01 什么是Gauge
Gauge是一款用于编写和运行验收测试的BDD框架,它有如下的特点:
-
使用Markdown的简单、灵活的语法来描述行为
-
支持多平台(Windows、Linux、macOS)、多语言(C#、Java、Javascript、Python、Ruby)
-
支持插件扩展
-
支持数据驱动和外部数据源(CSV文件)
-
支持VS Code
其中使用Markdown语法描述行为,算是Gauge最特殊的地方了,接下来我们将对其做一详细的说明,包括环境准备、项目初始化、用例编写、数据驱动、运行、测试报告等。
02 环境准备
1.安装Python
python安装比较简单,这里不做叙述。唯一需要注意的是要求python版本>=2.7
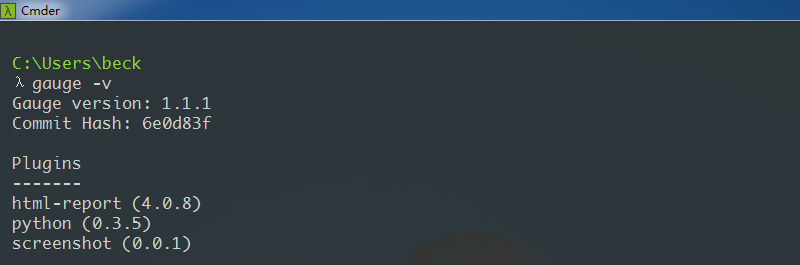
2.下载 gauge-1.1.1-windows.x86_64.exe
下载地址:https://github.com/getgauge/gauge/releases
安装比较简单,一路点击下一步,最后将gauge.exe所在路径配置环境变量。在cmder中输入gauge -v,有输出版本信息时,说明已经安装成功
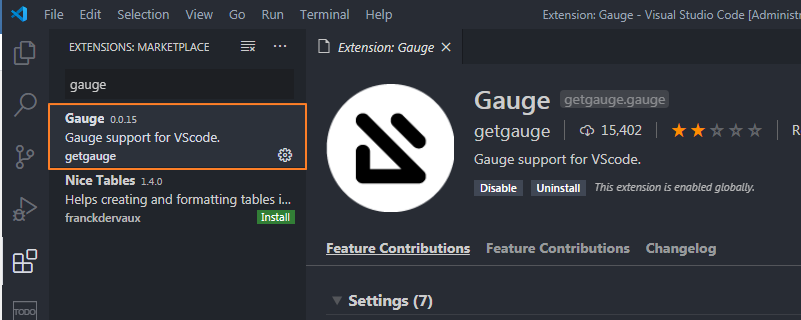
3.安装VS Code插件
在VS Code里安装gauge插件
03 项目初始化
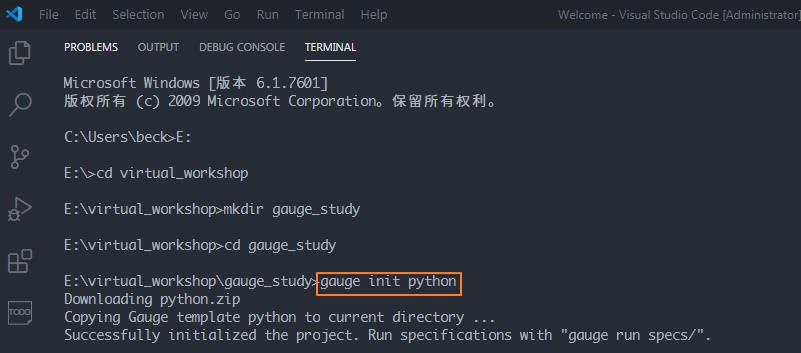
