RO-NeRF论文笔记
文章目录
- RO-NeRF论文笔记
- 论文概述
- Abstract
- 1 Introduction
- 2 Related Work
- 3 Method
- 3.1 RGB and depth inpainting network
- 3.2 Background on NeRFs
- 3.3 Confidence-based view selection
- 3.4 Implementation details
- 4 Experiments
- 4.1 Datasets
- Real Objects
- Synthetic Objects
- 4.2 Metrics
- 4.3 Ablations and comparison with baselines
- 4.4 Limitations
- 5 Conclusion
Github:Removing Objects from Neural Radiance Fields
项目地址:https://nianticlabs.github.io/nerf-object-removal/
论文概述
目的:在共享 NeRF 之前,可能需要删除个人信息或难看的物体。
方法:提出了一个框架,用于从 RGBD 序列创建的 NeRF 表示中删除对象。我们的 NeRF 修复方法利用了最近在 2D 图像修复方面的工作(LaMa),并由 user-provided mask 指导。我们的算法以基于置信度的视图选择程序为基础。它选择在创建 NeRF 时使用那些单独的 2D 修复图像,以便生成的修复 NeRF 是 3D 一致的。
贡献:
- 提出了第一个聚焦于利用单个图片修复的inpainting-NeRFs的方法。
- 提出了一个新的view-selection机制,能自动去除不连续的views。
- 提出了一个新数据集,用于评估室内/室外场景下的object removal和inpainting。
Abstract
神经辐射场 (NeRFs) 正逐步应用到场景表征的各个方向,来实现新颖视图的合成。NeRF 将越来越多内容与其他人共享。不过,在共享 NeRF 之前,可能需要删除个人信息或难看的物体。使用当前的 NeRF 编辑框架不容易实现这种删除。我们提出了一个框架,用于从 RGBD 序列创建的 NeRF 表示中删除对象。我们的 NeRF 修复方法利用了最近在 2D 图像修复方面的工作,并由 user-provided mask 指导。我们的算法以基于置信度的视图选择程序为基础。它选择在创建 NeRF 时使用那些单独的 2D 修复图像,以便生成的修复 NeRF 是 3D 一致的。我们研究表明,我们的NeRF 编辑方法能有效的以多视图连贯的方式 合成合理的修复。我们为NeRF Inpainting任务提出了一个新的且仍有挑战性的数据集,从而验证了我们的方法。
1 Introduction
NeRFs应用已经超出了最初的新视角合成任务,让非专业用户也能使用NeRF进行一些新颖的应用:如NeRF编辑或实时捕捉和训练。但是,其中会出现很多问题。
首当其冲的是如何无缝移除渲染场景的部分内容。例如:房产销售网站上共享的房屋扫描图可能需要移动不美观或可识别个人身份的物体。同时,物体也可以被移除,以便AR应用中的替换3D物体操作,例如:移除一张椅子并查看新椅子在相同位置的效果。
事实上,NeRFs编辑应用已有很多探索,例如,以对象为中心的表征将标注对象从背景中分离、语义分解。但他们不能生成任何视角都未观察到的元素。

