径16厘米的球中均匀分布,最后在直径4厘米的球上均匀分布。最粗的重影点关注全局粗场景特征云(![]() 粗视觉tokens),而较细的重影点将关注局部精细场景特征云,即
粗视觉tokens),而较细的重影点将关注局部精细场景特征云,即![]() 精细视觉tokens中最接近的
精细视觉tokens中最接近的![]() 。在训练过程中,我们在三个阶段平均分配1000个ghost points。在推理时,我们可以通过采样比模型在训练时看到的更多的重影点(在我们的实验中为10000个)来权衡额外的预测精度和任务性能,以获得额外的计算。我们将在第4节的消融中展示,我们的框架对这些超参数具有鲁棒性,但在采样阶段和相对的3d交叉注意力之间绑定权重对于泛化都是至关重要的。对于单任务实验,我们在nvidia 32gb v100 gpu上使用批量大小为16,执行20万步(一天),对于语言条件多任务实验,在8个nvidia 32gb v100 gpu上将批量大小为48,使用60万步(5天)。在测试时,我们调用低级运动规划器来达到预测的keyposes。在模拟中,我们使用rlbench中提供的原生运动规划器实现,rlbench是一种基于采样的birrt[38]运动规划器,由底层的开放运动规划库(ompl)[39]提供支持。对于真实世界的实验,我们使用moveit!ros包[40]提供的相同birrt规划器。请参阅附录7.4了解更多详细信息。
。在训练过程中,我们在三个阶段平均分配1000个ghost points。在推理时,我们可以通过采样比模型在训练时看到的更多的重影点(在我们的实验中为10000个)来权衡额外的预测精度和任务性能,以获得额外的计算。我们将在第4节的消融中展示,我们的框架对这些超参数具有鲁棒性,但在采样阶段和相对的3d交叉注意力之间绑定权重对于泛化都是至关重要的。对于单任务实验,我们在nvidia 32gb v100 gpu上使用批量大小为16,执行20万步(一天),对于语言条件多任务实验,在8个nvidia 32gb v100 gpu上将批量大小为48,使用60万步(5天)。在测试时,我们调用低级运动规划器来达到预测的keyposes。在模拟中,我们使用rlbench中提供的原生运动规划器实现,rlbench是一种基于采样的birrt[38]运动规划器,由底层的开放运动规划库(ompl)[39]提供支持。对于真实世界的实验,我们使用moveit!ros包[40]提供的相同birrt规划器。请参阅附录7.4了解更多详细信息。
4 Experiments
我们在模拟和现实世界中通过演示单任务和多任务操作policies来测试act3d。为了可重复性和基准测试,我们在rlbench[16]中进行了模拟实验,rlbench是学习操作policies的既定模拟基准。我们的实验旨在回答以下问题:
- 1.在不同训练演示次数的单任务和多任务设置中,act3d与sota 2d多视图和3d操纵policies相比如何?
- 2.与之前的2d多视图policies相比,act3d如何跨相机视点进行推广?
- 3.相对3d注意力、预训练的2d骨干、权重绑定注意力层和从粗到细采样阶段的数量等设计选择如何影响性能?
4.1 Evaluation in simulation
Datasets
我们在rlbench中以两种设置测试act3d:
1.单任务操作policy学习。我们考虑了hiveformer提出的分为9类的74项任务[2]。每个任务都包括测试对相同训练对象的新排列的泛化的变体。每种方法都经过100次演示训练,并在500次看不见的事件中进行评估。
2.多任务操作policy学习。我们考虑了peract[1]提出的18项任务和249种变体。每个任务包括2-60个变体,测试对涉及新对象颜色、形状、大小和类别的新目标配置的泛化能力。这是一个更具挑战性的环境。每种方法都经过训练,每项任务有100个演示,分为不同的变体,并在每项任务的500个看不见的事件上进行评估。
Baselines
我们将act3d与以下最先进的操纵policy学习方法进行了比较:
1.instructrl[3],一个2d policy,通过预先训练的视觉和语言骨干,直接从图像和语言条件中预测6个dof姿势。
2.peract[1],一个3d policy,它将工作空间体素化,并通过全局自我关注检测下一个最佳体素动作。
3.hiveformer[2]和auto-λ[13],混合方法,检测图像输入中的接触点,然后回归该接触点的偏移。我们在可用时报告论文中的数字。
Evaluation metric
我们通过任务完成成功率、导致语言指令中指定的目标条件的执行轨迹的比例来评估 policies。
Single-task and multi-task manipulation results
我们在图3中显示了我们的模型和基线的单任务定量结果。Act3D的成功率达到83%,比在此设置下的先前SOTA InstructRL[3]绝对提高了10%,并且在所有9类任务中始终优于它。Act3D每项任务只有10个演示,与之前每项任务使用100个演示的SOTA相比具有竞争力。Act3D优于InstructRL和Hiveformer的2D方法,因为它直接在3D中推理。出于同样的原因,它比它们更好地推广到新的相机位置,如表3所示。
图3:单任务性能。在9个类别的74个RLBench任务中,Act3D的成功率达到83%,比在此设置下的SOTA之前的InstructRL[3]绝对提高了10%。