在E盘的virtual_workshop目录下,创建一个gauge_study的项目目录,切换到该目录,使用命令 gauge init python 初始化项目
初始化做了一些目录分层、环境配置等工作,并且给出了一个样例(见example.spec、step_iml.py),这是一个关于英语单词中元音字母统计的项目
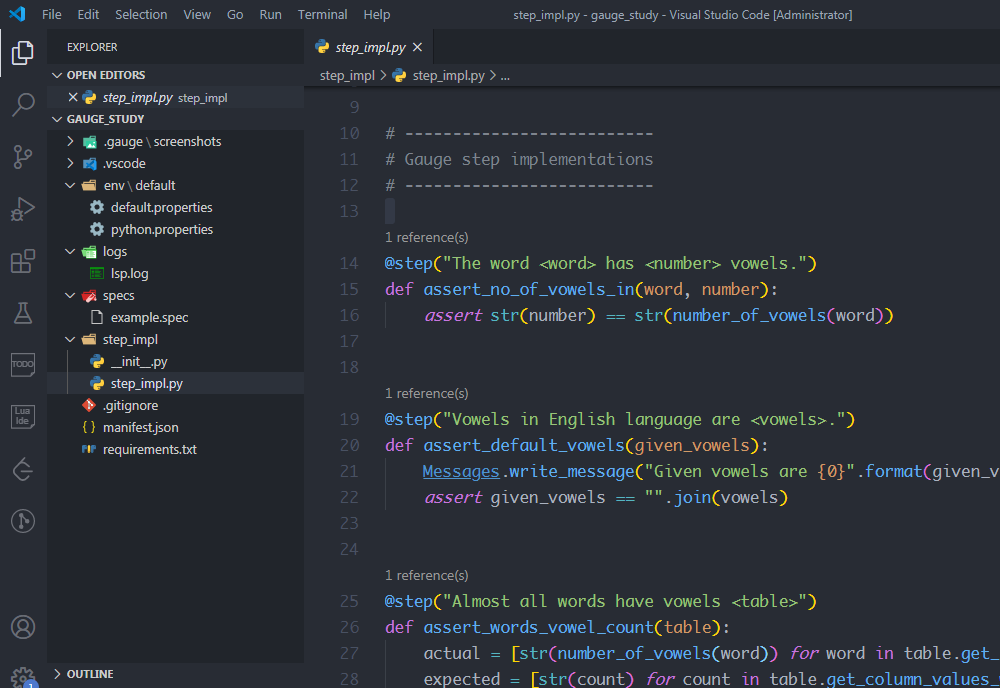
下面解释一下各个目录的作用:
-
env:环境配置目录
-
logs:日志目录
-
specs:描述行为的目录,这里存放的spec文件,使用MarkDown语法编写
-
step_impl:实现目录,使用python或其他语言来执行spec文件中描述的行为
04 用例编写
1、编写描述文件
既然是行为驱动,肯定是先有行为的描述,再有行为的实现。因此如何编写spec文件来描述行为,如何实现这些行为至关重要。现在有一个需求是这样的:
需求描述
要测试一个姓名的类型和长度,姓名类型一般是字符串,姓名长度是各个字符的总和
测试姓名类型
姓名"xxxx"的类型是"string"
测试姓名长度
姓名"xxxx"的长度是"4"
在specs目录下,创建一个name.spec的描述文件,使用MarkDown的语法来实现是这样的
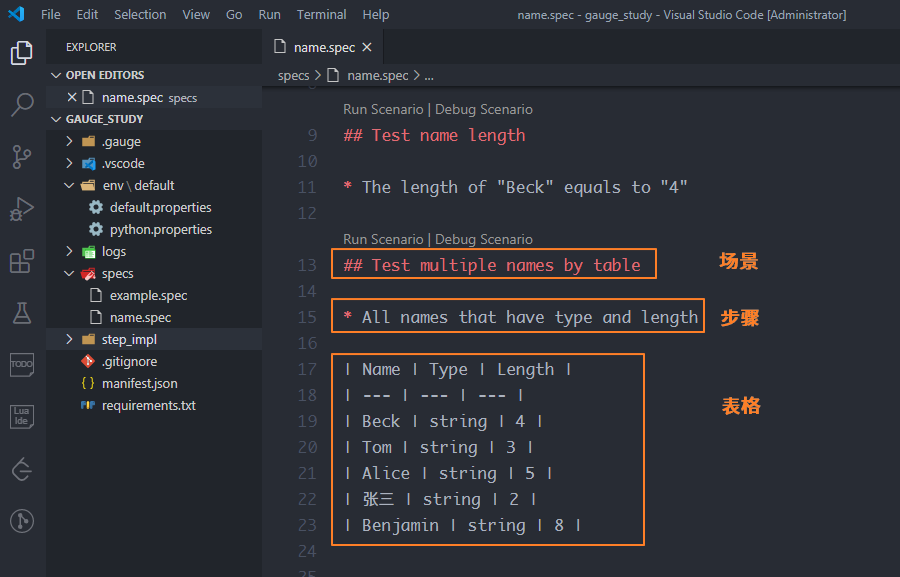
首先解释一下编写描述文件的规则:
在以往的测试用例中,都有测试套件、测试集合、测试场景、测试步骤的概念,这个概念同样适用于Gauge。你可以把Specs目录理解为测试套件,它下面的每一个spec文件都是一个测试集合,每个测试集合里包含着一个或多个测试场景,每个测试场景中又包含着一个或多个测试步骤。这样理解的话,很多东西一目了然
