文章目录
- 第6章 Directory
- 6.1 Directory介绍
- 6.1.1 FSDirectory
- 1)SimpleFSDirectory:
- 2)NIOFSDirectory:
- 3)MMapDirectory:
- 4)FSDirectory子类对比
- 6.2.2 RAMDirectory
- 6.2 Directory性能测试环境搭建
- 6.2.1 数据库环境准备
- 6.2.2 项目环境准备
- 6.2.3 测试环境准备
- 6.2.4 JVM参数控制
- 1)JVM内存划分
- 2)JVM参数说明
- 3)指定内存参数
- 6.3 Directory性能测试
- 6.3.1 数据准备
- 6.3.2 400W数据查询测试
- 1)Windows平台
- 2)Linux平台
- 6.3.3 并发查询测试
- 1)Windows平台
- 2)Linux平台
第6章 Directory
6.1 Directory介绍
Lucene使用Directory来关联一个目录用于存储索引文件,Directory为存储文件列表提供了一个抽象层;其子类非常丰富,不同的子类底层采用的IO模型不同,达到的性能也不一样。Directory将决定Luceen底层采用什么方式将数据写入到磁盘,是影响Lucene性能的一大关键;
Directory下面子类实现共有三大类:
- FSDirectory:用于在文件系统中存储索引文件的Directory实现的基类。
- RAMDirectory:基于内存的目录实现,但不适用于大型索引
- FilterDirectory:用于在其他类型的Directory上添加限制,或为测试添加额外的健全性检查;
Tips:FilterDirectory仅用于内部目的,在下一版本中可能会以不兼容的方式进行更改
不同的Directory底层对于如何存实现索引具有不同的功能,性能上也有很大的差异
6.1.1 FSDirectory
用于在文件系统中存储索引文件的Directory实现的基类。目前有三个核心子类:
1)SimpleFSDirectory:
SimpleFSDirectory底层采用RandomAccessile来完成索引操作,SimpleFSDirectory并发性能很差(多个线程将成为瓶颈),因为当多个线程从同一个文件读取时,它是同步的,通常使用NIOFSDirectory或MMapDirectory会更好。
Lucene中的SimpleFSDirectory底层是通过使用Java的文件系统API来实现的。具体实现方式如下:
- SimpleFSDirectory类继承自FSDirectory类,FSDirectory类封装了文件系统的基本操作,包括打开、关闭、读取文件等。
- SimpleFSDirectory类使用了Java文件系统API中的FileInputStream和FileOutputStream来实现文件的读取和写入。
- 在SimpleFSDirectory的构造函数中,会打开一个文件,并创建一个FileInputStream对象。
- 在SimpleFSDirectory的写入操作中,会将数据写入到FileOutputStream中的缓冲区,并使用FileOutputStream的flush()方法将缓冲区中的数据刷新到磁盘上。
- 在SimpleFSDirectory的读取操作中,会使用FileInputStream从文件中读取数据,并返回读取的数据。
- 在SimpleFSDirectory的关闭操作中,会关闭FileInputStream和FileOutputStream对象,释放资源。
总之,SimpleFSDirectory底层的实现是使用Java的文件系统API来实现文件的读取和写入操作。这种方式比较简单,但可能不如NIOFSDirectory的方式效率高。
2)NIOFSDirectory:
NIOFSDirectory底层采用Java中的NIO来解决索引文件并发能力的。它允许多个线程在不同步的情况下从同一个文件读取,但不幸的是,在Windows平台下由于Sun的JRE错误,NIOFSDirectory的性能并非很出色(FileChannel在windows下是同步操作),NIOFSDirectory这对于Windows来说是一个糟糕的选择,但在所有其他平台上这是首选。
Lucene中的NIOFSDirectory类底层是通过使用Java的NIO文件系统API来实现的。具体实现方式如下:
- NIOFSDirectory类继承自FSDirectory类,FSDirectory类封装了文件系统的基本操作,包括打开、关闭、读取文件等。
- NIOFSDirectory类使用了Java NIO文件系统API中的FileChannel类和MMapByteBuffer类来实现文件的读取和写入。
- 在NIOFSDirectory的构造函数中,会打开一个文件,并创建一个FileChannel对象。
- 在NIOFSDirectory的写入操作中,会将数据写入到FileChannel中的缓冲区,并使用FileChannel的force()方法将缓冲区中的数据刷新到磁盘上。
- 在NIOFSDirectory的读取操作中,会使用FileChannel的read()方法从文件中读取数据,并读取到MMapByteBuffer中的缓冲区中。
- 在NIOFSDirectory的关闭操作中,会关闭FileChannel和MMapByteBuffer对象,释放资源。
此外如果一个访问该类的线程,在IO阻塞时被interrupt或cancel,将会导致底层的文件描述符被关闭,后续的线程再次访问NIOFSDirectory时将会出现ClosedChannelException异常,此种情况应用SimpleFSDirectory代替。
Tips:NIOFSDirectory在Windows操作系统的性能比较差,甚至可能比SimpleFSDirecory的性能还差。