我们在图4中显示了我们的模型和PerAct的多任务定量结果。Act3D的成功率达到65%,比PerAct(在这种情况下是SOTA之前的PerAct)绝对提高了22%,在大多数任务中都表现出色。每项任务仅需10次演示,Act3D在每项任务100次演示时的表现优于PerAct。请注意,Act3D也使用了不到PerAct训练计算预算的三分之一:PerAct在8个Nvidia V100 GPU上训练了16天,而我们在相同的硬件上训练了5天。Act3D的表现优于PerAct,因为其基于从粗到细的相对注意力 coarse-to-fine relative attention的3D工作空间特征化在生成空间解纠缠特征方面比perceiver的潜在瓶颈注意力 latent bottleneck attention更有效。
图4:多任务性能。在18个具有249个变体的RLBench任务中,Act3D的成功率达到65%,比PerAct[1](在此设置4.2 Ablations下的SOTA之前)绝对提高了22%。

4.2 Ablations
我们在表3中消除了设计选择的影响。我们在5个任务的单任务设置中执行大多数消融:摘杯子、把刀放在砧板上、把钱放在保险箱里、滑块瞄准目标、把伞从支架上拿出来。我们在所有18个任务的多任务设置中消融了预先训练的2D骨干的选择。

Generalization across camera viewpoints:
我们在测试时为Act3D和HiveFormer改变了相机视角[2]。HiveFormer的成功率降至20.4%,相对下降77%,而Act3D的成功率为74.2%,相对下降24%。这表明,与回归偏移的多视图2D方法相比,检测3D中的动作使Act3D对相机视点变化更具鲁棒性。
Weight-tying and coarse-to-fine sampling:
从粗到细的所有3个阶段都是必要的:只有2个阶段的采样和对第二阶段所选位置的偏移进行回归的模型性能下降了4.5%。跨阶段的权重绑定和相对的3D位置嵌入都是至关重要的;我们观察到严重的过拟合,表现出17.5%和42.7%的性能下降。精细重影点采样阶段应关注具有精确位置的局部精细视觉特征:所有关注全局粗略特征的阶段都会导致性能下降8.3%。Act3D可以有效地在推理计算与性能之间进行权衡:采样10000个重影点,而不是模型训练时使用的1000个,可以将性能提高4.9%。
Pre-training 2D features:
我们研究了预训练的2D骨干在最需要语言指令的多任务环境中的作用。使用CLIP预训练的ResNet50[28]骨干网比在ImageNet上预训练的ResNet50骨干网的成功率提高了8.7%。
我们发现随机裁剪RGB-D图像可以提高性能,但偏航旋转扰动没有帮助。该模型对超参数的变化具有鲁棒性,例如重影点采样球的直径或训练期间采样的点数。有关增强和超参数敏感性的其他消融,请参阅附录第7.6节。
4.3 Evaluation in real-world
在我们的实际设置中,我们使用Franka Emika Panda机器人和单个Azure Kinect RGB-D传感器进行实验。我们考虑了8个任务(图2),这些任务涉及与多种类型的对象的交互,包括液体、铰接对象和可变形对象。对于每项任务,我们收集了10到15个动觉 kinesthetic 演示,并用所有这些演示训练了一个语言条件下的多任务模型。我们在表2中报告了每项任务10次发作的成功率。Act3D可以很好地捕捉演示中的语义知识,并且在所有任务上都表现得相当好,即使只有一个摄像头输入。一个主要的失败案例来自噪声深度传感:当深度图像不准确时,所选点会导致不精确的动作预测。利用多视图输入进行错误纠正可以改善这一点,我们将其留给未来的工作。有关机器人执行任务的视频,请参阅我们的项目网站。

4.4 Limitations and future work
我们的框架目前有以下局限性:
1、act3d受到用于将预测的keyposes与直线轨迹段连接起来的运动规划器的限制。它不能很好地处理铰接物体的操纵,例如打开/关闭门、冰箱和烤箱,在这些地方,机器人的轨迹无法用很少的线段很好地近似。
2、act3d不利用任何将任务分解为子任务的方法。一个分层框架可以预测子任务的语言子目标[41,42,43],并将其提供给我们的语言条件policy,这将允许跨任务更好地重用技能。解决这些局限性是未来工作的直接途径。
5 Conclusion
我们提出了act3d,这是一种语言条件的policy transformer,可以预测多任务机器人操纵的连续分辨率3d动作图。act3d使用连续分辨率的3d特征图来表示场景,该图是通过从粗到细的3d点采样和基于注意力的特征化获得的。act3d为rlbench(一个成熟的机器人操纵基准)设定了新的最先进技术,并通过单个rgb-d相机视图和少量演示解决了现实世界中的各种操纵任务。我们的消融量化了相对3d注意力、2d特征预训练和粗细迭代期间权重绑定的贡献。