接着,我们结合例子具体讲下描述文件spec文件的基本写法
(1)测试集合Spec
spec文件开始的标志,只能有一个。每个Spec至少包含一个测试场景Scenario,具体写法是 "# 描述",当然下面也可以加上注释。
-
这个主要描述了测试的功能模块,比如姓名功能
# NameThis is a spec file that describe name type and length(2)测试场景Scenario
每个Scenario至少包含了一个测试步骤Step,具体的写法是"## 描述"。
-
这个主要描述了测试场景,比如要测试姓名的类型、长度,是对功能模块的分解
## Test name type* The type of "Beck" must be "string"(3)测试步骤Step
测试步骤里可以包含测试数据"Beck"和期望结果"string",也可以不包含,具体的写法是"* 描述"
-
每个步骤是对测试场景的分解
## Test name type* The type of "Beck" must be "string"2、编写实现方法
描述文件准备好后,需要有语言的实现,描述文件和实现方法的关系,简单归纳一下是这样的:
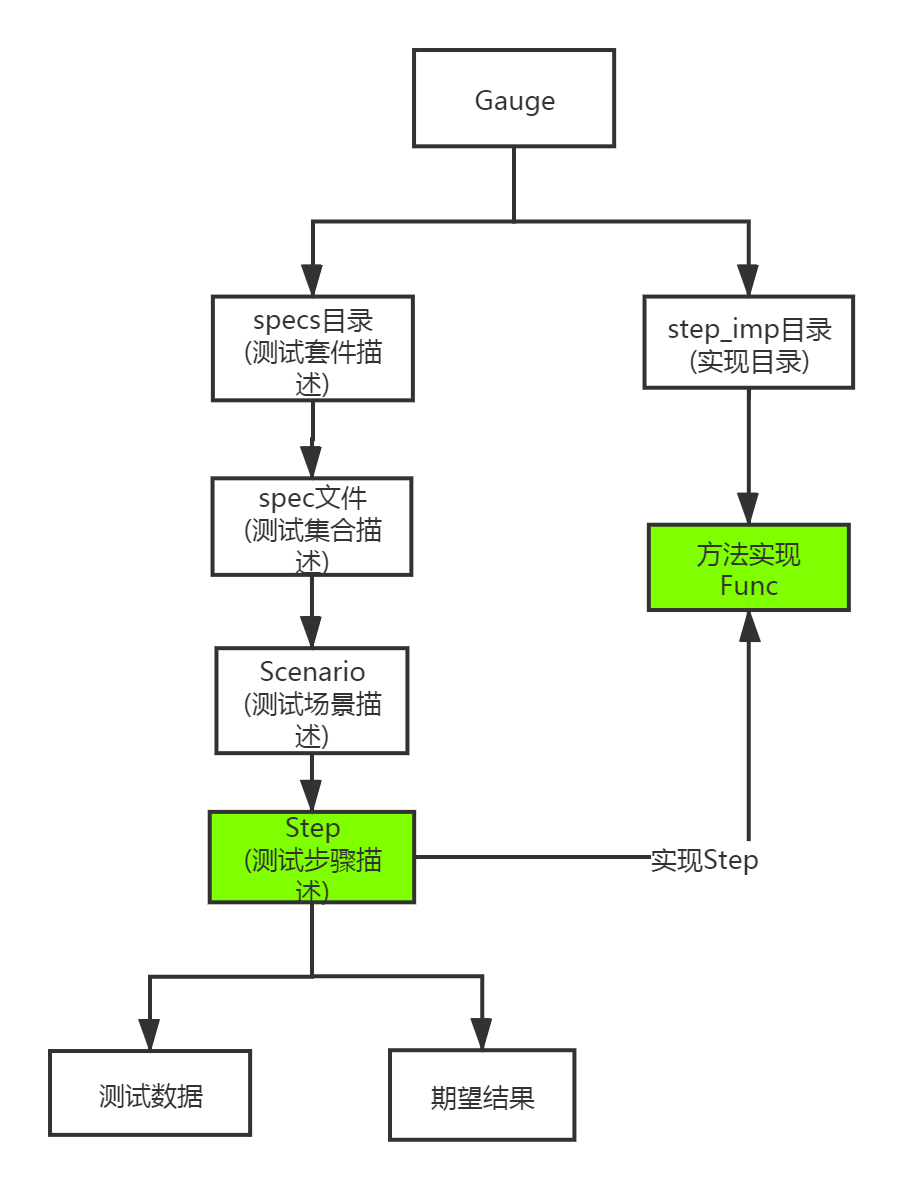
如上图所示,每一个测试方法都是对测试步骤描述的实现,只需要定义一个方法,就可以实现这个步骤。但问题来了,对于有测试数据和期望结果的步骤,我们应该怎么表示?