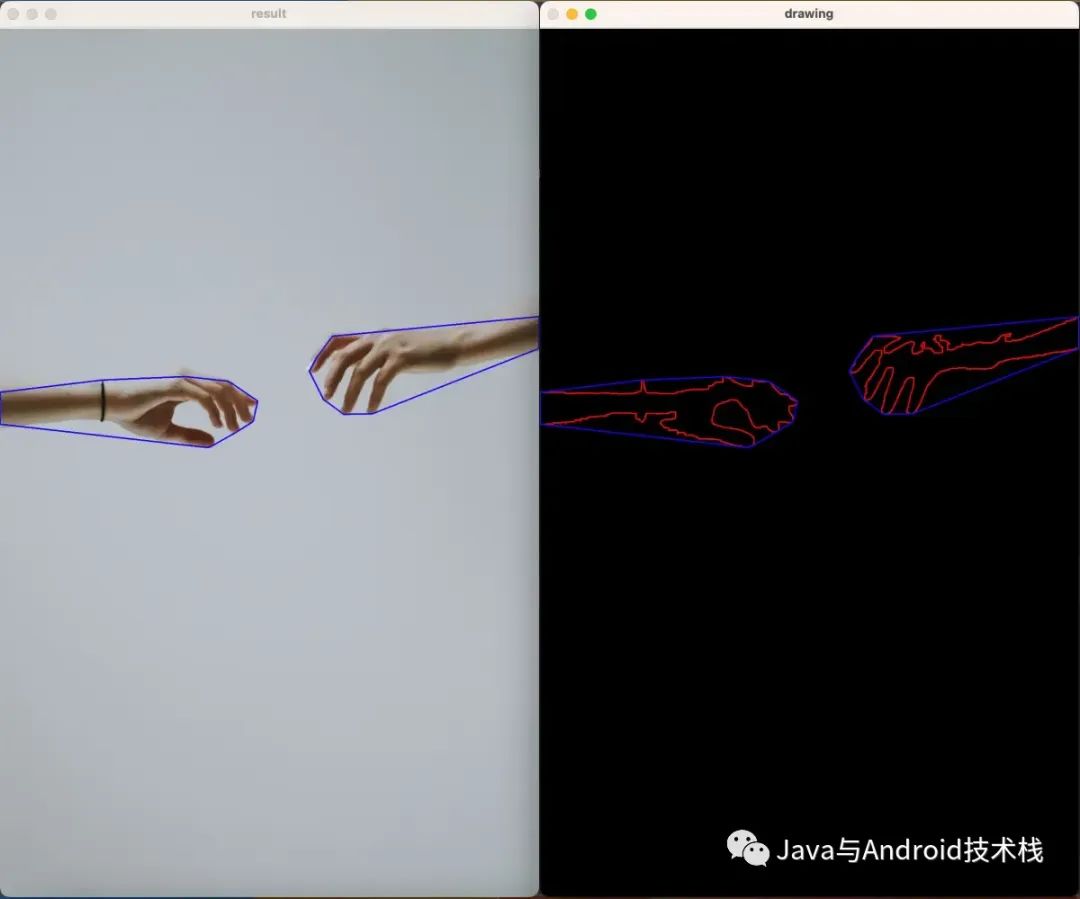
由上图所示,我们解决了场景中移除障碍物的问题,同时真实的填补了由此产生的漏洞。有两个需要用到的:
- 多视角信息:当场景的某些部分在某些帧中被观察到,但在另一些帧中被遮挡。
- 利用生成过程来填补从未被观察到的区域。
为此,我们将NeRFs的多视角一致性和Lama的生成能力相结合。但是,lama这种2D修复在结构上不具有多视角一致性,从而导致最终渲染出来的结果中很可能包含严重的伪影。因此,我们设计了一种新的基于置信度的视图选择方案,通过迭代的方式从优化中删除不一致的修复。
我们在一个新数据集上验证了我们的方法,结果表明,我们的新视图合成方法优于现有的方法,并能产生多视图一致的结果。
总的来说,贡献如下:
- 提出了第一个聚焦于利用单个图片修复的inpainting-NeRFs的方法。
- 提出了一个新的view-selection机制,能自动去除不连续的views。
- 提出了一个新数据集,用于评估室内/室外场景下的object removal和inpainting。
2 Related Work
- Image inpainting:对单个图片进行缺失区域填补。但是,这些方法无法实现视频帧之间的时间一致性。
- Removing moving objects from videos:这个问题研究的比较透彻,大多数工作都聚焦在移除移动物体上,通常是在附近帧的引导下实现的,移动的物体会使任务变得更加简单。
- Removing static objects from videos
- 如果序列中其他帧可以看到被遮挡的像素,则可以利用这些像素来填充区域。
- 但是,通常有一些像素在其他视图中无法看到,则需要对这些像素进行填补。
- Novel view synthesis and NeRFs
-
NeRF是非常流行的基于图像的渲染方法,用可微分体积渲染公式表示场景。训练多层感知机来回归给定三维坐标和光线观察方向的颜色和不透明度。它结合了隐式三维场景表示法、光场渲染和新型视图合成。扩展工作包括了减少混叠伪影、应对无边界场景、仅从稀疏视图重构场景、利用八叉树或其他稀疏结构等方式提高NeRF的效率。
-
深度感知的NeRF:为了克服NeRF对高密度视图的要求和重建几何图形质量的限制,在训练中使用深度(可以来自于SfM或传感器的深度)。
-
用于编辑的以对象为中心和语义的NeRF
- 动态场景:基于运动,有更多的背景可见,对背景的建模效果更好。
- 静态场景:基于实例分割,不考虑删除物体后的场景是完整的,很可能被删除物体后的背景是嘈杂的,或因为缺乏观察而出现空洞。
-
用于新视图合成的****生成模型
- 三维感知生成模型可用于 以三维一致的方式 从不同视角合成物体或场景的视图。与 NeRF model仅能通过测试的方式并很可能对某个场景过拟合 相比,生成模型可以通过潜在变量空间中采样,幻化出新物体的视图。为了训练一个生成模型,需要大量的RGB+相机姿态的室内场景(甚至需要depth),相比之下,我们使用2D inpainting network(lama更少依赖于训练数据和室内场景。
-
新视图合成中的inpainting
- Inpainting通常作为新视角合成的一个组成部分,用于估计输入图像中未观察到的区域的纹理,例如全景生成、Philipp等人的针对image-based-rendering的object removal,但他们假设了背景区域是局部平面。与我们方法类似,有两个工作利用了单个图片修复的方法,移除了NeRFs中的物体,他们针对多视角不一致问题,一个是[33]选择了在mask中的NeRF优化下使用单视角、另一个是[43]使用了percetual loss.
-
3 Method
我们假设给定了包含了相机内外参的RGB-D序列,深度和姿态是可以获取到的,例如使用一个dense的SfM。
我们使用了Apple’s ARKit直接获取RGB-D序列,但我们依旧展示了使用多视图立体方法预测RGB序列的深度。
我们还假定可以访问要删除对象的每帧mask。
目的:由这些input学一个NeRF,它能合成连续的新视图,每帧masked区域会被合理的填补。Overview如下:

