本文档旨在详细阐述当前主流的大模型技术架构如Transformer架构。我们将从技术概述、架构介绍到具体模型实现等多个角度进行讲解。通过本文档,我们期望为读者提供一个全面的理解,帮助大家掌握大模型的工作原理,增强与客户沟通的技术基础。本文档适合对大模型感兴趣的人员阅读。
论文介绍
论文名称:《Attention is all you need》
**发布时间:**2017/06/12
**发布单位:**Google、多伦多大学
**简单摘要:**所有LLM的始祖,迈向NLP新时代的基础架构
**中文摘要:**传统的序列转换模型使用复杂的循环或卷积神经网络,包括编码器和解码器。表现最好的模型会透过注意力机制连接编码器和解码器。
作者团队提出了一种新的简单网络结构,Transformer,完全基于注意力机制,不再使用循环和卷积。
在两个机器翻译任务上进行实验,发现这些模型在质量上的表现优越,并且更容易进行平行运算,训练所需时间明显减少。
该模型在WMT 2014年英德翻译任务上达到了28.4 BLEU,比现有最佳结果(包括整体模型)提高了超过2 BLEU。在WMT 2014年英法翻译任务中,模型在八个GPU上训练3.5天后,取得了新的单模型最佳BLEU分数41.8,训练成本仅为文献中最佳模型的一小部分。
展示出无论是在大量或有限的训练数据下,Transformer在其他任务中的泛化能力,成功应用于英语组成句分析。
**核心技术:**模型架构(此处先留下大体印象 encode+decode)
LLM 浅谈
很多人认为大模型可以直接回答问题或参与对话,但实际上,它们的核心功能是根据输入的文本预测下一个可能出现的词汇,即“Token”。这种预测能力使得LLM在各种应用中表现出色,包括但不限于:
文本生成:LLM可以生成连贯且有意义的文本段落,用于写作辅助、内容创作等。
问答系统:通过理解问题的上下文,LLM能够生成准确的回答,广泛应用于智能客服和信息检索。
翻译:LLM可以根据上下文进行高质量的语言翻译,支持多语言交流。
文本摘要:LLM能够提取长文档的关键内容,生成简洁的摘要,方便快速理解。
对话系统:LLM可以模拟人类对话,提供自然流畅的互动体验,应用于聊天机器人和虚拟助手。
通过理解Token的概念,我们可以更好地掌握LLM的工作原理及其在实际应用中的强大能力。
Token
样例
谈到 token,不得不提到近期一个大模型被揪出来的低级错误“Strawberry里有几个 r”。

嘲笑之后,大家也冷静了下来,开始思考:低级错误背后的本质是什么?
大家普遍认为,是 Token 化(Tokenization)的锅。
在国内,Tokenization 经常被翻译成「分词」。这个翻译有一定的误导性,因为 Tokenization 里的 token 指的未必是词,也可以是标点符号、数字或者某个单词的一部分。比如,在 OpenAI 提供的一个工具中,我们可以看到,Strawberry 这个单词就被分为了 Str-aw-berry 三个 token。在这种情况下,你让 AI 大模型数单词里有几个 r,属实是为难它。
为了让大家直观地看到大模型眼里的文字世界,Karpathy特地写了一个小程序,用表情符号(emoji)来表示 token。
尝试