-
很简单,所有的实参的位置都用<变量名>表示即可,步骤只负责描述,具体获取数据、处理数据、提取实际结果、断言等逻辑由测试方法来实现,这里有些数据分离的感觉了
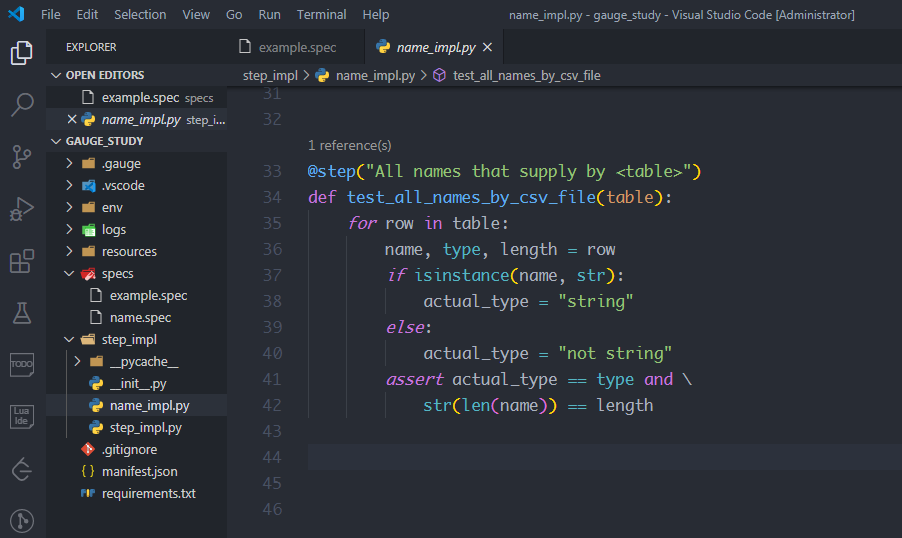
基于这一思路,在step_impl目录下创建一个name_impl.py模块,接着从getgauge.python模块中引入step方法,然后编写测试方法test_name_type和test_name_length,在测试方法上面加上@step装饰器,装饰器里的参数是描述里的内容,只不过使用<参数名>做了参数化,装饰器里的参数可以传递给测试方法

05 数据驱动
假设我们要对多个姓名做测试,显然写一行一行的步骤描述,定义一个一个的测试方法是不现实的,因此需要用到数据驱动。Gauge里支持表格和csv文件,我们先来看看表格:
01 表格
需要在描述文件name.spec中定义表格。表格作为步骤来看待,需要先准备好对应的场景和步骤
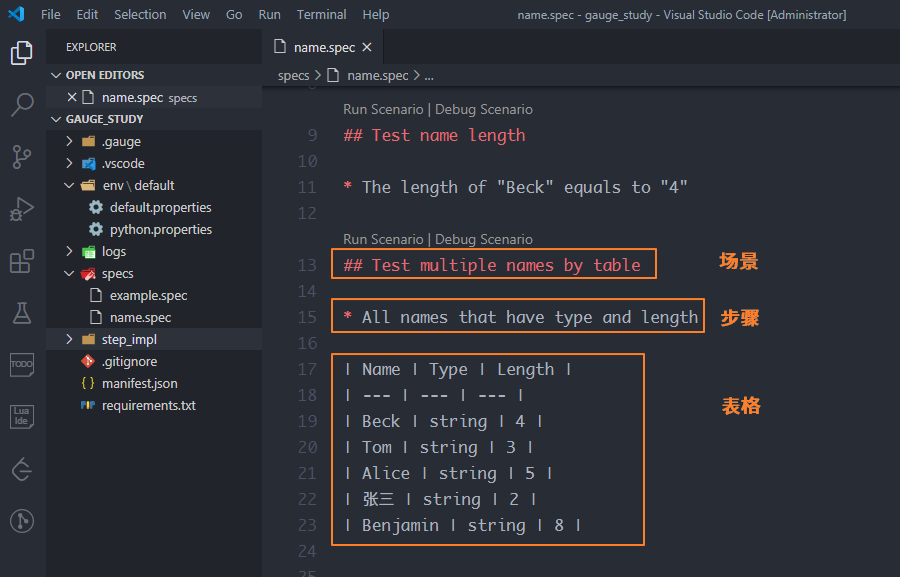
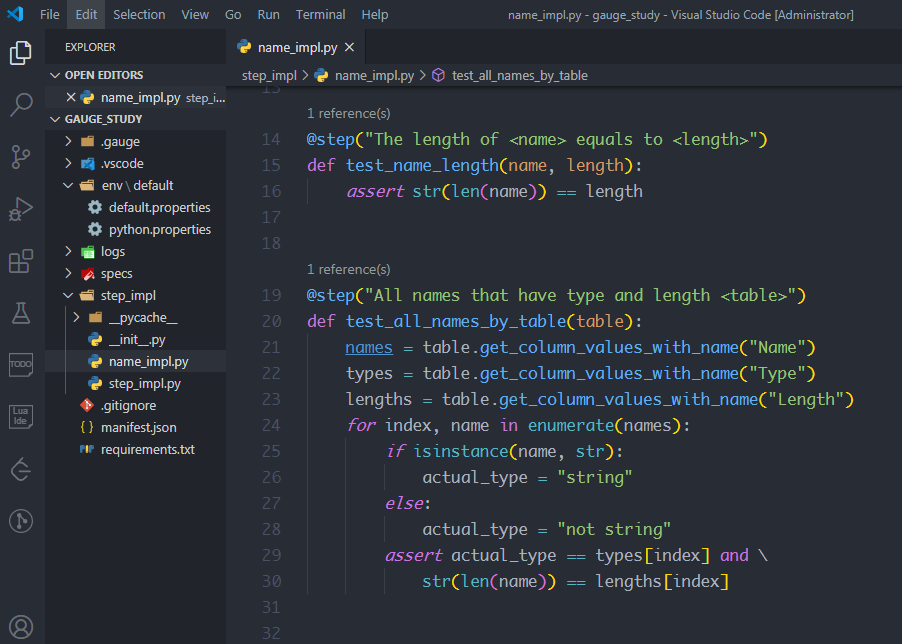
在name.spec中实现表格批量遍历的方法 test_all_names_by_table,给它加上装饰器@step(),装饰器的参数同样是描述步骤中的内容"All names that have type and length",只不过还要在后面加上变量<table>,变量table表示表格对象,因此参数是"All names that have type and length <table>"