3.1 RGB and depth inpainting network
我们的方法依赖于2D single image inpainting(对每个RGB图像进行修复),除此之外,还需要depth inpainting network,我们视这两个网络为黑盒,未来inpainting方法改进后能直接迁移至我们方法进行改进。
给定一张RGB图像 I n I_n In和对应mask M n M_n Mn,per-image inpainting算法会得到修复后的新RGB图像 I ^ n \hat{I}_n I^n.
类似的,depth inpainting算法会生成对应的深度图 D ^ n \hat{D}_n D^n
inpainting结果如下:

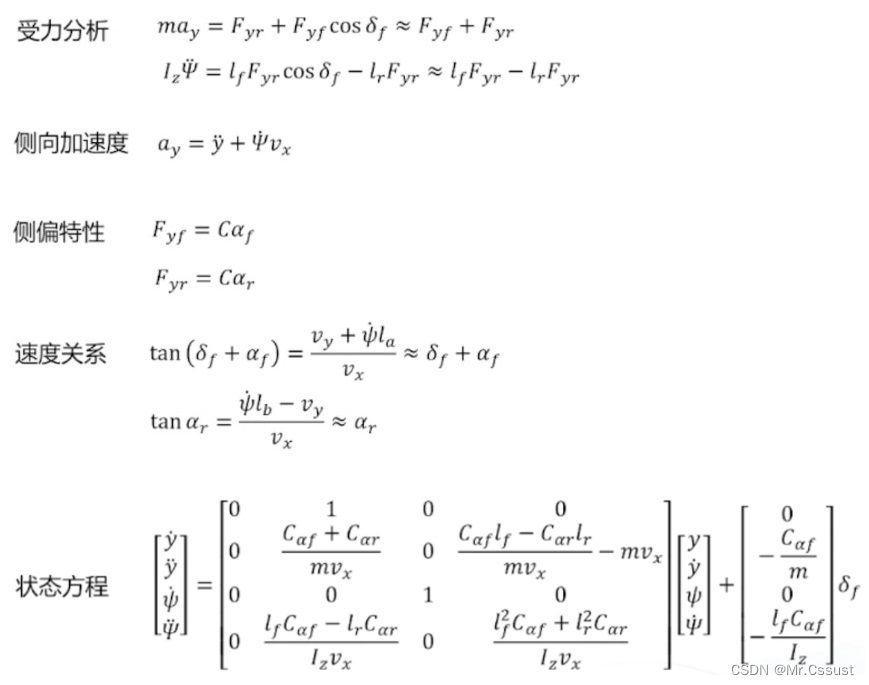
3.2 Background on NeRFs
- I ^ n ( r ) \hat{I}_n(r) I^n(r)公式
- 原本的NeRF loss: L R G B L_{RGB} LRGB公式
- 额外的Depth loss: L d e p t h L_{depth} Ldepth公式
- Distortion regularizer loss, l d i s t ( r ) l_{dist}(r) ldist(r)公式

