Kubernetes容器日志处理方案
50-Kubernetes容器日志处理方案
0 前言
k8s里面对容器日志的处理都叫cluster-level-logging,即该日志处理系统,与容器、Pod及Node的生命周期完全无关。这种设计当然为保证,无论容器挂、Pod被删,甚至节点宕机,应用日志依然可被正常获取。
对于一个容器,当应用把日志输出到 stdout、stderr后,容器项目默认就会把这些日志输出到宿主机上的JSON文件。你就能kubectl logs看到这些容器的日志。
该机制就是本文要讲解的容器日志收集的基础假设。而若你的应用是把文件输出到其他地方,如容器里的某个件或输出到远程存储,那就属特殊情况。
k8s本身不会为你做容器日志收集,为实现cluster-level-logging,你要在部署集群时,提前规划日志方案。
而 k8s本身推荐:
1 三种日志方案
1.1 在 Node 上部署 logging agent
将日志文件转发到后端存储里保存。方案架构图:
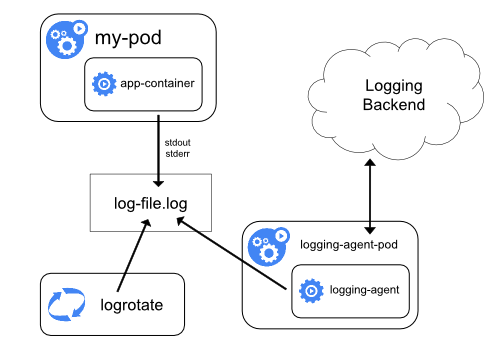
logging agent ,一般以 DaemonSet 运行在节点,然后将宿主机上的容器日志目录挂载进去,最后由 logging-agent 把日志转发出去。
如可通过 Fluentd 作为宿主机上的 logging-agent,然后把日志转发到远端的 ES 保存供检索。
具体操作:这篇文档。
很多 k8s 部署里,会自动启用 logrotate,在日志文件超过10MB 时自动对日志文件rotate。
可见 Node 上部署logging agent最大优点:一个节点只需部署一个 agent,且不会对应用和 Pod 有任何侵入性。所以,该方案最常用。
但不足在于,它要求应用输出的日志,须直接输出到容器的 stdout、stderr 。所以,k8s 容器日志方案第二种,就是对这种特殊情况的处理,即:当容器的日志只能输出到某些文件,可通过一个 sidecar 容器把这些日志文件重新输出到 sidecar 的 stdout、stderr,就能继续使用第一种方案。
方案具体工作原理:
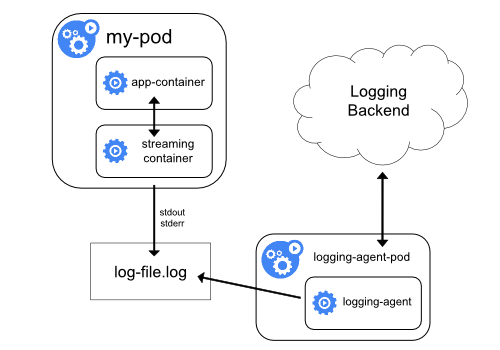 比如,现在我的应用 Pod 只有一个容器,它会把日志输出到容器里的/var/log/1.log 和2.log 这两个文件里。这个 Pod 的 YAML 文件如下所示:
比如,现在我的应用 Pod 只有一个容器,它会把日志输出到容器里的/var/log/1.log 和2.log 这两个文件里。这个 Pod 的 YAML 文件如下所示:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
在这种情况下,你用 kubectl logs 命令是看不到应用的任何日志的。而且我们前面讲解的、最常用的方案一,也是没办法使用的。
那么这个时候,我们就可以为这个 Pod 添加两个 sidecar容器,分别将上述两个日志文件里的内容重新以 stdout 和 stderr 的方式输出出来,这个 YAML 文件的写法如下所示:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
这时候,你就可以通过 kubectl logs 命令查看这两个 sidecar 容器的日志,间接看到应用的日志内容了,如下所示:
$ kubectl logs counter count-log-1
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
$ kubectl logs counter count-log-2
Mon Jan 1 00:00:00 UTC 2001 INFO 0
Mon Jan 1 00:00:01 UTC 2001 INFO 1
Mon Jan 1 00:00:02 UTC 2001 INFO 2
...