那么表格中的每一个值怎么遍历呢?
使用table.get_column_values_with_name(列名),可以得到对应列的每个值组成的可迭代对象,然后使用for循环依次遍历
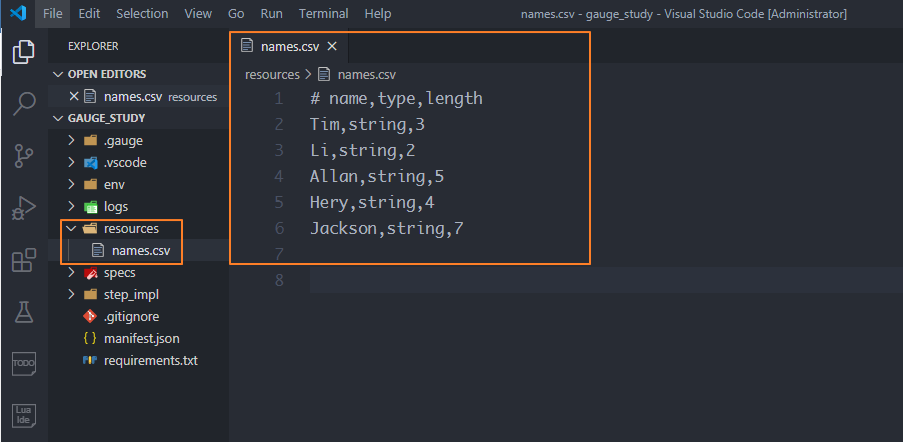
02 CSV文件
在gauge_study项目下新建一个resources目录,用来存放csv文件,可以定义一个names.csv文件,存放我们的测试数据
接着在描述文件name.spec中添加描述,和表格一样要设置场景和步骤,然后需要在步骤描述里加一个csv文件地址的引用<table:resources/names.csv>
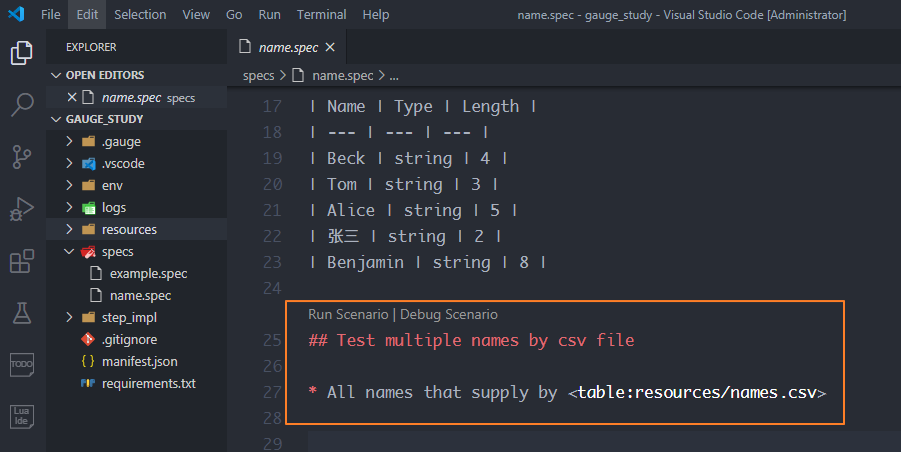
最后在name_impl.py中实现csv数据的描述步骤,创建一个方法test_all_names_by_csv_file,加装饰器@step,参数就是描述的一部分"All names that supply by <table>"。
这里需要注意的是:
table表示csv对象,对table进行遍历得到的是每一行的数据,比如第一行的 ["Beck", "string", "4"],将这个可迭代对象的元素进行分解,依次赋值给name, type, length,就拿到了csv文件中的每一个值