3)MMapDirectory:
MMapDirectory在读取时使用内存映射IO,不需要采取锁机制,并能很好的支持多线程读操作。如果您有足够的虚拟内存,这是一个不错的选择
具体来说,MMapDirectory底层会使用操作系统提供的系统调用来创建一个内存映射文件,将文件映射到进程的虚拟地址空间中。这样,进程就可以直接访问这个文件,而不需要通过读写文件的操作来访问。通过使用内存映射文件技术,可以提供高效的文件访问方式,同时避免了频繁的磁盘I/O操作,提高了程序的性能和效率。
MMapDirectory的具体实现方式如下:
- 通过操作系统提供的内存映射文件(Memory Mapping)功能,将索引文件映射到进程的虚拟地址空间中。
- Lucene对索引文件的访问,不再是通过读写文件的方式,而是直接访问内存中的数据。
- 当需要对索引进行修改时,MMapDirectory会使用操作系统提供的内存映射文件(Memory Mapping)功能,将新的数据写回到磁盘上的索引文件中。
Tips:由于Sun的JRE中的这个错误,MMapDirectory的IndexInput.close()无法关闭底层操作系统文件句柄。只有当GC最终收集底层对象时(这可能需要相当长的一段时间),文件句柄才会关闭。这将消耗额外的临时磁盘使用,并且可能会消耗很长的时间
关于内存映射:内存映射是一种常见的操作系统技术,它允许程序将磁盘文件映射到进程的地址空间中,从而使得程序可以像访问内存一样访问文件。这种技术可以极大地简化文件的读写操作,并且可以提高程序的性能。
4)FSDirectory子类对比
| 类名 | 读操作 | 写操作 | 特点 |
|---|---|---|---|
| SimpleFSDirectory | java.io.RandomAccessFile | java.io.RandomAccessFile | 简单实现,并发能力差 |
| NIOFSDirectory | java.nio.FileChannel | FSDirectory.FSIndexOutput | 并发能力强 |
| MMapDirectory | 内存映射 | FSDirectory.FSIndexOutput | 读取操作基于内存 |
对于FSDirectory的最佳子类的使用,直接采用FSDirectory的open方法Lucene将根据当前系统环境自动选择最佳的FSDirectory实现,如没有定制化要求,最好使用open方法来获取FSDirectory最佳实现;
- FSDirectory的获取:
@Test
public void test1() throws Exception {FSDirectory dir1 = FSDirectory.open(Paths.get("D:/index"));FSDirectory dir2 = MMapDirectory.open(Paths.get("D:/index"));FSDirectory dir3 = SimpleFSDirectory.open(Paths.get("D:/index"));FSDirectory dir4 = NIOFSDirectory.open(Paths.get("D:/index"));// 在windows平台中,不管是哪种方式获取FSDirectory都将返回MMapDirectorySystem.out.println(dir1.getClass()); // class org.apache.lucene.store.MMapDirectorySystem.out.println(dir2.getClass()); // class org.apache.lucene.store.MMapDirectorySystem.out.println(dir3.getClass()); // class org.apache.lucene.store.MMapDirectorySystem.out.println(dir4.getClass()); // class org.apache.lucene.store.MMapDirectory
}
如果想要指定不同的FSDirectory,可以使用new关键字来创建对应的实例:
@Test
public void test2() throws Exception {FSDirectory dir1 = new MMapDirectory(Paths.get("D:/index"));FSDirectory dir2 = new SimpleFSDirectory(Paths.get("D:/index"));FSDirectory dir3 = new NIOFSDirectory(Paths.get("D:/index"));System.out.println(dir1.getClass()); // class org.apache.lucene.store.MMapDirectorySystem.out.println(dir2.getClass()); // class org.apache.lucene.store.SimpleFSDirectorySystem.out.println(dir3.getClass()); // class org.apache.lucene.store.NIOFSDirectory
}
6.2.2 RAMDirectory
RAMDirectory将数据存储在内存中,该类针对小型内存驻留索引进行了优化,但不适合大量索引的情况。因为它使用1024字节的内部缓冲区大小,在数据量非常大的情况下,内部将会频繁创建字节数组,性能较低,另外也不适用于多线程的情况。在索引数据量大的情况下建议使用MMapDirectory代替。
Tips:小型的系统推荐使用,如果大型的,索引文件达到G级别上,推荐使用FSDirectory。