3.3 Confidence-based view selection
大多数inpainted RGB images I ^ n \hat{I}_n I^n很逼真,但存在一些问题:
- 一些inpainting是不正确的。
- 尽管每个inpainting都很逼真,但没有保证多视角一致性。
因此,我们提出一个基于置信度的视角选择方案(选择哪些视角用于NeRF优化)
对于每张RGB图像 I n I_n In,对应一个非负的uncertainty measure u n u_n un,一个置信度 e − u n e^{-u_n} e−un,用于re-weight NeRF loss,该置信度可以被视为权重衰减项。RGB loss公式如下:

其中,对于mask内的像素(loss的第二项),由inpainted图像进行监督;对于mask以外的像素(loss的第一项),由输入的RGB图像监督。事实上, P P P并不是{1,…,N}的全集,只有一部分inpainted regions会用于NeRF优化。
Depth loss公式如下,也是根据mask内外进行划分的。

最后,引入两个正则化因子:
一个是uncertainty weights L r e g P = ∑ n ∈ P u n L_{reg}^P=\sum_{n∈P}{u_n} LregP=∑n∈Pun,它能防止 e − u n e_{-u_n} e−un为0.
另一个是distortion regularizer,loss的具体公式如下:

View Direction and multi-view consistency
优化NeRF有三个observations:
- inpainting中的多视角不连续能由使用了viewing direction的网络建模。
- 输入中移除viewing direction能增强多视角一致性。
- 输入中不使用viewing direction时,不连续会导致云状的伪影。
为了防止1和3,并正确优化uncertainty u n u_n un(用于捕获 I ^ n \hat{I}_n I^n中的不确定性),我们提出
- 增加额外的network head: F θ M V F_{\theta}^{MV} FθMV,不以viewing direction作为输入。
- 停止color inpainting和 F θ M V F_{\theta}^{MV} FθMV对density的梯度。
- Uncertainty u n u_n un作为唯一一个view-dependent的输入。
这种设计能使模型将inpaintings之间的不连续 编码至uncertainty prediction。
F θ M V F_{\theta}^{MV} FθMV对应的损失项由公式5计算: L R G B P ( I ^ M V ) L_{RGB}^P{(\hat{I}^{MV})} LRGBP(I^MV)
F θ M V F_{\theta}^{MV} FθMV的输出不用于最终的渲染,该extra head对应的loss将作为正则项。
最终,我们的loss公式如下:
L P = λ R G B L R G B P ( I ^ ) + λ R G B L R G B P ( I ^ M V ) + λ d e p t h L d e p t h P + λ r e g L r e g P + λ d i s t L d i s t P L^P=\lambda_{RGB}L_{RGB}^P(\hat{I})+\lambda_{RGB}L_{RGB}^P(\hat{I}^{MV})+\lambda_{depth}L_{depth}^P+\lambda_{reg}L_{reg}^P+\lambda_{dist}L_{dist}^P LP=λRGBLRGBP(I^)+λRGBLRGBP(I^MV)+λdepthLdepthP+λregLregP+λdistLdistP
1:1:0.005:1
对MLP参数 θ = { θ σ , θ c , θ M V } \theta=\{\theta^{\sigma},\theta^{c},\theta^{MV}\} θ={θσ,θc,θMV}和uncertainty权重 U P = { u n , n ∈ P } U^P=\{u_n,n∈P\} UP={un,n∈P}进行优化。
所有图像的置信度被初始为1,也就是说 u n : = 0 u_n:=0 un:=0
loss的部分代码实现:

而3DGS的loss函数如下:

Iterative refinement
我们使用每个图像被预测出的uncertainty: u n u_n un,逐步将不可信的图像从NeRF优化过程中移除,也就是说,我们不断更新集合 P P P(会造成mask区域的损失)。在迭代 K g r a d K_{grad} Kgrad次优化 L P L^P LP后,我们取预测出的置信度的中位数 m m m,然后将所有置信度低于m的2D inpainted resgions从训练集中移除,接着,利用更新后的训练集重新训练NeRF,该过程重复 K o u t e r K_{outer} Kouter次。伪代码如下:
注意:除了集合 P P P以外的图像依旧会参与优化,但只针对非mask区域的射线,因为这些射线包含有关场景的宝贵信息。