06 运行
到此为止,我们自己写了4条用例,一起来总结下:
| 用例 | 方法 | 数据存放位置 | 备注 |
| 测试单个名字的类型 | test_name_type(name, type) | 描述文件name.spec | |
| 测试单个名字的长度 | test_name_length(name, type) | 描述文件name.spec | |
| 测试多个名字的类型和长度(表格) | test_all_names_by_table(table) | 描述文件name.spec | table.get_column_values_with_name(列名)的使用 |
| 测试多个名字的类型和长度(csv文件) | test_all_names_by_csv_file(table) | resources目录下的names.csv | 1.描述文件中csv路径的引用 2.遍历table得到每一行的数据 |
怎么运行这些用例?
-
gauge提供了很多方法,包括:批量运行所有的spec文件,运行特定的spec文件,运行特定的spec文件下特定的scenario
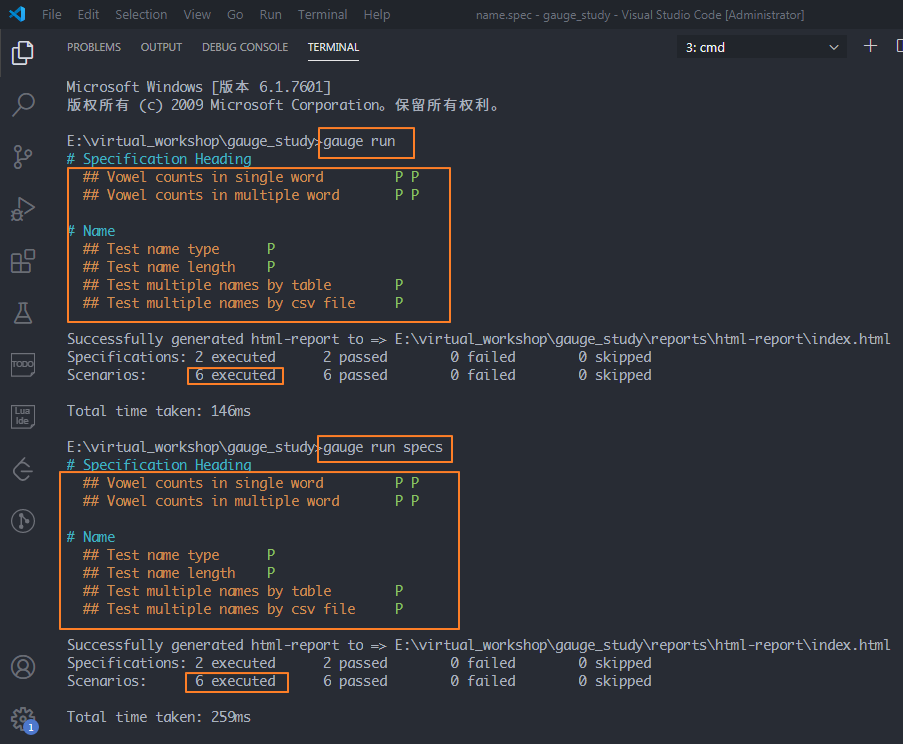
1、运行所有的spec文件
方法:gauge run
或 gauge run specs
为什么这里有6条用例呢?