RAMDirectory的底层实现是基于内存的。它通过将所有的索引文件加载到内存中,从而加快索引和查询的速度。具体实现方式如下:
- RAMDirectory使用一个HashMap来存储所有的文件和相应的读写器。
- 当需要添加一个文件时,RAMDirectory会创建一个RandomAccessFile对象,并将文件数据读取到内存中。
- 当需要查询一个文件时,RAMDirectory会根据文件的名称或ID在HashMap中查找对应的读写器,并返回该读写器对应的文件数据。
- 当需要删除一个文件时,RAMDirectory会关闭相应的读写器并从HashMap中删除该文件的数据。
- 当需要更新一个文件时,RAMDirectory会更新相应的读写器并重新写入文件数据到内存中。
RAMDirectory的底层实现是通过内存缓存来加速索引和查询的操作,适用于临时索引或小型的索引。在实际应用中,可以根据需要选择不同的目录实现,以满足不同的需求。
6.2 Directory性能测试环境搭建
6.2.1 数据库环境准备
1)准备测试表:
DROP TABLE IF EXISTS `goods`;
CREATE TABLE `goods` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '商品名称',`title` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '标题',`price` decimal(10, 2) NULL DEFAULT NULL COMMENT '价格',`pic` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '图片',PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 36 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = DYNAMIC;
2)创建存储过程:
创建存储过程用于模拟查询数据
create procedure test_insert(count int)
begindeclare i int default 1;while i<=count do INSERT INTO goods values(i, -- id'huawei shouji', -- name'huawei 5g zhineng youxi shouji', -- titleleft(RAND()*10000,7), -- priceuuid() -- pic);set i=i+1;end while;
end;
6.2.2 项目环境准备
- 1)引入依赖
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.0.1.RELEASE</version></parent><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.1</version></dependency><!--Lucene核心包--><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-analyzers-common</artifactId><version>8.0.0</version></dependency><!--lucene高亮查询依赖--><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-highlighter</artifactId><version>8.0.0</version></dependency><!--IK分词器--><dependency><groupId>com.github.magese</groupId><artifactId>ik-analyzer</artifactId><version>8.0.0</version></dependency><!--MySQL驱动--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.47</version></dependency><!--lombok--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.18</version></dependency></dependencies><build><plugins><!--SpringBoot打包插件--><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>1.4.2.RELEASE</version></plugin></plugins></build>- 2)实体类:
package com.dfbz.entity;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
import java.io.Serializable;/*** @author lscl* @version 1.0* @intro:*/
@Entity
@Table(name = "goods")@AllArgsConstructor
@NoArgsConstructor
@Data
public class Goods implements Serializable {@Idprivate Integer id;@Columnprivate String name;@Columnprivate String title;@Columnprivate Double price;@Columnprivate String pic;
}
3)dao