由于 sidecar 跟主容器之间是共享 Volume 的,所以这里的 sidecar 方案的额外性能损耗并不高,也就是多占用一点 CPU 和内存罢了。
但需要注意的是,这时候,宿主机上实际上会存在两份相同的日志文件:一份是应用自己写入的;另一份则是 sidecar 的 stdout 和 stderr 对应的 JSON 文件。这对磁盘是很大的浪费。所以说,除非万不得已或者应用容器完全不可能被修改,否则我还是建议你直接使用方案一,或者直接使用下面的第三种方案。
第三种方案,就是通过一个 sidecar 容器,直接把应用的日志文件发送到远程存储里面去。也就是相当于把方案一里的 logging agent,放在了应用 Pod 里。这种方案的架构:
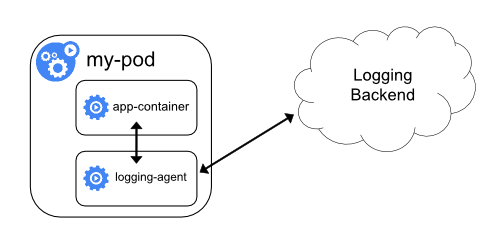 这种方案里,你的应用还可直接把日志输出到固定的文件里而不是 stdout,你的 logging-agent 还可以使用 fluentd,后端存储还可是 ElasticSearch。只不过, fluentd 的输入源变成应用的日志文件。一般会把 fluentd 的输入源配置保存在ConfigMap:
这种方案里,你的应用还可直接把日志输出到固定的文件里而不是 stdout,你的 logging-agent 还可以使用 fluentd,后端存储还可是 ElasticSearch。只不过, fluentd 的输入源变成应用的日志文件。一般会把 fluentd 的输入源配置保存在ConfigMap:
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
然后,我们在应用 Pod 的定义里,就可以声明一个Fluentd容器作为 sidecar,专门负责将应用生成的1.log 和2.log转发到 ElasticSearch 当中。这个配置,如下所示:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: k8s.gcr.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
可以看到,这个 Fluentd 容器使用的输入源,就是通过引用我们前面编写的 ConfigMap来指定的。这里我用到了 Projected Volume 来把 ConfigMap 挂载到 Pod 里。如果你对这个用法不熟悉的话,可以再回顾下第15篇文章《 深入解析Pod对象(二):使用进阶》中的相关内容。
这方案虽部署简单,且对宿主机非常友好,但这 sidecar 容器很可能会消耗较多的资源,甚至拖垮应用容器。并且,由于日志还是没有输出到 stdout上,所以你通过 kubectl logs 是看不到任何日志输出的。
总结
k8s 项目对容器应用日志的收集方式。综合对比以上三种方案,建议你将应用日志输出到 stdout 和 stderr,然后通过在宿主机上部署 logging-agent 的方式来集中处理日志。
这方案管理简单,kubectl logs 也可用,可靠性高,且宿主机本身很可能就自带 rsyslogd 等非常成熟的日志收集组件来供使用。
还有一种方式就是在编写应用时,就直接指定好日志的存储后端:
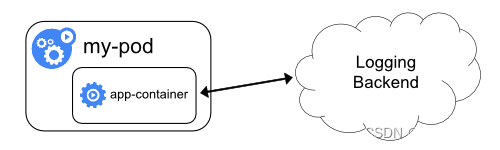 这种方案下,k8s 就完全不必操心容器日志收集,这对于本身已经有完善的日志处理系统的公司很友好。
这种方案下,k8s 就完全不必操心容器日志收集,这对于本身已经有完善的日志处理系统的公司很友好。
无论哪种方案,须及时将这些日志文件从宿主机上清理掉或给日志目录专门挂载一些容量巨大的远程盘。一旦主磁盘分区被打满,整个系统就可能会陷入崩溃。
FAQ
日志量很大时,直接将日志输出到容器 stdout 和 stderr上,有什么隐患?解决办法?
获取更多干货内容,记得关注我哦。
本文由 mdnice 多平台发布