因为它把官方的样例也运行了,所以多了2条出来
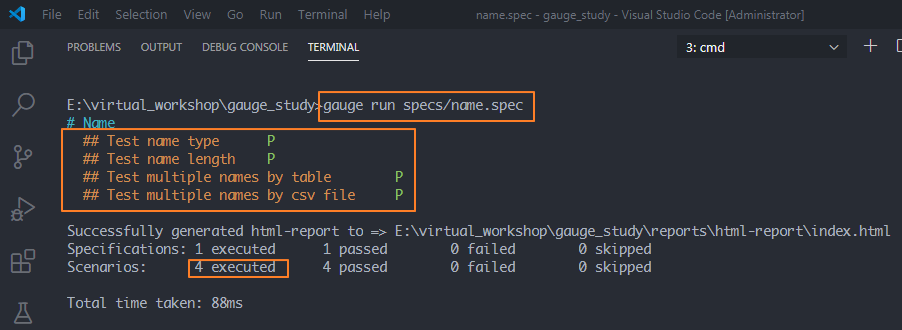
2、运行特定的spec文件
如果只想运行name.spec下的4条用例,需要加上指定的spec文件名
方法:gauge run specs/name.spec
可以看到只运行了4条用例
3、运行特定的spec文件下的特定的scenario
name.spec下有个4个场景,对应4个用例,如果此时只想运行其中一个场景,比如说读取表格数据的那个场景,这时候应该怎么写呢?
方法:gauge run specs/name.spec:13
这个13是什么?
实际上是name.spec文件中对应场景的行号
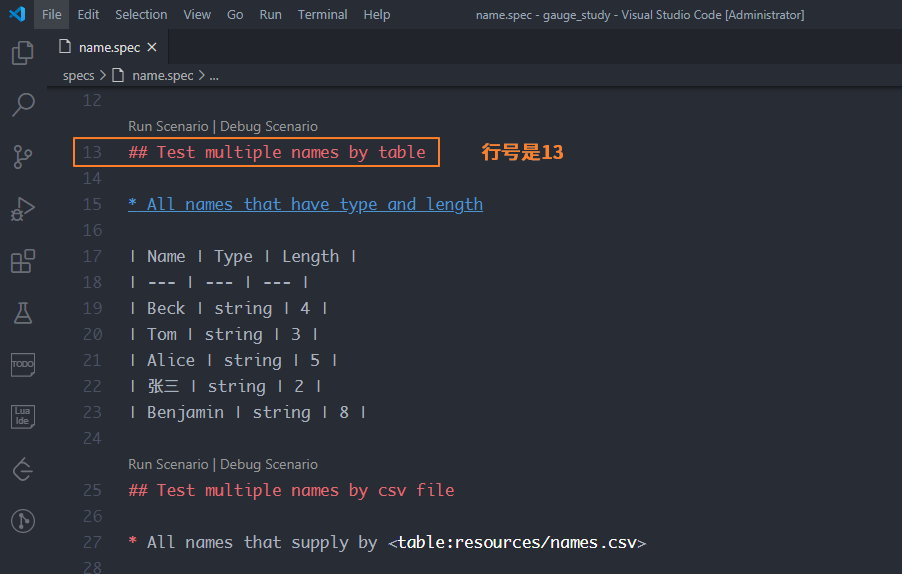
可以看到,只运行了一个场景Test multiple names by table