package com.dfbz.dao;import com.dfbz.entity.Goods;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;import java.util.List;/*** @author lscl* @version 1.0* @intro:*/
@Repository
public interface GoodsDao extends JpaRepository<Goods,Integer> {
}
- yml配置文件:
spring:datasource:driver-class-name: com.mysql.jdbc.Driver# Linux地址url: jdbc:mysql://192.168.28.161:3306/test?useUnicode=true&characterEncoding=utf8# Windows地址# url: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8username: rootpassword: admin
server:port: 8080# Windows Lucene目录
luceneDir: C:/index# Linux Lucene目录
#luceneDir: /root/index
6.2.3 测试环境准备
1)插入索引
package com.dfbz.controller;import com.dfbz.dao.GoodsDao;
import com.dfbz.entity.Goods;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.*;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.*;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.wltea.analyzer.lucene.IKAnalyzer;import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;/*** @author lscl* @version 1.0* @intro:*/
@RequestMapping("/index")
@RestController
public class TestIndexOperationController {@Value("${luceneDir}")private String luceneDir;@Autowiredprivate GoodsDao goodsDao;/*** 插入模拟数据** @param type* @param page* @param size* @return* @throws Exception*/@GetMapping("/create/{type}/{page}/{size}")public String insert(@PathVariable String type, @PathVariable Integer page, @PathVariable Integer size) throws Exception {Directory dir = null;if ("simple".equals(type)) {dir = new SimpleFSDirectory(Paths.get(luceneDir));} else if ("nio".equals(type)) {dir = new NIOFSDirectory(Paths.get(luceneDir));} else if ("mmap".equals(type)) {dir = new MMapDirectory(Paths.get(luceneDir));} else if ("ram".equals(type)) {dir = new RAMDirectory();}Analyzer analyzer = new IKAnalyzer();IndexWriterConfig config = new IndexWriterConfig(analyzer);config.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);IndexWriter indexWriter = new IndexWriter(dir, config);System.out.println("开始插入【" + type + "】:");long startTime = System.currentTimeMillis();for (int i = 0; i < page; i++) {// 每次查询固定的条数Page<Goods> pageData = goodsDao.findAll(PageRequest.of(i, size));List<Goods> goodsList = pageData.getContent();List<Document> docs = new ArrayList<>();for (Goods goods : goodsList) {// 创建一篇文档Document doc = new Document();// 添加域doc.add(new StringField("id", goods.getId() + "", Field.Store.YES));doc.add(new TextField("name", goods.getName(), Field.Store.YES));doc.add(new TextField("title", goods.getTitle(), Field.Store.YES));doc.add(new