Token 是 LLM 理解的文本基本单位。虽然将 Token 看作单词很方便,但对 LLM 来说,目标是尽可能高效地编码文本。所以在许多情况下,Token 代表的字符序列比整个单词都要短或长。标点符号和空格也被表示为 Token,可能是单独或与其他字符组合表示。LLM 词汇中的每个 Token 都有一个唯一的标识符,通常是一个数字。LLM 使用分词器在常规文本字符串和等效的 Token 数列表之间进行转换。
import tiktoken # 获取适用于 GPT-2 模型的编码器encoding = tiktoken.encoding_for_model("gpt-2") # 编码示例句子encoded_text = encoding.encode(“A journey of a thousand miles begins with a single step.”)print(encoded_text) # 解码回原始文本decoded_text = encoding.decode(encoded_text)print(decoded_text) # 单个 token 的编码与解码print(encoding.decode([32])) # 'A’print(encoding.decode([7002])) # ' journey'print(encoding.decode([286])) # ‘of’ # 编码单词 "Payment"payment_encoded = encoding.encode("thousand")print(payment_encoded) # 解码 “Payment” 的编码结果print(encoding.decode([400])) # 'th'print(encoding.decode([29910])) # ‘ousand’ [32, 7002, 286, 257, 7319, 4608, 6140, 351, 257, 2060, 2239, 13]A journey of a thousand miles begins with a single step.A journey of[400, 29910]th``ousand
预测下一个 Token
如上所述,给定一段文本,语言模型的任务是预测接下来的一个 Token。如果用 Python 伪代码来表示,这看起来就像这样:
predictions = predict_next_token([‘A’, ‘journey’, ‘of’, ‘a’])
这里predict_next_token 函数接收一个由用户提供的提示词转换成的一系列输入 Token。在本例中,我们假设每个单词都构成一个单独的 Token。实际上,每个 Token 都会被编码为一个数字,而非直接以文本形式传入模型。函数的输出是一个数据结构,其中包含了词汇表中每一个可能的 Token 出现在当前输入序列之后的概率值。
语言模型需要通过一个训练过程来学会做出这样的预测。训练过程中,模型会接触到大量的文本数据,从中学习语言模式和规则。训练完成后,模型就能够利用所学知识来估计任何给定 Token 序列之后可能出现的下一个 Token 的概率。
要生成连续的文本,模型需要反复调用自身,每次生成一个新的 Token 并将其加入到已有的序列中,直至达到预设的长度。下面是一段更详尽的 Python 伪代码,展示了这一过程:
def generate_text(prompt, num_tokens, hyperparameters): tokens = tokenize(prompt) # 将提示转换为 Token 列表 for _ in range(num_tokens): # 根据指定的 Token 数量重复执行 predictions = predict_next_token(tokens) # 获取下一个 Token 的预测 next_token = select_next_token(predictions, hyperparameters) # 根据概率选择下一个 Token tokens.append(next_token) # 将选中的 Token 添加到列表中 return ‘’.join(tokens) # 将 Token 列表合并为字符串 # 辅助函数用于选择下一个 Token``def select_next_token(predictions, hyperparameters): # 使用温度(temperature)、top-k 或 top-p 等策略调整 Token 选择 # 实现细节取决于具体的超参数设置 pass
在这段代码中,`generate_text` 函数接受一个提示字符串、生成 Token 的数量以及一组超参数作为输入。`tokenize` 函数负责将提示转换成 Token 列表,而 `select_next_token` 函数则根据预测的概率分布选择下一个 Token。通过调整 `select_next_token` 中的超参数,比如温度(temperature)、top-k 和 top-p,可以控制生成文本的多样性和创造性。随着循环的不断迭代,新的 Token 不断被添加到序列中,最终形成了连贯的文本输出。
模型训练
想象一下,我们要培养一个模型来预测句子中的下一个词。这就像是玩一个猜词游戏,模型需要根据已经出现的词来猜测下一个词。简化的词汇表,我们假设只有五个词:
[‘I’,‘you’,‘love’,‘oranges’,‘grapes’]
我们不考虑空格和标点,只关注这些词。
我们有三句话作为训练数据:
-
I love oranges
-
I love grapes
-
you love oranges
我们可以想象一个5x5的表格,表格中的每个格子代表一个词后面跟着另一个词的次数。这个表格可能看起来像这样:
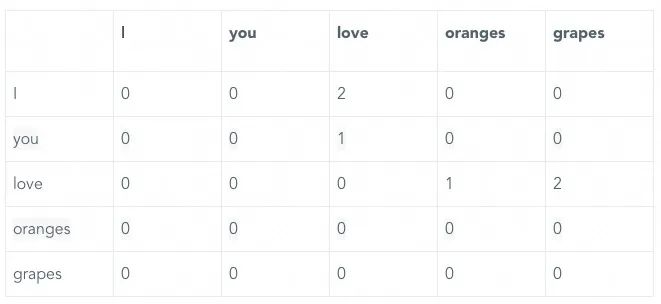
在这个例子中,“I”后面跟着“love”两次,而“love”后面跟着“oranges”一次,跟着“grapes”两次。为了使这个表格有用,我们需要将这些次数转换成概率,这样模型就可以预测下一个词的可能性。例如,“love”后面跟着“oranges”的概率是 1/3(大约33.3%),而跟着“grapes”的概率是 2/3(大约66.7%)。
但是,我们遇到了一个问题:“oranges”和“grapes”没有出现在其他词后面。这意味着,如果没有其他信息,模型将无法预测这两个词后面可能是什么。为了解决这个问题,我们可以假设每个词后面都可能跟着词汇表中的任何其他词,尽管这并不完美,但它确保了模型即使在训练数据有限的情况下也能做出预测。
在现实世界中,大型语言模型(LLM)使用了大量的训练数据,这减少了这种“漏洞”出现的机会。然而,由于某些词的组合在训练数据中出现得较少,LLM可能在某些情况下表现不佳,导致生成的文本虽然语法上正确,但逻辑上可能存在错误或不一致。这种现象有时被称为“模型幻觉”。