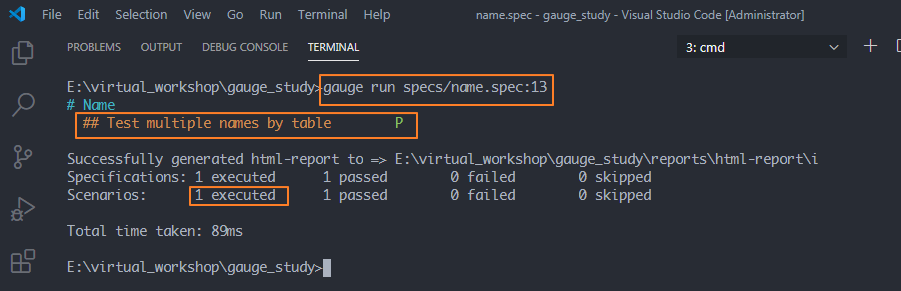
07 测试报告
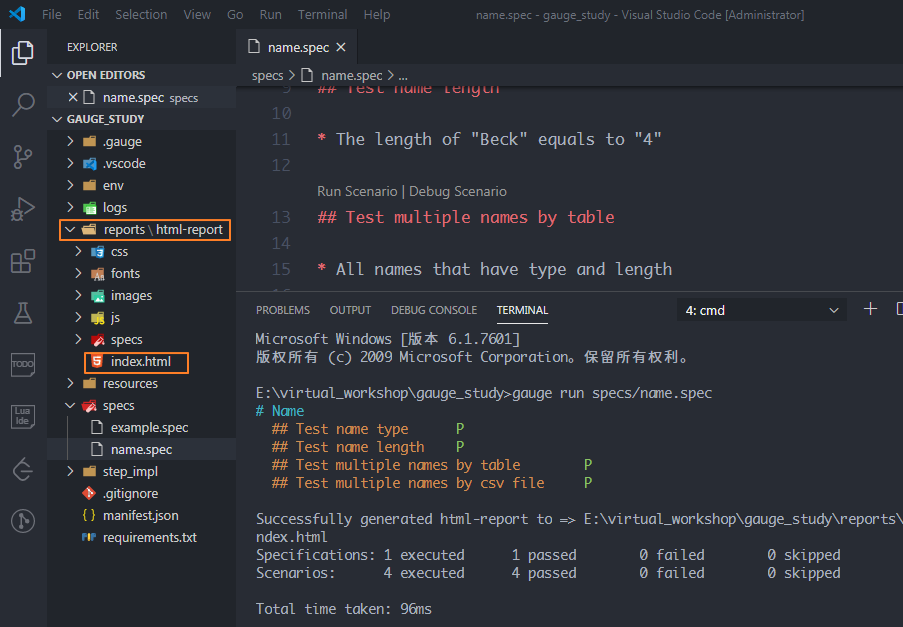
运行之后,会自动生成一个reports目录,index.html就是最终的测试报告,其相对路径是:reports/html-report/index.html
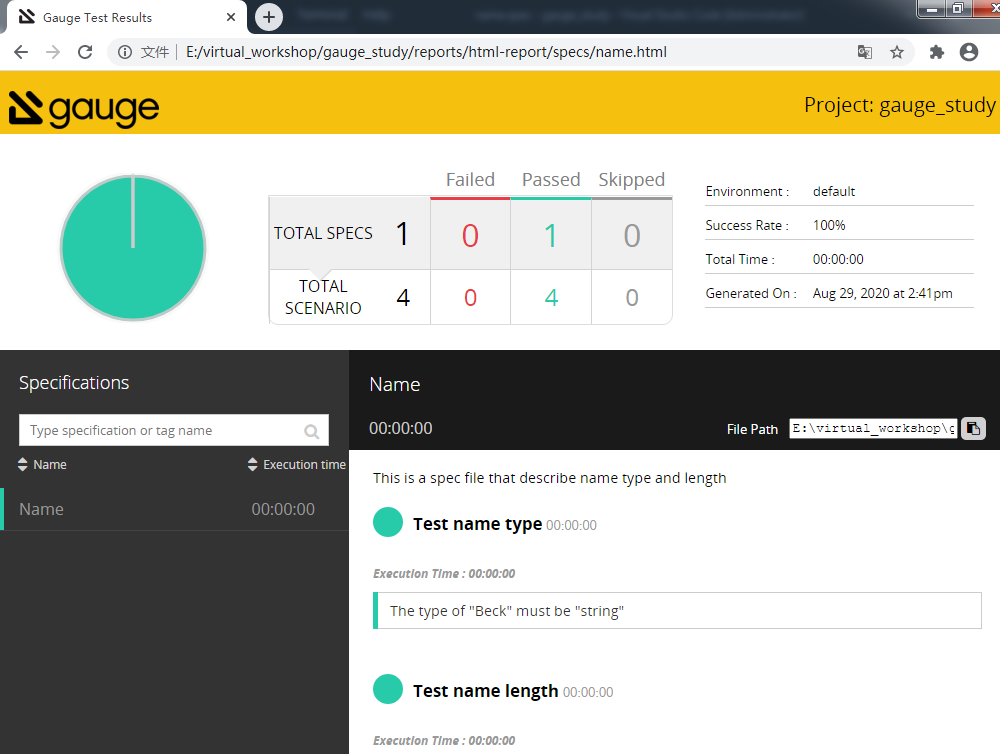
使用浏览器打开报告,感觉"颜值"还可以,这里都运行成功了。怎么样?这样方便快捷的BDD自动化测试框架你不打算试一下?
既然看到这里,希望点赞收藏支持一下!期待 ~
![]()
最后感谢每一个认真阅读我文章的人,下方这份完整的软件测试教程已经整理上传完成,需要的朋友们可以文末自行领取:【保证100%免费】

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!