DoublePoint("price", goods.getPrice()));doc.add(new StoredField("pic", goods.getPic()));docs.add(doc);}indexWriter.addDocuments(docs);System.out.println("第【" + (i + 1) + "】次插入,本次插入【" + size + "】条");}indexWriter.close();dir.close();long endTime = System.currentTimeMillis();String result = "【" + type + "】插入完毕,共插入【" + (page * size) + "】条记录,花费【" + (endTime - startTime) + "】毫秒";System.out.println(result);return result;}/*** 删除数据** @param type* @return* @throws Exception*/@GetMapping("/delete/{type}")public String insert(@PathVariable String type) throws Exception {Directory dir = null;if ("simple".equals(type)) {dir = new SimpleFSDirectory(Paths.get(luceneDir));} else if ("nio".equals(type)) {dir = new NIOFSDirectory(Paths.get(luceneDir));} else if ("mmap".equals(type)) {dir = new MMapDirectory(Paths.get(luceneDir));} else if ("ram".equals(type)) {dir = new RAMDirectory();}Analyzer analyzer = new IKAnalyzer();IndexWriterConfig config = new IndexWriterConfig(analyzer);config.setOpenMode(IndexWriterConfig.OpenMode.CREATE);IndexWriter indexWriter = new IndexWriter(dir, config);indexWriter.deleteAll();indexWriter.close();dir.close();return "ok";}
}
2)查询索引
package com.dfbz.controller;import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.*;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import java.io.IOException;
import java.nio.file.Paths;
import java.util.LinkedList;
import java.util.List;
import java.util.concurrent.CountDownLatch;/*** @author lscl* @version 1.0* @intro:*/
@RestController
@RequestMapping("/query")
public class TestQueryController {private Directory dir;private IndexReader reader;private IndexSearcher searcher;@Value("${luceneDir}")private String luceneDir;/*** 普通查询测试400W数据** @param type* @return* @throws Exception*/@GetMapping("/test_query/{type}/{dataCount}")public List<String> test_query(@PathVariable String type, @PathVariable Integer dataCount) throws Exception {System.out.println(type + "测试结果如下: ");if ("simple".equals(type)) {dir = new SimpleFSDirectory(Paths.get(luceneDir));} else if ("nio".equals(type)) {dir = new NIOFSDirectory(Paths.get(luceneDir));} else if ("mmap".equals(type)) {dir = new MMapDirectory(Paths.get(luceneDir));} else if ("ram".equals(type)) {dir = new RAMDirectory(FSDirectory.open(Paths.get(luceneDir)), IOContext.DEFAULT);}reader = DirectoryReader.open(dir);searcher = new IndexSearcher(reader);StandardAnalyzer analyzer = new StandardAnalyzer();QueryParser queryParser = new QueryParser("title", analyzer);Query query = queryParser.parse("huawei");LinkedList<String> resultInfo = new LinkedList<>();for (int i = 1; i <= 10; i++) {long startTime = System.currentTimeMillis();TopDocs topDocs = searcher.search(query, dataCount);long endTime = System.currentTimeMillis();String result = "第【" + i + "】次的查询时间为【" + (endTime - startTime) + "】";resultInfo.addLast(result);System.out.println(result);}return resultInfo;}/*** 测试并发查询 查询数据10W, 200个线程并发查询** @param type* @return* @throws Exception*/@GetMapping("/test_concurrent/{type}/{dataCount}/{threadCount}")public List<String> test_concurrent(@PathVariable String type,@PathVariable Integer dataCount,@PathVariable Integer threadCount) throws Exception {System.out.println(type + "测试结果如下: ");if ("simple".equals(type)) {dir = new SimpleFSDirectory(Paths.get(luceneDir));} else if ("nio".equals(type)) {dir = new NIOFSDirectory(Paths.get(luceneDir));} else if ("mmap".equals(type)) {dir = new MMapDirectory(Paths.get(luceneDir));} else if ("ram".equals(type)) {dir = new RAMDirectory(FSDirectory.open(Paths.get(luceneDir)), IOContext.DEFAULT);}reader = DirectoryReader.open(dir);searcher = new IndexSearcher(reader);StandardAnalyzer analyzer = new StandardAnalyzer();QueryParser queryParser = new QueryParser("title", analyzer);Query query = queryParser.parse("huawei");LinkedList<String> resultInfo = new LinkedList<>();for (int i = 1; i <= 10; i++) {List<Thread> threadList = new LinkedList<>();CountDownLatch count = new CountDownLatch(threadCount);for (int j = 0; j < threadCount; j++) {threadList.add(new Thread(() -> {try {TopDocs topDocs = searcher.search(query, dataCount);ScoreDoc[] scoreDocs = topDocs.scoreDocs;} catch (IOException exception) {exception.printStackTrace();}count.countDown();}));}long startTime = System.currentTimeMillis();for (Thread thread : threadList) {thread.start();}count.await();long endTime = System.currentTimeMillis();String result = "第【" + i + "】次的查询时间为【" + (endTime - startTime) + "】";resultInfo.addLast(result);System.out.println(result);}return resultInfo;}
}
6.2.4 JVM参数控制
1)JVM内存划分
每个 Java 程序都只能使用一定量的内存,这种限制是由于 JVM 的启动参数决定的。影响JVM内存的主要是堆内存;
堆内存包括:年轻代、老年代、永久代内存,这三块内存对JVM的性能有着重要的影响;在Jdk1.8将永久代从堆内存中独立出来了并且永久代被元空间(Metaspace)所替代,并且元空间位于本地内存中,其大小受限于可用的系统内存大小。
- Jdk1.8之前:总的堆内存=新生代+老年代+永久代
- Jdk1.8及之后:总的堆内存=新生代+老年代;
Tips:在JDK7及以前,堆内存包含了方法区,那个时候方法区的实现为永久代,到了JDK8之后,方法区从堆内存中独立了出来,并且实现方式改为了元空间;
- heap space:堆内存;
- 新生代:用于存储新创建的对象。新生代分为三个区域:Eden空间、From Survivor空间(S0)、To Survivor空间(S1)。大部分对象都会在新生代中被创建,并通过垃圾回收进行管理。新生代的特点是快速分配和回收。
- 老年代:用于存储经过多次垃圾回收后仍然存活的对象。老年代的特点是稳定性高,对象存活时间长,垃圾回收频率相对较低。