3.4 Implementation details
Masking the object to be removed
与其他修复方法类似,我们需要输入每帧的mask。很多现有的修复方法是通过手工标注的方式,得到每帧的mask。而我们手工标注包含物体的3D box,利用MeshLab可视化并标注3D点云 ,这样每个场景只需要做一次即可。除了手工标注以外,我们还能依靠2D object segmentation(例如SAM),或者3D object bbox detectors来实现。
Mask refinement
实践过程中,我们发现标注的3D bbox得到的mask是十分粗糙的,包含了很大部分的背景。由于较大的msak会导致修复质量较差,我们由此提出了一个msak refinement方法去获取更加贴合object的mask。该方法对于已经很贴合object的mask是不需要的,直觉上,该方法只需要移除3D bbox中空白(无物体)的空间。
首先,我们获取3D bbox中的3D点云,我们精炼后的mask是将这些点在每个图像上渲染而得到,并与深度图进行简单比较从而检查当前图像中的遮挡。最终的mask由二值化的膨胀和腐蚀算法进行去噪而得到。Mask refinement的前后对比图如下所示:

Inpainting network
我们分别对RGB和Depth图进行了独立的修复,我们的深度图预处理后,深度的区间为[0m,5m],像素值的区间为[0,255]。
NeRF estimation
我们对loss函数中的不同项进行赋权,分别为 λ R G B = λ d e p t h = λ d e p t h = 1 , λ r e g = 0.005 \lambda_{RGB}=\lambda_{depth}=\lambda_{depth}=1, \lambda_{reg}=0.005 λRGB=λdepth=λdepth=1,λreg=0.005.
我们设置了过滤步骤(将低置信度的图像从训练集中移除),每隔 K g r a d K_{grad} Kgrad移除一轮,一共移除 K o u t e r = 4 K_{outer}=4 Kouter=4次。
4 Experiments
4.1 Datasets
本工作引入了一个真实场景下的RGB-D数据集,用于评估物体移除的质量。
Real Objects
该数据集由 17 个场景组成,这些场景集中在一个有一个感兴趣物体的小区域内。这些场景在背景纹理、物体大小和场景几何复杂度方面的难度各不相同。对于每个场景,我们都收集了两个序列,一个有我们想要移除的物体,另一个没有。这些序列是在配备激光雷达的 hone 12 Pro 上使用 ARKit[2] 收集的,包含 RGB-D 图像和姿势。
如第 3.4 节所示,我们对mask进行了标注和改进。
- 训练:包含物体和相应mask的序列
- 测试:不包含物体的序列
使用真实物体可以更容易的评估系统如何处理真实阴影和反射,以及新视图合成。
Synthetic Objects
大多数视频和图像的修复方法,不会进行新视角生成,意味着不能公平的在Real objects上评估。因此,我们对数据集进行了合成增强。该数据集与Real Objects的场景是相同的,但只使用没有物体的序列。然后,我们对每个场景手动定位来自ShapeNet的3D物体。Masks由mesh投影到输入图像上,这是我们对3D object mesh的唯一用途。
- 训练:除测试外的帧用于训练。
- 测试:每隔8帧进行测试。
4.2 Metrics
为了评估物体移除和填补的质量,我们对比test集中的rendered image和gt image【只计算图片中的mask区域】
- PSNR
- SSIM
- LPIPS
为了评估几何完成度,我们计算rendered 和gt 的depth maps的L1和L2 error【只计算图片中的mask区域】
4.3 Ablations and comparison with baselines
- Image and video inpainting baselines
- Image LaMa
- Video inpainting E2FGVI
- 3D scene completion baselines
- PixelSynth
- CompNVS
- Object compositional NeRF
- Ablations
- Masked NeRF
- Inpainted NeRF
- Inpainted NeRF + inpainted Depth
- Ours – no depth
- Ours – depth predicted using [62]

4.4 Limitations
- RO-NeRF会受到2D修复方法的性能限制,当mask较大的时候,很可能2D修复会失败。
- 渲染的时候会出现模糊现象,这是由于2D修复中的高频纹理闪烁造成的。
- 物体的投影或反射没有很好的处理。
5 Conclusion
我们提出了一个训练NeRF的框架,在这个框架中,物体从输出的渲染图中合理地移除。我们的方法借鉴了现有的2D修复工作,并引入了基于置信度的自动视图选择方案,以选择具有多视图一致性的单视图inpaintings。
实验证明,与现有的方法对比,我们提出的方法改善了三维内画场景的新视角同步性,尽管依旧存在模糊问题。我们还引入了一个用于评估这项工作的数据集,为该领域的其他研究人员树立了一个基准。