上下文窗口
在之前的讨论中,我们提到使用马尔可夫链训练小模型的方法,这种方法的局限在于它只依赖最后一个 Token 来预测下一个 Token。这意味着,任何出现在最后一个 Token 之前的文本都不会影响预测结果,因此这种解决方案的上下文窗口非常小,只有一个 Token。由于上下文窗口过小,模型容易“忘记”先前的信息,导致生成的文本缺乏一致性,从一个词跳跃到另一个词。
改进上下文窗口
为了提高模型的预测质量,可以尝试增加上下文窗口的大小。例如,如果使用两个 Token 的上下文窗口,就需要构建一个更大的概率矩阵,其中每一行代表所有可能的两个 Token 序列。对于五个 Token 的词汇表,这将新增 25 行(5^2)。在每次调用 predict_next_token() 函数时,将使用输入的最后两个 Token 来查找概率表中的对应行。
然而,即使使用两个 Token 的上下文窗口,生成的文本仍可能缺乏连贯性。为了生成更加一致且有意义的文本,需要进一步增加上下文窗口的大小。例如,将上下文窗口增加到三个 Token 将使概率表的行数增加到 125 行(5^3),但这仍然不足以生成高质量的文本。
随着上下文窗口的增大,概率表的大小呈指数级增长。以 GPT-2 模型为例,它使用了 1024 个 Token 的上下文窗口。如果按上文中使用马尔可夫链来实现这样一个大的上下文窗口,每行概率表都需要代表一个长度在 1 到 1024 个 Token 之间的序列。对于一个包含 5 个 Token 的词汇表,可能的序列数量为 5^1024,这是一个天文数字。这个数字太大了,以至于无法实际存储和处理如此庞大的概率表。因此,马尔可夫链在处理大规模上下文窗口时存在严重的可扩展性问题。
从马尔可夫链到神经网络
显然,使用概率表的方法在处理大规模上下文窗口时不可行。我们需要一种更高效的方法来预测下一个 Token。这就是神经网络发挥作用的地方。神经网络是一种特殊的函数,它可以接受输入数据,对其进行一系列计算,然后输出预测结果。对于语言模型而言,输入是一系列 Token,输出是下一个 Token 的概率分布。
神经网络的关键在于其参数。这些参数在训练过程中逐渐调整,以优化模型的预测性能。训练过程涉及大量的数学运算,包括前向传播和反向传播。前向传播是指输入数据通过网络的各个层进行计算,生成预测结果;反向传播则是根据预测结果与真实标签之间的差异,调整网络的参数,以减小误差。
现代语言模型,如 GPT-2、GPT-3 和 GPT-4,使用了非常深的神经网络,拥有数亿甚至数万亿的参数。这些模型的训练过程非常复杂,通常需要数周甚至数月的时间。尽管如此,训练有素的 LLM 能够在生成文本时保持较高的连贯性和一致性,这得益于其强大的上下文理解和生成能力。
Transformer 和注意力机制
Transformer 是目前最流行的神经网络架构之一,特别适用于自然语言处理任务。Transformer 模型的核心特点是其注意力机制。注意力机制允许模型在处理输入序列时,动态地关注序列中的不同部分,从而更好地捕捉上下文信息。
注意力机制最初应用于机器翻译任务,目的是帮助模型识别输入序列中的关键信息。通过注意力机制,模型可以“关注”输入序列中的重要 Token,从而生成更准确的翻译结果。在语言生成任务中,注意力机制同样发挥了重要作用,使得模型能够在生成下一个 Token 时,综合考虑上下文窗口中的多个 Token,从而生成更加连贯和有意义的文本。