- 永久代:是方法区的实现,JDK8之后被称为元空间,用于存储类信息、常量池、方法静态变量以及时编译器编译后的代码等等。存储的内容比较稳定,但也可能因为内存溢出等问题导致性能下降。
这两个区域的最大内存大小是由 JVM 启动参数 -Xmx 和 -XX:MaxPermSize(永久代)/-XX:MaxMetaspaceSize(元数据区) 指定,如果没有指定,则会根据操作系统版本、JVM 版本和物理内存的大小来确定。
当创建新的对象时,堆内存中的空间不足以存放新创建的对象,就会引入 java.lang.OutOfMemoryError Java heap space 错误,并且只要超过了堆内存的最大限度,就会报错,和物理内存没有直接关系。
2)JVM参数说明
| 参数 | 说明 |
|---|---|
| -Xms | 指定 JVM 的初始内存大小(堆内存)。建议和 -Xmx 大小一样,防止因为内存收缩或突然增大带来的性能影响。 |
| -Xmx | 指定JVM 的最大内存大小(堆内存)。建议为物理内存的80%。 |
| -Xmn | 指定 JVM 中 NewGeneration(年轻代)的大小。这个参数很影响性能。 如果你的程序需要比较多的临时内存,建议设置到512M。 如果用的少,尽量降低这个数值,一般来说128或256足以使用了。 sun官方推荐配置为整个堆内存的3/8; |
| -XX:OldSize | 用来指定老年代的初始大小。 开发者不能直接调整Jvm老年代的最大内存,因为老年代内存的大小是由JVM自动管理的。 但是开发者可以调整Jvm的堆内存、年轻代内存、年轻代与老年代的比例来影响老年代的最大值; |
| -XX:NewRatio | 设置老年代和年轻代的比例。 |
| -XX:PermSize | 指定 JVM 中 Perm Generation(永久代)的初始值。这个参数需要看你的实际情况。可以通过 jmap 命令看看到底需要多少。 |
| -XX:MaxPermSize | 指定 Perm Generation(永久代) 的最大值。 |
| -XX:MaxMetaspaceSize | 在Java 8中,元空间的大小默认是随着可用内存的增加而增加的,因此无需手动设置其大小。 如果需要限制,可以使用该参数来设置最大元空间大小 |
| -Xss | 指定桟大小。一般来说,web框架下的应用需要256K。 如果程序中有大规模的递归行为,请考虑设置到512K或1M。 这个参数对性能的影响比较大的,在相同物理内存下,减小这个值能生成更多的线程。 |
3)指定内存参数
在Runtime类中存在有如下几个方法可以获取当前Jvm示例所占用的内存情况:
| 返回值 | 方法名 | 作用 |
|---|---|---|
| Runtime | public static getRuntime() | 获取当前进程的Runtime实例 |
| long | maxMemory() | Jvm能够从操作系统申请的最大内存,如果内存本身没有限制,则返回值Long.MAX_VALUE |
| long | totalMemory() | Jvm已经向操作系统申请的内存大小,也就是虚拟机这个进程已占用的所有内存。 |
| long | freeMemory() | 获取JVM中的空闲内存量,JVM已经占用,但实际并未使用的内存 |
- 示例代码:
package com.dfbz.demo01;import org.junit.Test;/*** @author lscl* @version 1.0* @intro:*/
public class Demo01 {@Testpublic void test1() throws Exception {// 获取Jvm最大能够使用的内存System.out.println("maxMemory: " + (Runtime.getRuntime().maxMemory() / 1024 / 1024) + "M");// Jvm已经向操作系统申请的内存System.out.println("totalMemory: " + (Runtime.getRuntime().totalMemory() / 1024 / 1024) + "M");// Jvm中此时空闲的内存System.out.println("freeMemory: " + (Runtime.getRuntime().freeMemory() / 1024 / 1024) + "M");}
}
- 执行结果:
maxMemory: 3495M
totalMemory: 236M
freeMemory: 217M
- 设置Jvm参数:
-Xms 3072m -Xmx3072m
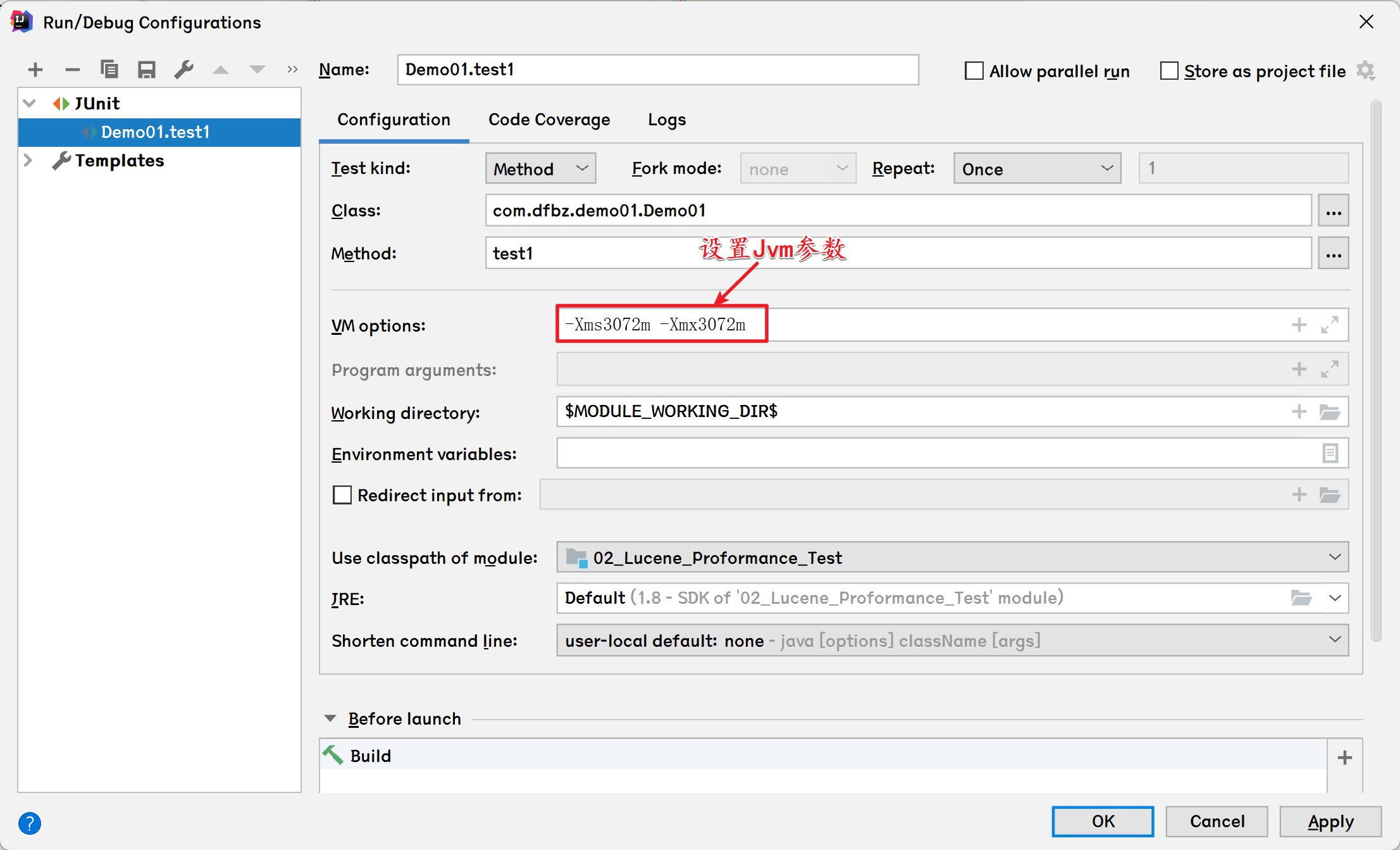
执行代码效果:
maxMemory: 2944M
totalMemory: 2944M
freeMemory: 2851M
Tips:Jvm实际申请的内存和参数指定的内存会有点差别
6.3 Directory性能测试
6.3.1 数据准备
【1-调用存储过程想数据库插入400W数据】
begin
call test_insert(4000000);
commit;
【2-使用idea对项目进行打包】
【3-启动jar包】
java -Xms3072m -Xmx3072m -Xmn800m -jar 02_Lucene_Proformance_Test-1.0-SNAPSHOT.jar
- -Xms:堆内存的初始化大小,避免由于频繁申请堆空间而造成性能损耗从而影响测试效果
- -Xmx:堆内存的最大大小,设置过小可能会导致堆内存溢出
- -Xmn:堆内存中年轻代的内存大小
【4-每次插入40W数据,分10批次插入】
http://localhost:8080/index/create/simple/10/400000
共用时:【224537】毫秒
Tips:采用什么Directory插入数据对查询测试不影响