总结来说,虽然马尔可夫链提供了一种简单的文本生成方法,但其在处理大规模上下文窗口时存在明显的局限性。现代语言模型通过使用神经网络和注意力机制,克服了这些局限性,实现了高效且高质量的文本生成。
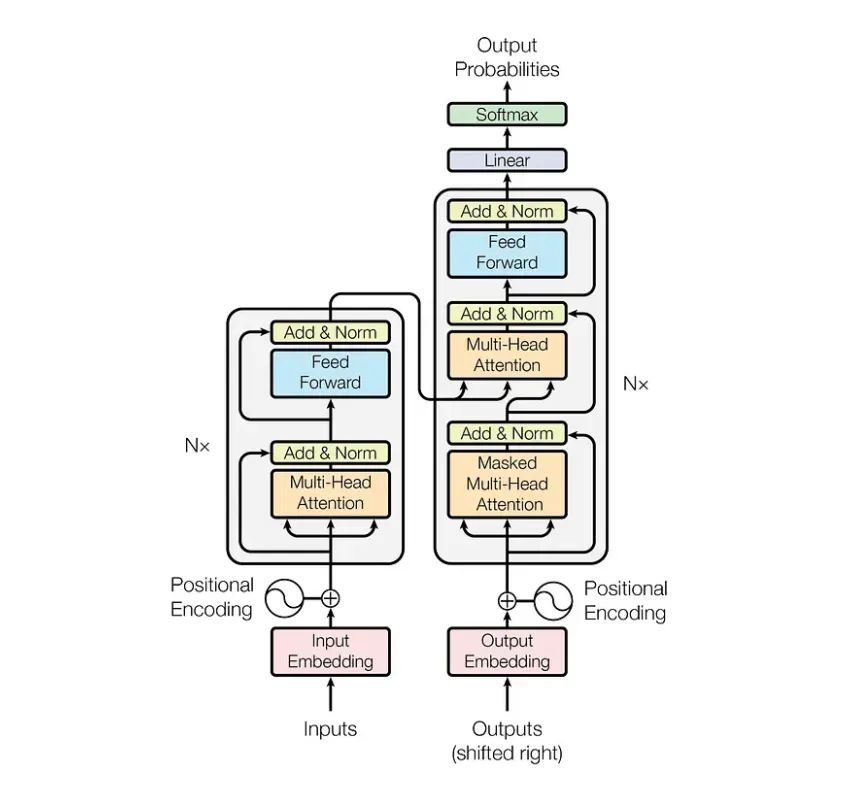
Transformer 的输入
回到框架图,Transformer中单词的输入表示x由单词Embedding和位置Embedding (Positional Encoding)相加得到。
单词的 Embedding 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到。
Transformer 中除了单词的 Embedding,还需要使用位置 Embedding 表示单词出现在句子中的位置。**因为 Transformer 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于 NLP 来说非常重要。**所以 Transformer 中使用位置 Embedding 保存单词在序列中的相对或绝对位置。
简而言之:以苹果为例
“水果店里有苹果,香蕉”中苹果代指水果,“商店里最新推出了苹果 16”中苹果代表品牌
Self-Attention(自注意力机制)
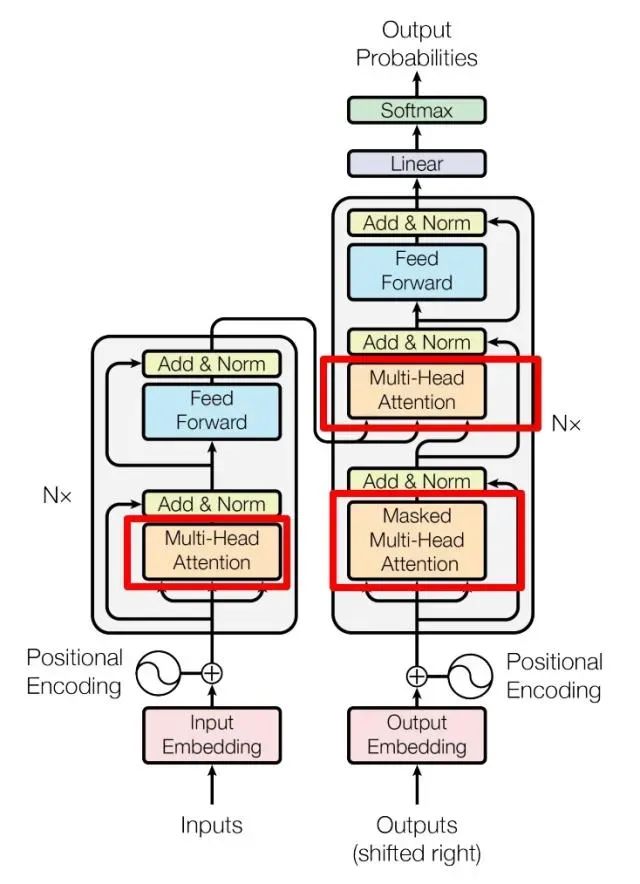
上图是论文中 Transformer 的内部结构图,左侧为 Encoder block,右侧为 Decoder block。红色圈中的部分为 Multi-Head Attention,是由多个 Self-Attention组成的,可以看到 Encoder block 包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)。Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
因为 Self-Attention是 Transformer 的重点,所以我们重点关注 Multi-Head Attention 以及 Self-Attention,首先详细了解一下 Self-Attention 的内部逻辑。
当然,我们可以用更简洁的方式来理解Self-Attention机制。
Self-Attention 简介
Self-Attention 是一种允许模型在处理序列数据时关注不同部分的方法,特别适用于处理长文本。它通过计算序列中每个元素与其他所有元素之间的相关性来实现这一点。
工作流程
- 转换:
- 每个输入元素(比如一个词)都会被转换成三个向量:Query (查询)、Key (键) 和 Value (值)。这些向量是通过将输入向量分别乘以三个不同的权重矩阵WQ、WK 和 WV 得到的。
- 计算注意力分数:
- 对于每个元素,使用它的 Query 向量与所有其他元素的 Key 向量进行点积运算,得到一个分数列表。这个分数表示当前元素与其他所有元素的相关性。
- 归一化:
- 将这些分数通过 softmax 函数进行归一化,得到一个概率分布,表示当前元素对其他所有元素的注意力权重。
- 加权求和:
- 使用这些注意力权重对所有元素的 Value 向量进行加权求和,得到最终的输出向量。