【使用Luke工具查看】
6.3.2 400W数据查询测试
1)Windows平台
- SimpleFSDirectory:http://localhost:8080/query/test_query/simple/4000000
- NIOFSDirectory:http://localhost:8080/query/test_query/nio/4000000
- MMapFSDirectory:http://localhost:8080/query/test_query/mmap/4000000
- RAMFSDirectory:http://localhost:8080/query/test_query/ram/4000000
由于400W数据对Lucene来说也并不是特别多,这个数据量的测试具备很大的波动性,测试结果的偶然性较高,有兴趣的小伙伴可以自己私下测试,我们直接观察下面已经测试好的结果:
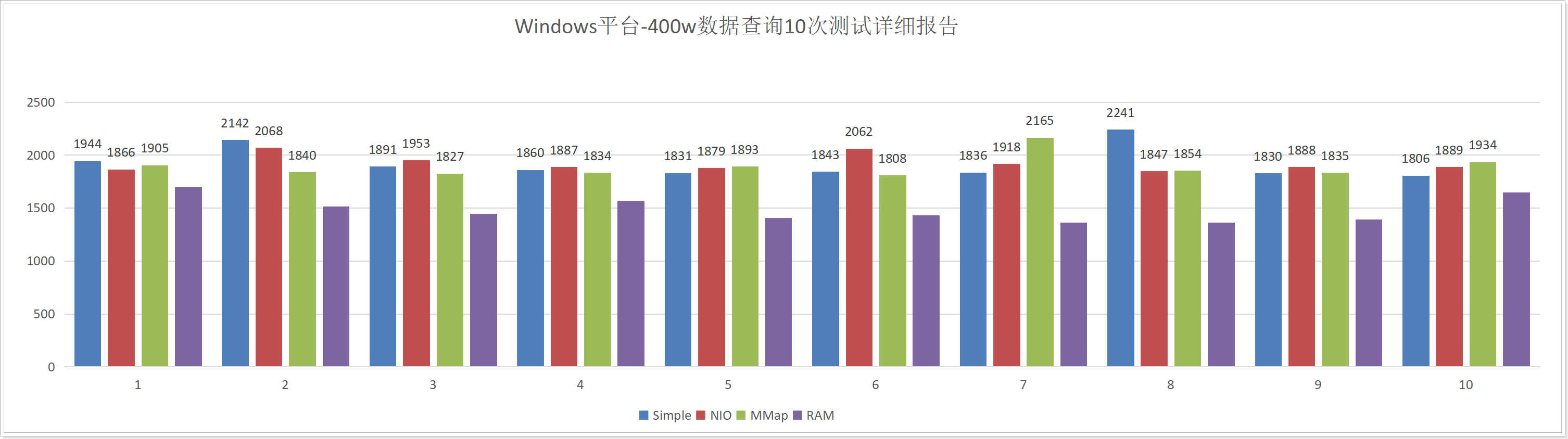
在实际测试过程中,由于第一次测试有机器性能预热等因素会影响测试结果,因此测试时最好测试11次,取后面10次的结果作为测试样本;
- 下面是测试10次累计时长比较:
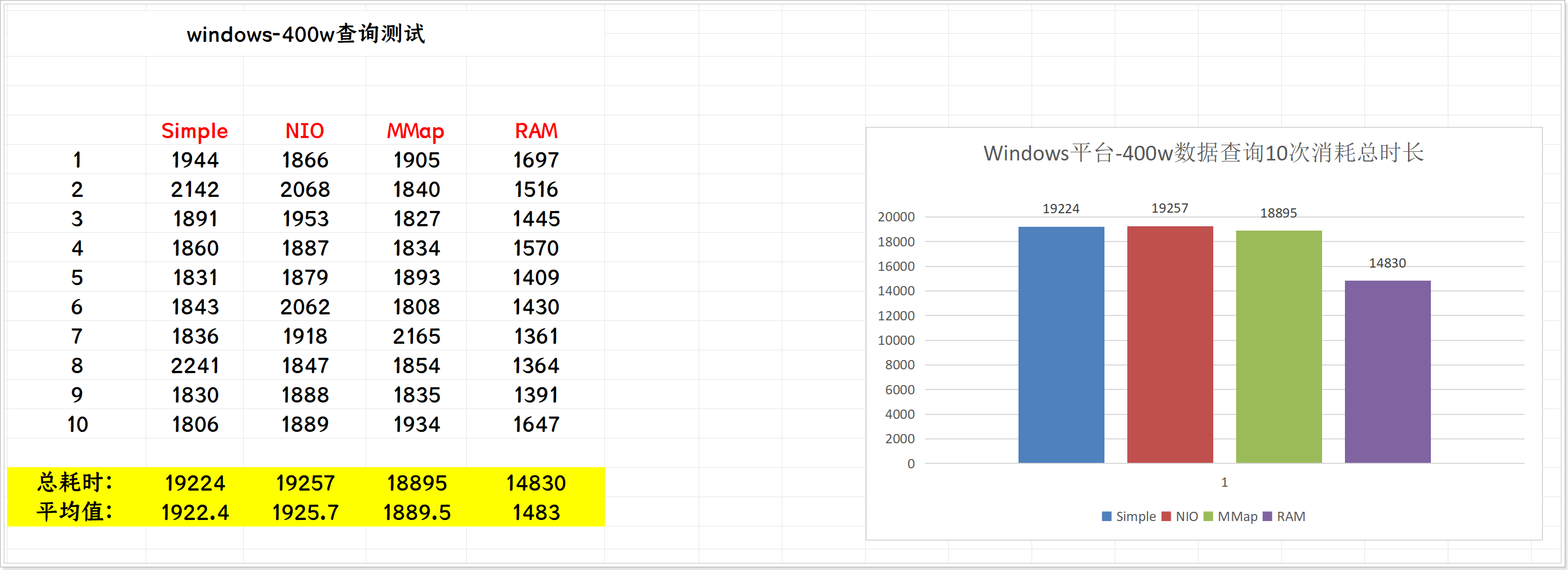
可以观察到,在Windows平台各个Directory的查询性能没有太大的差别;
2)Linux平台
在Linux平台安装Java环境:
yum -y install java-1.8.0-openjdk
将打好的jar包上传到Linux平台,使用同样的内存参数将jar包启动起来:
java -Xms3072m -Xmx3072m -Xmn800m -jar 02_Lucene_Proformance_Test-1.0-SNAPSHOT.jar
重新插入400W数据:
http://localhost:8080/index/create/simple/10/400000
执行各个Directory进行测试:
- SimpleFSDirectory:http://192.168.28.161:8080/query/test_query/simple/4000000
- NIOFSDirectory:http://192.168.28.161:8080/query/test_query/nio/4000000
- MMapFSDirectory:http://192.168.28.161:8080/query/test_query/mmap/4000000
- RAMFSDirectory:http://192.168.28.161:8080/query/test_query/ram/4000000
测试10次详细情况:

10次查询累计时长报告:
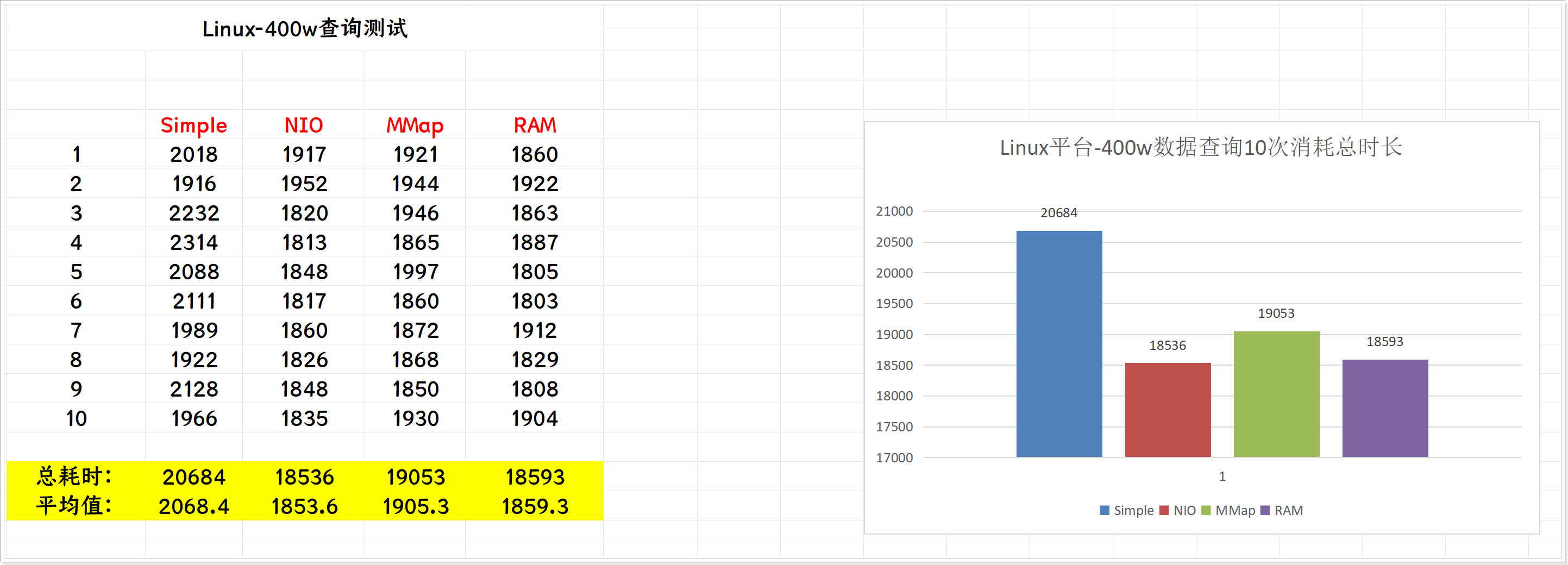
可以观察到,在Linux平台各个Directory查询性能有一定的差距。
6.3.3 并发查询测试
1)Windows平台
将MySQL中的数据控制到10W:
truncate goods;begin;
call test_insert(100000);
commit;select count(1) from goods;
将C:/index文件夹删除,重新向索引库中插入10W数据:
http://localhost:8080/index/create/simple/1/100000
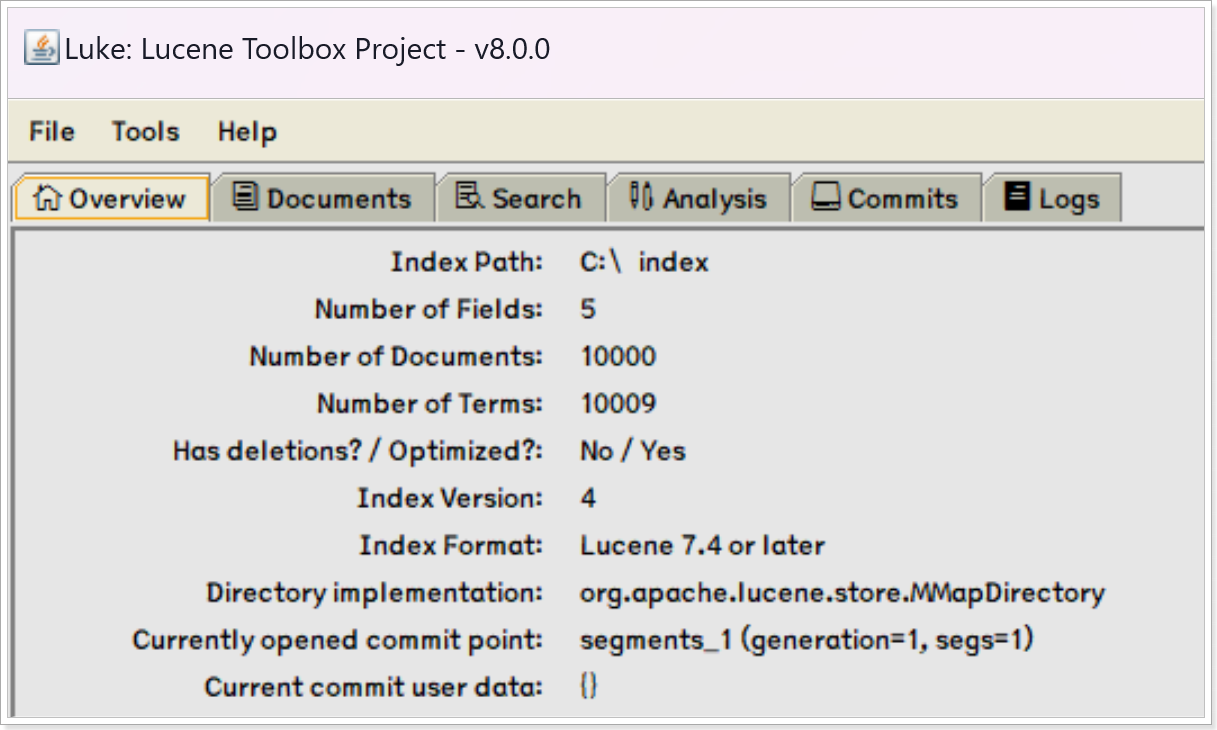
执行查询测试:
- SimpleFSDirectory:http://localhost:8080/query/test_concurrent/simple/100000/200
- NIOFSDirectory:http://localhost:8080/query/test_concurrent/nio/100000/200
- MMapFSDirectory:http://localhost:8080/query/test_concurrent/mmap/100000/200
- RAMFSDirectory:http://localhost:8080/query/test_concurrent/ram/100000/200
测试10次详细报告如下:
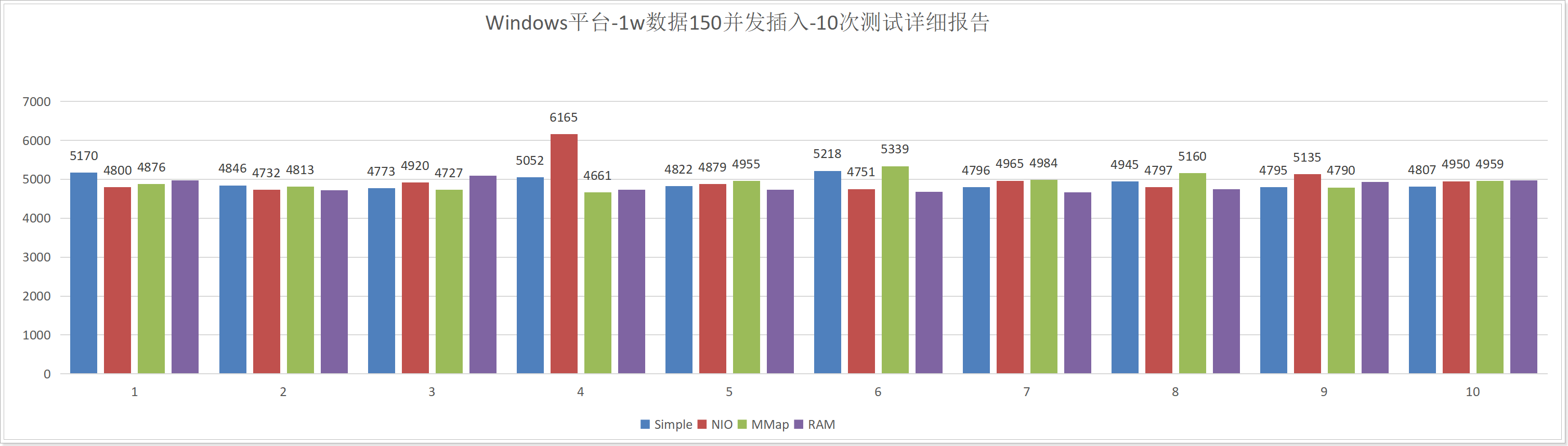
10次测试总消耗时长:

可以看到在Windows平台中,NIO的并发插入性能还不如Simple;
2)Linux平台
将/root/index目录删除,重新插入10W数据到索引库:
http://192.168.28.161:8080/index/create/simple/1/100000
执行查询测试:
- SimpleFSDirectory:http://192.168.28.161:8080/query/test_concurrent/simple/100000/200
- NIOFSDirectory:http://192.168.28.161:8080/query/test_concurrent/nio/100000/200
- MMapFSDirectory:http://192.168.28.161:8080/query/test_concurrent/mmap/100000/200
- RAMFSDirectory:http://192.168.28.161:8080/query/test_concurrent/ram/100000/200
测试10次详细报告如下:
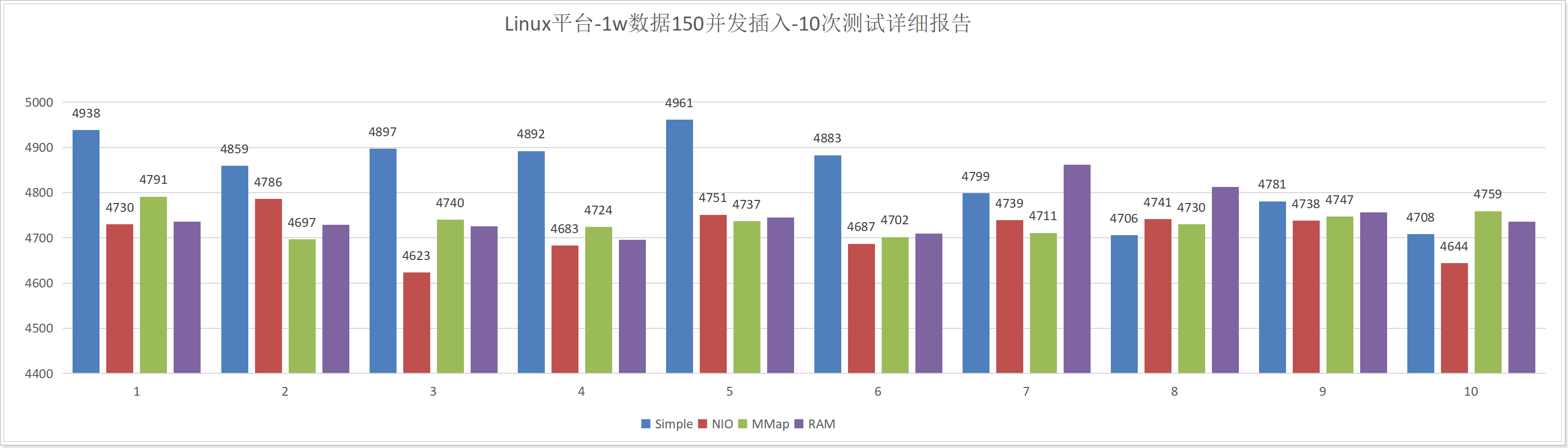
10次测试总消耗时长:
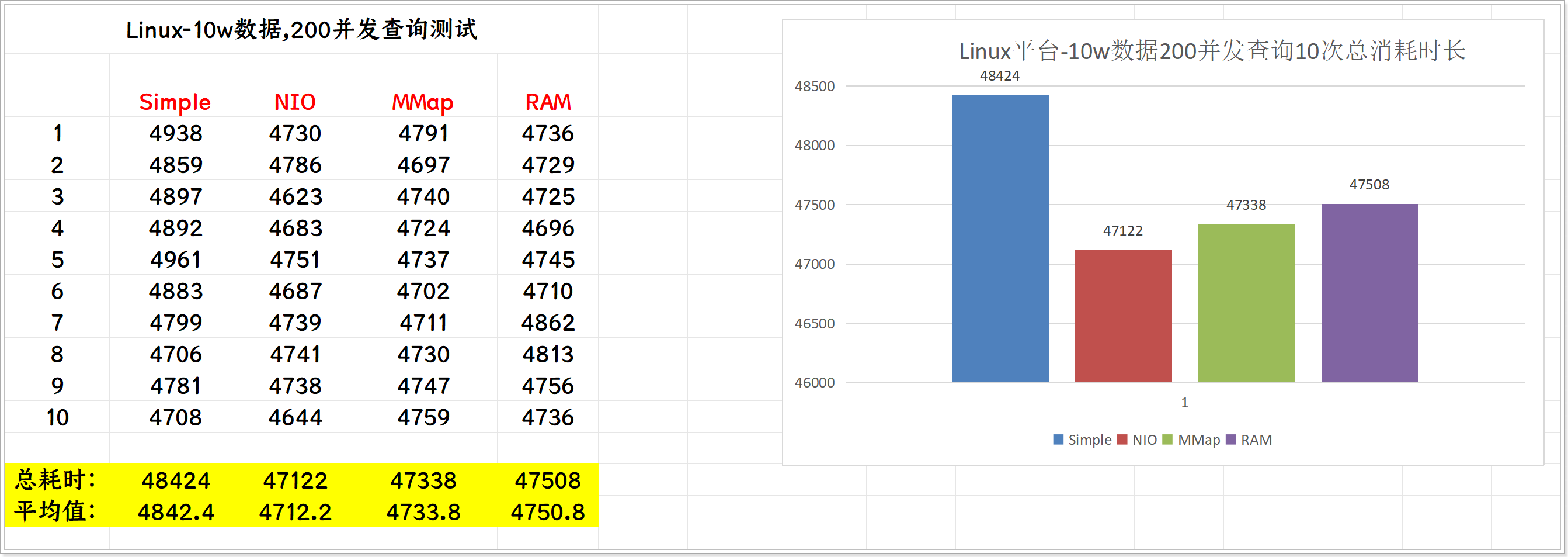
在Linux平台中,NIO的性能要高于Simple