公式
假设输入序列为 X=[x1,x2,…,xn]X,每个 xi 都是一个向量。
-
转换:
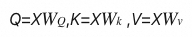
-
计算注意力分数:
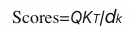 其中 dk 是 Key 向量的维度。
其中 dk 是 Key 向量的维度。 -
归一化:
Attention Weights=softmax(Scores)
-
加权求和:Output=Attention Weights⋅V
Multi-Head Attention
- 多头注意力(Multi-Head Attention)是为了让模型从多个不同的角度捕捉信息。具体做法是并行运行多个Self-Attention层(每个称为一个“头”),然后将所有头的输出拼接在一起,再通过一个线性变换。
总结
-
Self-Attention 让模型能够关注序列中的不同部分,从而更好地捕捉长距离依赖关系。
-
Multi-Head Attention 通过多个Self-Attention层增强模型的表达能力,使其能够从多个角度综合考虑信息。
Add & Norm 和 Feed Forward
Add & Norm (残差连接与层归一化)
残差连接 (Residual Connection)
-
**作用:**帮助模型更好地学习,防止训练过程中信息丢失。
-
**方法:**把输入直接加到输出上。
层归一化 (Layer Normalization)
-
**作用:**让数据更稳定,加快训练速度。
-
**方法:**把每个样本的特征值调整到一个标准范围内,通常是平均值为0,标准差为1。
结合使用
- 步骤:
-
先计算某一层的输出 F(x)F(x)。
-
把输入 xx 加到 F(x)F(x) 上,得到 y=F(x)+xy=F(x)+x。
-
对 yy 进行层归一化,得到最终的输出。
Feed Forward (前馈神经网络)
作用
- **增加非线性:**让模型更灵活,能处理更复杂的数据。
结构
- 两层全连接网络:
-
第一层:把输入通过一个线性变换(乘以一个矩阵),然后用 ReLU 激活函数处理。
-
第二层:再通过一个线性变换(乘以另一个矩阵)。
总结
-
**Add & Norm:**通过残差连接和层归一化,让模型更稳定,训练更快。
-
**Feed Forward:**通过两层全连接网络增加模型的灵活性,使其能处理更复杂的数据。
Decoder 结构
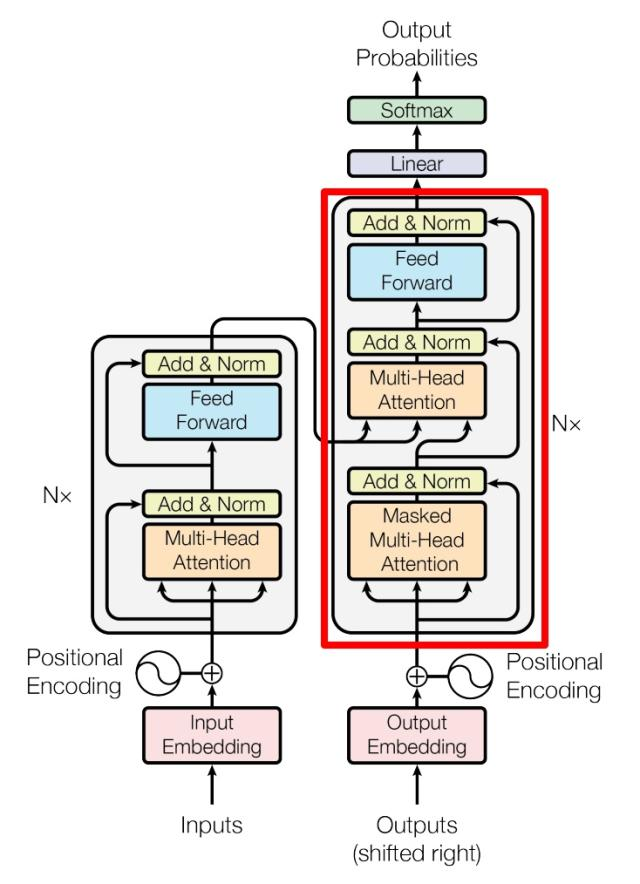
上图红色部分为 Transformer 的 Decoder block 结构,与 Encoder block 相似,但是存在一些区别:
-
包含两个 Multi-Head Attention 层。
-
第一个 Multi-Head Attention 层采用了 Masked 操作。
-
第二个 Multi-Head Attention 层的K, V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。
-
最后由一个 Softmax 层计算下一个翻译单词的概率。

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